人工智能的本質就是最優化,假設把任務比作是一碗飯,
傳統的解決方法,就是根據數學公式,然后一口氣吃完飯,如果飯碗小,數學公式還行,如果飯碗大,數學公式能一口吃完飯嗎?
人工智能的本質就是最優化,得益于有很多優化演算法,優化演算法等于是一口一口吃飯,再大的飯碗,再多的飯,也能干,
本文以一元線性回歸為例,
通過代碼來感受下神經網路的優化演算法,
一.梯度下降演算法SGD
梯度下降是一種非常通用的優化演算法,
假設在濃霧下,你迷失在了大山中,你只能感受到自己腳下的坡度,為了最快到達山底,最好的方法就是沿著坡度最陡的地方下山,這就是梯度下降,它計算誤差函式關于引數θ 的區域梯度,同時它沿著梯度下降的方向進行下一次迭代,當梯度值為0的時候,就達到誤差函式最小值,
具體來說,開始時,需要指定一個隨機的θ ,然后逐漸去改進它,每次變化一小步,每一次都試著降低損失函式,直到演算法收斂到一個最小值,
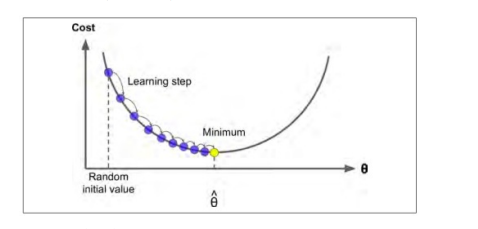
在梯度下降中一個最重要的引數就是步長,也叫學習率
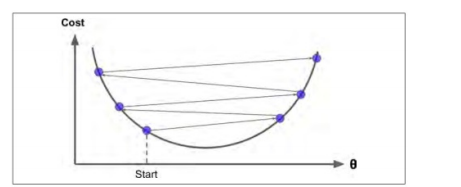
如果學習率太小,則需要多次迭代才能達到最小值,
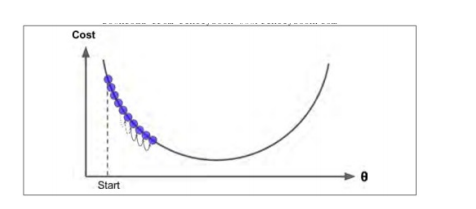
如果學習率太大,可能跳過最小值,很難收斂,
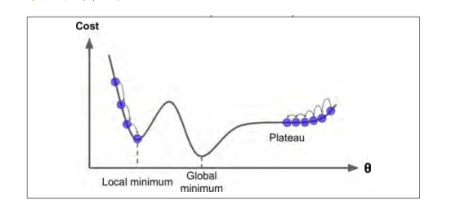
并不是所有的損失函式都是一個V型,有的像山脊等各種不規則地形,如果早早地結束訓練可能會陷入區域最小值,所以這時需要指定訓練輪數,當輪數過大,才有可能得到全域最小值,
線性目標函式為
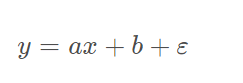
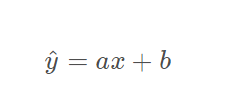
線性回歸損失函式為
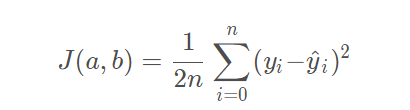 優化函式
優化函式
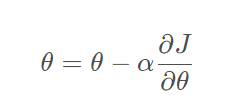 對于一元線性回歸的優化函式為:
對于一元線性回歸的優化函式為:
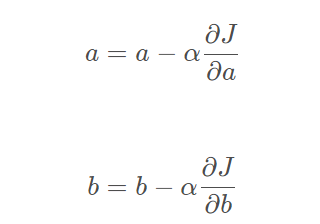

import numpy as np
import matplotlib.pyplot as plt
#定義線性回歸
def model(a, b, x):
return a*x + b
#損失函式
def cost_function(a, b, x, y):
n = 5#5個樣本,后面舉例的資料為5個樣本
return 0.5/n * (np.square(y-a*x-b)).sum()
#梯度下降
#梯度下降
def sgd(a,b,x,y):
n = 5#5個樣本
alpha = 1e-1
y_hat = model(a,b,x)#預測值
da = (1.0/n) * ((y_hat-y)*x).sum()
db = (1.0/n) * ((y_hat-y).sum())
