Redis——Redis集群理論
文章目錄
- Redis——Redis集群理論
- 一、為什么需要搭建 Redis 集群
- 1、單點故障
- 2、容量有限
- 3、壓力過大
- 二、AKF服務拆分原則
- 1、X軸水平擴展
- 2、Y軸服務拆分
- 3、Z軸資料磁區
- 三、基于AKF的Redis集群
- 1、水平擴展
- 2、縱向擴展
- 四、集群的問題——資料一致性
- 1、強一致性
- 2、弱一致性
- 3、最終一致性
一、為什么需要搭建 Redis 集群
在前面的文章中,我們已經學習過 Redis 在單機情況下,Redis 的常見應用:
- 快取
- 資料庫
如果是當作快取的時候,當服務掛掉重啟的時候,我們可以重啟一個新的實體,里面什么資料都沒有,這樣的話請求將會穿透快取,直接請求到資料庫,然后慢慢把熱資料加載到快取;也可以在重啟 Redis 服務的時候,就把百分之七八十的熱資料加載到快取,這樣就涉及到單機本地的持久化,因為是快取,允許部分資料丟失,所以使用 RDB 持久化就夠了,根據 dump.rdb 就能夠很快的恢復大量熱資料,對外提供服務
如果是當作資料庫的話,就需要保證資料不可丟失,就需要使用 RDB以快斬訓者 AOF 以日志方式進行持久化,以增量日志的方式保證資料不丟失,4.0 以后 AOF 以混合模式進行存盤,前半部分是 RDB,后面以追加寫的方式保存日志
那么為什么生產中需要搭建集群?一定是單機情況下,有些問題是無法解決的,那么單機、單節點、單實體會有什么問題?單機的 Redis 服務通常會有以下風險:
- 單點故障
- 容量有限
- 壓力過大
1、單點故障
由于只有一個 Redis 行程對外提供服務,一旦服務器出現斷電、宕機、卡死等等的意外問題,系統中就無法使用 Redis 快取服務,這樣大量請求就會大量到達資料庫,而資料庫存盤于磁盤,回應速度極慢,而且容易造成資料庫崩潰
簡單來說就是容易造成服務不可用,這在上線的生產環境中是不允許的
2、容量有限
如果一個特別大的系統,如淘寶、12306,資料特別多,資料量特別大,一個 Redis 服務 hold 住嗎?存的下嗎?
所以單機 Redis 服務的另一個問題就是容量有限,稍微大一點的系統,一個 Redis 服務無法支撐起來
3、壓力過大
由于只有一個 Redis 單機服務,則這個 Redis 行程將要處理所有的 client 端請求,以及所有的查詢、修改操作,無論是大量的連接帶來的 socket 壓力,還是 CPU 的密集型操作壓力,都會造成 Redis 服務行程壓力過大
