第一章:計算機系統漫游
#include<stdio.h>
int main()
{
printf("hello,world\n");
return 0;
}
1 資訊就是位+背景關系
- 系統中所有的資訊——包括磁盤檔案、記憶體中的程式、記憶體中存放的用戶資料以及網路上傳送的資料,都是由一串位元(0和1)表示的,區分不同資料物件的唯一方法就是我們讀到這些寫資料物件時的背景關系,比如在不同程式中,同一個位元組序列可能表示一個整數、浮點數、字串或者機器指令
2 程式被翻譯成不同的格式

- 預處理階段: 前處理器(cpp)根據以字符#開頭,修改原始的c程式,例如,hello.c中第一行#include<stdio.h>命令就鈣素前處理器讀取系統頭檔案stdio.h中的內容,并把它直接插入程式文本中,結果就得到了另一個C程式,通常是以.i作為檔案擴展名
- 編譯階段: 編譯器(ccl)將文本檔案hello.i翻譯成文本檔案hello.s,它包含了一個匯編語言程式,改程式包含main函式的定義
- 匯編階段: 匯編器(as)將hello.s翻譯成機器語言指令,并把這些指令打包成一種叫做可重定位目標程式的格式,并將結果保存在目標檔案hello.o(二進制檔案)中
- 連接階段: 注意hello程式呼叫了printf函式,printf函式存在于一個名為printf.o的單獨預編譯好了的目標檔案中,而這個檔案必須以某種方式合并到我們的hello.o程式中,連接器(ld)就負責處理這種合并,結果就得到了一個hello檔案,他是一個可執行檔案,可以被加載到記憶體中,由系統執行
3了解編譯系統如何作業是大有益處的
- 優化程式性能
- 理解連接時出現的錯誤
- 避免安全漏洞
4系統硬體的組成
在Unix系統上,從源檔案到目標檔案的轉化是由編譯器驅動完成的
linux> gcc-o hello hello.c
這個程序大致可以分為四個階段,執行這四個階段的程式(前處理器、編譯器、匯編器和聯結器)一起構成了編譯系統,gcc編譯器是Linux系統默認的編譯器,
- 總線: 貫穿整個系統的是一組電子管,稱作總線,通常總線被設計成傳送定長的位元組塊,也就是字,但是這個字在各個系統中的設定一般也不相同,
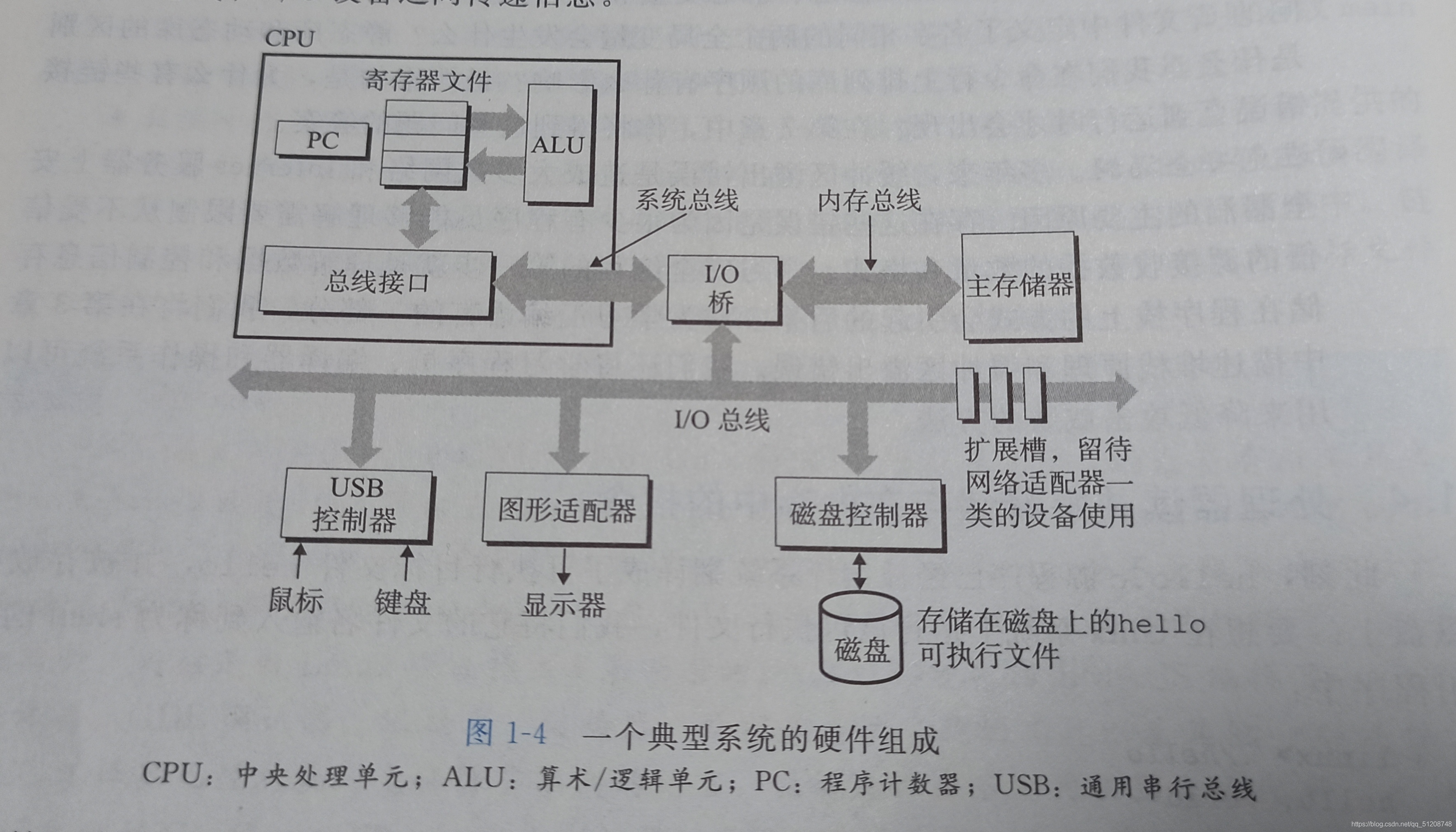
- I/O設備: 每個I/O設備都通過控制器或者配接器與I/O總線相連,控制器是I/O設備本身或者系統的主印制電路板(主板)上的芯片組,而配接器是一塊插在主板插槽上的卡,
