全面理解矩陣分解MF在推薦系統中的應用
那么,這是本系列的第二篇文章,討論的是關于第一篇協同過濾之后的改進演算法矩陣分解(MF),我會從多個方面討論該演算法的與案例以及它的優缺點,矩陣分解并不是某一種單一的方法,雖然我們最常用的是其中的梯度下降法,但是你會發現在我們之前學習的線性代數中有很多技術可以拿來實作矩陣分解,比如特征值分解ED和奇異值分解SVD,只不過這兩種方法都有自己的不足而無法滿足實際推薦系統的需要,我會在下文中說明為什么歷史選擇了梯度下降法,其實,我發現我在上一節最后一部分給出的案例代碼當中寫的其實不是單純的協同過濾系統,而是結合了SVD奇異值分解去分解協同過濾共現矩陣的改進版協同過濾,大家可以結合來看看,案例本身是模仿自《機器學習實戰》這本書,不過,我們主要還是針對在推薦系統中的應用來去解釋MF的主流方法為主,
問題引入
在很多情況下,資料中的一小段攜帶了資料集中的大部分資訊,而其他資訊要么是噪聲,要不就是不相關的一些資訊,所以我們把目光頭像了矩陣分解領域,在線性代數中還有很多矩陣分解技術,矩陣分解可以將原始矩陣表示成新的易于處理的形式,這種新的形式將是兩個或多個矩陣的乘積的形式,我們可以用代數中的因子分解來類比理解這個概念,比如我想分解數字12,那么(2,6)(3,4)(1,12)都是可以接受的答案,我這里只是想說MF其實有多種方法,但是不同的矩陣分解技術具有不同的性質,其中有些更適合于某個應用,有些則更適合其他應用,
我們在上一篇文章中介紹了協同過濾的不足,協同過濾的頭部效應明顯、泛化能力差,矩陣分解就是針對解決這個問題而被提出的,矩陣分解簡單來說就是在協同過濾演算法中的共現矩陣的基礎上加入了隱向量的概念,加強了模型處理稀疏矩陣的能力,針對性的解決了協同過濾存在的主要問題,
理解矩陣分解的原理
現在我們舉一個例子來幫助我們理解MF的原理,就以視頻網站的推薦場景來作為案例,我們可以通過使用協同過濾和使用矩陣分解兩種方法來進行推薦,通過這個程序感受MF的原理,
首先我們知道其實協同過濾的邏輯非常簡單,演算法找到用戶可能喜歡的視頻是基于用戶觀看歷史的,找到跟目標用戶看過相同視頻的相似用戶,然后找到這些相似用戶喜歡看的其他視頻推薦給目標用戶,
而矩陣分解演算法則期望為每一個用戶和視頻生成一個隱向量,將用戶和視頻定位到隱向量的標識空間上,距離相近的用戶和視頻表明興趣特點接近,在推薦程序中應該講距離相近的視頻推薦給目標用戶,舉個例子:
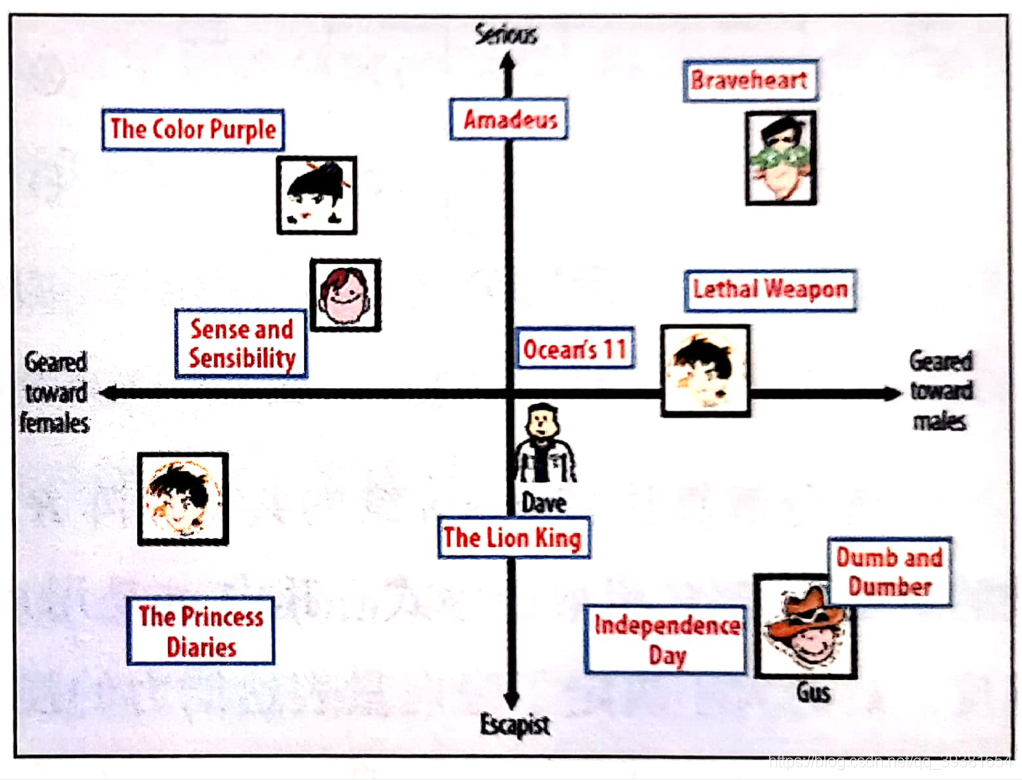
如果希望給圖中坐標原點出的Dave推薦視頻,那么可以發現離Dave最近的兩個視頻分別是《The Lion King》和《Ocean’s 11》那么可以根據向量距離由近及遠的生成推薦串列,
用隱向量去表達用戶和物品,還要保證相似的用戶及用戶可能喜歡的物品的距離相近,實用的方法就是MF,在MF的框架中,用戶和物品的隱向量是通過分解共現矩陣得到的:

