比較檢驗
- 前言
- 內容引出
- 二項檢驗
前言
??二項檢驗在周志華老師的西瓜書中并沒有做太多解釋,自己也是網上搜索了相關的資料和其他人的看法,并結合了自己的一些理解寫下博客記錄一下,
內容引出
??我們在對學習器的性能進行評估比較的時候,有了評估方法和性能度量也不一定能很好判斷學習器的優劣,通常是用統計假設檢驗,基于假設檢驗的結果我們可以推斷出,若在測驗集上觀察到學習器A比B好,則A的泛化性能是否在統計意義上優于B,以及這個結論的把握有多大,這里,默認以錯誤率為性能度量,用 ? \epsilon ?表示,即泛化錯誤率,
??假設檢驗中的“假設”是對學習器泛化錯誤率分布的某種判斷或者是猜想,比如“ ? = ? 0 \epsilon=\epsilon_{0} ?=?0?”,現實的任務中我們不知道學習器的泛化錯誤率,只能獲知其測驗錯誤率 ? ^ \hat{\epsilon} ?^,而且泛化錯誤率和測驗錯誤率不一定相同,直觀上,它們兩者接近的可能性比較大,相差很遠的可能性比較小,由此我們可以根據測驗錯誤率估推出泛化錯誤率的分布,這也是此章節的目的,
二項檢驗
??泛化錯誤率為 ? \epsilon ?的學習器在一個樣本上犯錯的概率是 ? \epsilon ?,而測驗錯誤率 ? ^ \hat{\epsilon} ?^表示的是在m個測驗樣本中恰好有 ? ^ ? m \hat{\epsilon}*m ?^?m個被誤分類,我們假定測驗樣本是從總體分布中獨立采樣得到的,那請問泛化錯誤率為 ? \epsilon ?的學習中將m0個樣本誤分類,其余樣本全部分類正確的概率是多少?
??如果上面的看不懂沒關系,我們來分析一下這個問題,假如你去投籃,你不能投中的概率是 ? \epsilon ?,你總共只能投m個,其中m0個投不中的概率是多少?這個問題我們都不陌生吧,因為你每次投籃都是相互獨立的,所以我們可以用二項分布的方法迅速得出結果 ( m m 0 ) ? ? m 0 ? ( 1 ? ? ) m ? m 0 \begin{pmatrix} m \\ m_0 \end{pmatrix}*\epsilon^{m_0}*(1-\epsilon)^{m-m_0} (mm0??)??m0??(1??)m?m0?這個公式的前面的矩陣的意思其實就是排列組合,相當于C(m,m0),那對之前的問題也是一樣的道理,它也滿足二項分布,所以結果也是一樣 ( m m 0 ) ? ? m 0 ? ( 1 ? ? ) m ? m 0 \begin{pmatrix} m \\ m_0 \end{pmatrix}*\epsilon^{m_0}*(1-\epsilon)^{m-m_0} (mm0??)??m0??(1??)m?m0?所以由此我們可以估算出恰好將 ? ^ ? m \hat{\epsilon}*m ?^?m個樣本誤分類的概率,這也表達了在包含m個樣本的測驗集上,泛化錯誤率為 ? \epsilon ?的學習器被測得測驗錯誤率為 ? ^ \hat{\epsilon} ?^的概率: P ( ? ^ ; ? ) = ( m m ? ? ^ ) ? ? m ? ? ^ ? ( 1 ? ? ) m ? m ? ? ^ P(\hat{\epsilon};\epsilon)=\begin{pmatrix} m \\ m*\hat{\epsilon} \end{pmatrix}*\epsilon^{m*\hat{\epsilon}}*(1-\epsilon)^{m-m*\hat{\epsilon}} P(?^;?)=(mm??^?)??m??^?(1??)m?m??^書上給出的公式其實是很好理解的,但是其最后直接得出結論概率在 ? = ? ^ \epsilon=\hat{\epsilon} ?=?^時最大,其中略過求解程序,所以這里對其進行推導,
??這里其實用到的時極大似然法(不太懂的同學可以看看這篇博客極大似然估計)我們先對原式進行求對數
l
n
(
P
(
?
^
;
?
)
)
=
l
n
(
(
m
m
?
?
^
)
?
?
m
?
?
^
?
(
1
?
?
)
m
?
m
?
?
