前面的文章,我們分析了壓測的時機,壓測的指標,那么這次呢,我們來看下,我們這些壓測的指標,常見的都需要性能壓測中觀測點,有了對指標的梳理 ,我們才有重點的關注點,下面,我列舉一些常見的指標,
?服務器cpu
?服務器記憶體
?服務器load
?資料庫連接池
?Redis 連接池
?Tomcat連接池
?TPS
?網路帶寬
?回應時間
?GC
?錯誤率
這些都是一些常見的指標了,當然了,還有一些其他的指標,需要我們根據自己的實際的業務去選擇,這些關注點,大家都可以去搭建一些監控平平臺,展示分析使用,例如火焰圖,zabbix,Grafana,InfluxDB,prometheus等工具,都可以成為我們監控分析的利器,
這些工具呢,都是一些在壓測中常見呢, 我們來介紹下火焰圖
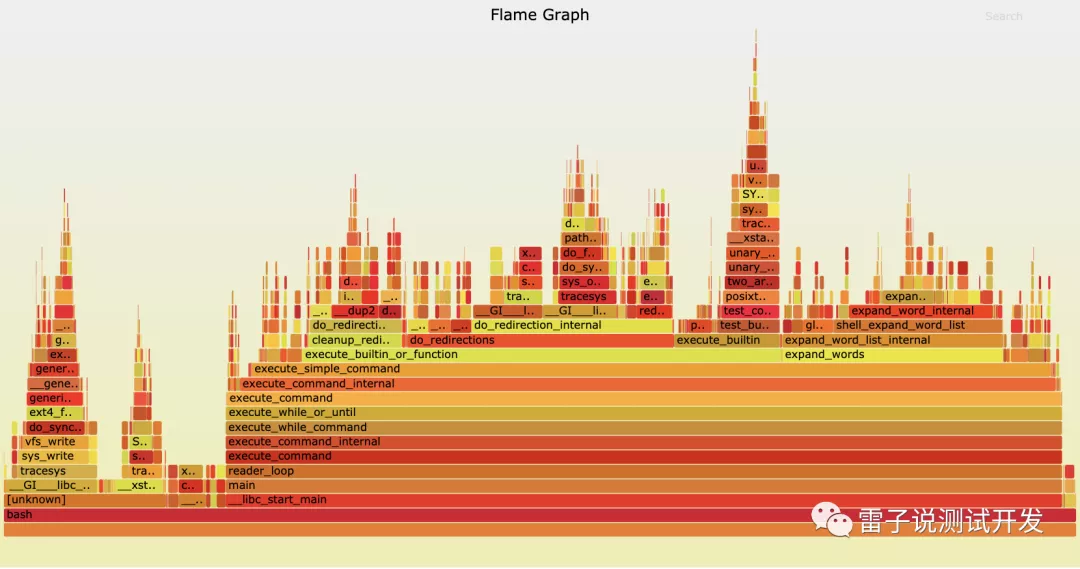
這是官方的github給我們的,
-
由底部到頂部可以追溯一個唯一的呼叫鏈,下面的方塊是上面方塊的父呼叫,
-
同一父呼叫的方塊從左到右以字母序排列,
-
方塊上的字符表示一個呼叫名稱,括號內是火焰圖指向的呼叫在火焰圖中出現的次數和這個方塊占最底層方塊的寬度百分比,
-
方塊的顏色沒有實際意義,相鄰方塊的顏色差只為了便于查看,
火焰圖則適合用在:
-
代碼回圈分析:如果代碼中有很大的回圈或死回圈代碼,那么從火焰圖的頂部或接近項部的地方會有很明顯的”平頂”,表示代碼頻繁地在某個執行緒堆疊上下切換,但需要注意的是,如果回圈的總耗時不長,在火焰圖上不會很明顯,
-