a = a - alpha*da
b = b - alpha*db
return a, b
#定義資料 5個樣本
x=np.array([1,2,3,4,5])
y=np.array([2.1,4.2,5.9,7.8,10.2])
def train():
# 初始化引數
a = np.random.random()
b = np.random.random()
n_iterations = 10000 # 輪數
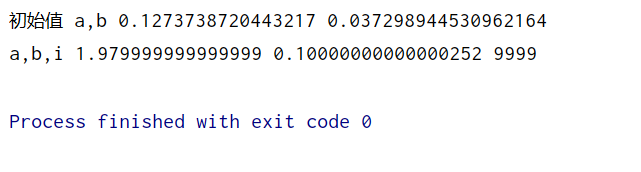
print('初始值 a,b', a, b)
for i in range(n_iterations):
a, b= sgd(a, b, x, y)
cost=cost_function(a,b,x,y)
if np.abs(cost)<0.01:
break
return a,b,i
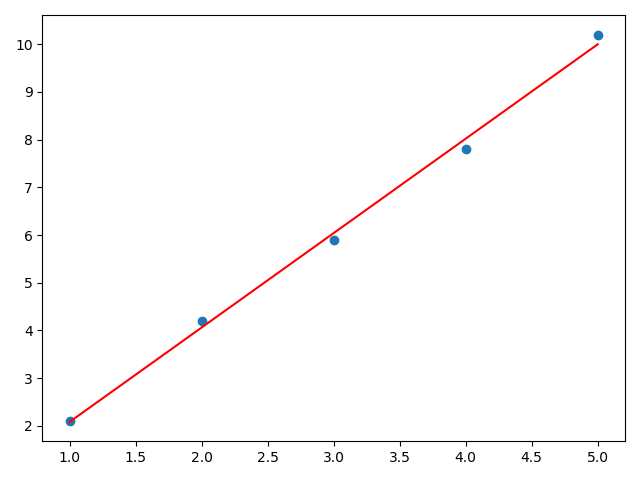
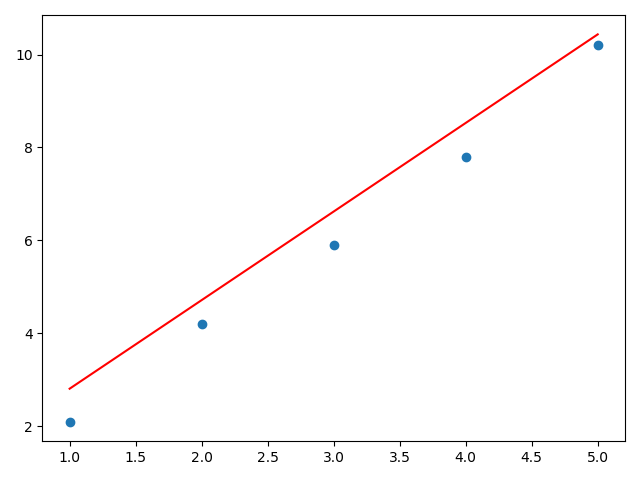
a,b,i=train()
print('a,b,i',a,b,i)
y1=np.dot(x,a)+b
plt.scatter(x,y)
plt.plot(x,y1,color='red',)
plt.show()
二.動量優化Momentum
梯度下降演算法只是通過直接減去損失函式J(θ)相對于θ的梯度,乘以學習率η來更新權重θ,方程是θ=θ-η?J(θ),它不關心早期的梯度是什么,如果區域梯度很小,則會非常緩慢,
動量優化Momentum很關心之前的梯度,在每次迭代時,它將動量矢量m(乘以學習率β)與區域梯度相加,并通過簡單地減去或加上該動量矢量來更新權重,換句話講,梯度作用于加速度,不作用于速度,人為引入了一個初速度βm,
公式為
 其中的β類似于摩擦系數,一般取0.9,m為動量,
其中的β類似于摩擦系數,一般取0.9,m為動量,
import numpy as np
import matplotlib.pyplot as plt
#定義線性回歸
def model(a, b, x):
return a*x + b
#損失函式
def cost_function(a, b, x, y):
n = 5#5個樣本,后面舉例的資料為5個樣本
return 0.5/n * (np.square(y-a*x-b)).sum()
#動量優化
def nesterov(a, b, ma, mb, x, y):
n = 5#5個樣本
alpha = 1e-1
beta = 0.1
y_hat = model(a,b,x)
da = (1.0/n) * ((y_hat-y)*x).sum()
db = (1.0/n) * ((y_hat-y).sum())
ma = beta*ma + alpha*da#動量矢量,其中beta*ma 控制速度,alpha*da控制加速度
mb = beta*mb + alpha*db#動力矢量
