1.1 前言
隨著現代通信技術的發展,高速傳輸和高可靠性成為資訊傳輸的兩個主要方面,而可靠性尤為重要,資訊在實際信道中傳輸時,信道特性的不理想、加性噪聲和人為干擾等因素的影響,都會使系統接收的資訊不可避免地出現差錯,為降低誤碼率,實作可靠性通信,通常采用的途徑有兩種:一種是通過選擇高質量的傳輸線路、改善信道的傳輸特性、增加發送信號的功率、選擇有較強抗干擾能力的調制解調方式等,來降低信道本身引起的誤碼;另一種是通過信道編碼對信道差錯進行控制,許多情況下,前者常常會受條件的限制,不是所有情況都能采用,而信道差錯控制編碼則可以彌補前者的不,糾錯編碼的基本實作方法是在發送端將被傳輸的資訊附上一些監督碼元,這些多余的碼元與資訊碼元之間以某種確定的規則相互關聯(約束),接收端則根據既定的規則校驗資訊碼元與監督碼元之間的關系,一旦傳輸發生差錯,則資訊碼元與監督碼元的關系就受到破壞,從而在接收端可以發現錯誤乃至糾正錯誤,
1.2糾錯碼的應用和發展
在實際傳輸資訊時,如果由于信道傳輸特性、加性噪聲和人為干擾等因素的影響而使接收到的資訊出現差錯,那么為了使系統能夠達到一定的誤位元率,可以通過合理設計基帶信號,選擇調制、解調方式,采用頻域均衡或時域均衡等手段,使誤位元率盡可能降低,但如果誤位元率仍達不到要求,那么必須通過信道編碼即糾錯編碼來進一步降低誤位元率,由于信道編碼可以使傳輸質量提高1-2個數量級或更多,所以在現代通信系統中,信道編碼已經成為系統重要的組成部分,對提高整個系統的傳輸性能起著重要的作用,
1948年,香農(Shannon)在他的開創性論文“通信的數學理論“中,首次闡明了在有擾信道中實作可靠通信的方法,提出了著名的有擾信道編碼定理:對于一個給定的有擾信道,若信道容量為C,只要發送端以低于C的速率R發送資訊,則一定存在一種編碼方法,使譯碼錯誤概率Pe隨著碼長n的增加,
目前,各種糾錯碼如回圈碼、BCH碼、RS碼、LDPC碼以及調制與糾錯碼相結合的TCM碼等都得到很好的研究、發展和應用,可以說糾錯碼已滲透到很多領域,在移動通信中,糾錯碼被廣泛用于模擬體制的信令傳輸及數字體制的整個傳輸,以提高傳輸的可靠性和節省寶貴的頻譜資源;在衛星通信中,糾錯碼技術已成為降低對高功放的要求和減少地球站天線孔徑尺寸的經濟且可靠的方法;在電話網上的資料傳輸中,糾錯碼技術已成為將高速資料傳輸變成現實的關鍵技術;在計算機存貯和運算系統中,也廣泛應用了糾錯碼技術,此外,在超大規模集成電路設計中采用糾錯碼技術后,大大提高了集成電路芯片的成品率,同時又降低了芯片成本,
由信道編碼理論可知,隨著碼長n的增加,譯碼錯誤概率按指數方式趨近于零,因此為提高糾錯碼有效性,就必須使用長碼,但碼長增加,碼率會相應下降,譯碼設備復雜性與計算量也相應增加,以致難以實作,要解決這一矛盾,可采用級聯碼的方法,級聯碼一般由內碼和外碼兩級組成,內碼既可以用作純糾錯,也可以用做糾錯與檢錯,但一般情況下,級聯碼被用在組合信道中,內碼中出現的錯誤往往超過了內碼的糾錯能力,所以,內碼通常僅用來糾正少量錯誤,其主要能力用來檢錯,指出錯誤位置;糾錯任務則由外碼譯碼器完成,這樣兩級譯碼的結果,得到了好的糾錯效果,還使得內/外譯碼器均較簡單,內譯碼器是檢錯譯碼器,外譯碼器是糾錯譯碼器,