矩陣分解演算法將m*n維的共現矩陣R分解為m*k維的用戶矩陣U和k*n維的物品矩陣V相乘的形式,其中m為用戶的數量,n為物品的數量,k是隱向量維度,K的大小決定了隱向量表達能力的強弱,k的取值越小,隱向量包含的資訊就越少,相對來講泛化能力就越高;反之k取值越大,隱向量的表達能力越強,但泛化能力相對降低,但并不是說刻意為了追求高的泛化能力而去降低k的維度,這是沒有意義的,因為那樣推薦效果也會下降,通常k的取值是在實驗的程序中折中取值的,以此來保證推薦效果和工程開銷能保持平衡,
既然我們現在已經實作了分解,那么該如何計算得分rui呢(用戶u對物品i的預估評分),公式如下:
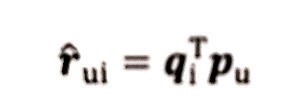
其中pu是用戶u在用戶矩陣U中對應行向量,qi是物品i對應物品矩陣中的列向量,
矩陣求解的方法分類
矩陣求解的方法常見的方法有三種:特征值分解,奇異值分解和梯度下降方法,
根據之前的學習我們知道,特征值分解只能針對方陣來進行,但是我們的實際推薦系統中的共現矩陣用戶的數量往往遠遠大于物品的數量,所以幾乎不可能出現方陣,所以顯然我們不能選擇特征值分解的方法來分解矩陣,
而奇異值分解相對來說就可以解決了,而且我們在機器學習階段也學習過還比較熟悉,SVD的核心是將任意矩陣表示為三個矩陣相乘的形式,即M=UΣVT,其中,U和V分別是兩個m階和n階的正交陣,Σ則是一個m*n的近似對角陣(因為不是方陣),對角陣的元素值即包含著原始共現矩陣特征的隱特征,截斷奇異值分解可以取Σ近似對角陣的前k個隱特征(認為前K個奇異值包含9成以上的資訊),拋棄其他維度的特征來完成分解,可以說奇異值分解幾乎完美的實作了我們剛剛解釋的MF的原理,事實上,SVD也有著它的缺陷,最致命的兩個缺陷直接導致SVD也不是適合應用到推薦系統中來的MF方法:
- 奇異值分解對于稠密的共現矩陣分解結果是很好的,但是現實是,大部分需要用到推薦的場景中,用戶-物品共現矩陣的密度是很稀疏的,這與奇異值分解的應用條件相悖,如果想要應用奇異值分解就必須對缺失的元素進行填充,這也無疑加大了作業量,
- SVD的計算復雜度是非常高的,它的計算復雜度能夠達到O(m*n2)的水平,這對于商品數量動輒上百萬,用戶千萬級的系統來說是無法容忍的,
所以根據以上兩個問題,SVD也不適用于大規模的系數矩陣分解問題,小規模的像我們上一節使用的資料集規模還是可以的,因此,梯度下降法成了MF的主要方法,這里對其進行主要介紹(但也是基于實際場景進行闡述的),
梯度下降法的優化程序
我們剛才在講述MF原理的時候給出了它的得分函式rui的運算式,所以現在我們可以去定義一個新的目標函式形式出來用于優化:
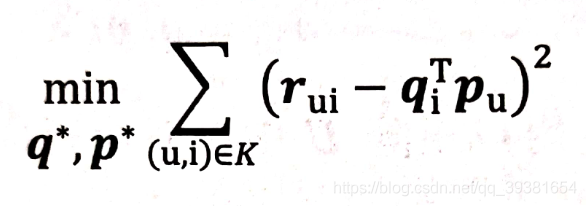
該目標函式的目的是為了讓原始評分rui與用戶向量和物品向量之積qiTpu的差盡量小,這樣才能最大限度的保留共現矩陣的有效資訊,其中K代表的是所有用戶評分樣本的集合,也就是共現矩陣的全部,