a = a - ma#權重引數更新
b = b - mb#權重引數更新
return a, b, ma, mb
#定義資料 5個樣本
x=np.array([1,2,3,4,5])
y=np.array([2.1,4.2,5.9,7.8,10.2])
def train():
# 初始化引數
a = np.random.random()
b = np.random.random()
n_iterations = 10000 # 輪數
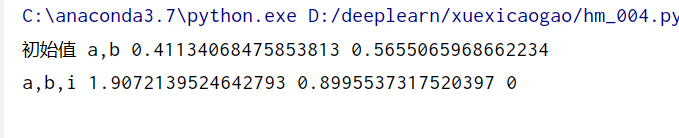
print('初始值 a,b', a, b)
for i in range(n_iterations):
a, b, ma, mb = nesterov(a, b, 0.9, 0.9, x, y)
cost=cost_function(a,b,x,y)
if np.abs(cost)<1:
break
return a,b,i
a,b,i=train()
print('a,b,i',a,b,i)
y1=np.dot(x,a)+b
plt.scatter(x,y)
plt.plot(x,y1,color='red',)
plt.show()
ma = betama + alphada#動量矢量,其中betama 控制速度,alphada控制加速度
合理選擇速度
資料量大還行,資料量小我感覺效果不如梯度下降
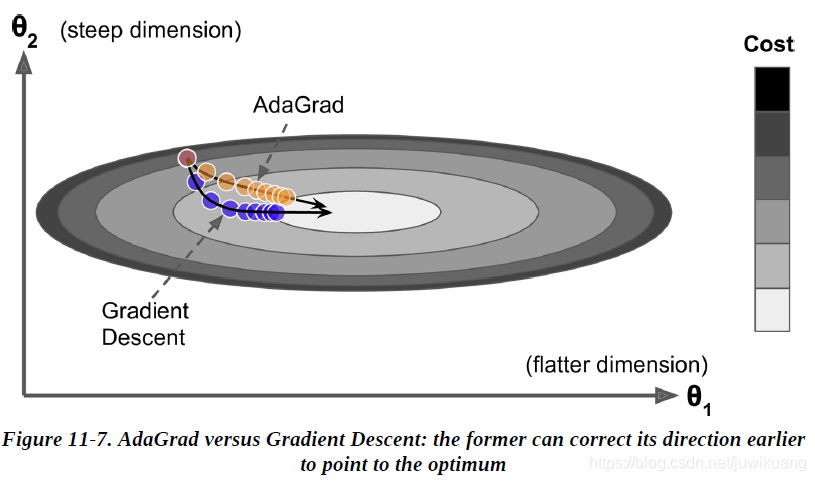
三.AdaGrad
在圖中,藍色的為梯度下降,它朝著梯度最大的方向快速前進,而不是朝著全域最后前進,黃色的是AdaGrad,它指向的是全域最優,它的辦法是縮小(scaling down)最大的梯度引數,

import numpy as np
import matplotlib.pyplot as plt
#定義線性回歸
def model(a, b, x):
return a*x + b
#損失函式
def cost_function(a, b, x, y):
n = 5#5個樣本,后面舉例的資料為5個樣本
return 0.5/n * (np.square(y-a*x-b)).sum()
#ada_grad
def ada_grad(a,b,sa, sb, x,y):
epsilon=1e-10
n = 5#5個樣本
alpha = 1e-1
y_hat = model(a,b,x)
da = (1.0/n) * ((y_hat-y)*x).sum()
db = (1.0/n) * ((y_hat-y).sum())
sa=sa+da*da + epsilon
sb=sb+db*db + epsilon
# da,db隨著輪數變小,sa,sb大趨勢隨著輪數變大
a = a - alpha*da / np.sqrt(sa)
b = b - alpha*db / np.sqrt(sb)
return a, b, sa, sb
#定義資料 5個樣本
x=np.array([1,2,3,4,5])