Turbo碼是由C.Berron等人在1993年提出的接近香農極限的一種并行級聯碼,是在綜合幾十年來級聯碼、乘積碼、最大后驗概率譯碼及迭代譯碼等理論基礎上的一種創新,其基本原理是通過編碼器的巧妙構造,即多個子碼通過交織器進行并行或串行級聯(PCC/SCC),然
后進行迭代譯碼,從而獲得卓越的糾錯性能,Turbo碼不但在抑制加性高斯噪聲方面性能優越,而且還具有很強的抗衰落、抗干擾能力,在低于香農極限0.7dB的情況下,可以得到10-5
的誤碼率,正是由于Turbo碼超乎尋常的性能,使得它的一經出現就立即引起編碼學界的極大轟動,圍繞Turbo碼的研究也成了通信系統中的一個熱點,
隨著近年來電子技術和集成電路技術的發展,糾錯編碼技術不但早已應用于實際的通信設備之中,而且不斷的有更高性能、更低功耗的譯碼器出現,正是這種實際應用與糾錯碼理論研究的相互促進,使得糾錯編碼技術不斷呈現出蓬勃向上的活力,
1.3 本課題研究意義
進行信道編碼時,可采用多種糾錯碼,其中卷積碼和分組碼是糾錯碼的兩種主要形式,在碼率和編碼器復雜程度相同的情況下,卷積碼的性能要優于分組碼,而且更易于實作最佳譯碼和準最佳譯碼,由于卷積碼的優異性能,使得它在很多方面都得到了應用,由于卷積碼各碼組之間的相互關聯,在對卷積碼的分析時,至今未找到像分組碼那樣嚴密的數學分析手段,因此對卷積碼的性能分析比較困難,目前大多是通過計算機進行好碼的搜索,卷積碼的譯碼也較分組碼容易,可有兩大類譯碼方法:代數譯碼和概率譯碼,在概率譯碼中,維特比譯碼演算法是一種最大似然演算法,在碼的約束度較小時,其效率比序列譯碼演算法更高、速度更快,譯碼器也較之更為簡單,所以,自維特比譯碼演算法提出以來,在理論和實踐方面都得到了極其迅速的發展,被廣泛地應用于各種數傳系統,
1.4 卷積編碼和維特比譯碼
現代資訊和編碼理論的奠基人C.E.Shannon在1948年提出了著名的有噪信道編碼定理,在定理中Shannon給出了在數字通信系統中實作可靠通信的方法以及在特定信道上實作可靠通信的資訊傳輸速率上限,同時,該定理還給出了有效差錯控制編碼的存在性證明,從而促進了信道編碼領域研究的快速發展,
卷積碼是Elias等人在1955年提出的,是一種非常有前途的編碼方法,尤其是在其最大似然譯碼演算法-Viterbi譯碼演算法提出之后,卷積碼在通信系統中得到了極為廣泛的應用,其中約束長度K=7,碼率為1/2和1/3的卷積碼己經成為商業衛星通信系統中的標準編碼方法,在“航海家“以及“先驅者”等太空探測器上也都采用了卷積碼作為其差錯控制編碼方法,在移動通信領域,GMS采用約束長度K=5,碼率為1/2的卷積碼;在IS-95中,上行鏈路中采用的是約束長度K=9,碼率為1/3的卷積碼,在下行鏈路中采用的是約束長度K=9,碼率為1/2的卷積碼,特別在第三代移動通信標準中也是以卷積碼以及與卷積碼相關的編碼方法作為差錯控制編碼方案的,
1.5 本課題主要研究內容
本文首先介紹糾錯編碼的應用和發展,對本課題研究的現實意義進行了簡要闡述,然后介紹了與卷積碼有關的基本概念,同時對與Viterbi譯碼相關的兩種卷積碼的表示方法進行了介紹,然后詳細介紹了Viterbi譯碼演算法,由于Viterbi譯碼是一種最大似然譯碼,所以首先對此進行了介紹;然后從理論的角度,分析了Viterbi譯碼演算法;軟判決Viterbi譯碼的性能要優于硬判決譯碼,對此也進行了介紹和比較,然后利用MATLAB進行卷積編碼和維特比譯碼的仿真和性能分析,