但是我們根據以前的優化經驗就知道,這個形式的目標函式是會發生過擬合的,他缺少正則化項的參與,(在這里簡單說明一下:對于加入了正則化的損失函式來說,模型權重的值越大,損失函式越大,但是梯度下降的方向是朝著Loss小的方向發展的,因此正則化項的實際作用是希望在盡量不影響原模型與資料集之間損失表達的前提下,使模型的權重變小,權重的減小自然會讓模型的輸出波動更小,即降低了過擬合的發生可能,而擬合效果越好,模型的泛化能力越強,這也是優化的主要目標之一,)所以,現在為剛才我們的定義好的目標函式加上正則化項:
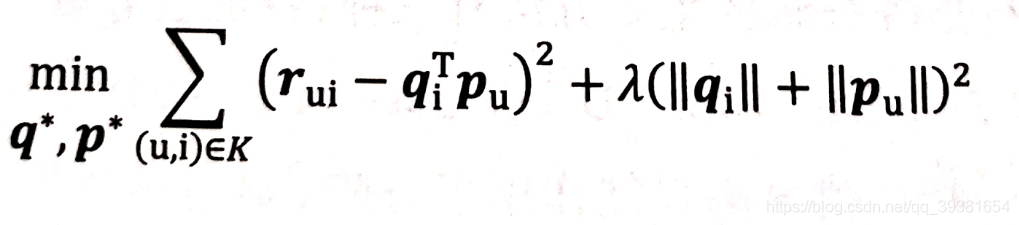
然后我們后續的作業就是使用我們的老朋友,梯度下降法對目標損失函式進行迭代優化,直到目標函式收斂為止,而梯度下降的核心實際就是求偏導數,來取得梯度下降的方向和幅度,

利用求偏導的結果沿梯度的反方向對引數進行更新:(γ是學習率)
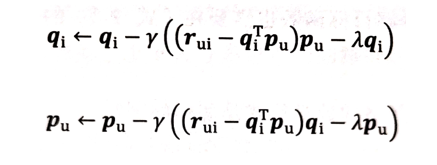
迭代上述步驟不斷更新引數,知道迭代次數超過設定上限或者損失函式收斂為止,
優化結果分析
在完成矩陣分解之后,既可以得到所有用戶和物品的隱向量,在對某用戶進行推薦時,可利用該用戶的隱向量與所有物品的隱向量進行逐一的內積運算來計算出該用戶對所有物品的評分預測,根據評分的高低排序取得TopN推薦序列,
可以看出在矩陣分析演算法中,由于隱向量的存在,使得任意用戶和物品之間都可以預測分值,而通過剛才的程序也可以知道,矩陣分解產生隱向量的程序其實就是對協同過濾共現矩陣的全域擬合程序,因此隱向量是可以囊括全域資訊的,卻有著更強大的泛化能力,
而對于協同過濾來說,如果兩個用戶沒有相同的歷史行為,兩個物品沒有共同的人購買,那么這兩個用戶和兩個物品的相似度就都為0,因此,協同過濾CF不具備泛化利用全域資訊的能力,他只能通過利用用戶和物品自己的資訊進行相似度計算,
方法改進(消除用戶和物品打分的偏差)
在《深度學習推薦系統》中還有一種對MF的改進方案,事實上我在之前的學習中也沒有關注到這一點,那就是,我們在進行矩陣分解的程序中,用戶事實上是有著不同的打分體系的(比如:在5分為滿分的情況下,有的用戶認為3分就是很低的分數了,而有的用戶認為1分才是差評),同理,不同的物品衡量標準也有所不同(電資產評的平均分he日用品的平均分顯然差異會很大),那么我們如何應對這種問題呢(這里要學習思想,因為這個問題不僅MF會需要處理,任何時候我們都要更多地去考慮用戶的心理才能開發出好的系統)
為了消除用戶和物品打分偏差bias,我們通常做法是在矩陣分解時加入用戶和物品的偏差向量,這個偏差可以包含一些均值資訊,比如我們剛才總結的打分函式,現在就可以變化一下:
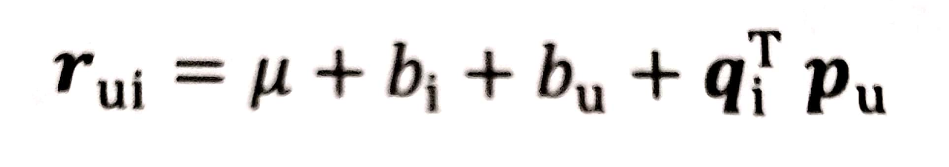
其中,μ是全域偏差常熟,bi是物品偏差系數(可使用物品i收到的所有評分的均值來表達)同理,bu是用戶偏差系數(可使用用戶u給出的所有評分的均值)
當然,這樣一來損失函式也要變化了:
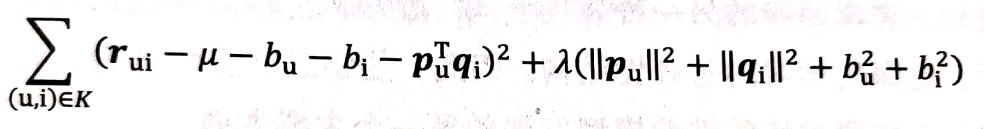
