大資料介紹及集群安裝
- 1、大資料概述
- 2、什么是大資料?(Big Data)
- 3、傳統資料與大資料的對比
- 4、大資料的特點
- 5、大資料生態系統
- 6、大資料技術為什么快?
- 7、Hadoop詳解
- 8、Hadoop三大公司發型版本介紹
- 9、Hadoop的架構模型(1.x,2.x的各種架構模型介紹)
- 10、CDH版本Hadoop重新編譯
- 11、CDH 分布式環境搭建
- 瀏覽器查看啟動頁面
1、大資料概述
傳統資料處理介紹
目標: 了解大資料到來之前,傳統資料的通用處理模式,
資料來源:
1、企業內部管理系統 ,如員工考勤(打卡)記錄,
2、客戶管理系統(CRM)
資料特征:
1、資料增長速度比較緩慢,種類單一,
2、資料量為GB級別,資料量較小
資料處理方式:
1、資料保存在資料庫中,處理時以處理器為中心,應用程式到資料庫中檢索資料再進行計算(移
動資料到程式端)
遇到的問題:
1、資料量越來越大、資料處理的速度越來越慢,
2、資料種類越來越多,出現很多資料庫無法存盤的資料,如音頻、照片、視頻等,
2、什么是大資料?(Big Data)
目標:掌握什么是大資料、傳統資料與大資料的對比有哪些區別、大資料的特點
是指無法在一定時間范圍內用常規軟體工具進行捕捉、管理和處理的資料集合,是需要新處理模式才能具有更強的決策力、洞察發現力和流程優化能力的海量、高增長率和多樣化的資訊資產,
是指一種規模大到在獲取、存盤、管理、分析方面大大超出了傳統資料庫軟體工具能力范圍的資料集合,具有海量的資料規模、快速的資料流轉、多樣的資料型別和價值密度低四大特征,
資料的存盤單位
最小的基本單位是bit
1 Byte =8 bit
1 KB = 1,024 Bytes = 8192 bit
KB MB GB TB PB EB ZB YB BB NB DB 進率1024
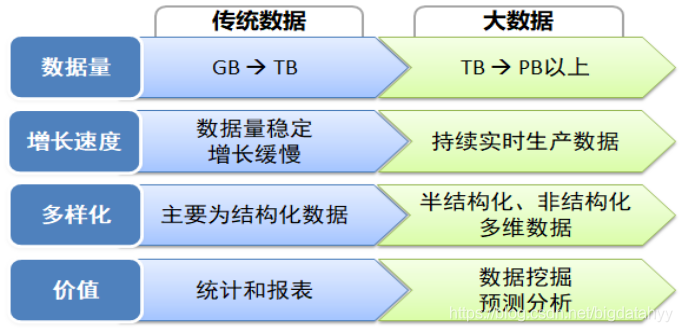
3、傳統資料與大資料的對比
4、大資料的特點
資料集主要特點
Volume(大量): 資料量巨大,從TB到PB級別,
Velocity(高速): 資料量在持續增加(兩位數的年增長率),
Variety(多樣): 資料型別復雜,超過80%的資料是非結構化的,
Value(低密度高價值): 低成本創造高價值,
其他特征
資料來自大量源,需要做相關性分析,
需要實時或者準實時的流式采集,有些應用90%寫vs.10%讀,
資料需要長時間存盤,非熱點資料也會被隨機訪問,
傳統資料與大資料處理服務器系統安裝對比
