作者|Orhan Gazi Yal??nv
編譯|VK
來源|Towards Datas Science

你可能對不同的神經網路結構有點熟悉,你可能聽說過前饋神經網路,CNNs,RNNs,這些神經網路對于解決諸如回歸和分類之類的監督學習任務非常有用,
但是,在無監督學習領域,我們面臨著大量的問題,如降維、特征提取、例外檢測、資料生成、增強以及噪聲抑制等,對于這些任務,我們需要特殊的神經網路的幫助,這些神經網路是專門為無監督學習任務而開發的,
因此,他們必須能夠在不需要監督的情況下訓練出來,其中一種特殊的神經網路結構是自編碼器,
自編碼器
什么是自編碼器?
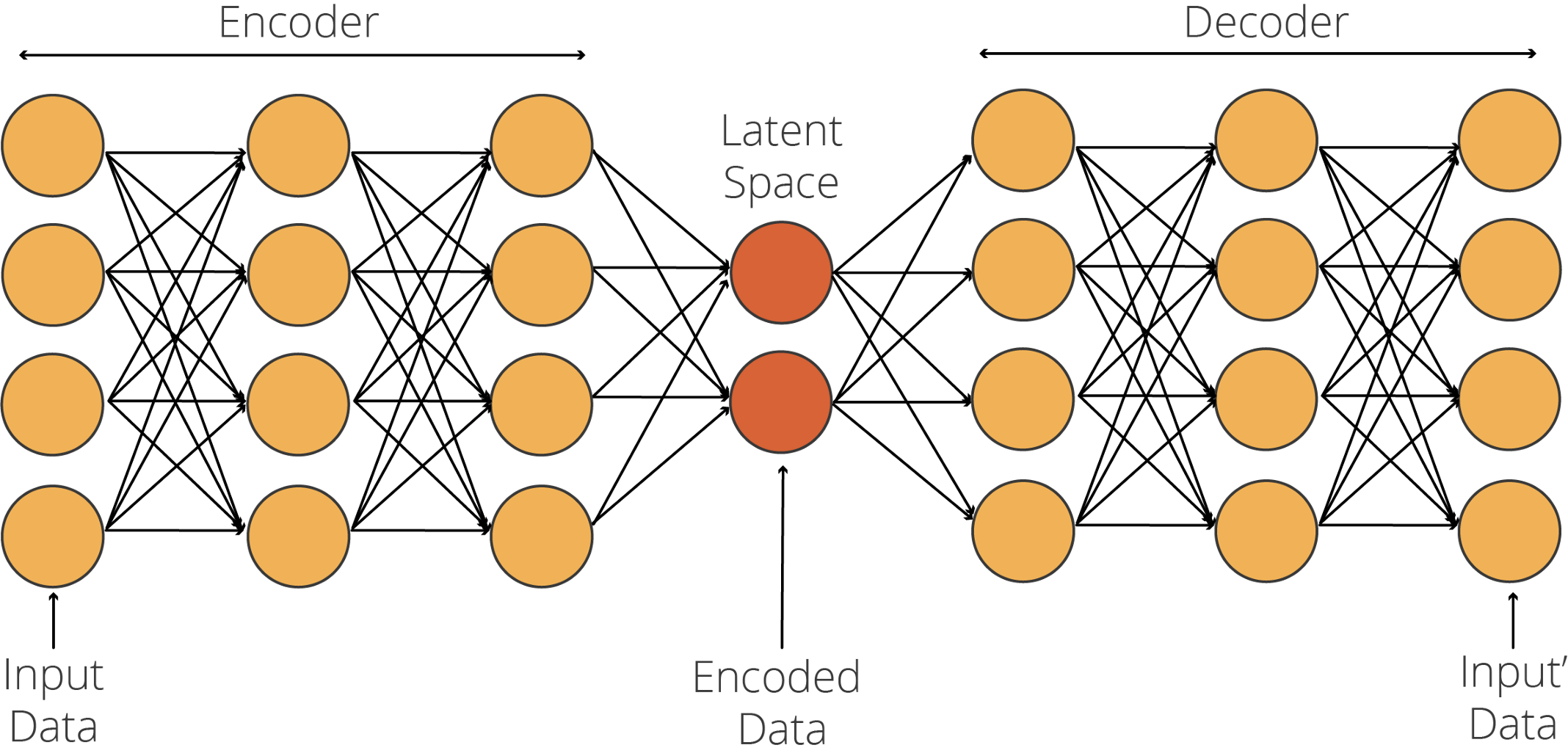
自編碼器是一種神經網路結構,它由兩個子網路組成,即編碼和解碼網路,它們之間通過一個潛在空間相互連接,
自編碼器最早由杰弗里·辛頓(Geoffrey Hinton)和PDP小組在20世紀80年代開發,Hinton和PDP小組的目標是解決“沒有教師的反向傳播”問題,即無監督學習,將輸入作為教師,換句話說,他們只是簡單地將特征資料用作特征資料和標簽資料,讓我們仔細看看自編碼器是如何作業的!