- 主存: 主存是一個臨時存盤設備,用來存放程式和程式處理的資料,主存是由一組動態隨機存取存盤器(DRAM)芯片組成的,從邏輯上來說,存盤器是一個線性的位元組陣列,每個位元組都有唯一的地址(陣列索引),這些地址是從零開始的,
- 處理器: 也就是CPU,處理器的核心是一個大小為一個字的存盤設備(或暫存器),稱為程式計數器(PC).在任何時刻,PC都指向主存中的某潭訓器語言命令(含有該條指令的地址),處理器一直不斷地執行PC指向的指令,再更新PC,使其指向下一條指令,處理器中還有暫存器和ALU,暫存器是小的存盤設備,每個暫存器都有唯一的名字;ALU是算數邏輯單元,用來計算新的資料和地址值,
5運行hello程式
- shell程式字符逐一讀入暫存器,再把它放入記憶體中(圖片)
- 一旦目標檔案hello中的代碼和資料被加載到主存,處理器就開始執行hello程式的main程式的機器語言指令
- 這些指令將“hello,world\n”字串中的位元組從主存復制到暫存器檔案,再從暫存器檔案中復制到顯示設備,最終顯示在螢屏上,
6高速快取至關重要
隨著半導體基礎的進步,處理器與主存之間讀取資料的差距在不斷變大,為了解決這個問題,出現了高速緩沖存盤器(cache) ,作為暫時的集結區域,存放處理器近期可能會需要的資訊,
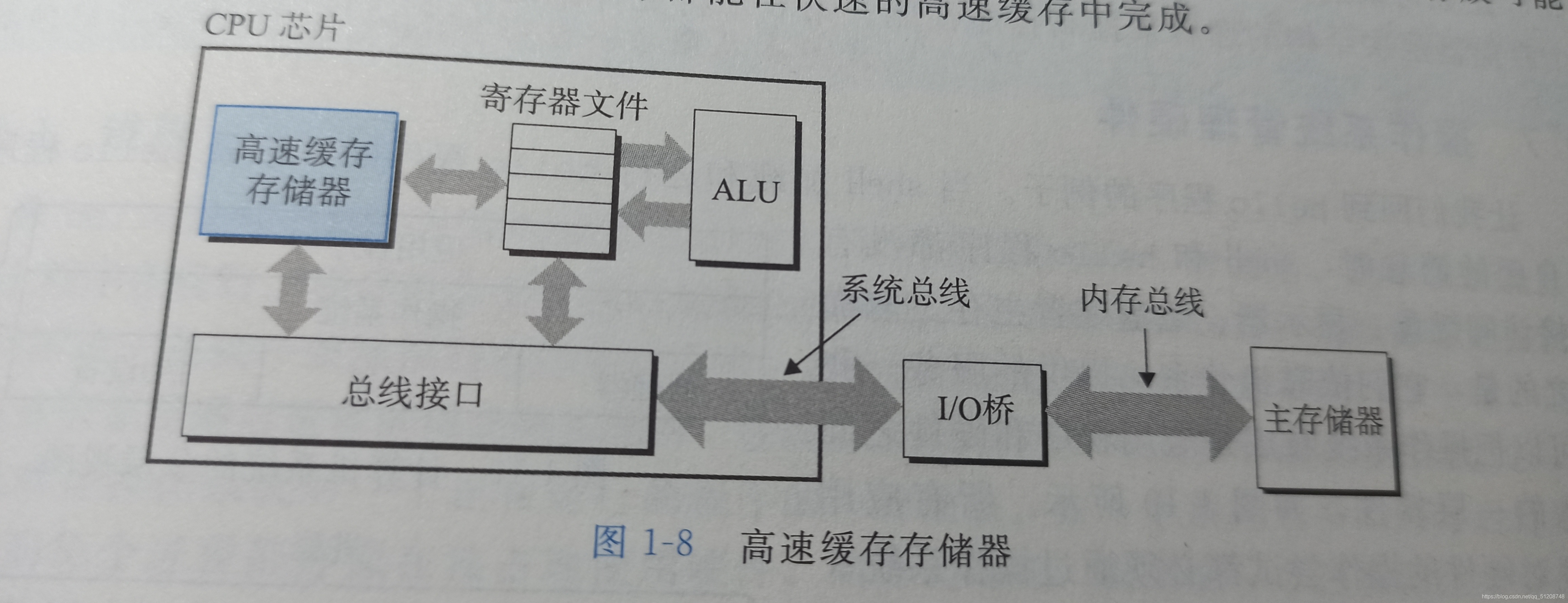
L1高速快取位于處理器芯片上,容量可以達到數萬位元組,訪問速度幾乎可以和訪問暫存器檔案一樣快,
L2高速快取通過一條特殊的總線連接到處理器,容量為數十萬位元組到數百萬位元組,行程訪問L2高速快取的時間要比訪問L1的時間長5倍,L1和L2都是用一種靜態隨機訪問存盤器(SRAM) 實作的
7存盤設備形成層次結構
存盤器層次結構的主要思想就是上一層的存盤器作為低一層存盤器的高速快取

8作業系統管理硬體
我們可以把作業系統看成是應用程式和硬體之間插入的一層軟體,所有應用程式對硬體的操作嘗試都必須通過作業系統
作業系統有兩個功能:(1)防止硬體被失控的程式濫用;(2)向應用程式提供簡單一致的機制來控制復雜而又通常大不相同的低級硬體設備
作業系統提供了幾個基本的抽象概念來實作這兩個功能:行程,虛擬記憶體和檔案

-
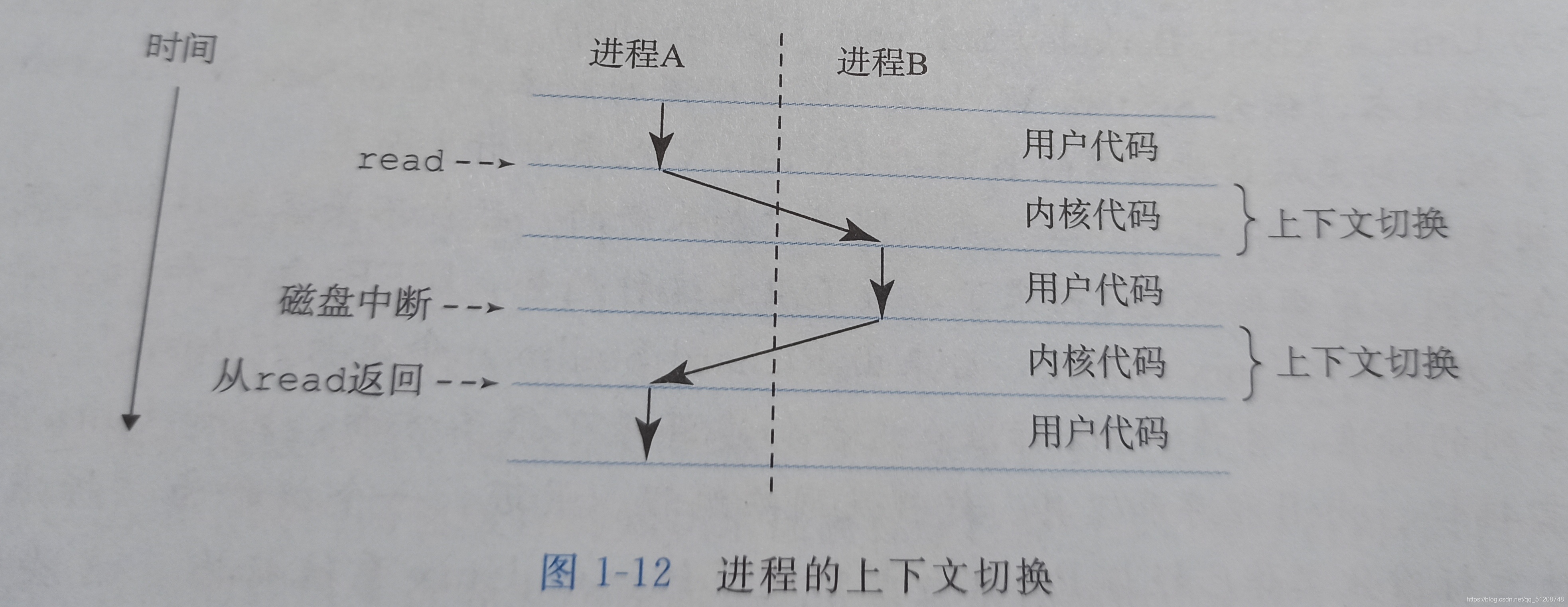