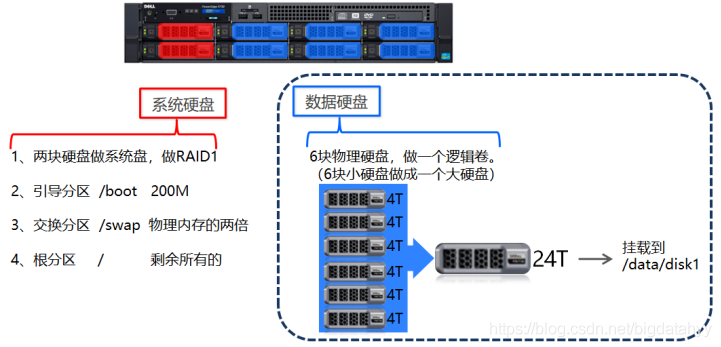
傳統資料下服務器系統安裝
在傳統資料背景下,服務器系統安裝中,系統硬碟、資料硬碟完全隔離,通常會將多塊資料硬碟制作成LVM(邏輯卷),即將多塊物理硬碟通過軟體技術“拼接”在一起形成一個大的硬碟(邏輯上是一個硬碟),
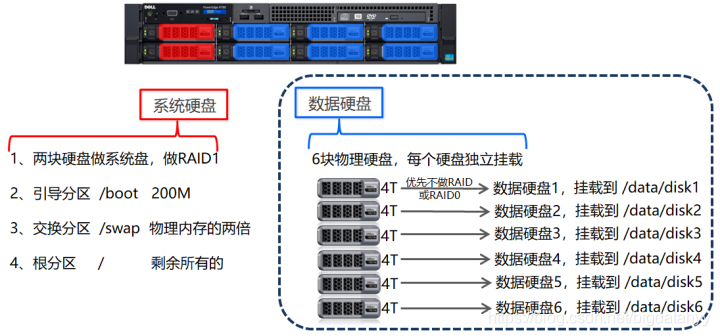
大資料下服務器系統安裝
在大資料背景下,服務器系統安裝中,系統硬碟、資料硬碟完全隔離,資料硬碟必須獨立掛載,每個硬碟掛載到系統的一個獨立的目錄下,
5、大資料生態系統
目標:了解大資料生態系統,大資料技術列舉
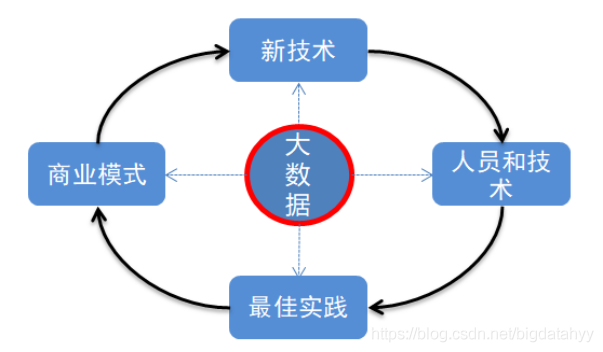
大資料:歷史資料量逐漸攀升、新型資料型別逐漸增多,是企業必然會遇到的問題
新技術:傳統方式與技術無法處理大量、種類繁多的資料,需要新的技術解決新的問題,
技術人員:有了問題,有了解決問題的技術,需要大量懂技術的人解決問題,
最佳實踐:解決 問題的方法,途徑有很多,尋找最好的解決方法,
商業模式:有了最好的解決辦法,同行業可以復用,不同行業可以借鑒,便形成了商業模式,
新技術
HADOOP
HDFS: 海量資料存盤,
YARN: 集群資源調度,
MapReduce: 歷史資料離線計算,
Hive:海量資料倉庫,
Hbase:海量資料快速查詢資料庫,
Zookeeper:集群組件協調,
Impala:是一個能查詢存盤在Hadoop的HDFS和HBase中的PB級資料的互動式查詢引擎,
Kudu:是一個既能夠支持高吞吐批處理,又能夠滿足低延時隨機讀取的綜合組件
Sqoop:資料同步組件(關系型資料庫與hadoop同步),
Flume :海量資料收集,
Kafka:訊息總線,
Oozie:作業流協調,
Azkaban: 作業流協調,
Zeppelin: 資料可視化,
Hue: 資料可視化,
Flink:實時計算引擎,
Kylin: 分布式分析引擎,提供Hadoop/Spark之上的SQL查詢介面及多維分析,
Elasticsearch: 是一個分布式多用戶能力的全文搜索引擎,
Logstash: 一個開源資料搜集引擎,
Kibana: 一個開源的分析和可視化平臺,
SPARK
SparkCore:Spark 核心組件
SparkSQL:高效數倉SQL引擎
Spark Streaming: 實時計算引擎
Structured: 實時計算引擎2.0
Spark MLlib:機器學習引擎
Spark GraphX:圖計算引擎
6、大資料技術為什么快?