卷積碼是Elias在1955年提出的,在分組碼中,把k個資訊位元序列編成n個位元的碼組,每個碼組中的(n-k)個校驗位僅與本碼組的k個資訊位有關,而與其它碼組無關,為了達到一定的糾錯能力和編碼效率,分組碼的碼組長度一般比較大,編譯碼時必須把整個資訊碼組存盤起來,由此產生的譯碼延遲會隨著n的增加而增加,和分組碼不同,卷積碼前后各碼組之間具有相關性,即卷積碼編碼后的n個碼元不僅與當前段的k個資訊有關,而且還與前面(N-1)(N為編碼約束度)段的資訊有關,在卷積碼中,k個資訊位元也被編成n個位元的碼組,但k和n通常很小,并且可以通過串行或并行的方式進行傳輸,而且時延很小,編碼程序中互相關聯的碼元個數為nN,由于卷積碼在編碼程序中,充分地利用了各碼組之間的相關性,且k和n都比較小,因此,在與分組碼同樣的碼率和設備復雜性條件下,從理論和實際兩個方面,均已證明卷積碼的性能至少不比分組碼差,且實作最佳和準最佳也較分組碼容易,但卷積碼沒有分組碼那樣嚴密的數學分析手段,目前,好的卷積碼大多是通過計算機進行搜索得到的,
卷積碼編碼器如圖3-1所示:
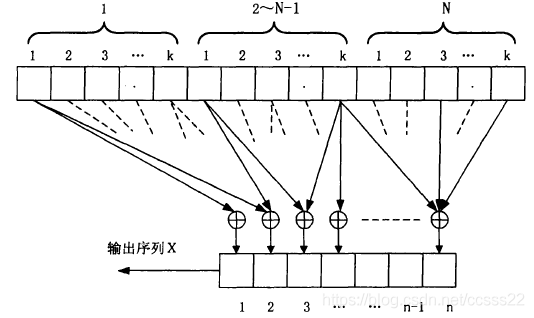
圖3-1碼率為k/n,編碼約束度為N的卷積碼編碼器
圖3-1主要包括:一個輸入移位暫存器(分為N段,每段k位);n個模2加法器;一個輸出資料選擇器(n選一),某一時刻,輸入到編碼器的k個資訊元組成一個資訊組,相應的輸出序列是由n個碼元組成的碼段,這里,稱N為編碼約束度,說明編碼程序中互相約束的碼段個數,令N=m+1,則m稱為編碼存盤,它表示輸入資訊組在編碼器中需存盤的單位時間(有時為了簡化,編碼器中只用m段的輸入移位暫存器),稱Nn為編碼約束長度,說明編碼程序中互相約束的碼元個數,如m=2,n=2,則Nn=6,所以m或N以及Nn都是表示卷積碼編碼器復雜性的重要引數,
卷積碼的表示方法主要有多項式矩陣表示法、狀態圖表示法和網格圖表示法,其中,多項式矩陣表示法主要用于代數譯碼,而Viterbi譯碼演算法主要采用后面兩種方法來表示,下面以(2,1,2)碼為例來介紹狀態圖表示法和網格圖表示法,設(2,1,2)碼的兩個子生成元為:
所以,該碼的生成多項式矩陣為:
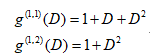
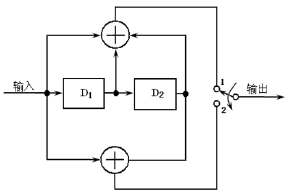
根據G(D)可得如圖3-2所示的編碼電路:
![]()
圖3-2(2,1,2)卷積碼編輯器
3.3 卷積碼的狀態表示法
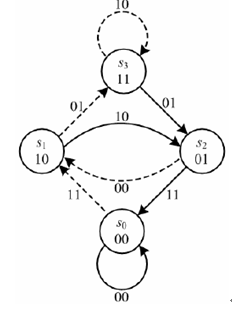
圖3-3 (2,1,2)卷積編碼狀態圖
上圖為圖3-2所示卷積碼編碼器的狀態圖,編碼器的暫存器在任一時刻的所存盤的內容稱為編碼器的一個狀態,以s1表示,本例中,編碼存盤m=2,k=1,編碼器由兩級移位暫存器構成,所以,移位暫存器所存盤的內容只有四種情況:00、10、01和11,這就是說本例中的編碼器共有四種狀態:s0、s1、s2和s3,隨著資訊序列不斷送入,編碼器會不斷地從一個狀態轉移到另一個狀態,利用狀態轉移路徑不但可以表示出該轉移程序中所對應的輸出碼段,同時還可以顯示所對應的輸入資訊元,雖然狀態圖能夠表示卷積碼編碼器在不同輸入的資訊序列下,編碼器各狀態之間的轉移轉移關系,但卻不能描述隨時間變化時系統狀態轉移的軌跡,為了解決這個問題,可引入下面要介紹的網格圖表示法,