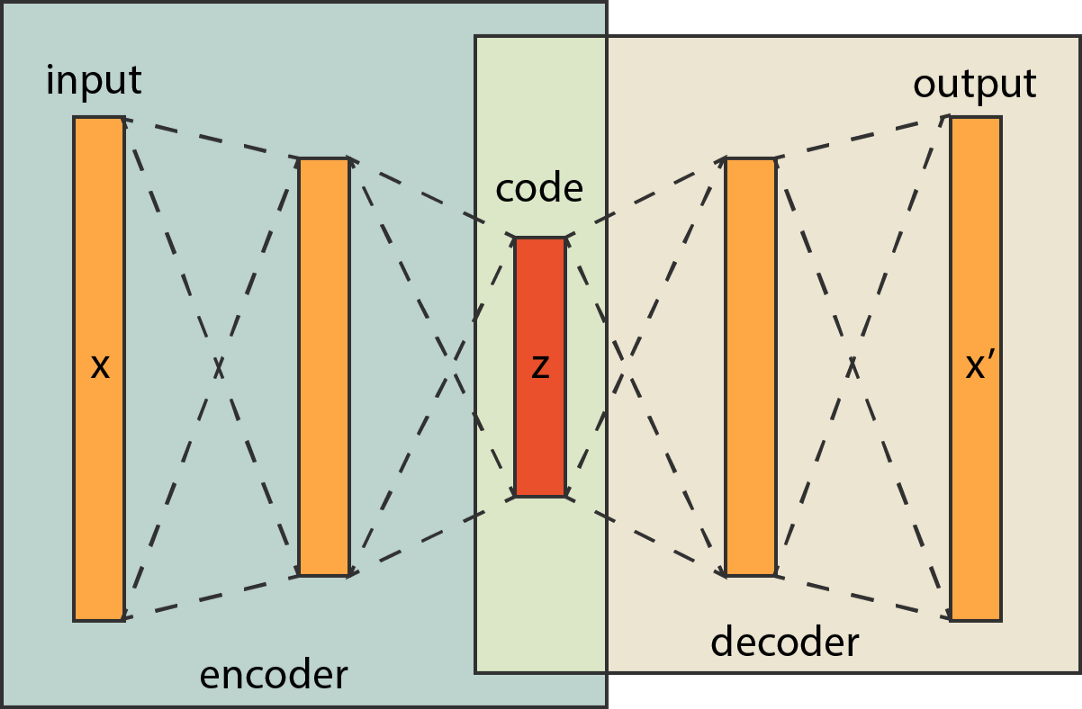
自編碼器體系結構
自編碼器由一個編碼器網路組成,該網路接收特征資料并對其進行編碼以適應潛在空間,解碼器使用該編碼資料(即代碼)將其轉換回特征資料,在編碼器中,模型學習的是如何有效地編碼資料,以便解碼器能夠將其轉換回原始資料,因此,自編碼器訓練的關鍵是生成一個優化的潛在空間,
現在,要知道在大多數情況下,潛在空間中的神經元數量要比輸入層和輸出層小得多,但不一定要這樣,有不同型別的自編碼器,如欠完備、過完備、稀疏、去噪、壓縮和變分自編碼器,在本教程中,我們只關注用于去噪的欠完備自編碼器,
自編碼器中的層
構建自編碼器時的標準做法是設計一個編碼器并創建該網路的反向版本作為該自編碼器的解碼器,因此,只要編碼器和解碼器網路之間存在反向關系,你就可以自由地向這些子網路添加任何層,例如,如果你處理的是影像資料,你肯定需要卷積和池層,另一方面,如果要處理序列資料,則可能需要LSTM、GRU或RNN單元,這里重要的一點是,你可以自由地構建任何你想要的東西,
現在,你已經有了可以構建影像降噪的自編碼器的想法,我們可以繼續學習教程,開始為影像降噪模型撰寫代碼,在本教程中,我們選擇使用TensorFlow的官方教程之一《Autoencoders簡介》[1],我們將使用AI社區成員中非常流行的資料集:Fashion MNIST,
下載Fashion MNIST資料集
Fashion MNIST由德國柏林的歐洲電子商務公司Zalando設計和維護,Fashion MNIST由60000個影像的訓練集和10000個影像的測驗集組成,每個例子是一個28×28的灰度影像,與來自10個類的標簽相關聯,
Fashion MNIST包含服裝的影像(如圖所示),被設計為MNIST資料集的替代資料集,MNIST資料集包含手寫數字,我們選擇Fashion MNIST僅僅是因為MNIST在許多教程中已經被過度使用,
下面的行匯入TensorFlow和load Fashion MNIST:
import tensorflow as tf
from tensorflow.keras.datasets import fashion_mnist
# 我們不需要y_train和y_test
(x_train, _), (x_test, _) = fashion_mnist.load_data()
print('Max value in the x_train is', x_train[0].max())
print('Min value in the x_train is', x_train[0].min())
現在,讓我們使用資料集中的示例生成一個網格,其中包含以下行:
import matplotlib.pyplot as plt
fig, axs = plt.subplots(5, 10)
fig.tight_layout(pad=-1)
plt.gray()
a = 0
for i in range(5):
for j in range(10):
axs[i, j].imshow(tf.squeeze(x_test[a]))