行程: 行程是作業系統對一個正在運行的程式的一種抽象,一個系統可以同時運行多個行程,而每個行程都好像在獨占地使用硬體,而并發運行則是說一個行程的指令和另一個行程的指令是交錯執行的,
作業系統保持跟蹤行程運行所需要的所有狀態資訊,這種狀態,也就是背景關系,在任何一個時刻,單處理器系統都只能執行一個行程的代碼,當作業系統決定要把控制權從當前行程轉移到某個新行程時,就會進行背景關系切換(保存當前行程的背景關系、恢復新行程的背景關系,然后將控制權傳遞到新行程),新行程就會從它上次停止的地方開始
-
執行緒: 一個行程實際上由多個稱為執行緒的執行單元組成,每個執行緒都運行在行程的背景關系中,并共享同樣的代碼和全域資料,
-
虛擬記憶體: 虛擬記憶體是一個抽象概念,它為每一個行程提供了一個假象,即每個行程都在獨占地使用主存,每個行程看到的記憶體都是一致的,稱為虛擬地址空間 ,下圖是Linux行程的虛擬地址空間(地址從下往上是增大的)
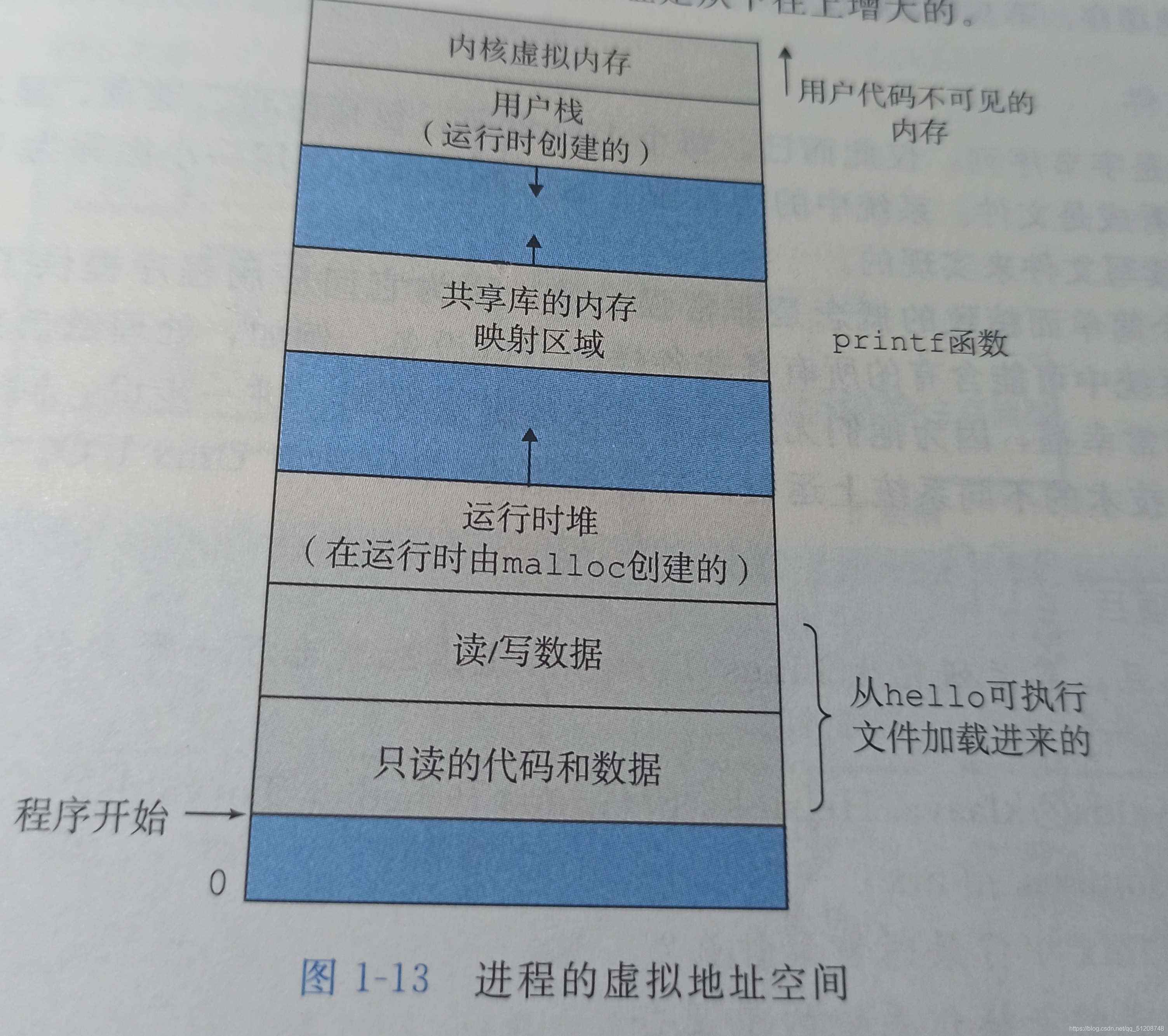
在Linux中,地址空間最上面的區域是保留給作業系統中代碼和資料的,這對所有行程來說都是一樣的,地址空間的底部區域存放的是用戶行程定義的代碼和資料1、程式代碼和資料: 對所有行程來說,代碼是從同一固定地址開始,緊接著的是和C全域變數相對應的資料位置,代碼和資料區是直接按照可執行目標檔案的內容初始化的