y=np.array([2.1,4.2,5.9,7.8,10.2])
def train():
# 初始化引數
a = np.random.random()
b = np.random.random()
n_iterations = 10000 # 輪數
print('初始值 a,b', a, b)
for i in range(n_iterations):
a, b, sa, sb = ada_grad(a, b, 0.9, 0.9, x, y)
cost=cost_function(a,b,x,y)
if np.abs(cost)<0.1:
break
return a,b,i,sa,sb
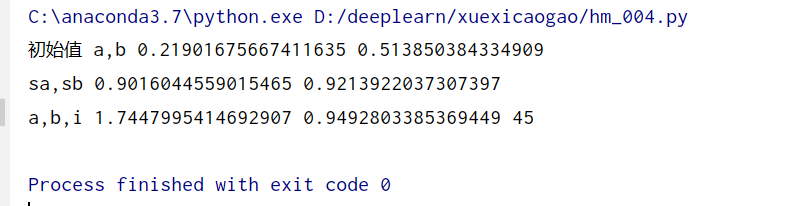
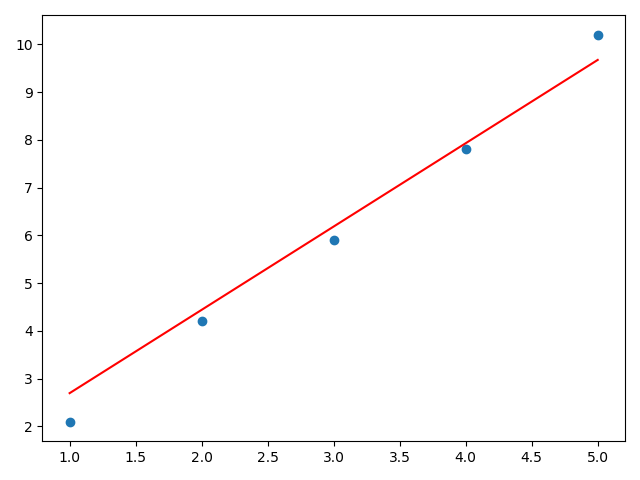
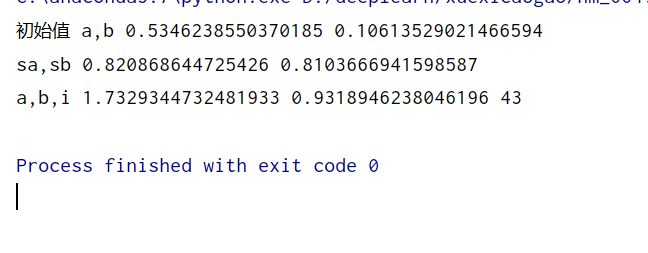
a,b,i,sa,sb=train()
print('sa,sb',sa,sb)
print('a,b,i',a,b,i)
y1=np.dot(x,a)+b
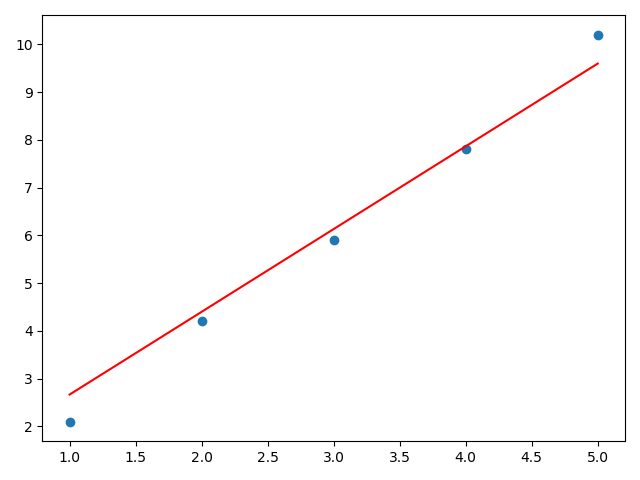
plt.scatter(x,y)
plt.plot(x,y1,color='red',)
plt.show()
決議:
sa=sa+dada + epsilon,sb=sb+dbdb + epsilon 會隨著輪數越來越大,然后導致學習率1/ np.sqrt(sa) 越來越小,權重更新得越慢,即開始時學習率比較大,后面學習率較小,學習率一直在變,是一種自適應學習率,
四.RMSProp
盡管AdaGrad的速度變慢了一些,并且從未收斂到全域最優,
AdaGrad 權重更新,學習率累積的時訓練以來的所以梯度(sa累積的是所有的da,sb累積的是所有的db)
AdaGrad 中
sa=sa+dada + epsilon
sb=sb+dbdb + epsilon
a = a - alphada / np.sqrt(sa)
b = b - alphadb / np.sqrt(sb)
da,db總體上會隨著輪數越來越小,,sa,sb隨著輪數變大
1/ np.sqrt(sa),1/ np.sqrt(sb) 學習率隨著輪數變小,容易陷入區域最小值,(因為當它區域最小值附近時,da小,學習率也小,很難爬出小凹谷)
RMSProp 通過僅累積最近迭代的(da,db)的梯度來修正這個問題,它通過在第一步中使用指數衰減來實作,
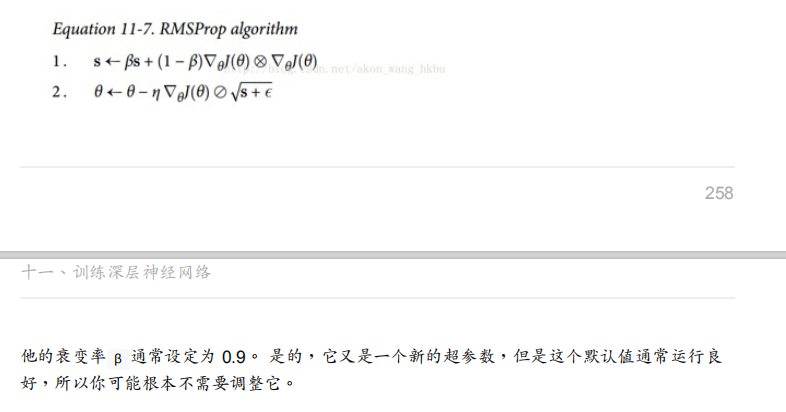
相比于AdaGrad ,RMSProp就是在AdaGrad基礎上級訓學習率[1 / np.sqrt(sa) 和1/ np.sqrt(sb) ]的變化,
import numpy as np
import matplotlib.pyplot as plt
#定義線性回歸
def model(a, b, x):
return a*x + b