圖3-4編碼器的編碼程序,可以用圖3-4所示的碼樹來描述,圖中每個節點“.”對應于一個輸入碼元,按照習慣,當輸入為“0”時,走上分支:輸入為“1”時,走下分支,并將編碼器的輸出標在每個分支的上面,按此規則,就可以畫出碼樹的路徑,對于任一個碼元輸入序列,編碼器輸出序列一定與碼樹中的一條特殊的路徑相對應,因此,沿著碼元輸入序列,就可以獲得相應的輸出碼序列,例如,如果輸入的資訊序列為1010…,輸出編碼序列為11100010…,如圖中虛線所示,可以看出,編碼器的輸出與當前輸入的碼元mj和先前輸入的兩個碼元mj-2mj-1,的取值有關,我們將編碼器中暫存器內所存盤的,先前輸入的資訊碼元的可能取值稱為編碼器的狀態,編碼器mj-2mj-1,可能的取值有四種:00,01,10和11,我們分別用 s0,sl,s2和s3表示,并將其分別標注在碼樹的各節點上,
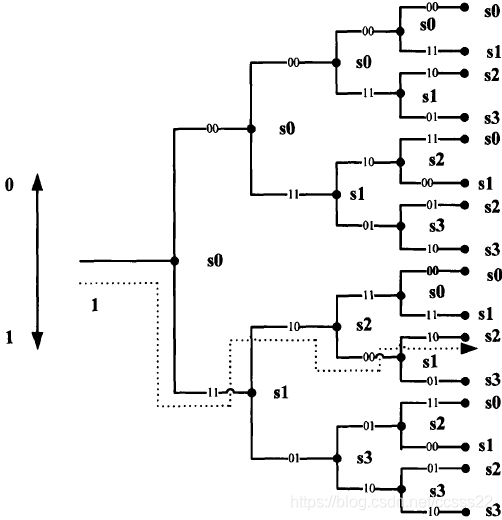
圖3-4 (2,1,2)卷積碼的碼樹
在編碼器的輸入端輸入一個新的資訊碼元后,編碼器會從原來的狀態轉換成新的狀態,例如,若編碼器原來的狀態為sl,當輸入碼元為“1”時,編碼器會從sl狀態轉換到s3狀態:當輸入碼元為“0”時,編碼器會從sl狀態轉換到s2狀態,從碼樹上還可以看到,從第四條支路開始,碼樹的各節點從上而下開始重復出現s0,sl,s2,s3四種狀態,并且碼樹的上半部和下半部分完全相同,這意味著從第4位資訊元輸入開始,無論第1位資訊碼是“0”還是“1”,對編碼輸出都沒有影響,即輸出碼已經與第1位資訊碼元無關,這正是約束度N=3的含義,
在碼樹中,從同一個狀態節點出發的分支都相同,我們可以將狀態相同的節點合并在一起,這樣就得到了卷積碼的另外一種更為緊湊的圖形表示方法,即網格圖,雖然狀態圖展示了狀態的轉移的去向,但不能記錄狀態轉移的軌跡,網格圖可以彌補狀態圖的缺陷,它可以將狀態轉移展開在時間軸上,使編碼的全程序躍然紙上,是分析卷積碼的有力工具,在網格圖中,將碼樹中的上分支(對應于輸入碼元為“o”的情況)用實線表示,下支路(對應于輸入碼元為“1”的情況)用虛線表示,并將編碼輸出標在每條支路的上方,網格圖的每一行節點分別代表s0,sl,s2,s3四種編碼器狀態,(2,1,2)卷積碼編碼器的網格圖如圖3-5所示,
圖3-5 卷積碼的網狀圖
在某一時間單位i,離開每一狀態的虛線分支,表示輸入編碼器的資訊碼元mi=0即輸入為0:而實線分支表示此時刻輸入至編碼器的資訊碼元mi=l,即輸入為1,每一分支上的2位數字,表示i時刻編碼器輸出的子組,因而網格圖中的每一條路徑都對應于不同輸入的資訊序列,與碼樹一樣,任何可能的輸入碼元序列都對應著網格圖上的一條路徑,例如輸入至圖3-5中編碼器序列m=(1011100),對應的編碼輸出序列C=(11,10,00,01,10,01,11),它相應于圖3-5中粗
