注意:如果只想解決這個問題可以跳過1,2直接看3和4的解決步驟
- 一鍵啟動集群查看datanode的日志在哪里
sh start-all.sh

進入日志查看
用shift+g進入末行模式,在往上翻,看到第一個INFO,下面有WARN(警告),這個里有提示資訊,大約是講datenode的clusterID和namenode的clusterID不一致,

- 進入cd /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas/current/
查看 cat VERSION
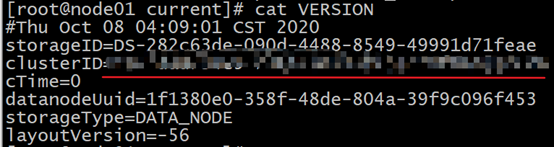
這個與namenode舊的ID一致
3. 洗掉集群每一個節點的current

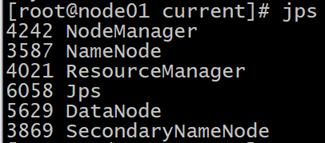
- 重新啟動集群即可,并查看是否全部啟動成功
sh start-all.sh
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/163812.html
標籤:其他
上一篇:MapReduce編程實踐
下一篇:Hadoop集群安裝部署