什么是事務?
事務就是滿足 ACID 特性的一組操作,可以用 commit 提交一個事務,也可以用 rollback 回滾事務,
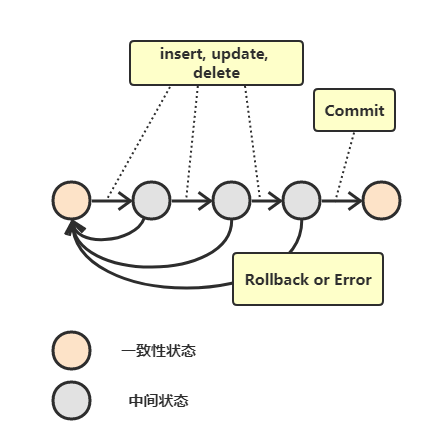
AUTOCOMMIT
MySQL 默認 自動提交模式,也就是說,如果不顯式使用 START TRANSACTION 陳述句來開始一個事務,那么每個查詢都會被當做一個事務自動提交
存盤引擎
MySQL 支持多種存盤引擎,甚至你可以自己寫一個專屬的存盤引擎,可以看一下 MySQL 的多存盤引擎架構
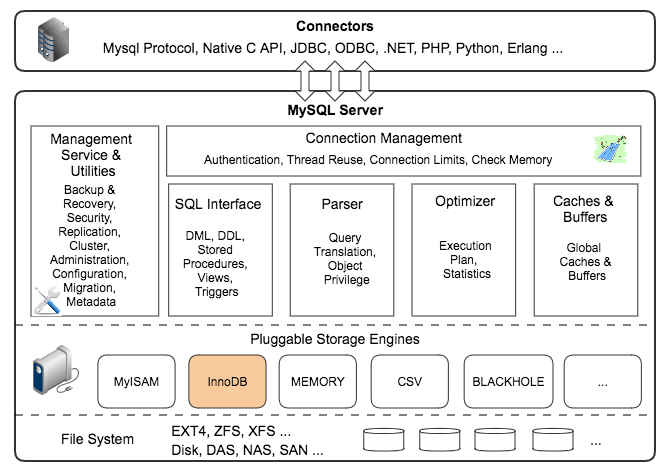
簡介
MySQL 中的資料用各種不同的技術存盤在檔案或記憶體中,這些技術中的每一種技術都使用不同的存盤機制、索引技巧、鎖實作并且最終提供廣泛的不同的功能和能力,通過選擇不同的技術,你能夠獲得額外的速度或者功能,從而改善你的應用的整體功能,存盤引擎其實就是如何存盤資料、如何為存盤的資料建立索引和如何更新、查詢資料等技術的實作方法,
如何選擇引擎?
MySQL 5.5 以前的默認存盤引擎是 MyISAM, 5.5 之后換成了 Innodb,
MyISAM
特性:
- 并發性和鎖級別(只有表鎖,讀鎖和寫鎖互斥)
- 表損壞修復
- 支持全文索引
- 支持表壓縮
應用場景:
- 沒有事務
- 只讀類應用(讀多寫少)
- 空間類應用(唯一支持空間類函式的引擎)
- 做很多 count 的計算(MyISAM 會保存表的行數,不需要掃描,Innodb 沒有保存,需要掃描)
Innodb
特性
- 支持事務
- 完全支持事務的 ACID 特性
- Redo log (實作事務的持久性) 和 Undo log (實作事務的原子性,存盤未完成事務 log, 用于回滾)
- 支持行鎖(通過間隙鎖(GAP)在 RR 級別解決了幻讀的問題)
- 鎖粒度是支持 mvcc(多版本并發控制) 的行級鎖
應用場景
- 可靠性要求比較高,或者要求事務
- 表的更新和查詢都很頻繁,并且行鎖定的機會比較大
問:如何選擇存盤引擎
- 是否需要事務
- Innodb 支持事務,MyISAM 不支持事務
- 可靠性要求
- Innodb 支持完全的 ACID 特性,支持崩潰恢復,而 MyISAM
- 應用場景
- 頻繁讀取,不頻繁插入和更新的場景建議使用 MyISAM
- 讀寫都頻繁,要求事務選擇 Innodb
- 存盤引擎的特性
別的引擎
MySQL 中的引擎只是一個插件,如果技術好且有需要,甚至自己寫一個引擎來使用也是可以的,在這里列舉一些別的引擎,特性就不去看了,以后如果有機會用到再寫
CSV
Archive
Memory
Merge
MaxDB
MySQL 中的資料型別
1、整數
整數包括了 TINYINT、SMALLINT、MEDIUMINT、INT、BIGINT;
占用記憶體空間的情況
| TINYINT | SMALLINT | MEDIUMINT | INT | BIGINT |
|---|---|---|---|---|
| 1 byte | 2byte | 3 byte | 4 byte | 8 byte |
INT(1)、INT(10) 中的數字只是規定顯示字符的個數,但是對于存盤和計算是沒有影響的,