那么怎么解決單機的問題呢?我們可以通過搭建多臺 Redis 服務,共同對外提供服務,減輕單臺壓力
二、AKF服務拆分原則
在《架構即未來》這本書,里面提到的AKF擴展立方體,是業界公認的微服務拆分原則的最佳實踐,其核心思想就是:通過加機器可以解決容量和可用性問題(如果一臺不行就兩臺)
用個段子描述就是:在重慶沒有什么事是一頓火鍋解決不了的,如果有,那就兩頓
既然是立方體,那么這是一個三維的模型,分別包含X,Y,Z軸,三個不同維度相輔相成,示意圖如下:

1、X軸水平擴展
所謂 X 軸代表把同樣的作業或資料鏡像分配給多個物體,換句話說就是復制服務然后負載均衡,使單臺服務壓力降低,而且單臺服務掛掉之后,其他的服務能夠頂上來,提高容錯性
豪橫一點的說法就是:“我有錢,我就加機器來解決問題”
例子:
我有個網站,一開始部署在服務器A上對外服務,隨著訪問人數增加,一臺服務其的性能無法支持,于是我又在服務器上B上同樣部署了網站,然后在前面部署了Apache或者Nginx來分流訪問,這就是最基本的X軸擴展
但是基于 X 軸擴展,每臺服務器都是存盤全量資料,在資料量很大的系統中,每臺機器容量有限,壓力很大
2、Y軸服務拆分
針對X軸擴展產生的問題,我們需要將大型服務進行拆解,把分割的作業指責和資料分配個多個物體,這也就是Y軸擴展,也是微服務理論誕生的基礎,
每個服務實作一組相關的功能,如訂單管理,客戶管理等,在工程上常見的方案是服務化架構(SOA),比如對于一個電子商務平臺,我們可以做如下拆分:
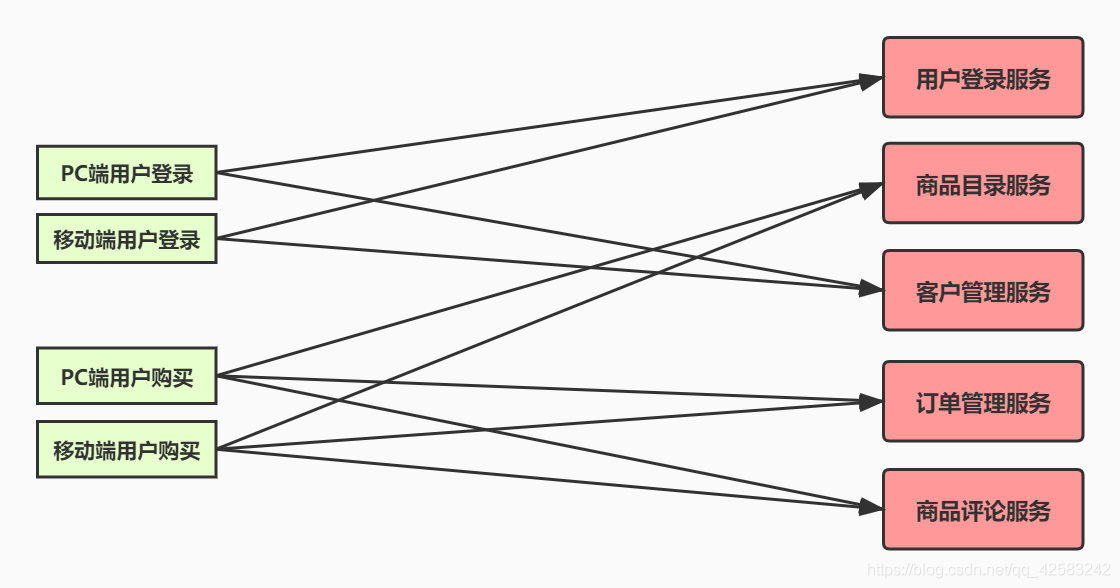
這樣進行拆分的話,當其中一個服務掛掉之后,不會影響其他服務正常對外提供服務
3、Z軸資料磁區
Z 軸擴展通常是指基于請求和用戶獨特的需求,進行系統劃分,并使得劃分出來的子系統相互隔離,但又是完整的
Z軸代表按照客戶、客戶的需要、位置或者價值分割或分配作業指責,一般在超大型系統中,架構設計就會面臨Z軸擴展的需求,
三、基于AKF的Redis集群
Redis 集群模型:

1、水平擴展
既然一臺 Redis 服務行程對外提供服務容易造成單點故障,那就使用多臺服務器,每臺服務器存放的資料相互之間實時同步,保證每臺機器里面的都是全量資料,這樣,當其中一個服務行程實體掛掉之后,其余行程實體能夠繼續對外提供服務
而且既然起了多臺服務,就不要浪費性能,可以讓多個行程實體組成主從關系,實作讀寫分離,減輕單臺主機壓力
2、縱向擴展
使用多臺主機雖然能夠避免單點故障,而且能夠組成讀寫分離,減輕單臺服務器接收全部請求的壓力,但是每臺服務器都是保存的全量資料,當系統膨脹,資料量變大之后容量仍然是一個問題
