11.1、寫出圖11.3中無向圖描述的概率圖模型的因子分解式,
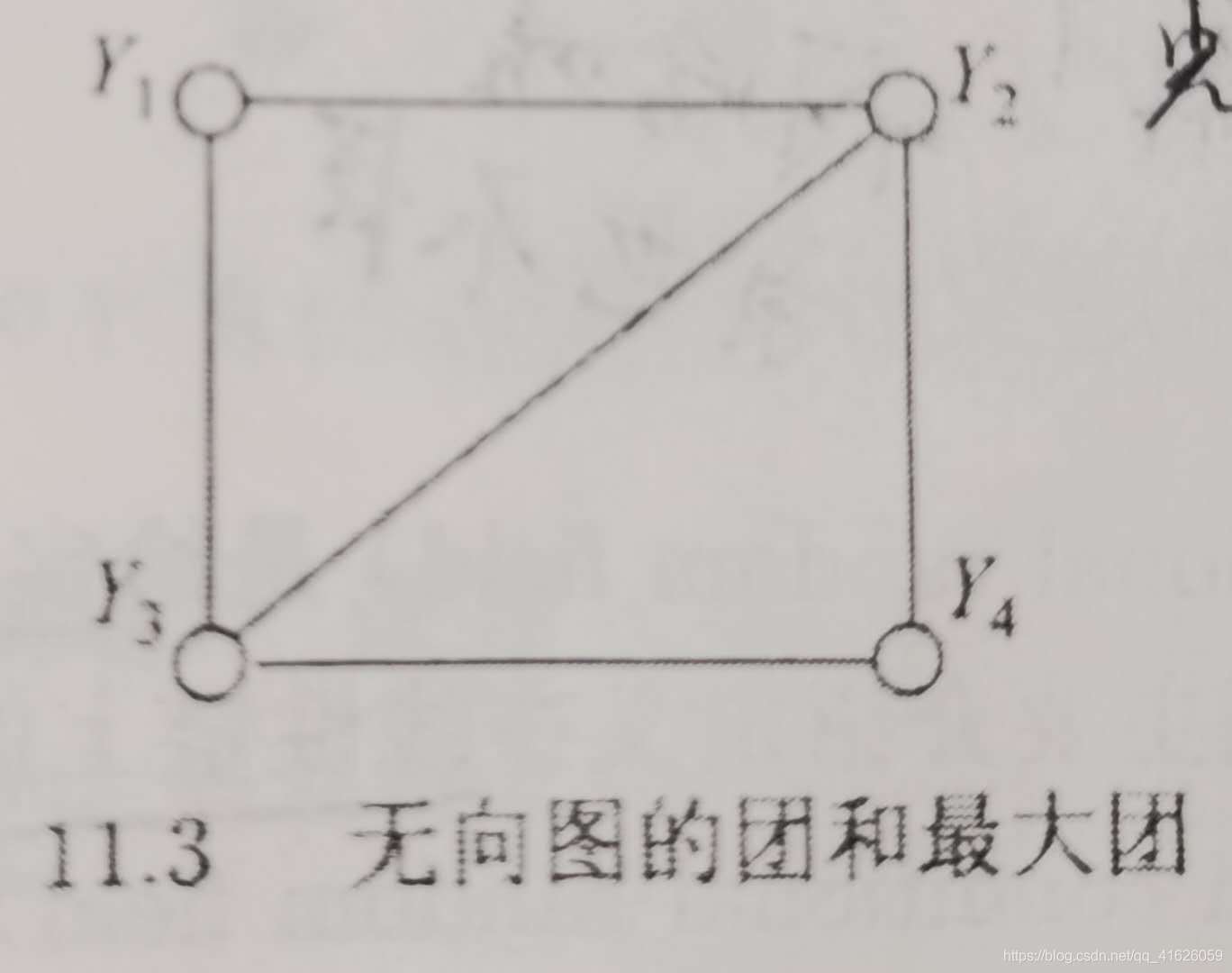
解:根據最大團的定義可知,該最大團共有兩個最大團,李航老師的書上也指了出來,分別是:
c
1
=
(
Y
1
,
Y
2
,
Y
3
)
,
c
2
=
(
Y
2
,
Y
3
,
Y
4
)
c_{1}=(Y_{1},Y_{2},Y_{3}), c_{2}=(Y_{2},Y_{3},Y_{4})
c1?=(Y1?,Y2?,Y3?),c2?=(Y2?,Y3?,Y4?)