目標:掌握傳統資料與大資料相比在擴展性的區別、存盤方式上的區別、可用性上
的區別、計算模型上的區別,
傳統資料與大資料處理方式對比
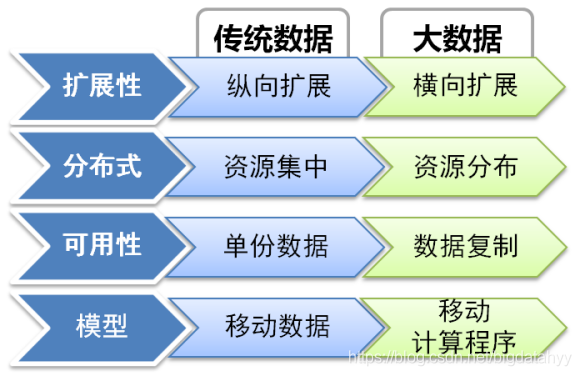
縱向擴展:
表示在需要處理更多負載時通過提高單個系統處理能力的方法來解決問題,最簡單的情況就是為應用系統提供更為強大的硬體,例如如果資料庫所在的服務器實體只有2G記憶體、低配CPU、小容量硬碟,進而導致了資料庫不能高效地運行,那么我們就可以通過將該服務器的記憶體擴展至8G、更換大容量硬碟或者更換高性能服務器來解決這個問題
橫向擴展
是將服務分割為眾多的子服務并在負載平衡等技術的幫助下在應用中添加新的服務實體
例如如果資料庫所在的服務器實體只有一臺服務器,進而導致了資料庫不能高效地運行,那么我們就可以通過增加服務器數量,將其構成一個集群來解決這個問題,
資源集中(計算與存盤)
集中式計算:資料計算幾乎完全依賴于一臺中、大型的中心計算機的處理能力,和它相連的終端(用戶設備)具有各不相同的智能程度,實際上大多數終端完全不具有處理能力,僅僅作為一臺輸入輸出設備使用,
集中式存盤:指建立一個龐大的資料庫,把各種資訊存入其中,各種功能模塊圍繞資訊庫的周圍并對資訊庫進行錄入、修改、查詢、洗掉等操作的組織方式,
分布式(計算與存盤)
分布式計算:是一種計算方法,是將該應用分解成許多小的部分,分配給多臺計算機進行處理,這樣可以節約整體計算時間,大大提高計算效率,
分布式存盤:是一種資料存盤技術,通過網路使用企業中的每臺機器上的磁盤空間,并將這些分散的存盤資源構成一個虛擬的存盤設備,資料分散的存盤在企業的各個角落,多臺服務器,
大資料技術快的原因
1、分布式存盤
2、分布式并行計算
3、移動程式到資料端
4、更前衛、更先進的實作思路
5、更細分的業務場景
6、更先進的硬體技術+更先進的軟體技術
7、Hadoop詳解
Hadoop的介紹以及發展歷史
目標:了解Hadoop的起源,作者、發展歷程
Hadoop之父Doug Cutting

1.?Hadoop最早起源于lucene下的Nutch,Nutch的設計目標是構建一個大型的全網搜索引擎,包括網頁抓取、索引、查詢等功能,但隨著抓取網頁數量的增加,遇到了嚴重的可擴展性問題——如何解決數十億網頁的存盤和索引問題,
2.?2003年、2004年谷歌發表的三篇論文為該問題提供了可行的解決方案,
——分布式檔案系統(GFS),可用于處理海量網頁的存盤
——分布式計算框架MAPREDUCE,可用于處理海量網頁的索引計算問題,
——分布式的結構化資料存盤系統Bigtable,用來處理海量結構化資料,
3.?Doug Cutting基于這三篇論文完成了相應的開源實作HDFS和MAPREDUCE,并從Nutch中剝離成為獨立專案HADOOP,到2008年1月,HADOOP成為Apache頂級專案(同年,cloudera公司成立),迎來了它的快速發展期,
為什么叫Hadoop? Logo為什么是黃色的大象?
狹義上來說,Hadoop就是單獨指代Hadoop這個軟體(HDFS+MAPREDUCE)
廣義上來說,Hadoop指代大資料的一個生態圈(Hadoop生態圈),包括很多其他的軟體,

Hadoop的歷史版本介紹
0.x系列版本:Hadoop當中最早的一個開源版本,在此基礎上演變而來的1.x以及2.x的版本
1.x版本系列:Hadoop版本當中的第二代開源版本,主要修復0.x版本的一些bug等
2.x版本系列:架構產生重大變化,引入了yarn平臺等許多新特性
8、Hadoop三大公司發型版本介紹
目標:了解最出名的三個Hadoop版本
1、免費開源版本apache:http://Hadoop.apache.org/
優點:擁有全世界的開源貢獻者,代碼更新迭代版本比較快,
缺點:版本的升級,版本的維護,版本的兼容性,版本的補丁都可能考慮不太周到,學習可以用,實際生產作業環境盡量不要使用
apache所有軟體的下載地址(包括各種歷史版本):
http://archive.apache.org/dist/
2、免費開源版本hortonWorks:https://hortonworks.com/
hortonworks主要是雅虎主導Hadoop開發的副總裁,帶領二十幾個核心成員成立Hortonworks,核心產品軟體HDP(ambari),HDF免費開源,并且提供一整套的web管理界面,供我們可以通過web界面管理我們的集群狀態,web管理界面軟體HDF網址(http://ambari.apache.org/)