#損失函式
def cost_function(a, b, x, y):
n = 5#5個樣本,后面舉例的資料為5個樣本
return 0.5/n * (np.square(y-a*x-b)).sum()
#rmsprop
def rmsprop(a,b,sa, sb, x,y):
epsilon=1e-10
beta = 0.9
n = 5#本文5個樣本資料
alpha = 1e-1
y_hat = model(a,b,x)
da = (1.0/n) * ((y_hat-y)*x).sum()
db = (1.0/n) * ((y_hat-y).sum())
sa=beta*sa+(1-beta)*da*da + epsilon
sb=beta*sb+(1-beta)*db*db + epsilon
#da,db會隨著輪數越來越小,sa,sb,大趨勢變小
a = a - alpha*da / np.sqrt(sa)
b = b - alpha*db / np.sqrt(sb)
return a, b, sa, sb
#定義資料 5個樣本
x=np.array([1,2,3,4,5])
y=np.array([2.1,4.2,5.9,7.8,10.2])
def train():
# 初始化引數
a = np.random.random()
b = np.random.random()
n_iterations = 10000 # 輪數
print('初始值 a,b', a, b)
for i in range(n_iterations):
a, b, sa, sb = rmsprop(a, b, 0.9, 0.9, x, y)
cost=cost_function(a,b,x,y)
if np.abs(cost)<0.1:
break
return a,b,i,sa,sb
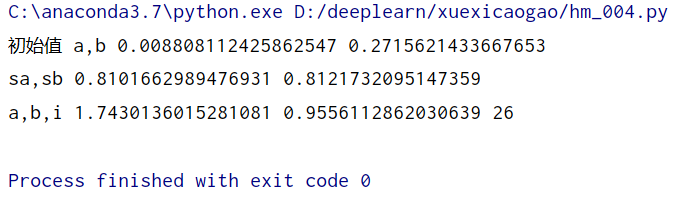
a,b,i,sa,sb=train()
print('sa,sb',sa,sb)
print('a,b,i',a,b,i)
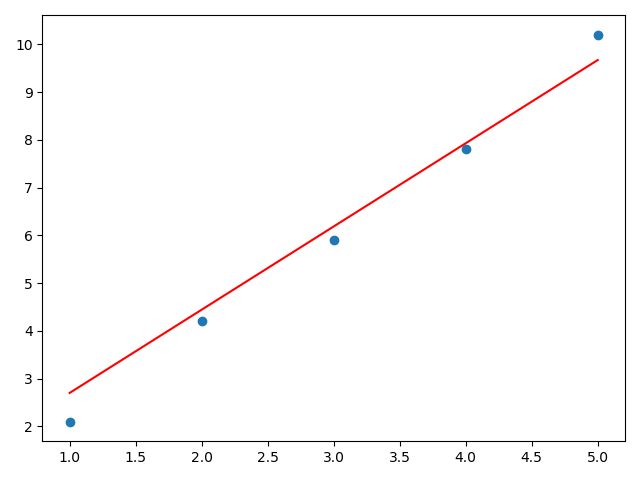
y1=np.dot(x,a)+b
plt.scatter(x,y)
plt.plot(x,y1,color='red',)
plt.show()
決議
sa=betasa+(1-beta)dada + epsilon. beta=0.9,現在=0.9以前的+0.1的現在梯度,
sa=betasa+(1-beta)dada + epsilon
sb=betasb+(1-beta)dbdb + epsilon
#da,db總體上會隨著輪數越來越小,sa,sb,大趨勢變小,學習率1 / np.sqrt(sa)變大
a = a - alphada / np.sqrt(sa)
b = b - alpha*db / np.sqrt(sb)
當處于區域最小值附近時,學習率足夠大,容易爬出小凹谷,
五.Adam