卷積碼的自由距離,是用來衡量所有可能碼字序列對之間的距離的,其定義為:整個編碼碼樹上,所有半無限長序列之間的最小漢明距離,由于卷積碼的自由距離直接決定了它的糾錯能力,所以尋找具有最人白由距離的卷積碼是一項非常重要的作業,不過對于卷積碼的構造,目前除了計算機搜索外還沒有其它更好的方法,下表是由奧登沃爾德和拉森采用計算機搜索方法得到的固定碼率和約束長度時具有最大自由距離的卷積碼,
表2-l卷積碼的自由距離與編碼增益
| 約束長度K | 生成多項式 | 白由距離 | 編碼增益db |
| 3 | (5,7) | 5 | 4.26 |
| 4 | (15,17) | 6 | 5.23 |
| 5 | (23,35) | 7 | 6.02 |
| 6 | (53,75) | 8 | 6.37 |
| 7 | (133,171) | 10 | 6.99 |
| 8 | (247,371) | 10 | 7.72 |
| 9 | (561,753) | 12 | 7.78 |
4.1維特比譯碼器的演算法
當前最流行的,最常用的卷積碼譯碼演算法式A.J.維特比于1967年提出的維特比(Vietbri)演算法,1973年,富尼最終證明了維特比演算法實質上就是卷積碼的最大似然譯碼,這就是說,從似然的角度上看,這種演算法已經式最優的了,維特比演算法在約束長度K<10卷積碼譯碼中己成為首選的,最普遍采用的演算法,
卷積編碼的程序就是編碼器狀態沿著時間軸一級一級跳轉的程序,維特比譯碼演算法則是在網格圖上搜索最可能的狀態跳轉路徑的程序,維特比譯碼演算法先讀取t時刻的所有狀態的幸存路徑度量,再根據t+1時刻的輸入,算出跳轉路徑的度量:根據這兩類度量算出t+1時刻到狀態S的所有路徑的度量,比較選出一個具有較小路徑度量的路徑作為t+l時刻狀態S的幸存路徑,這樣對每個狀態都得到一個幸存路徑,根據這些幸存路徑和最終編碼器所處的狀態就可以得到編碼器的狀態轉移路徑即譯碼結果,維特比譯碼結果的可信度取決于幸存路徑的深度和它的路徑度量值,幸存路徑越深、路徑度量值越高,那么譯出資訊的可信度就越高,在譯碼程序中有些路徑被拋棄了,有些路徑被保留了下來,被以為是幸存路徑的,也可能會在后面的搜索程序中被拋棄掉,這樣隨著搜索的深度不斷加深,最終正確的路徑將會被保留下來,所有的幸存路徑都將收斂于一條路徑,由上面的描述可知,維特比譯碼器至少需要完成以下操作:
·t時刻幸存路徑度量的存盤,
·t時刻到t+l時刻的分支度量的生成,
·t+1時刻幸存路徑度量的生成和選擇,
維特比譯碼器的基本結構正是按照這些操作劃分的,前面說過,網格圖是理解維特比演算法的核心,其核心思想是依次在每個時刻對網格圖相應列的每個點(對應于編碼器該時刻的狀態),按照最大似然準則比較所有以它為終點的的路徑,只保留一條具有最大似然值的路徑,稱之為幸存路徑,而將其他路徑堵死棄之不用,故到了下一時刻只要對幸存路徑延伸出來的路徑繼續比較即可,即接收一段,計算、比較一段保留下幸存路徑,如此反復直到最后,
下面舉個簡單例子說明維特比譯碼演算法的程序:
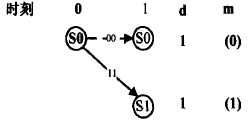
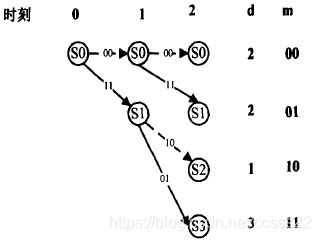
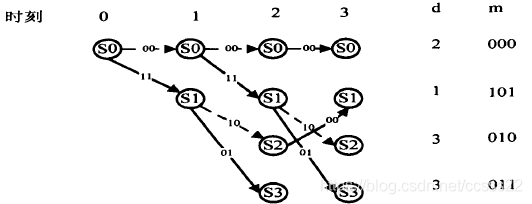