那么根據Hammersley-Clifford定理,可以將圖11.3上面的無向圖的聯合概率分布表示為:
P
(
Y
)
=
1
Z
?
Ψ
c
1
(
Y
c
1
)
?
Ψ
c
2
(
Y
c
2
)
P(Y)=\frac{1}{Z}*\Psi _{c_{1}}(Y_{c_{1}})*\Psi _{c_{2}}(Y_{c_{2}})
P(Y)=Z1??Ψc1??(Yc1??)?Ψc2??(Yc2??)
其中:
Z
=
∑
Y
∏
c
Ψ
c
(
Y
c
)
Z=\sum_{Y}\prod_{c}\Psi _{c}(Y_{c})
Z=Y∑?c∏?Ψc?(Yc?)
注:這里求Z的時候應該是對所有可能的Y的取值求和,將P(Y)歸一化,這樣才滿足是概率分布,所有的加起來所得的和是1.比如在詞性標注任務,對這句話:“為中華之崛起而讀書”,假設詞性標簽有N個,那么所有的Y的取值有9的N次方這么多,Z是9的N次方這么多非規范化概率的和,還有個問題可以看到,如果使用暴力方法來求的話,這是個Np難問題,
11.2、證明 Z ( x ) = α n T ? 1 = 1 ? β 1 ( x ) Z(x)=\alpha _{n}^{T}*1=1*\beta _{1}(x) Z(x)=αnT??1=1?β1?(x),其中1表示元素全為1m維列向量,
證明:
看下李航老師書上的Z(x)的一個計算公式:
Z
(
x
)
=
[
M
1
(
x
)
?
.
.
.
?
M
n
+
1
]
s
t
a
r
t
,
s
t
o
p
Z(x)=[M_{1}(x)*...*M_{n+1}]_{start,stop}
Z(x)=[M1?(x)?...?Mn+1?]start,stop?
結合書上面的一個例子:給定一個由圖11.6所示的線性鏈條件隨機場,觀測序列x,狀態序列y,i=1,2,3,標記{1,2},假設y0=start=1,y4=stop=1,各個位置的隨機矩陣為
M
1
(
x
)
=
[
a
01
a
02
0
0
]
M_{1}(x)=\begin{bmatrix} a_{01} & a_{02}\\ 0& 0 \end{bmatrix}
M1?(x)=[a01?0?a02?0?]
M
2
(
x
)
=
[
b
11
b
12
b
21
b
22
]
M_{2}(x)=\begin{bmatrix} b_{11} & b_{12}\\ b_{21}& b_{22} \end{bmatrix}
M2?(x)=[b11?b21??b12?b22??]
M
3
(
x
)
=
[
c
11
c
12
c
21
c
22
]
M_{3}(x)=\begin{bmatrix} c_{11} & c_{12}\\ c_{21}& c_{22} \end{bmatrix}
M3?(x)=[c11?c21??c12?c22??]
M
4
(
x
)
=
[
1
0
1
0
]
M_{4}(x)=\begin{bmatrix} 1 & 0\\ 1& 0 \end{bmatrix}
M4?(x)=[11?00?]
可以計算得上面四個矩陣相乘后得到的矩陣的第一行一列的元素就是Z(x),這也對應(start=1,stop=1),如果將y4=stop=1修改為y4=stop=2,那么對應的第4個隨機矩陣要修改為:
M
4
(
x
)
=
[
0
1
0
1
]
M_{4}(x)=\begin{bmatrix} 0 & 1\\ 0& 1 \end{bmatrix}
M4?(x)=[00?11?]
再將上面的四個隨機矩陣進行連乘的話得到的矩陣的第一行第二個位置就是Z(x).
如果明白了上面這個例子,下面的這個證明就會簡單一點,
還要明白一點矩陣運算的小技巧:如果在一個矩陣的乘上一個(1,0,…,0)的行向量,相當于把這個矩陣的第一行取出來,在矩陣右邊乘這樣的列向量的話就是相當于把第一列取出來,
由遞推公式:
α
i
T
(
x
)
=
α
i
?