IO 瓶頸/鎖分析:在我們的應用代碼中,我們的呼叫普遍都是同步的,也就是說在進行網路呼叫、檔案 I/O 操作或未成功獲得鎖時,執行緒會停留在某個呼叫上等待 I/O 回應或鎖,如果這個等待非常耗時,會導致執行緒在某個呼叫上一直 hang 住,這在火焰圖上表現得會非常清晰,與此相對的是,我們應用執行緒構成的火焰圖無法準確地表達 CPU 的消耗,因為應用執行緒內沒有系統的呼叫堆疊,在應用執行緒堆疊 hang 住時,CPU 可能去做其他事了,導致我們看到耗時很長,而 CPU 卻很閑,
-
火焰圖倒置分析全域代碼:火焰圖倒置有時也會很實用,如果我們的代碼 N 個不同的分支都呼叫某一方法,倒置后,所有堆疊頂相同的呼叫被合并在一塊,我們就能看出這個方法的總耗時,也就很容易評估出優化這個方法的收益,
zabbix 監控利器,官網是:
https://www.zabbix.com/
我們來看下官方給我們的效果圖
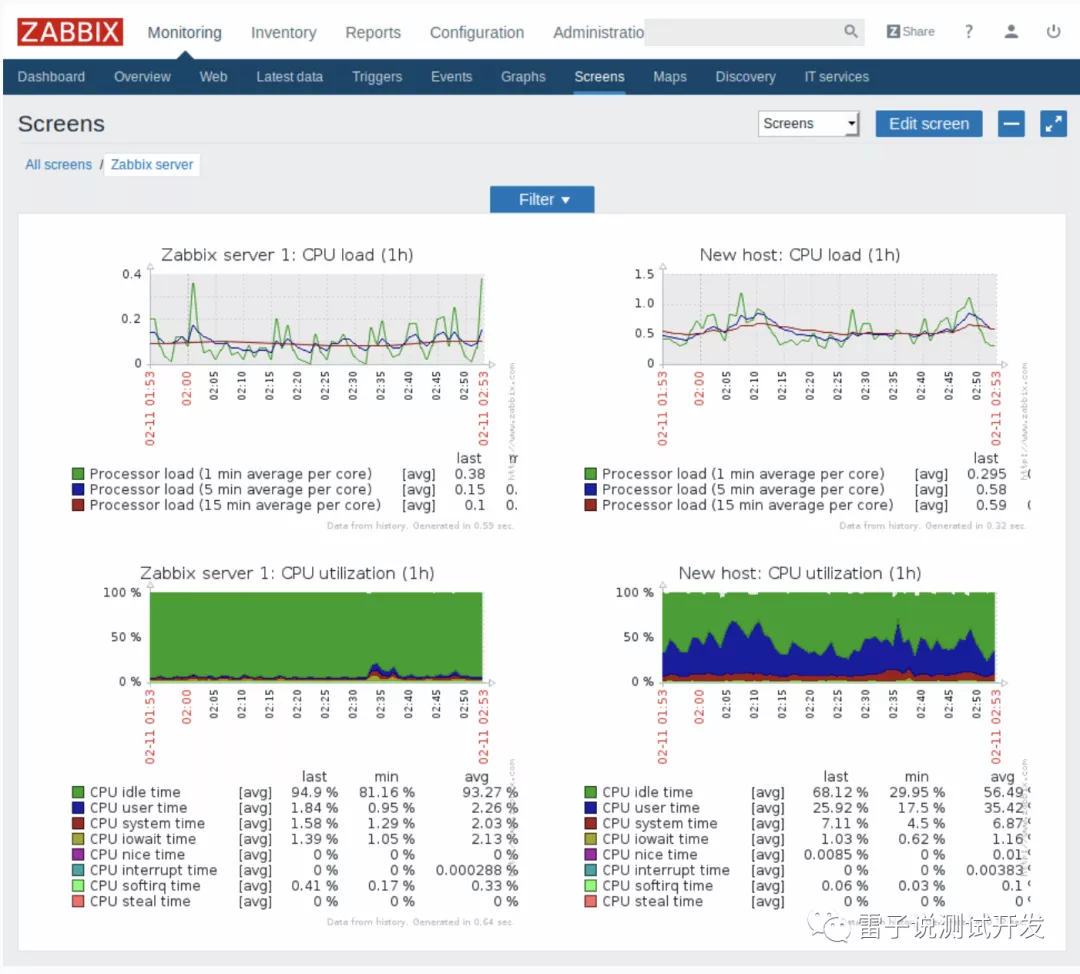
zabbix由2部分構成,zabbix server與可選組件zabbix agent,
Zabbix主要功能:
- CPU負荷
- 記憶體使用
-磁盤使用
- 網路狀況
- 埠監視
- 日志監視,
我們可以用它來做我們服務端的資料收集,
Grafana
美觀、強大的可視化監控指標展示工具,
https://grafana.com/docs/grafana/latest/installation/ 官網,
我們來看下最后的效果,這是官網給的效果圖
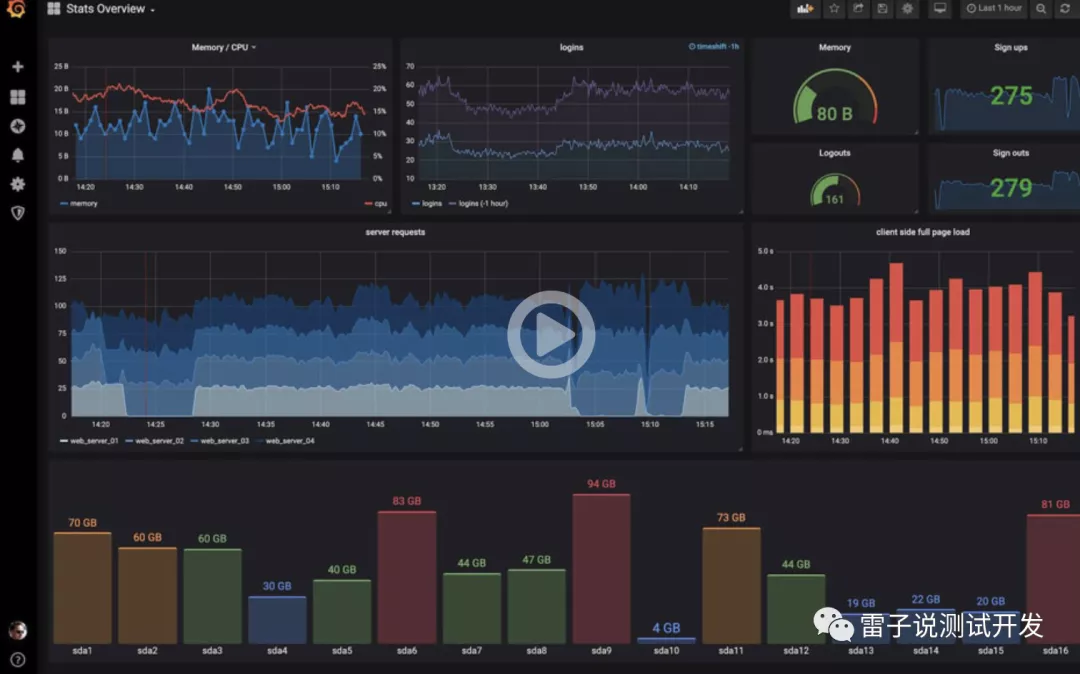
在實際中,我們可以根據我們的實際的需求,去完成我們需要的平臺的搭建,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/16213.html
標籤:其他
上一篇:Flash 0day(CVE-2018-4878)復現程序
下一篇:UnitTest的基本概念與原理