前言:
我們所處的世界充滿了各種各樣的字符,我們使用它們,用自己定義的方式來表示,交流,那么計算機內部是怎么樣表示這些字符的呢?這個時候你滿腦子都是電腦螢屏上的0 1 0 1對吧,是的,沒錯,由于硬體的原因,計算機使用01來表示我們世界的字符,但字符的種類如此之多,這其中的范式又是什么呢?
在我們走進01世界之前,我們先看看當下我們使用的字符編碼,這其中不乏大家熟知的ascall碼、utf-8等等,
| 編碼 | 提出時間 | 字符集大小 | 解釋 |
| ASCALL | 1961年 | 128個字符(最初為8位,最高位為校驗位) | 可以表示數字、英文字符和一些字符 |
| (ANSI)MBCS | 由于ASCALL字符有限,每個國家語言不同,所以對ASCALL進行擴充,產生MBCS | 對于不同國家來說,基本實作所有字符的覆寫 | 不同的國家和地區制定了不同的標準,由此產生了 GB2312, BIG5, JIS 等各自的編碼標準,這些使用 2 個位元組來代表一個字符的各種漢字延伸編碼方式,稱為 ANSI 編碼,又稱為"MBCS(Muilti-Bytes Character Set,多位元組字符集) |
| GB2312 | 是ANSI的一種,針對我們國家發布的,也叫國標碼 | 6763個常用漢字和682個全角的非漢字字符組成 | 采用94行94列的區位碼進行編碼 |
| GBK | GB 2312的出現,基本滿足了漢字的計算機處理需要,但對于人名、古漢語等方面出現的罕用字,GB 2312不能處理,這導致了后來GBK及GB 18030漢字字符集的出現, | 總計23940 個碼位,共收入21886個漢字和圖形符號,其中漢字(包括部首和構件)21003 個,圖形符號883 個 | 有些漢字用五筆和拼音都打不出來,如:溙(五筆IDWI),須調出GBK字符集才能打出這個字 |
| Big5 | 為統一繁體字符集編碼,1984年,臺灣五大廠商宏碁、神通、佳佳、零壹以及大眾一同制定了一種繁體中文編碼方案,因其來源被稱為五大碼,英文寫作Big5,后來按英文翻譯回漢字后,普遍被稱為大五碼 | 大五碼是一種繁體中文漢字字符集,其中繁體漢字13053個,808個標點符號、希臘字母及特殊符號 | 目前,Big5編碼在臺灣、香港、澳門及其他海外華人中普遍使用,成為了繁體中文編碼的事實標準, |
| Unicode | 世界上存在著多種編碼 方式,在ANSi編碼下,同一個編碼值,在不同的編碼體系里代表著不同的,為了統一就誕生了Unicode | Unicode當然是一個很大的集合,現在的規模可以容納100多萬個符號 | Unicode固然統一了編碼方式,但是它的效率不高,比如UCS-4(Unicode的標準之一)規定用4個位元組存盤一個符號,那么每個英文字母前都必然有三個位元組是0,這對存盤和傳輸來說都很耗資源, |
| UTF-8 | 為了提高Unicode的編碼效率,于是就出現了UTF-8編碼,UTF-8可以根據不同的符號自動選擇編碼的長短,比如英文字母可以只用1個位元組就夠了, | 和Unicode一樣字符集 | 對Unicode的優化,可以包含世界上所有字符,字母占1個位元組,漢字占3個位元組; UTF-8 是在互聯網上使用最廣的一種 Unicode 的實作方式, UTF-8 是一種變長的編碼方式,它可以使用 1-6 個位元組表示一個符號,根據不同的符號而變化位元組長度 |
| Base64 | 有的電子郵件系統(比如國外信箱)不支持非英文字母(比如漢字)傳輸, 這是歷史原因造成的,因為一個英文字母使用ASCII編碼來存盤,占存盤器的1個位元組(8位),實際上只用了7位2進制來存盤,第一位并沒有使用,設定為0,所以,這樣的系統認為凡是第一位是1的位元組都是錯誤的,而有的編碼方案(比如GB2312)不但使用多個位元組編碼一個字符,并且第一位經常是1,于是郵件系統就把1換成0,這樣收到郵件的人就會發現郵件亂碼, | 英文中文字符都可以 | 為了能讓郵件系統正常的收發信件,就需要把由其他編碼存盤的符號轉換成ASCII碼來傳輸,比如,在一端發送GB2312編碼->根據Base64規則->轉換成ASCII碼,接收端收到ASCII碼->根據Base64規則->還原到GB2312編碼 |
這些編碼集都是外面平時使用的,不信你可以打開記事本,點擊另存為的時候就可以選擇字符集,當然就有上面我們提到的ANSI,而我們做javaee或者網頁的時候,大都也采用utf-8,看了上面的介紹我們心里應該大致知道是為什么了吧,所以,亂碼并不可怕,只要編碼和解碼的字符集一致就好,絕對不會出問題,
一、思維導圖
我們可以看看關于我們世界所使用的文字的思維匯入,接下來所展示的數字和文字表示方式會根據這個來進行,