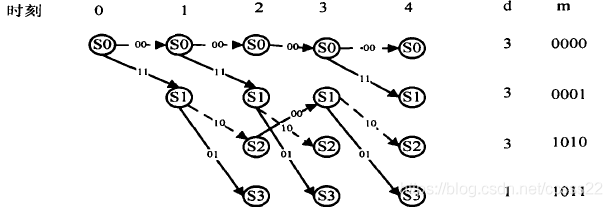
輸入至(2,1,2)編碼器的資訊序列M=(1011100),編碼器輸出的碼序列C=(11,10,00,01,10,01,11),通過二進制對稱信道(BSC)送入譯碼器的序列R=(10,10,00,01,11,01,11)有兩個錯誤,下面我們利用維特比譯碼演算法輸出估計資訊序列M和碼序列C,維特比譯碼器接收序列R的程序如下所示:
·第一時刻接收到子碼R0=10
·第二時刻接收到子碼Rl=10
·第三時刻接收到R2=00
·第四時刻收到子碼R3=0l
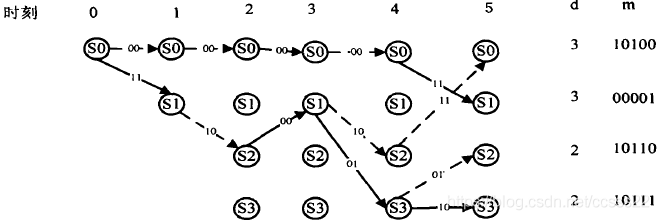
·第五時刻接收到子碼R4=11
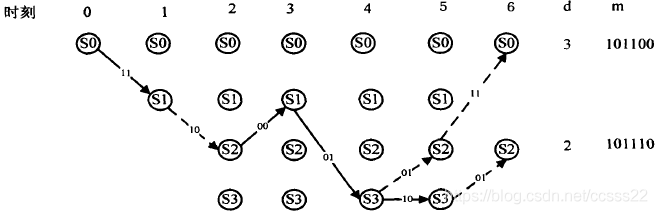
·第六時刻接收到子碼R5=01
·第六時刻接收到子碼R6=11
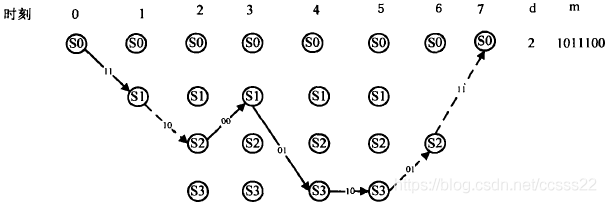
線條所示,
上面描述出了各時刻進入每一狀態的幸存路徑及其度量值d(最小漢明距離),以及與此相應的譯碼器估計的資訊序列M,當L+m=7個時刻以后,4條幸存路徑只剩一條,它就是譯碼器輸出的估值序列C=(11,10,00,01,10,01,11),相應的估值資訊序列M=(1011100),R中的兩個錯誤得到了糾正,在某一時刻,如j=3時,進入s0狀態的幸存路徑的確定程序可敘述如下,進入s0狀態的有兩條路徑:一條是由(00)分支加上與此分支相連的前一時刻(第2時刻)的幸存路徑C01=(00,00)連接組成的路徑(C01,00)=(00,00,00),d(R2,00)=d(00,00)=0,因而d(C0l,00,ROR1R2)=d(C0l,ROR1)+d(R2,00)=2+0=2,所以該路徑的度量值d是2;另一條路徑是由(11)分支加上與此分支相連的前一時刻(第2時刻)的幸存路徑C01’=(11,10)連接組成的路徑(C01’,11)==(11,10,11),它的度量值d=d(C0l’11,R0R1R2)=d(C0l’,R0R1)+d(R2,11)=l+2=3,根據最小漢明距離準則可得在第3時刻s0的幸存路徑是C012=(00,00,00),它的度量值d=2,在其他時刻及進入其余狀態的幸存路徑的選擇與此完全相同,若某一時刻進入某一狀態的兩條路徑有相同的度量,如第4時刻,進入s2狀態的兩條路徑(11,10,00,10)和(00,11,01,01),它們的度量值d都為3,故可任選一條作為s2狀態的幸存路徑,在圖中選擇(11,10,00,10),這種任意選的結果,并不會影響最后結果的正確性,
5.2 卷積編碼的MATLAB仿真與分析
卷積編碼的MATLAB代碼如下所示:
function output=encode(G,k0,input)
if rem(length(input),k0)>0
input=[input,zeros(size(1:k0-rem(length(input),k0)))];
end
n=length(input)/k0;
if rem(size(G,2),k0)>0
error('Error,G is not of the right size.')