3、服務收費版本ClouderaManager: https://www.cloudera.com/
cloudera主要是美國一家大資料公司在apache開源Hadoop的版本上,通過自己公司內部的各種補丁,實作版本之間的穩定運行,大資料生態圈的各個版本的軟體都提供了對應的版本,解決了版本的升級困難,版本兼容性等各種問題,生產環境推薦使用,
Hadoop的模塊組成
1、HDFS:一個高可靠、高吞吐量的分布式檔案系統,
2、MapReduce:一個分布式的離線并行計算框架,
3、YARN:作業調度與集群資源管理的框架,
4、Common:支持其他模塊的工具模塊,
9、Hadoop的架構模型(1.x,2.x的各種架構模型介紹)
目標:了解Hadoop1.x、2.x架構及兩個版本架構的差異,
1.x的版本架構模型介紹
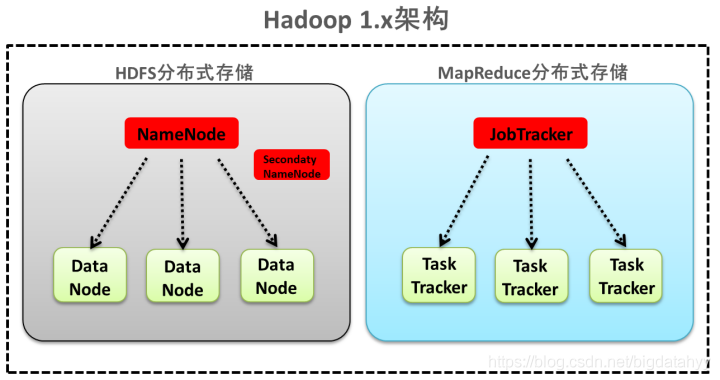
檔案系統核心模塊:
NameNode:集群當中的主節點,主要用于管理集群當中的各種資料
secondaryNameNode:主要能用于Hadoop當中元資料資訊的輔助管理
DataNode:集群當中的從節點,主要用于存盤集群當中的各種資料
資料計算核心模塊:
JobTracker:接收用戶的計算請求任務,并分配任務給從節點
TaskTracker:負責執行主節點JobTracker分配的任務
2.x的版本架構模型介紹
第一種:NameNode與ResourceManager單節點架構模型
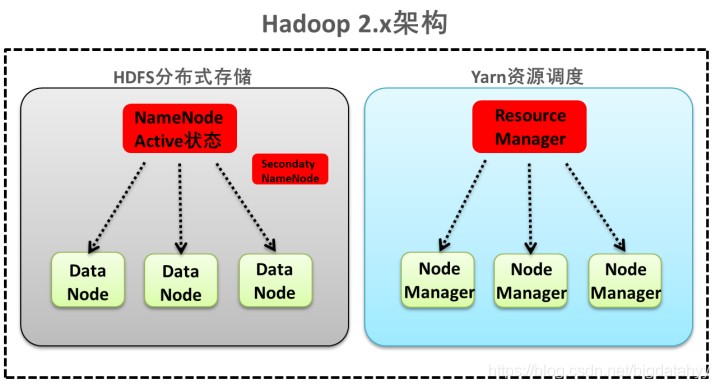
檔案系統核心模塊:
NameNode:集群當中的主節點,主要用于管理集群當中的各種元資料
secondaryNameNode:主要能用于Hadoop當中元資料資訊的輔助管理
DataNode:集群當中的從節點,主要用于存盤集群當中的各種資料
資料計算核心模塊:
ResourceManager:接收用戶的計算請求任務,并負責集群的資源分配
NodeManager:負責執行主節點APPmaster分配的任務
第二種:NameNode單節點與ResourceManager高可用架構模型
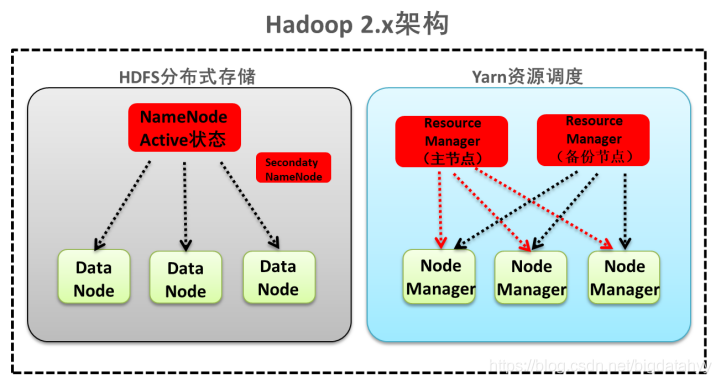
檔案系統核心模塊:
NameNode:集群當中的主節點,主要用于管理集群當中的各種資料
secondaryNameNode:主要能用于Hadoop當中元資料資訊的輔助管理
DataNode:集群當中的從節點,主要用于存盤集群當中的各種資料
資料計算核心模塊:
ResourceManager:接收用戶的計算請求任務,并負責集群的資源分配,以及計算任務的劃分,通過zookeeper實作ResourceManager的高可用
NodeManager:負責執行主節點ResourceManager分配的任務
第三種:NameNode高可用與ResourceManager單節點架構模型
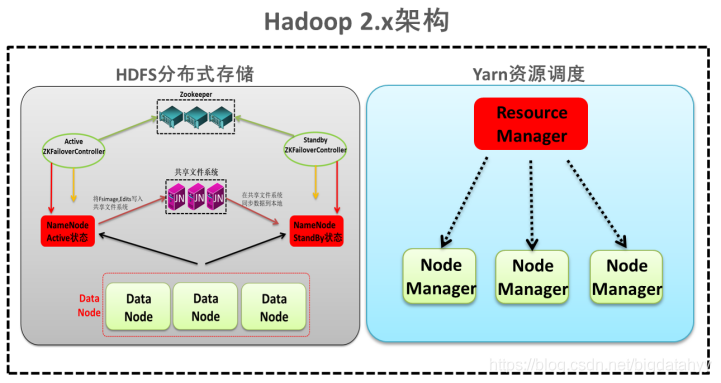
檔案系統核心模塊:
NameNode:集群當中的主節點,主要用于管理集群當中的各種資料,其中nameNode可以有兩個,形成高可用狀態
DataNode:集群當中的從節點,主要用于存盤集群當中的各種資料
JournalNode:檔案系統元資料資訊管理
資料計算核心模塊:
ResourceManager:接收用戶的計算請求任務,并負責集群的資源分配,以及計算任務的劃分
NodeManager:負責執行主節點ResourceManager分配的任務
第四種:NameNode與ResourceManager高可用架構模型
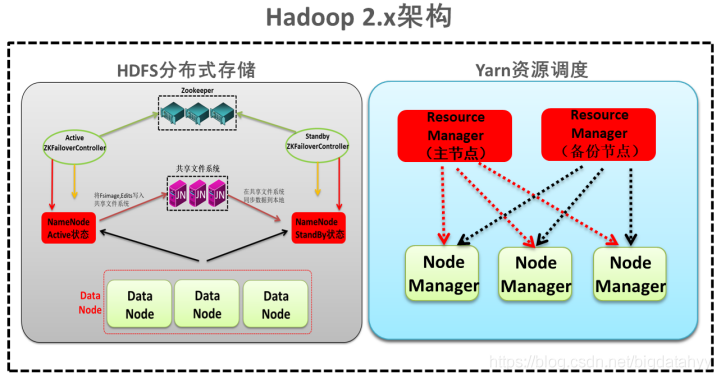
檔案系統核心模塊:
NameNode:集群當中的主節點,主要用于管理集群當中的各種資料,一般都是使用兩個,實作HA高可用
JournalNode:元資料資訊管理行程,一般都是奇數個
DataNode:從節點,用于資料的存盤
資料計算核心模塊:
ResourceManager:Yarn平臺的主節點,主要用于接收各種任務,通過兩個,構建成高可用
NodeManager:Yarn平臺的從節點,主要用于處理ResourceManager分配的任務
10、CDH版本Hadoop重新編譯
目標:重新編譯CDH版本的Hadoop
為什么要編譯Hadoop
由于CDH的所有安裝包版本都給出了對應的軟體版本,一般情況下是不需要自己進行編譯的,但是由于CDH給出的Hadoop的安裝包沒有提供帶C程式訪問的介面,所以我們在使用本地庫(本地庫可以用來做壓縮,以及支持C程式等等)的時候就會出問題,好了廢話不多說,接下來看如何編譯