axs[i, j].xaxis.set_visible(False)
axs[i, j].yaxis.set_visible(False)
a = a + 1
我們的輸出顯示了測驗資料集的前50個樣本:

處理Fashion MNIST資料
為了提高計算效率和模型可靠性,我們必須對影像資料應用Minmax規范化,將值范圍限制在0到1之間,由于我們的資料是RGB格式的,所以最小值為0,最大值為255,我們可以使用以下代碼進行最小最大規格化操作:
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
我們還必須改變NumPy陣列維度,因為資料集的當前形狀是(60000,28,28)和(10000,28,28),我們只需要添加一個單一值的第四個維度(例如,從(60000,28,28)到(60000,28,28,1)),
第四維幾乎可以證明我們的資料是灰度格式的,如果我們有彩色影像,那么我們需要在第四維中有三個值,但是我們只需要一個包含單一值的第四維度,因為我們使用灰度影像,以下幾行代碼可以做到這一點:
x_train = x_train[…, tf.newaxis]
x_test = x_test[…, tf.newaxis]
讓我們通過以下幾行來看看NumPy陣列的形狀:
print(x_train.shape)
print(x_test.shape)
輸出:(60000,28,1)和(10000,28,28,1)
給影像添加噪聲
記住我們的目標是建立一個模型,它能夠對影像進行降噪處理,為了做到這一點,我們將使用現有的影像資料并將它們添加到隨機噪聲中,
然后,我們將原始影像作為輸入,噪聲影像作為輸出,我們的自編碼器將學習干凈的影像和有噪聲的影像之間的關系,以及如何清除有噪聲的影像,
因此,讓我們創建一個有噪聲的版本,
對于這個任務,我們使用tf.random.normal方法,然后,我們用一個噪聲系數乘以隨機值,你可以隨意使用它,以下代碼為影像添加噪聲:
noise_factor = 0.4
x_train_noisy = x_train + noise_factor * tf.random.normal(shape=x_train.shape)
x_test_noisy = x_test + noise_factor * tf.random.normal(shape=x_test.shape)
我們還需要確保陣列項的值在0到1的范圍內,為此,我們可以使用 tf.clip_by_value方法,clip_by_value是一種TensorFlow方法,它將“最小值-最大值”范圍之外的值剪裁并替換為指定的“最小值”或“最大值”,以下代碼剪輯超出范圍的值:
x_train_noisy = tf.clip_by_value(x_train_noisy, clip_value_min=0., clip_value_max=1.)
x_test_noisy = tf.clip_by_value(x_test_noisy, clip_value_min=0., clip_value_max=1.)