^
)
ln(P(\hat{\epsilon};\epsilon))=ln(\begin{pmatrix} m \\ m*\hat{\epsilon} \end{pmatrix}*\epsilon^{m*\hat{\epsilon}}*(1-\epsilon)^{m-m*\hat{\epsilon}})
ln(P(?^;?))=ln((mm??^?)??m??^?(1??)m?m??^)這里要提一個關于對數函式的性質
l
n
(
a
?
b
)
=
l
n
(
a
)
+
l
n
(
b
)
ln(a*b)=ln(a)+ln(b)
ln(a?b)=ln(a)+ln(b)所以根據這個性質我們可以對原式進行分解
l
n
(
P
(
?
^
;
?
)
)
=
l
n
(
(
m
m
?
?
^
)
?
?
m
?
?
^
?
(
1
?
?
)
m
?
m
?
?
^
)
=
l
n
(
(
m
m
?
?
^
)
)
+
l
n
(
?
m
?
?
^
)
+
l
n
(
(
1
?
?
)
m
?
m
?
?
^
)
=
l
n
(
(
m
m
?
?
^
)
)
+
(
m
?
?
^
)
?
l
n
(
?
)
+
(
m
?
m
?
?
^
)
l
n
(
(
1
?
?
)
)
ln(P(\hat{\epsilon};\epsilon))=ln(\begin{pmatrix} m \\ m*\hat{\epsilon} \end{pmatrix}*\epsilon^{m*\hat{\epsilon}}*(1-\epsilon)^{m-m*\hat{\epsilon}})\\=ln(\begin{pmatrix} m \\ m*\hat{\epsilon} \end{pmatrix})+ln(\epsilon^{m*\hat{\epsilon}})+ln((1-\epsilon)^{m-m*\hat{\epsilon}})\\=ln(\begin{pmatrix} m \\ m*\hat{\epsilon} \end{pmatrix})+({m*\hat{\epsilon}})*ln(\epsilon)+({m-m*\hat{\epsilon}})ln((1-\epsilon))
ln(P(?^;?))=ln((mm??^?)??m??^?(1??)m?m??^)=ln((mm??^?))+ln(?m??^)+ln((1??)m?m??^)=ln((mm??^?))+(m??^)?ln(?)+(m?m??^)ln((1??))然后我們再對式子進行求導,現在對
?
\epsilon
?求導,此時要比之前更容易求導
?
(
l
n
(
P
(
?
^
;
?
)
)
)
?
?
=
?
(
l
n
(
(
m
m
?
?
^
)
)
)
+
?
(
(
m
?
?
^
)
?
l
n
(
?
)
)
+
?
(
(
m
?
m
?
?
^
)
l
n
(
(
1
?
?
)
)
)
=
0
+
(
m
?
?
^
)
?
1
?
+
(
m
?
?
^
?
m
)
?
1
1
?
?
=
m
?
(
?
^
?
?
)
(
1
?
?
)
?
?
\frac{\partial(ln(P(\hat{\epsilon};\epsilon)))}{\partial\epsilon}=\partial(ln(\begin{pmatrix} m \\ m*\hat{\epsilon} \end{pmatrix}))+\partial(({m*\hat{\epsilon}})*ln(\epsilon))+\partial(({m-m*\hat{\epsilon}})ln((1-\epsilon)))\\=0+({m*\hat{\epsilon}})*\frac{1}{\epsilon}+({m*\hat{\epsilon}-m})*\frac{1}{1-\epsilon}\\=\frac{m*(\hat{\epsilon}-\epsilon)}{(1-\epsilon)*\epsilon}
???(ln(P(?^;?)))?=?(ln((mm??^?)))+?((m??^)?ln(?))+?((m?m??^)ln((1??)))=0+(m??^)??1?+(m??^?m)?1??1?=(1??)??m?(?^??)?
我們也知道當其導數為0時有最大值,且此時
?
=
?
^
\epsilon=\hat{\epsilon}
?=?^,根據書上的例子,
?