由于后續課程需要使用snappy進行壓縮資料,而CDH給出的Hadoop的安裝包沒有提供帶C程式訪問的介面,無法使用snappy,所以使用本地庫(本地庫可以用來做壓縮,以及支持C程式等等)的時候就會出問題,所系需要重新編譯使其支持snappy,
準備編譯環境linux環境
準備一臺linux環境,記憶體4G或以上,硬碟40G或以上,我們這里使用的是Centos6.9 64位的作業系統(注意:一定要使用64位的作業系統)
虛擬機聯網,關閉防火墻,關閉selinux
關閉防火墻命令:
service iptables stop
chkconfig iptables off
關閉selinux
vim /etc/selinux/config

(注意:如果你安裝jdk1.7或jdk1.8的話必須要編譯,除非你的jdk是編譯好的,不然必須要走這一步)
注意:親測證明hadoop-2.6.0-cdh5.14.0 這個版本的編譯,只能使用jdk1.7,如果使用jdk1.8那么就會報錯
查看centos6.9自帶的openjdk
rpm -qa | grep java
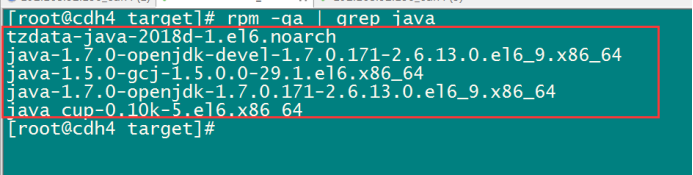
將所有這些openjdk全部卸載掉
rpm -e java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64 tzdata-java-2016j-1.el6.noarch java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64
注意:這里一定不要使用jdk1.8,親測jdk1.8會出現錯誤
將我們jdk的安裝包上傳到/export/softwares(我這里使用的是jdk1.7.0_71這個版本)
解壓我們的jdk壓縮包
統一兩個路徑
mkdir -p /export/servers
mkdir -p /export/softwares
cd /export/softwares
tar zxvf jdk-7u75-linux-x64.tar.gz -C ../servers/
配置環境變數
vim /etc/profile.d/java.sh
在java.sh內添加一下內容,保存退出
export JAVA_HOME=/export/servers/jdk1.7.0_75
export PATH=:$JAVA_HOME/bin:$PATH
注意:
有種辦法是將配置資訊追加到系統組態檔/etc/profile內的最后,此方法也行,但profile是系統核心組態檔,若修改時不小心損壞了組態檔,會導致系統很多基本功能失效,此方法風險較高,不建議使用,
讓修改立即生效
source /etc/profile
安裝maven
這里使用maven3.x以上的版本應該都可以,不建議使用太高的版本,強烈建議使用3.0.5的版本即可
將maven的安裝包上傳到/export/softwares
然后解壓maven的安裝包到/export/servers
cd /export/softwares/
tar -zxvf apache-maven-3.0.5-bin.tar.gz -C ../servers/
配置maven的環境變數
vim /etc/profile.d/maven.sh
export MAVEN_HOME=/export/servers/apache-maven-3.0.5
export MAVEN_OPTS="-Xms4096m -Xmx4096m"
export PATH=:$MAVEN_HOME/bin:$PATH

讓修改立即生效
source /etc/profile
解壓maven的倉庫,我已經下載好了的一份倉庫,用來編譯Hadoop會比較快
tar -zxvf mvnrepository.tar.gz -C /export/servers/
修改maven的組態檔
cd /export/servers/apache-maven-3.0.5/conf
vim settings.xml
指定我們本地倉庫存放的路徑
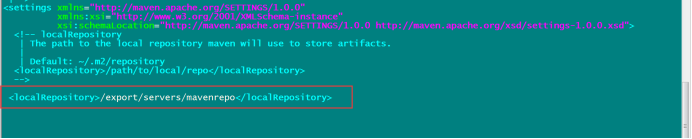
<localRepository>/export/servers/mvnrepository</localRepository>
添加一個阿里云的鏡像地址,會讓我們下載jar包更快