加入了打分偏差項之后,MF得到的隱向量就能更好地反映不同用戶對不同產品的真實態度差異,事實上就是綜合了更多的全域均值因素,去減少因為差異所帶來的噪聲,這樣可以更好的去捕捉和評價資料中有價值的資訊,避免推薦結果產生偏差,
矩陣分解的優勢和局限性
這里討論優勢的話肯定是針對CF來說的,畢竟MF的產生就是為了解決CF的缺陷:
- 首先,泛化能力相對于CF大大增強,MF在一定程度上解決了資料稀疏的問題,
- 其次,空間復雜度相對要低,因為通過分解,我們得到了隱向量的概念表示,因此CF中需要維護的巨大的相似性矩陣可以舍棄掉了,空間復雜度大大降低,
- 最后,MF有著更好的可擴展性和靈活性,矩陣分解自重產出的是User-Item隱向量,這其實與深度學習中的Embedding思想類似,因此矩陣分解的結果非常適合與其他特征進行組合拼接,并且便于深度學習網路的結合,
關于局限性,也很明顯,MF同樣不容易考慮用戶物品以及背景關系的資訊,這使得矩陣分解喪失了利用很多有效資訊的機會,同時在缺乏用戶歷史行為時,無法進行有效推薦(盡管,在這一點上比CF要好很多),
為了解決這些問題,邏輯回歸模型以及后續發展出來的FM,FMM憑借其天然的融合不同特征的能力,主鍵在推薦系統領域得到更廣泛的應用,關于這些模型,將在稍后的文章中繼續介紹,
延伸閱讀
文章撰寫的程序中參考了一下前輩的博客給出了很多MF的延伸研究,有興趣的話可以研究一下這幾篇論文:(參考自 - https://blog.csdn.net/qq_23968185/article/details/70477613)
一、基于投影梯度法的非負矩陣分解
論文:Projected gradient methods for non-negative matrix factorization
代碼:Matlab及Python原始碼
二、基于類牛頓法的最小二乘矩陣近似解法
論文:Fast Newton-type Methods for the Least Squares Nonnegative Matrix Approximation Problem
PPT:https://www.niss.org/sites/default/files/Dhillon_workshop.pdf
三、基于alternating nonnegative least squares(ANLS)框架的一種NMF分解方法
論文:Toward Faster Nonnegative Matrix Factorization: A New Algorithm and Comparisons
四、 active-set-like演算法求解NMF
論文: Fast nonnegative matrix factorization: An active-set-like method and comparisons
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/159576.html
標籤:其他
下一篇:??CSDN快速漲粉秘笈??