=
0.3
\epsilon=0.3
?=0.3,m=10,我們可以用Python代碼將其表示出來:
import matplotlib.pyplot as plt
from scipy.special import comb
from matplotlib.font_manager import FontProperties
import numpy as np
import matplotlib
a = 0.3
m = 10
p = []
for error in range(11):
k = comb(m,error)*(a**error)*((1-a)**(m-error))
p.append(k)
fig = plt.figure()
ax = fig.add_subplot(111)
font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)
plt.xlabel('誤分類樣本數',fontproperties=font)
plt.ylabel('概率',fontproperties=font)
y = np.arange(0,0.35,0.05)
x = np.arange(0,11.0,1.0)
plt.xticks(x)
plt.yticks(y)
ax.scatter(x,p)
plt.plot(x,p)
plt.show()
我們可以得到和書上基本一致的影像
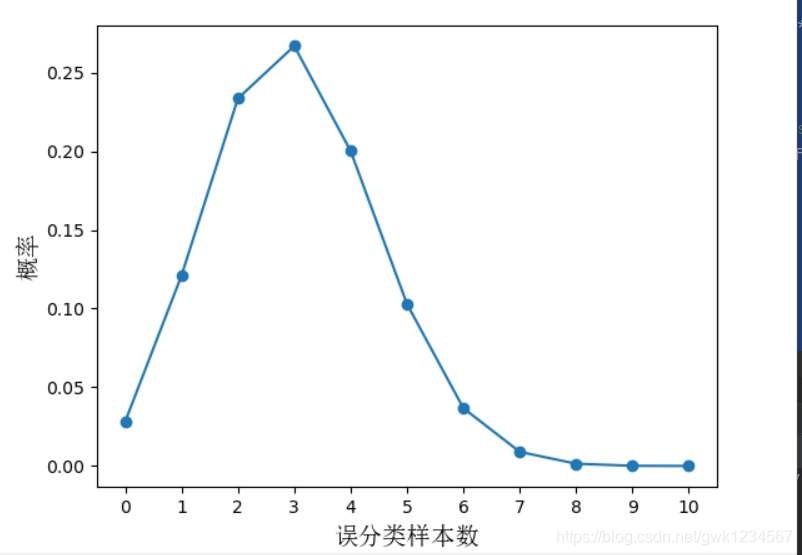
圖中的橫坐標雖然是誤分類的樣本數,但是除以樣本總數即可得到此時的測驗錯誤率
?
^
\hat{\epsilon}
?^,由圖我們也可以看出當泛化錯誤率
?
\epsilon
?為
?
^
\hat{\epsilon}
?^時其概率最大,
??我們可以由圖看出當泛化錯誤率給定時,測驗錯誤率與總樣本數的乘積即誤分類樣本數說一個二項分布,我們對其進行假設檢驗,也稱為二項檢驗,書中給出原假設“ ? < = ? 0 \epsilon<=\epsilon_0 ?<=?0?”,那么其備擇假設就是“ ? > ? 0 \epsilon>\epsilon_0 ?>?0?”,即原假設不成立時的對立結果,由此我們也可以得出這是一個右側單邊檢驗,書中直接給出了公式(最新的印刷有些不一樣) ? ˉ = m i n ? s . t . ∑ i = ? ? m + 1 m ( m i ) ? ? 0 i ? ( 1 ? ? 0 ) m ? i < α \bar{\epsilon}=min\ \epsilon\ \ s.t.\ \displaystyle\sum_{i=\epsilon*m+1}^{m} \begin{pmatrix} m \\ i \end{pmatrix}* \epsilon_0^{i}*(1-\epsilon_0)^{m-i}<\alpha ?ˉ=min ? s.t. i=??m+1∑m?(mi?)??0i??(1??0?)m?i<α
??我們知道假設檢驗如果結果落入拒絕域范圍,那么我們則可以拒絕原假設,所以對于上述公式也同樣的道理,用書上的圖來解釋

α \alpha α是顯著水平,1- α \alpha α是置信區間,我們可以將圖看作是普通的假設檢驗的單邊檢驗的函式影像,圖中的 α \alpha α區域看成拒絕域,其他部分看成是接受域,只要在 ? = ? 0 \epsilon=\epsilon_0 ?=?0?的情況下,該學習器的測驗錯誤率 ? ^ \hat{\epsilon} ?^沒有落入拒絕域中,那么我們就有1- α \alpha α的置信度認為學習器的泛化錯誤率 ? {\epsilon} ?小于 ? 0 {\epsilon_0} ?0?,(因為 ? {\epsilon} ?是不知道的,我們只是假設),所以我們的關鍵就在于求出那個臨界值,
??我們之前的概率值是在泛化錯誤率給定的情況下,學習器對
?
^
\hat{\epsilon}
?^的概率估計,我們要求假設接受的臨界值,相當于就是滿足概率相加的和小于
α
\alpha
α最小的那個測驗錯誤率,書中給出的這個公式的作用也就是這個意思,我們可以看出圖中5就是那個臨界值,因為當誤分類樣本數為6,7,8,9,10的這些概率相加的和小于
α
\alpha
α,但若是加上5的這個概率值,那么就會大于
α
\alpha
α,不滿足條件,所以5就是最小的臨界值,得到臨界值后,只要判斷其與測驗錯誤率的大小即可,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/163570.html
標籤:其他
上一篇:CTF 內涵的軟體 stage1