1
T
(
x
)
M
i
(
x
)
\alpha _{i}^{T}(x)=\alpha _{i-1}^{T}(x)M_{i}(x)
αiT?(x)=αi?1T?(x)Mi?(x)
可以得到
α
n
T
(
x
)
=
α
0
T
(
x
)
M
1
(
x
)
.
.
.
M
n
(
x
)
\alpha _{n}^{T}(x)=\alpha _{0}^{T}(x)M_{1}(x)...M_{n}(x)
αnT?(x)=α0T?(x)M1?(x)...Mn?(x)
由上面那個矩陣運算的小技巧可以知道,
α
n
T
(
x
)
=
α
0
T
(
x
)
M
1
(
x
)
.
.
.
M
n
(
x
)
\alpha _{n}^{T}(x)=\alpha _{0}^{T}(x)M_{1}(x)...M_{n}(x)
αnT?(x)=α0T?(x)M1?(x)...Mn?(x)表示的是
M
1
(
x
)
.
.
.
M
n
(
x
)
M_{1}(x)...M_{n}(x)
M1?(x)...Mn?(x)的start行,如果將他們使用全1的m維列向量乘積之后就是矩陣
M
1
(
x
)
.
.
.
M
n
(
x
)
M_{1}(x)...M_{n}(x)
M1?(x)...Mn?(x)的(start,stop)位置的元素,因而也就是Z(x).其實結合上面的那個例子很容易理解,我們看到M4隨機矩陣的第一列也就是全1的元素,其實這個是對應的,
感覺這個題目的第二部分可能是有點錯誤的,
由遞推公式
β
i
(
x
)
=
M
i
+
1
(
x
)
β
i
+
1
(
x
)
\beta _{i}(x)=M_{i+1}(x)\beta _{i+1}(x)
βi?(x)=Mi+1?(x)βi+1?(x)可知
β
1
(
x
)
=
M
2
(
x
)
.
.
.
M
n
+
1
(
x
)
β
n
+
1
\beta _{1}(x)=M_{2}(x)...M_{n+1}(x)\beta _{n+1}
β1?(x)=M2?(x)...Mn+1?(x)βn+1?
如果還是使用上面的那個例子具體來驗證的話,算不出正確的結果的,
證明都是類似的,差別不大,