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>

安裝findbugs
下載findbugs
cd /export/softwares
解壓findbugs
tar -zxvf findbugs-1.3.9.tar.gz -C ../servers/
配置findbugs的環境變數
vim /etc/profile.d/findbugs.sh
export FINDBUGS_HOME=/export/servers/findbugs-1.3.9
export PATH=:$FINDBUGS_HOME/bin:$PATH

讓修改立即生效
source /etc/profile
在線安裝一些依賴包
yum install -y autoconf automake libtool cmake
yum install -y ncurses-devel
yum install -y openssl-devel
yum install -y lzo-devel zlib-devel gcc gcc-c++
bzip2壓縮需要的依賴包
yum install -y? bzip2-devel
安裝protobuf
protobuf下載百度網盤地址 https://pan.baidu.com/s/1pJlZubT
下載之后上傳到 /export/softwares,解壓protobuf并進行編譯,
cd /export/softwares
tar -zxvf protobuf-2.5.0.tar.gz -C ../servers/
cd /export/servers/protobuf-2.5.0
./configure
make && make install
安裝snappy
snappy下載地址:http://code.google.com/p/snappy/
cd /export/softwares/
tar -zxvf snappy-1.1.1.tar.gz -C ../servers/
cd ../servers/snappy-1.1.1/
./configure
make && make install
下載cdh原始碼準備編譯
原始碼下載地址為: http://archive.cloudera.com/cdh5/cdh/5/Hadoop-2.6.0-cdh5.14.0-src.tar.gz
下載原始碼進行編譯
cd /export/softwares
tar -zxvf hadoop-2.6.0-cdh5.14.0-src.tar.gz -C ../servers/
cd /export/servers/hadoop-2.6.0-cdh5.14.0
編譯不支持snappy壓縮:
mvn package -Pdist,native -DskipTests –Dtar
編譯支持snappy壓縮:
mvn package -DskipTests -Pdist,native -Dtar -Drequire.snappy -e -X
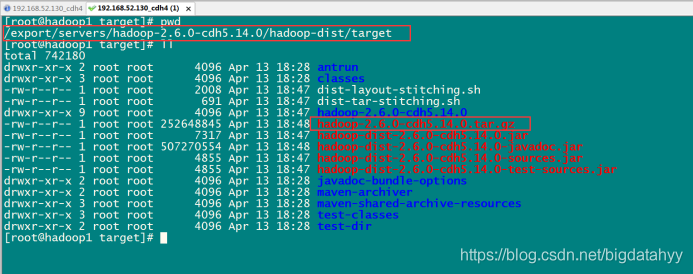
編譯完成之后我們需要的壓縮包就在下面這個路徑里面
/export/servers/hadoop-2.6.0-cdh5.14.0/hadoop-dist/target
常見編譯錯誤
如果編譯時候出現這個錯誤: An Ant BuildException has occured: exec returned: 2
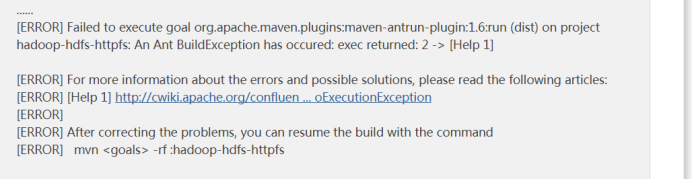
這是因為tomcat的壓縮包沒有下載完成,需要自己下載一個對應版本的apache-tomcat-6.0.53.tar.gz的壓縮包放到指定路徑下面去即可
這兩個路徑下面需要放上這個tomcat的 壓縮包
/export/servers/hadoop-2.6.0-cdh5.14.0/hadoop-hdfs-project/hadoop-hdfs-httpfs/downloads
/export/servers/hadoop-2.6.0-cdh5.14.0/hadoop-common-project/hadoop-kms/downloads

11、CDH 分布式環境搭建
目標:搭建基于CDH的分布式集群
安裝環境服務部署規劃
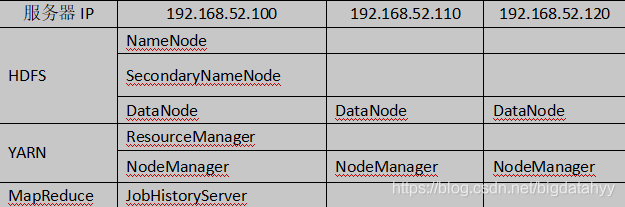
第一步:上傳壓縮包并解壓