end
L=size(G,2)/k0;
n0=size(G,1);
u=[zeros(size(1:(L-1)*k0)),input,zeros(size(1:(L-1)*k0))];
u1=u(L*k0:-1:1);
for i=1:n+L-2
u1=[u1,u((i+L)*k0:-1:i*k0+1)];
end
uu=reshape(u1,L*k0,n+L-1);
output=reshape(rem(G*uu,2),1,n0*(L+n-1));
我們來驗證輸入的信號是否正確,加上輸入的信號為:
0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 ………………………
通過卷積編碼以后,得到信號:
0 0 1 1 0 1 1 0 1 0 1 0 1 0 1 0 ………………………
卷積編碼比較簡單,這里我們就不做詳細介紹了,下面我們將介紹維特比譯碼的實作,
5.3 維特比譯碼的MATLAB仿真與分析
維特比譯碼的MATLAB代碼如下所示:
·檢驗G的維數
if rem(size(G,2),k)~=0
error('Size of G and k do not agree')
end
if rem(size(channel_output,2),n)~=0
error('channle output not of the right size')
end
L=size(G,2)/k;
number_of_states=2^((L-1)*k);
·產生狀態轉移矩陣,輸出矩陣和輸入矩陣
for j=0:number_of_states-1
for t=0:2^k-1
[next_state,memory_contents]=nxt_stat(j,t,L,k);
input(j+1,next_state+1)=t;
branch_output=rem(memory_contents*G',2);
nextstate(j+1,t+1)=next_state;
output(j+1,t+1)=bin2deci(branch_output);
end
end
input;
state_metric=zeros(number_of_states,2);
depth_of_trellis=length(channel_output)/n;
channel_output_matrix=reshape(channel_output,n,depth_of_trellis);
survivor_state=zeros(number_of_states,depth_of_trellis+1);
[row_survivor col_survivor]=size(survivor_state);
·開始非尾信道輸出的解碼 i為段,j為每一階段的狀態,t為輸入
for i=1:depth_of_trellis-L+1
flag=zeros(1,number_of_states);
if i<=L
step=2^((L-i)*k);
else
step=1;
end
for j=0:step:number_of_states-1
for t=0:2^k-1
branch_metric=0;
binary_output=deci2bin(output(j+1,t+1),n);
for tt=1:n
branch_metric=branch_metric+metric(channel_output_matrix(tt,i),binary_output(tt));
end
if ((state_metric(nextstate(j+1,t+1)+1,2)>state_metric(j+1,1)+branch_metric)|flag(nextstate(j+1,t+1)+1)==0)
state_metric(nextstate(j+1,t+1)+1,2)=state_metric(j+1,1)+branch_metric;
survivor_state(nextstate(j+1,t+1)+1,i+1)=j;
flag(nextstate(j+1,t+1)+1)=1;
end
end
end
state_metric=state_metric(:,2:-1:1);
end
·開始尾信道輸出的解碼
for i=depth_of_trellis-L+2:depth_of_trellis
flag=zeros(1,number_of_states);
last_stop=number_of_states/(2^((i-depth_of_trellis+L-2)*k));
for j=0:last_stop-1
branch_metric=0;