2、浮點數
浮點數包括 FLOAT 和 DOUBLE,還有一個 DECIMAL,是高精度小數型別,可以存比 BIGINT 還大的整數,因為 DECIMAL 是用字串來保存的,,,,
還有關于單精度和雙精度也記錄一下
| 型別 | 符號位 | 指數位 | 小數位 |
|---|---|---|---|
| 單精度 | 1 位 | 8 位 | 23 位 |
| 雙精度 | 1 位 | 11 位 | 52 位 |
3、字串
字串包括 char 和 varchar,區別在于 char 是定長的,而 varchar 是變長的,varchar 會根據實際需要的大小來進行存盤,但是會額外占用一個位元組(長度超過 255 時會占用兩個位元組),
VARCHAR 會保留字串末尾的空格,而 CHAR 會洗掉,
4、時間和日期
datetime 和 timestamp
datetime 與時區無關,而 timestamp 與時區有關
索引
基于Innodb引擎
MySQL 中選擇索引是優化器的作業,如果有多個索引都可以查到資料,優化器會估算使用每個索引的成本然后進行選擇,
如何創建索引?
創建索引有 3 種方式
-
直接創建
create index indexName on tableName(columnName(lenth)); -
在建表的時候創建索引
create table tableName ( id int not null, columnName varchar(16) not null, key indexName (columnName), ); -
修改表結構
alter table tableName add index indexName(columnName);
這里還遇到個小問題,之前一直沒有注意過,原來 MySQL 中有 key 和 index 兩個關鍵字,但是他們其實是一樣的,在官方有介紹:
KEY is normally a synonym for INDEX. The key attribute PRIMARY KEY can also be specified as just KEY when given in a column definition. This was implemented for compatibility with other database systems.
索引的分類
唯一索引
唯一索引是指索引列沒有重復的索引,包括了主鍵索引和其它索引,
主鍵索引
主鍵索引也可以稱作聚簇索引,我們都知道,Innodb 底層是用 B+ 樹實作的,在葉子節點存盤的是資料,并且每一條資料肯定都有對應的鍵,如果在建表的時候沒有指定主鍵索引,MySQL 會自動生成一個自增的主鍵,用一張圖來展示一下資料在主鍵中的存盤情況,
其它
泛指定義為唯一索引但是又不是主鍵索引的索引
創建唯一索引的方式和上面類似,只不過需要多一個 unique 關鍵字,而且 Innodb 引擎允許唯一索引值為 null,
初始化表
mysql> create table T (
ID int primary key,
k int NOT NULL DEFAULT 0,
s varchar(16) NOT NULL DEFAULT '',
index k(k))