11.3、寫出條件隨機場模型學習的梯度下降演算法,
**解:**李航老師的這本書第231頁上面給出了學習的優化目標函式和他的梯度函式,有了這兩個公式,可以很簡單的寫出梯度下降演算法,梯度下降演算法是優化方法里面最簡單的了估計,
首先,學習的優化目標函式和梯度函式公式為:
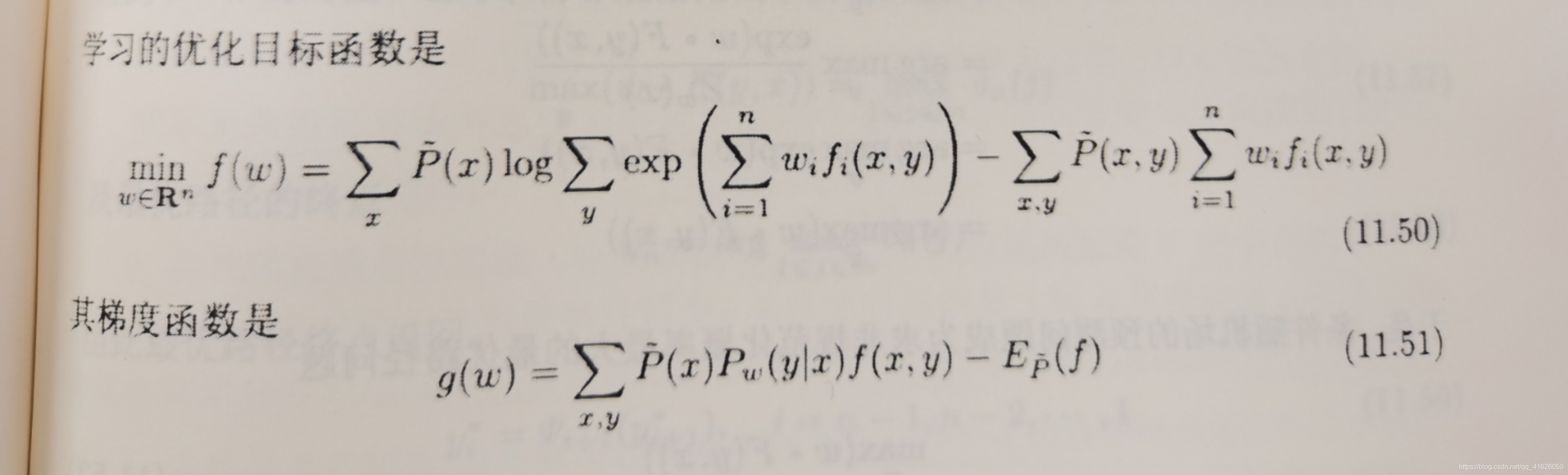
一個需要注意的地方,無論是什么優化方法,下降的方向都要盡量歸一化變為模長為1的單位向量,因為,假如有方向(2,0,3),設定下降步長為2,由于沒有進行下降方向模長歸一化,實際上模型是下降了2*sqrt(13)的步長,會造成模型的不收斂
演算法步驟如下:
輸入:各個特征函式,以及經驗分布;
輸出:最優的引數和最優模型,
(1)選定初始點
w
0
w_{0}
w0?,令k=0,也就是此時
w
k
=
w
0
w_{k}=w_{0}
wk?=w0?
(2)計算梯度
g
k
=
g
(
w
k
)
g_{k}=g(w_{k})
gk?=g(wk?),如果
g
k
=
0
g_{k}=0
gk?=0,停止計算,否則轉入下一步,
(3)進行一維搜索求出最優的下降步長
λ
k
\lambda_{k}
λk?,也就是求解下列的優化問題
f
(
ω
k
?
λ
k
g
k
)
=
m
i
n
λ
>
=
0
f
(
ω
k
?
λ
g
k
)
f(\omega ^{k}-\lambda _{k}g_{k})=min_{\lambda >=0}f(\omega ^{k}-\lambda g_{k})
f(ωk?λk?gk?)=minλ>=0?f(ωk?λgk?)
注:其實在實際實作的時候,我們都是直接預先設定一個固定的步長,或者讓步長隨模型訓練的輪數增加而逐漸減小
(4)令
w
k
+
1
=
w
k
?
λ
k
g
k
w_{k+1}=w_{k}-\lambda_{k}g_{k}
wk+1?=wk??λk?gk?,如果
g
k
+
1
g_{k+1}
gk+1?=0,停止計算,否則令k=k+1,轉步驟(3)