二、談談資料的表示方式
大部人是知道計算機內部以01來存盤我們的資料,也知道進制的轉換,這里就根據上面的思維導圖來簡單說說我們的資料表示吧,
(1)數值型別
首先,大家最新認識的當然是十進制的資料(在沒有學計算機之前,其它的進制數大都是在初高中數學里面知道的,但都不熟悉),對于十進制數,我們在熟悉不過了,我們可以用二進制,八進制,十六進制來表示,例如十進制27就可以表示為十六進制的1B,二進制的0001 1010,那么聰明的你可能會問我,負數是怎么表示的呀?當然,我們用十進制是很好表示負數的,但是對計算機來說,卻是一件頭疼的事情,所以CS(Computer scientist)們就想出將二進制能夠表示的數用一半的數表示正數,另一半的數表示負數的形式,例如8位二進制數,0~127這128個數字就表示正數,而128~255這128個數字就表示負數,但是約定它們表示-128~-1,所以就有了課堂上老師說計算機內部擁有符號位的說法,其本質就是這個,如果想要了解更過關于二進制補碼的,可以跳轉到我這篇博客:進制轉換小技巧之讓你重新認識二進制補碼(大師,我悟了)!!!,所以對于數值我們就說清楚了對吧,
當然沒有啦,因為我們小學所學的,除了整數,還有小數呢,這里小數又分為定點數和浮點數,但是你會問我,什么?小學不就是小數嗎?上面的定點數和浮點數當然是我們計算機有關的定義啦,所謂的定點數就是約定機器中所有資料的小數點位置是固定不變的,由于約定在固定位置,小數點就不再使用記號“.”來表示了,所以定點數就是我們上面所說的純整數還有純小數,我們只需要最高位表示符號位,后面為尾數即可,
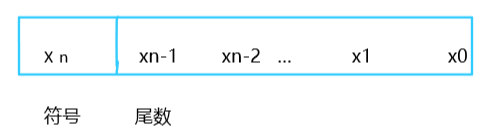
如果數X表示的是純小數,那么小數點位于Xn和Xn-1之間;如果數X表示的是純整數,那么小數點位于最低位X0的右邊,
--------->
對于浮點數來說:把數的范圍和精度分別表示的方法,相當于數的小數點位置隨比例因子的不同而在一定范圍內可以自由浮動,所以稱為浮點數表示法,
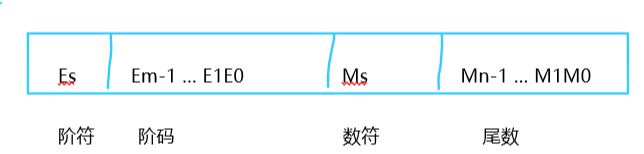
任意的一個十進制數N可以寫成N = 10^E.M;同樣,任意二進制N可以寫成N = 2^e.M,其中M稱為浮點數的尾數,是一個純小數,e是比例因子,稱為指數,表示為整數,也稱為階碼,而階符合數符當然就是符號位啦,所以我們現在已經知道了定點數和浮點數在機器內的表達方式了,那么我們小時候所學的也并非只有數學,還有語文,還有各種各樣的符號,它們是怎么在計算機中表示呢?
(2)字符和字串
對于我們所學的ABCD,顯然需要另一種方式來表達,于是我們就有了ASCALL碼,美國人將英語字符和其它符號專門定義了一個統一的標準,用專門的數字對應符號,例如a的ASCALL碼就是97,它對應的大寫的A的ascall碼就是65,為什么我會知道,你可能相差32,那是因為在二進制表達的時候大小寫的差值就在于第5位二進制的符號相異,而表示字串,我們既可以用ascall碼,也可以用我們可以理解的方法(但這些方法大都不實用,因為計算機內部無法表示),
由于ascall碼能夠表示的字符有限,所以后來我們就有了Unicode,萬國碼,超級齊全,之后的utf-8和utf-16也是以此為基準在計算機內部表示,
三、談談漢字的表示方式
那我們國家的漢字如何表示存盤的呢?
存盤漢字有很多種方法對吧,我們國家采用的數字編碼其實就是國標區位碼,也就是將國家標準局公布的6763個兩級漢字分為94個區,每個區分94位,實際上就是一個二維的表格,例如“中”字就是第54區48位,區位碼為5448,而它的機器內嗎無非就是將5448轉換為進制數(因為這里的5448是十進制數),例如我們轉換為16進制數為36 30,注意,這里54 48是兩個數字,所以轉換是分別轉換,然后將它加上A0A0H,就得到它的機器內碼的表示:D6D0,也就是說:漢字內碼 = 區位碼 + 0XA0X0H,
為什么是這樣呢?那是因為,一個漢字要兩個位元組,為了讓計算機識別出左邊和右邊一同聯合表示一個漢字,最高位就為1,所以我們這么加也就是讓最高位都為1啦,
四、展望:有沒有更好的表示呢?
現在幾乎所有的人類語言和字符都可以用計算機來表示了,我們做專案一件很重要的事情也就是統一字符編碼,讓編碼和解碼的字符一致,才不會出現亂碼的情況,當然最常用的也就是utf-8啦,那么有沒有比這更好更快的表達呢?讓計算機更加的便捷呢?就看你們啦~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/155704.html
標籤:其他
上一篇:模板 - 二維幾何常用演算法(平面掃描、凸包、半平面交、平面區域)
下一篇:Word錯誤,嵌入物件無效