簡而言之,Adam使用動量和自適應學習率來加快收斂速度,
Momentum (動量)
在解釋動量時,研究人員和從業人員都喜歡使用比球滾下山坡而向區域極小值更快滾動的類比法,但從本質上講,我們必須知道的是,動量演算法在相關方向上加速了隨機梯度下降,如 以及抑制振蕩,
為了將動量引入我們的神經網路,我們將時間元素添加到過去時間步長的更新向量中,并將其添加到當前更新向量中, 這樣可以使球的動量增加一定程度, 可以用數學表示,如下圖所示,
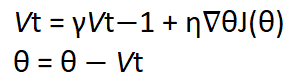
動量更新方法,其中θ是網路的引數,即權重,偏差或激活值,η是學習率,J是我們要優化的目標函式,γ是常數項,也稱為動量, Vt-1(注意t-1是下標)是過去的時間步長,而Vt(注意t是下標)是當前的時間步長,
動量項γ通常被初始化為0.9
適應性學習率
通過將學習率降低到我們在AdaGrad,RMSprop,Adam和AdaDelta中看到的預定義時間表(schedule),可以將自適應學習率視為訓練階段的學習率調整,這也稱為學習率時間表 有關該主題的更多詳細資訊
在不花太多時間介紹AdaGrad優化演算法的情況下,這里將解釋RMSprop及其在AdaGrad上的改進以及如何隨時間改變學習率,
RMSprop(即均方根傳播)其目的是解決AdaGrad的學習率急劇下降的問題, 簡而言之,RMSprop更改學習速率的速度比AdaGrad慢,但是RMSprop仍可從AdaGrad(更快的收斂速度)中受益-數學運算式請參見下圖
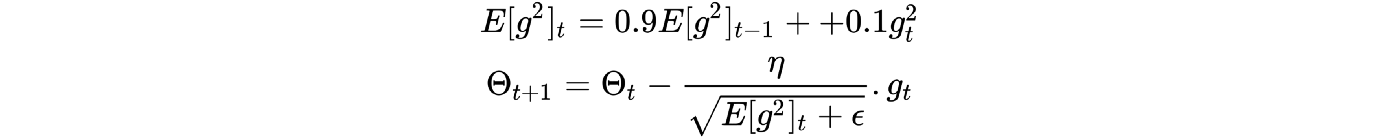
E [g2] t的第一個方程是平方梯度的指數衰減平均值, Geoff Hinton建議將γ設定為0.9,而學習率η的默認值為0.001
這可以使學習率隨著時間的流逝而適應,這很重要,因為這種現象也存在于Adam中, 當我們將兩者(Momentum 和RMSprop)放在一起時,我們得到了Adam

import numpy as np
import matplotlib.pyplot as plt
#定義線性回歸
def model(a, b, x):
return a*x + b
#損失函式
def cost_function(a, b, x, y):
n = 5#5個樣本,后面舉例的資料為5個樣本
return 0.5/n * (np.square(y-a*x-b)).sum()
#Adam
def adam(a, b, ma, mb, sa, sb, t, x, y):
epsilon = 1e-10
beta1 = 0.9
beta2 = 0.9
n = 5#5個樣本
alpha = 1e-1
y_hat = model(a, b, x)
da = (1.0 / n) * ((y_hat - y) * x).sum()#計算梯度a
db = (1.0 / n) * ((y_hat - y).sum())#計算梯度b
ma = beta1 * ma - (1 - beta1) * da#計算動量ma