現在,我們已經創建了資料集的規則化和噪聲版本,我們可以查看它的外觀:
n = 5
plt.figure(figsize=(20, 8))
plt.gray()
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.title("original", size=20)
plt.imshow(tf.squeeze(x_test[i]))
plt.gray()
bx = plt.subplot(2, n, n+ i + 1)
plt.title("original + noise", size=20)
plt.imshow(tf.squeeze(x_test_noisy[i]))
plt.show()

正如你所見,在嘈雜的影像中幾乎不可能理解我們所看到的,然而,我們的自編碼器將神奇地學會清潔它,
建立我們的模型
在TensorFlow中,除了順序API和函式API之外,還有第三種方法來構建模型:模型子類化,在模型子類化中,我們可以自由地從零開始實作一切,
模型子類化是完全可定制的,使我們能夠實作自己的定制模型,這是一個非常強大的方法,因為我們可以建立任何型別的模型,但是,它需要基本的面向物件編程知識,我們的自定義類是tf.keras.Model物件,它還需要宣告幾個變數和函式,
另外請注意,由于我們處理的是影像資料,因此構建一個卷積式自編碼器更為有效,如下所示:

要構建模型,我們只需完成以下任務:
-
創建一個擴展keras.Model的物件
-
創建一個函式來宣告兩個用順序API構建的獨立模型,在它們中,我們需要宣告相互顛倒的層,一個Conv2D層用于編碼器模型,而一個Conv2DTranspose層用于解碼器模型,
-
使用__init__ 方法創建一個call函式,告訴模型如何使用初始化的變數來處理輸入
-
我們需要呼叫以影像為輸入的初始化編碼器模型
-
我們還需要呼叫以編碼器模型(encoded)的輸出作為輸入的初始化解碼器模型
-
回傳解碼器的輸出
我們可以通過以下代碼實作所有這些目標:
from tensorflow.keras.layers import Conv2DTranspose, Conv2D, Input
class NoiseReducer(tf.keras.Model):
def __init__(self):
super(NoiseReducer, self).__init__()
self.encoder = tf.keras.Sequential([
Input(shape=(28, 28, 1)),
Conv2D(16, (3,3), activation='relu', padding='same', strides=2),
Conv2D(8, (3,3), activation='relu', padding='same', strides=2)])
self.decoder = tf.keras.Sequential([
Conv2DTranspose(8, kernel_size=3, strides=2, activation='relu', padding='same'),
Conv2DTranspose(16, kernel_size=3, strides=2, activation='relu', padding='same'),
Conv2D(1, kernel_size=(3,3), activation='sigmoid', padding='same')])
def call(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
讓我們用一個物件呼叫來創建模型:
autoencoder = NoiseReducer()
配置我們的模型
對于這個任務,我們將使用Adam優化器和模型的均方誤差,我們可以很容易地使用compile函式來配置我們的自編碼器,如下所示:
autoencoder.compile(optimizer='adam', loss='mse')
最后,我們可以在10個epoch下通過輸入噪聲和干凈的影像運行我們的模型,這將需要大約1分鐘的訓練,我們還使用測驗資料集進行驗證,以下代碼用于訓練模型:
autoencoder.fit(x_train_noisy,
x_train,
epochs=10,
shuffle=True,
validation_data=https://www.cnblogs.com/panchuangai/archive/2020/10/06/(x_test_noisy, x_test))

用我們訓練過的自編碼器降低影像噪聲
我們現在就可以開始清理噪音影像了,注意,我們可以訪問編碼器和解碼器網路,因為我們在NoiseReducer物件下定義了它們,
所以,首先,我們將使用一個編碼器來編碼我們的噪聲測驗資料集(x_test_noise),然后,我們將編碼后的輸出輸入到解碼器,以獲得干凈的影像,以下代碼完成這些任務:
encoded_imgs=autoencoder.encoder(x_test_noisy).numpy()
decoded_imgs=autoencoder.decoder(encoded_imgs)
讓我們繪制前10個樣本,進行并排比較:
n = 10
plt.figure(figsize=(20, 7))
plt.gray()
for i in range(n):
# 顯示原始+噪聲
bx = plt.subplot(3, n, i + 1)
plt.title("original + noise")
plt.imshow(tf.squeeze(x_test_noisy[i]))
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 顯示重建
cx = plt.subplot(3, n, i + n + 1)
plt.title("reconstructed")
plt.imshow(tf.squeeze(decoded_imgs[i]))
bx.get_xaxis().set_visible(False)
bx.get_yaxis().set_visible(False)
# 顯示原始
ax = plt.subplot(3, n, i + 2*n + 1)
plt.title("original")
plt.imshow(tf.squeeze(x_test[i]))
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
第一行用于噪聲影像,第二行用于清理(重建)影像,最后,第三行用于原始影像,查看清理后的影像與原始影像的相似性:

結尾
你已經構建了一個自編碼器模型,它可以成功地清除非常嘈雜的影像,這是它以前從未見過的(我們使用測驗資料集),
顯然有一些未恢復的變形,例如右起第二張圖片中缺少拖鞋的底部,然而,如果考慮到噪聲影像的變形程度,我們可以說我們的模型在恢復失真影像方面是相當成功的,
在我的腦子里,你可以比如說——考慮擴展這個自編碼器,并將其嵌入照片增強應用程式中,這樣可以提高照片的清晰度和清晰度,
參考
[1] Intro to Autoencoders, TensorFlow, available on https://www.tensorflow.org/tutorials/generative/autoencoder
原文鏈接:https://towardsdatascience.com/image-noise-reduction-in-10-minutes-with-convolutional-autoencoders-d16219d2956a
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/160335.html
標籤:其他
下一篇:Object基礎問題