將我們重新編譯之后支持snappy壓縮的Hadoop包上傳到第一臺服務器并解壓
第一臺機器執行以下命令
cd /export/softwares/
mv hadoop-2.6.0-cdh5.14.0-自己編譯后的版本.tar.gz hadoop-2.6.0-cdh5.14.0.tar.gz
tar -zxvf hadoop-2.6.0-cdh5.14.0.tar.gz -C ../servers/
第二步:查看Hadoop支持的壓縮方式以及本地庫
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0
bin/hadoop checknative

如果出現openssl為false,那么所有機器在線安裝openssl即可,執行以下命令,虛擬機聯網之后就可以在線進行安裝了
yum -y install openssl-devel

第三步:修改組態檔
修改core-site.xml
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/tempDatas</value>
</property>
<!-- 緩沖區大小,實際作業中根據服務器性能動態調整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 開啟hdfs的垃圾桶機制,洗掉掉的資料可以從垃圾桶中回收,單位分鐘 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>
修改hdfs-site.xml
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
<configuration>
<!-- NameNode存盤元資料資訊的路徑,實際作業中,一般先確定磁盤的掛載目錄,然后多個目錄用,進行分割 -->
<!-- 集群動態上下線
<property>
<name>dfs.hosts</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/accept_host</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/deny_host</value>
</property>
-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node01:50090</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas</value>
</property>
<!-- 定義dataNode資料存盤的節點位置,實際作業中,一般先確定磁盤的掛載目錄,然后多個目錄用,進行分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/snn/name</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:///export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/snn/edits</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
</configuration>
修改Hadoop-env.sh
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改mapred-site.xml
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim mapred-site.xml
<configuration>
<property>
<!--運行模式-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--JVM重用 -->
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node01:19888</value>
</property>
</configuration>
修改yarn-site.xml
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node01</value>
</property>
<property>