binary_output=deci2bin(output(j+1,1),n);
for tt=1:n
branch_metric=branch_metric+metric(channel_output_matrix(tt,i),binary_output(tt));
end
if ((state_metric(nextstate(j+1,1)+1,2)>state_metric(j+1,1)+branch_metric)|flag(nextstate(j+1,1)+1)==0)
state_metric(nextstate(j+1,1)+1,2)=state_metric(j+1,1)+branch_metric;
survivor_state(nextstate(j+1,1)+1,i+1)=j;
flag(nextstate(j+1,1)+1)=1;
end
end
state_metric=state_metric(:,2:-1:1);
end
·從最優路徑產生解碼輸出
state_sequence=zeros(1,depth_of_trellis+1);
size(state_sequence);
state_sequence(1,depth_of_trellis)=survivor_state(1,depth_of_trellis+1);
for i=1:depth_of_trellis
state_sequence(1,depth_of_trellis-i+1)=survivor_state((state_sequence(1,depth_of_trellis+2-i)+1),depth_of_trellis-i+2);
end
state_sequence;
decoder_output_matrix=zeros(k,depth_of_trellis-L+1);
for i=1:depth_of_trellis-L+1
dec_output_deci=input(state_sequence(1,i)+1,state_sequence(1,i+1)+1);
dec_output_bin=deci2bin(dec_output_deci,k);
decoder_output_matrix(:,i)=dec_output_bin(k:-1:1)';
end
decoder_output=reshape(decoder_output_matrix,1,k*(depth_of_trellis-L+1));
cumulated_metric=state_metric(1,1);
通過譯碼以后,我們可以得到信號:
0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 ………………………
說明譯碼是完全正確的,我們對該信號進行誤碼率分析,得到如下結果:
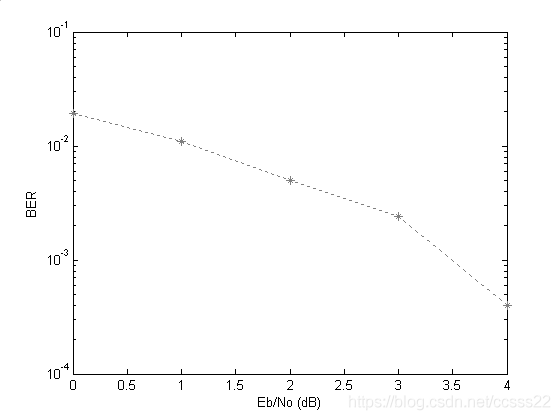
圖5-1 維特比譯碼的信噪比
該系統的MATLAB代碼如下所示:
x = bin_generator(x_num);
x(find(x < 0)) = 0;
x(find(x > 0)) = 1;
s=encode(G,1,x); %卷碼編碼
r=(2*s-1)+sigma(k)*randn(1,length(s));
r(2:10004)=0.3*r(1:10003)+0.7*r(2:10004);
r(find(r < 0)) = 0;
r(find(r > 0)) = 1;
dd=viterbi(G,1,r); %譯碼
%誤碼計數
Pe = length(find(x – dd))/x_num;
Plot_Pe = [Plot_Pe Pe];
5.4 不通過維特比譯碼的性能仿真
以上信號不通過維特比譯碼,其頂層代碼如下所示:
x = bingen(x_num);
x(find(x < 0)) = 0;
x(find(x > 0)) = 1;
r=(2*x-1)+sigma(k)*randn(1,length(x));
r(2:5000)=0.3*r(1:4999)+0.7*r(2:5000);
r(find(r < 0)) = 0;
r(find(r > 0)) = 1
Pe = length(find(x - r))/x_num;
Plot_Pe = [Plot_Pe Pe];
其性能仿真如下所示:
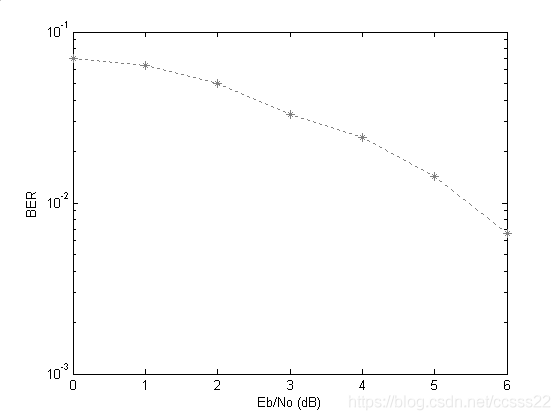
圖5-2 無維特比譯碼的信噪比
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/163091.html
標籤:其他
下一篇:【測驗框架】cxxtest