engine=InnoDB;
insert into T values(100,1, 'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
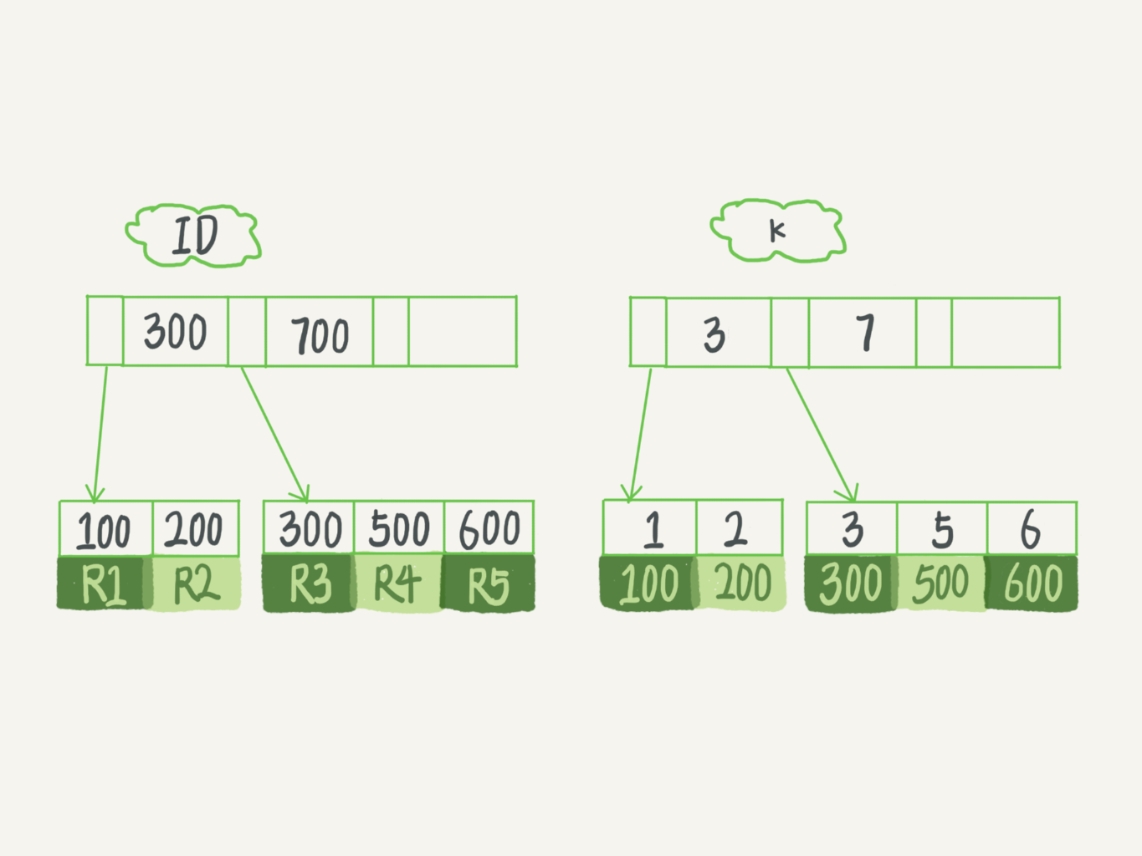
圖片來自極客時間專欄,丁奇老師的《MySQL45講》真的很贊,
如果在上面的表中執行這條陳述句 select * from T where k between 3 and 5 執行流程是怎樣的呢?
- 用 k 索引樹找到 k = 3,得到主鍵索引 ID = 300
- 將 ID = 300 帶回 ID 索引樹查到 R3.
- 再從 k 索引樹找到 K = 5, 對應的 ID = 500
- 回到 ID 索引樹查到 ID = 500 的 R4
- 回到 k 索引樹找下一個 k = 6,不滿足條件,結束查詢
- 統計:查 k 索引樹三次,ID 索引樹 2 次,其中從 k 索引樹取到主鍵的值,再回到主鍵索引樹查詢的程序稱之為回表,
普通索引
普通索引沒有索引列必須唯一的限制,
區別
在查詢的時候,唯一索引和普通索引還是有點區別的,如果使用的是普通索引,那么查詢陳述句會在找到第一個不滿足條件的時候結束查詢,而唯一索引只要找到一個滿足條件就會結束查詢,不過在查詢方面,唯一索引和普通索引的消耗是差不多的,因為在 MySQL 中資料是按頁存盤的,一次讀入一整頁,一頁可以存上千條 key,但是再更新的時候,兩者就有區別了,
覆寫索引
文章開頭創建的索引都是只有一列的,也叫單列索引,而覆寫索引也叫多列索引,借用丁奇老師的例子,對一個城市中的市民建立索引,如果用名字來做索引肯定不行,重名的人很多,還需要其他的判斷條件來進行篩選,既然如此,可以選擇用身份證號碼來做索引,但是這也會有一個問題,如果我要查詢的是姓名,但是索引里只有身份證號,這個時候就需要回表去主鍵索引上查找,多了一次查詢,為了解決這個問題,就可以用姓名和身份證號建立聯合索引,減少一個回表的消耗,
CREATE TABLE `tuser` (
`id` int(11) NOT NULL,
`id_card` varchar(32) DEFAULT NULL,
`name` varchar(32) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`ismale` tinyint(1) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `id_card` (`id_card`),
KEY `name_age` (`name`,`age`) //覆寫索引必須保證索引列沒有重復
) ENGINE=InnoDB
最左前綴原則
要知道,索引在存盤的時候是有序的,對于多列索引而言,先保證第一列有序,然后在此基礎上第二列有序,以此類推,因此在使用多列索引的時候,會先對第一列索引欄位進行匹配,然后再匹配第二列,
公眾號:沒有夢想的阿巧 后臺回復 "群聊",一起學習,一起進步
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/160092.html
標籤:其他
下一篇:做一個靶機練習_djinn