此時我們可以把資料按照不同的功能進行劃分,不同業務的資料保存在不同的服務行程,對外只提供此業務功能,這樣每臺服務就不需要保存全量資料,解決單臺服務容量有限的問題,而且根據功能可以讓請求打到不同的服務器,減輕單臺服務器接收過多請求的壓力
四、集群的問題——資料一致性
雖然水平擴展能夠解決單點故障的問題,但是每臺機器中都需要進行資料同步,當主服務器接收到修改資料請求時,各個從屬服務器也需要進行資料修改,保證資料一致性
保證資料一致性,可以分為以下情況
1、強一致性
強一致性:使用同步阻塞方式,所有節點阻塞直到資料全部一致
強一致性一直是企業所追求的情況,但是成本極其高昂,而且容易造成服務不可用

總結:強一致性容易破壞可用性,與我們使用集群解決單點故障的初衷背道而馳,不可取
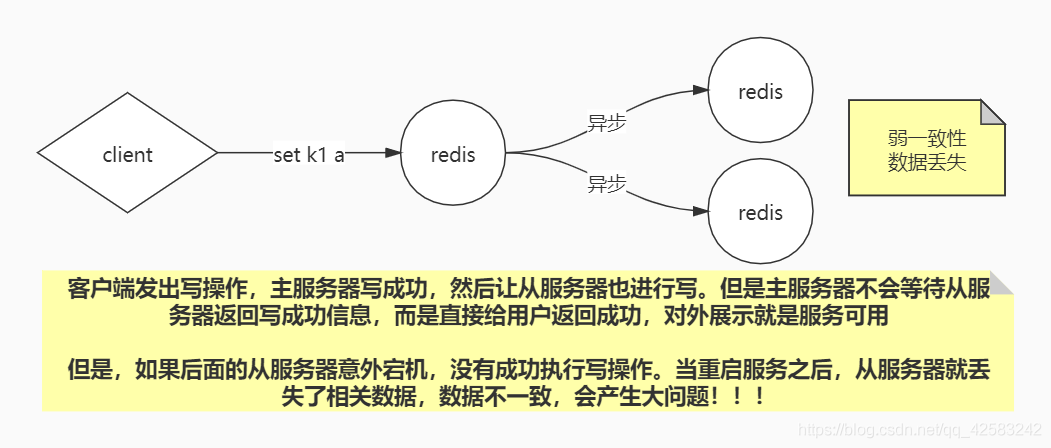
2、弱一致性
弱一致性:使用異步方式,主服務器不需要等待從服務器執行結果,就可以給客戶端回應成功
弱一致性會造成資料丟失,資料不一致會產生大問題
3、最終一致性
最終一致性:在主從之間通過一個可靠的訊息組件,實作資料最終一定會一致
最終一致性可以有多種實作方式,如 kafka 等訊息佇列,但是在資料實作最終一致性之前,有可能請求到的資料并非最新的資料

這一種看起來還不錯,但是 Redis 也并沒有采用這種方式
Redis 最大的特點就是快,玩命的給客戶提供最快的回應速度,所以一定要盡量的減少技術的整合
本篇文章只是通過講解 Redis 單機會出現什么問題,來引出為什么需要搭建 Redis 集群,Redis 集群內容很多,如果在本篇文章中講解就會顯得主次不分,內容冗長,所以我們在后面的文章中將會通過以下兩個方面來詳細介紹 Redis 集群:
- X軸水平擴展:對 master 做HA高可用,解決單點故障問題
- Y軸縱向擴展:通過集群對資料進行分治,解決單臺機器容量有限問題
關聯文章:
Redis入門–萬字長文詳解epoll
Redis——詳解五種資料結構
Redis——Redis的進階使用(管道/發布訂閱/事務/布隆過濾器)
Redis——Redis用作快取(記憶體回收/穿透/擊穿/雪崩)
Redis——Redis用作資料庫(持久化/RDB/AOF)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/156236.html
標籤:其他
上一篇:關于OPNET14.5自帶的HLA Tutorial
下一篇:s1ap信令如何決議?