2、堆: 代碼和資料區后緊隨著的是運行時堆,代碼和資料區在行程一開始就被指定了大小,與此不同,當呼叫想malloc和free這樣的C標準庫函式時,堆可以在運行時動態地擴展和收縮,
3、堆疊: 位于用戶虛擬地址空間頂部的是堆疊,編譯器用它來實作函式呼叫,和堆一樣,用戶堆疊在程式執行期間可以動態地收縮和擴展,特別的,每當我們呼叫一個函式時,堆疊就會增長;從一個函式回傳時,堆疊就會收縮
4、內核虛擬記憶體: 地址空間頂部的區域是為內核保留的,不允許應用程式來讀寫這個區域的內容或者直接呼叫內核代碼定義的函式,相反,它們必須呼叫內核來執行這些操作9檔案
檔案就是位元組序列,僅此而已,每個I/O設備都可以看做一個檔案,
10并發和并行
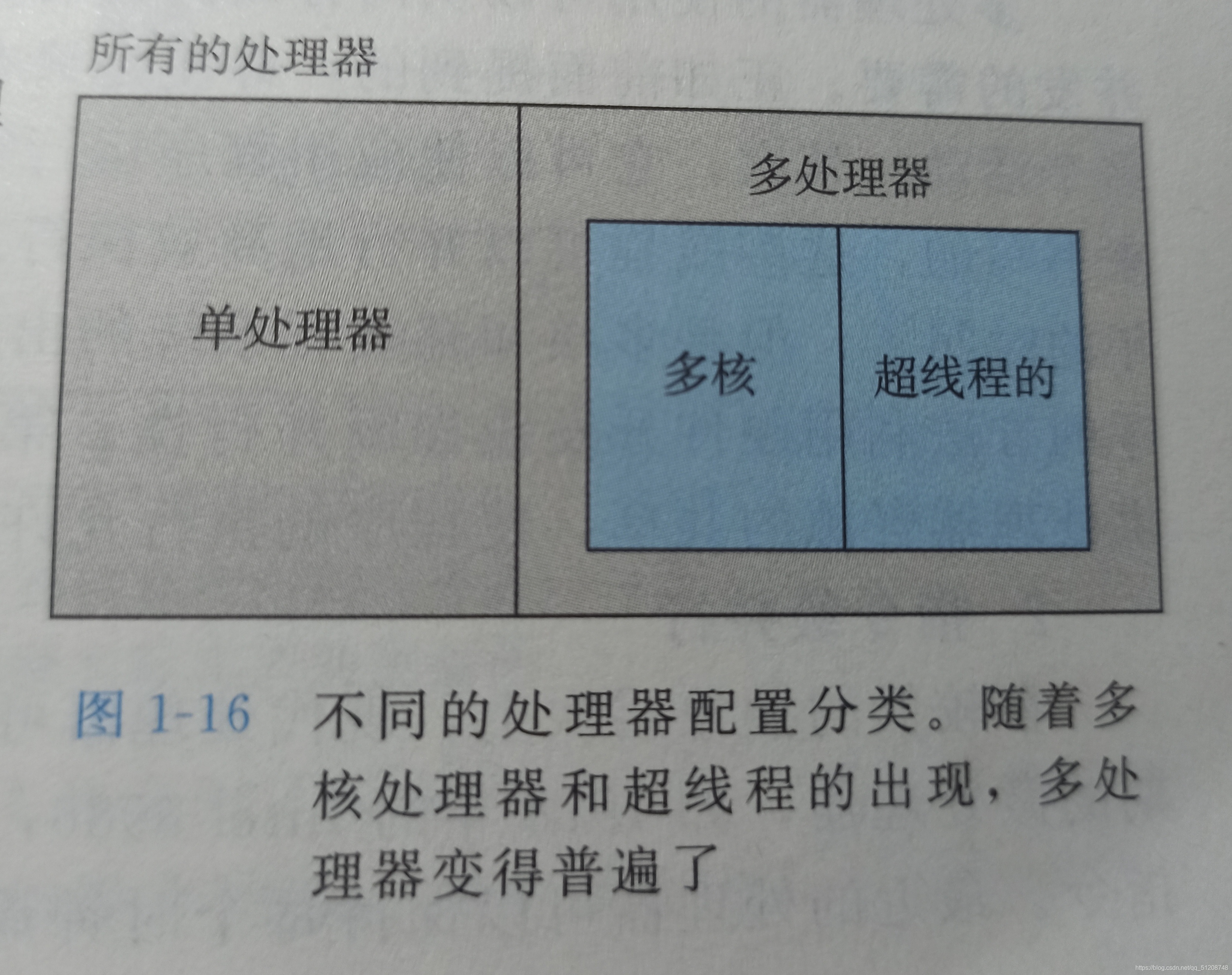
- 執行緒級并發: 構建在行程這個抽象之上,我們能夠設計出同時有多個程式執行的系統,這就導致了并發,使用執行緒,我們甚至能夠在一個行程中執行多個控制流,當構建一個有單作業系統內核控制的多處理器組成的系統時,我們就得到了一個多處理器系統