<!-- nodemanager 上的附屬服務,只有配置成mapreduce_shuffle 才能運行-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改slaves檔案
第一臺機器執行以下命令(主機名是什么你就寫什么)
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim slaves

第四步:創建檔案存放目錄
第一臺機器執行以下命令
node01機器上面創建以下目錄
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/edits
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/snn/name
mkdir -p /export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/dfs/nn/snn/edits
第五步:安裝包的分發
第一臺機器執行以下命令
cd /export/servers/
scp -r hadoop-2.6.0-cdh5.14.0/ 主機名:$PWD
scp -r hadoop-2.6.0-cdh5.14.0/ 主機名:$PWD
第六步:配置Hadoop的環境變數
三臺機器都要進行配置Hadoop的環境變數
三臺機器執行以下命令
vim /etc/profile.d/hadoop.sh
export HADOOP_HOME=/export/servers/hadoop-2.6.0-cdh5.14.0
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
配置完成之后生效
source /etc/profile
第七步:集群啟動
要啟動 Hadoop 集群,需要啟動 HDFS 和 YARN 兩個集群,
注意:首次啟動HDFS時,必須對其進行格式化操作,本質上是一些清理和準備作業,因為此時的 HDFS 在物理上還是不存在的,
bin/hdfs namenode -format或者bin/Hadoop namenode –format (格式化)
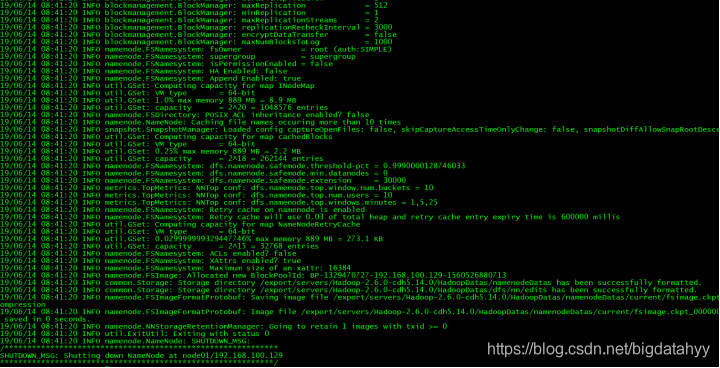
單個節點逐一啟動
在主節點上使用以下命令啟動 HDFS NameNode: hadoop-daemon.sh start namenode
在每個從節點上使用以下命令啟動 HDFS DataNode: hadoop-daemon.sh start datanode
在主節點上使用以下命令啟動 YARN ResourceManager: yarn-daemon.sh start resourcemanager
在每個從節點上使用以下命令啟動 YARN nodemanager: yarn-daemon.sh start nodemanager
以上腳本位于$HADOOP_PREFIX/sbin/目錄下,如果想要停止某個節點上某個角色,只需要把命令中的start 改為stop 即可,
腳本一鍵啟動HDFS、Yarn
如果配置了 etc/Hadoop/slaves 和 ssh 免密登錄,則可以使用程式腳本啟動所有Hadoop 兩個集群的相關行程,在主節點所設定的機器上執行,
啟動集群
node01節點上執行以下命令
第一臺機器執行以下命令
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/start-dfs.sh
sbin/start-yarn.sh
停止集群:沒事兒不要去停止集群
sbin/stop-dfs.sh
sbin/stop-yarn.sh
腳本一鍵啟動所有
一鍵啟動集群
sbin/start-all.sh
一鍵關閉集群
sbin/stop-all.sh
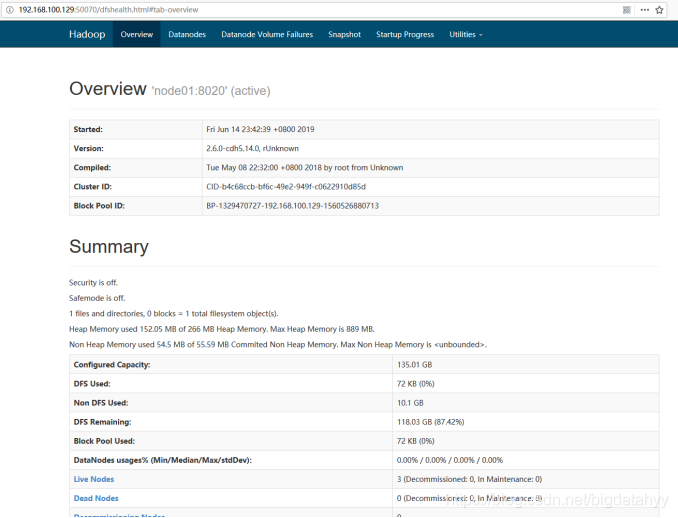
瀏覽器查看啟動頁面
hdfs集群訪問地址: http://192.168.52.100:50070/dfshealth.html#tab-overview
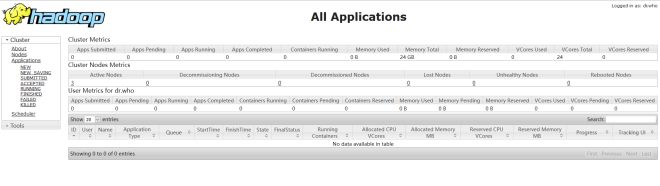
yarn集群訪問地址: http://192.168.52.100:8088/cluster
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/164392.html
標籤:其他
上一篇:一個網站是怎么搭建與運營的?