mb = beta1 * mb - (1 - beta1) * db#計算動量mb
sa = beta2 * sa + (1 - beta2) * da * da#自適應sa
sb = beta2 * sb + (1 - beta2) * db * db#自適應sb
ma_hat = ma / (1 - beta1 ** t)#動量添加指數
mb_hat = mb / (1 - beta1 ** t)#動量添加指數
sa_hat = sa / (1 - beta2 ** t)#自適應添加指數
sb_hat = sb / (1 - beta2 ** t)#自適應添加指數
a = a + alpha * ma_hat / np.sqrt(sa_hat)#權重更新
b = b + alpha * mb_hat / np.sqrt(sb_hat)
return a, b, ma, mb, sa, sb
#定義資料 5個樣本
x=np.array([1,2,3,4,5])
y=np.array([2.1,4.2,5.9,7.8,10.2])
def train():
# 初始化引數
a = np.random.random()
b = np.random.random()
n_iterations = 10000 # 輪數
print('初始值 a,b', a, b)
for i in range(n_iterations):
a, b, ma,mb,sa, sb = adam(a, b, 0.05, 0.05, 0.9,0.9,1000,x, y)
cost=cost_function(a,b,x,y)
if np.abs(cost)<0.1:
break
return a,b,i,sa,sb
a,b,i,sa,sb=train()
print('sa,sb',sa,sb)
print('a,b,i',a,b,i)
y1=np.dot(x,a)+b
plt.scatter(x,y)
plt.plot(x,y1,color='red',)
plt.show()
決議
adam(a, b, ma, mb, sa, sb, t, x, y):
中的ma,mb控制初速度,要不要一來就梯度更新得很快(資料量大時可以考慮較大的ma,mb) 做學習率的分子
sa,sb控制權重更新速度,越大更新越慢,做學習率的分母
本文主要參考文獻如下,感謝大佬,
1.Adam 優化演算法詳解
2.https://blog.csdn.net/juwikuang/article/details/108039680
、、、、、、、、、、、、、、、、、、、、、、、、、、、、
常用優化演算法就這些,還有其他的未列舉,
我也感覺似懂非懂,唉,
電氣工程的計算機萌新:余登武,
寫博文不容易,如果你覺得本文對你有用,請點個贊支持下,謝謝,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/159586.html
標籤:其他
上一篇:教你如何追求女神
下一篇:大資料的簡要介紹