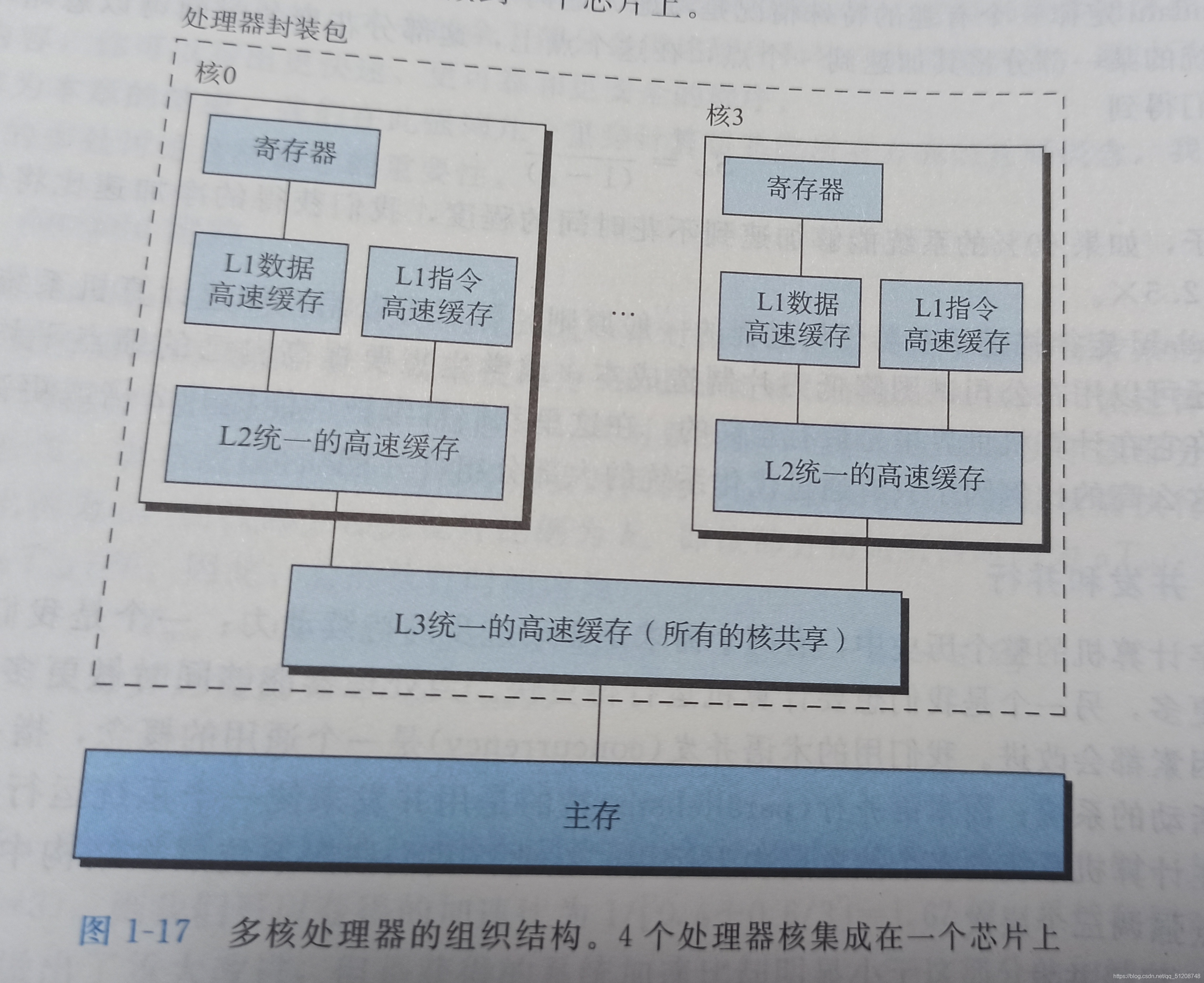
微處理器芯片有4個CPU核,每個核都有自己的L1和L2高速快取,其中的L1分為兩個部分——一個保存最近取到的指令,另一個存放資料,這些核共享更高層次的高速快取,以及到主存的介面,
超執行緒,有時稱為同時多執行緒,是一項允許一個CPU執行多個控制流的技術,常規的處理器需要大約20000個時鐘周期做不同執行緒間的轉換,而超執行緒的處理器可以在單個周期的基礎上決定要執行哪一個執行緒,- 指令級并行: 在較低的抽象層次上,現代處理器可以同時執行多條指令的屬性稱為指令級并行,如果處理器可以達到比一個周一一條指令更快的執行速率,就稱之為超標量處理器,大多數現代處理器都支持超標量操作
## 單指令,多資料并行: 在最低層次上,許多現代處理器擁有特殊的硬體,允許一條指令產生多個可以并行執行的操作,這種方式成為單指令,多資料,即SIMD并行, 提供這些SIMD指令多是為了提高處理影像、聲音和視頻資料應用的執行速度,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/155711.html
標籤:其他