11.4、參考圖11.6的狀態路徑圖,假設隨機矩陣分別為 M 1 ( x ) = [ 0 0 0.5 0.5 ] M_{1}(x)=\begin{bmatrix}0 & 0\\ 0.5& 0.5\end{bmatrix} M1?(x)=[00.5?00.5?] M 2 ( x ) = [ 0.3 0.7 0.7 0.3 ] M_{2}(x)=\begin{bmatrix}0.3 & 0.7\\ 0.7& 0.3\end{bmatrix} M2?(x)=[0.30.7?0.70.3?] M 3 ( x ) = [ 0.5 0.5 0.6 0.4 ] M_{3}(x)=\begin{bmatrix}0.5 & 0.5\\ 0.6& 0.4\end{bmatrix} M3?(x)=[0.50.6?0.50.4?] M 4 ( x ) = [ 0 1 0 1 ] M_{4}(x)=\begin{bmatrix}0 & 1\\ 0& 1\end{bmatrix} M4?(x)=[00?11?],求以start=2為起點,以stop=2為終點的所有路徑的狀態序列y的概率以及概率最大的狀態序列,
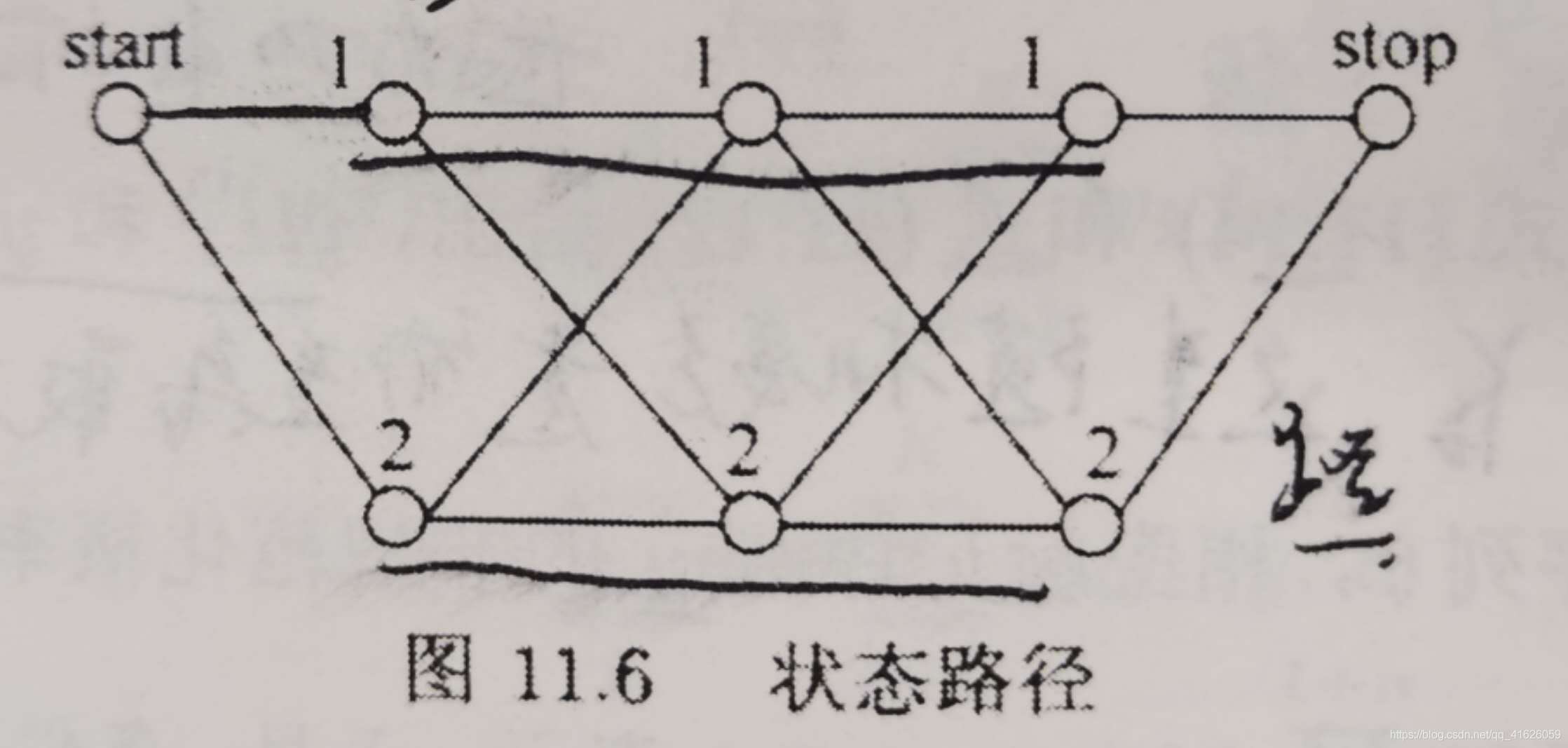
解:
按照暴力求法很容易計算,可以參考李航老師書上的例子11.2,在求的程序中只需要注意一下不同狀態的取值對應的矩陣的元素的行數和列數,這里就簡單舉個例子吧,比如計算路徑start,1,2,1,stop的概率分數,其實也即是2,1,2,1,2的概率大小,
取M1矩陣的(2,1)位置的元素0.5和M2矩陣的(1,2)位置的元素0.7和M3矩陣的(2,1)位置的元素0.6和M4矩陣的(1,2)位置的元素1,乘積可得0.50.70.6*1=0.21
其他的路徑分數也可以類似計算,
其實可以看到,如果序列非常長,這就變成了一個NP難問題,在多項式時間復雜度內是不可以解決的,可以參考動態規劃的計算方法,資料結構里面也有這樣的演算法,數學課運籌學,最優化,圖論等等都會有這樣的計算方法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/159594.html
標籤:其他
上一篇:線性表的論述(Java版)
下一篇:MySQL——Lock鎖