這里,沒有直接采用之前的方案,是因為在設計的時候,發現直接采用顏色等直接特征提取然后進行二值化處理的方法,如果視頻中出現顏色類似的區域,則很有可能錯誤的定位,例如在公交車中車牌區域范圍和前窗以及部分的背景比較相似,直接采用這種方法會出錯,
這里,定位的演算法,我們使用的是HOG特征提取和Adaboost的演算法進行定位,對應的程式為:
![]()
具體的原理如下所示:
adaboost:
http://www.doc88.com/p-211656392146.html
http://www.doc88.com/p-908977169291.html
hog:
http://www.doc88.com/p-938477812496.html
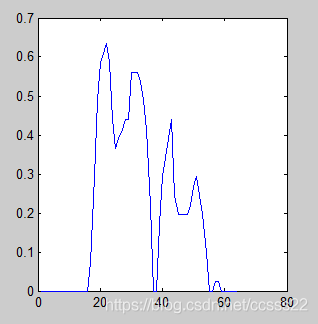
上面的幾個論文,是我們參考的幾個比較好的資料,定位的仿真效果如下所示:


通過上面的步驟,我們能夠對車牌整體范圍進行定位,采用這種方法的缺點就是需要大量的樣本進行訓練才能夠獲得精度較大的訓練結果,樣本越多,精度越高,
步驟二:訓練識別
之前給你的方案是使用SVM進行訓練識別,后來考慮了一下,這里稍微變了下,采用BP神經網路進行訓練識別,因為采用SVM只針對2分類識別,所以效果不佳,所以采用BP神經網路進行訓練識別,
運行![]()
得到如下結果:
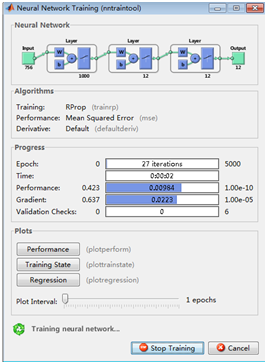
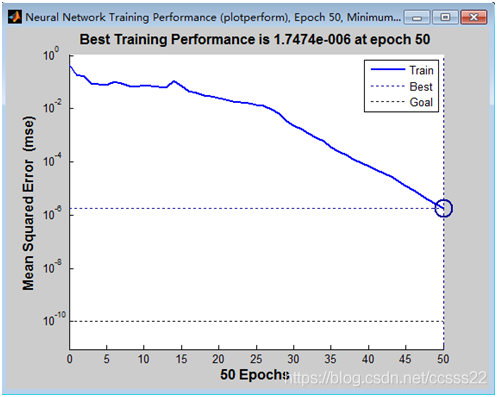
步驟三:整體的車牌識別
通過上面的分析,我們所這里的整個演算法流程如下所示:
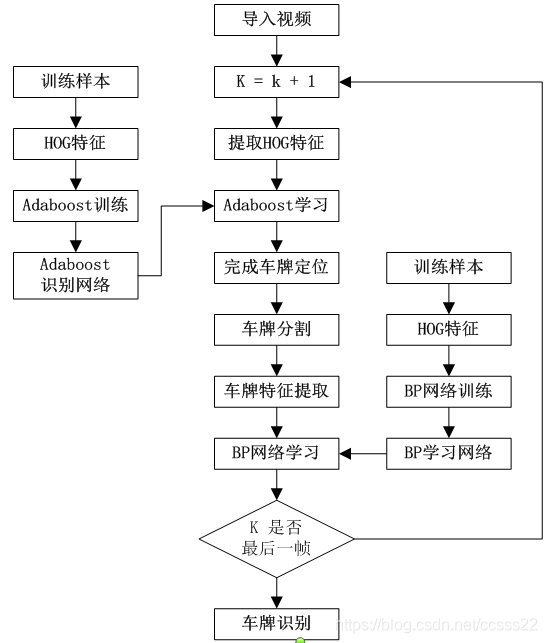
最后仿真結果如下所示:




轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/163572.html
標籤:其他