文章目錄
- 前言
- 一、HDFS 和 MapReduce 優缺點分析
- 1.1 HDFS
- 1.2 MapReduce
- 二、HDFS 和 MapReduce 基本架構
- 三、MapReduce 內部原理實踐
- 四、小結
前言
接著前兩章 構建大資料開發知識體系圖譜 和 大資料平臺架構技術概覽 ,本次繼續分享邦中老師的《離線和實時大資料開發實戰》讀書筆記 ,講講大資料開發的主戰場 —— 離線資料開發,離線資料技術已經有了十多年的發展,已經 比較穩定,形成了 Hadoop、 MapReduce 和 Hive 為事實標準的離線資料處理技術,離線資料平臺是整個資料平臺的根本和基礎,也是目前資料平臺的主站場,
一、HDFS 和 MapReduce 優缺點分析
1.1 HDFS
HDFS 文全稱是 Hadoop Distributed File System ,即 Hadoop 分布式檔案系統,它是Hadoop 的核心子專案,實際上, Hadoop 中有一個綜合性的檔案系統抽象,它提供了檔案系 現的各類介面,而 HDFS 只是這個抽象檔案系統的一種實作,但 HDFS 是各種抽象介面實作中應用最為廣泛和最廣為人知的一個,
HDFS 是基于流式資料模式訪問和處理超大檔案的需求而開發的,其主要特點如下:

當然,HDFS 的上述種種特點非常適合于大資料量的批處理,但是對于一些特定問題不但沒有優勢, 而且有一定的局限性,主要表現在如下幾個方面:
- 不適合低延遲資料訪問
對于那些有低延時要求的應用程式, HBase 是一個更好的選擇,尤其適用于對海量資料集進行訪問并要求毫秒級回應時間的情況,
- 無法高效存盤大量小檔案
要想讓 HDFS 處理好小檔案,有不少方法,例如,利用 SequenceFile、MapFile、Har 等方式歸檔小檔案,這個方法的原理就是把小檔案歸檔起來管理, HBase 就是基于此的對于這種方法,如果想找回原來的小檔案內容,就必須得知道與歸檔檔案的映射關系,此外,也可以橫向擴展,一個 NameNode不夠,可以多 Master 設計,將NameNode 一個集群代替, Alibaba DFS 的設計,就是多 Master 設計,它把 Metadata 的映射存盤和管理分開了,由多個 Metadata 存盤節點和一個查詢 Master 節點組成,
- 不支持多用戶寫入和隨機檔案修改
在 HDFS 的一個檔案中只有一個寫入者,而且寫操作只能在檔案末尾完成,即只能執行追加操作,
1.2 MapReduce
MapReduce 是 Google 公司的核心計算模型,它將運行于大規模集群上的復雜并行計算程序高度地抽象為兩個函式: Map 和 Reduce, Hadoop 中的 MapReduce 是一個使用簡單的軟體框架,基于它寫出來的應用程式能夠運行在由上千個商用機器組成的大型集群上,并能可靠容錯地并行處理 TB 級別的資料集,
MapReduce 目前非常流行,尤其在互聯網公司中 MapReduce 之所以如此受歡迎,是因為它有如下的特點:
二、HDFS 和 MapReduce 基本架構
HDFS 和 MapReduce 是 Hadoop 的兩大核心,它們的分工也非常明確, HDFS 負責分布式存盤,而 MapReduce 負責分布式計算,
首先介紹 HDFS 的體系結構, HDFS 采用了主從( Master/Slave )的結構模型,一個HDFS 集群是由一個 NameNode 和若干個 DataNode 組成的,其中 NameNode 作為主服務器,管理檔案系統的命名空間(即檔案有幾塊,分別存盤在哪個節點上等)和客戶端對檔案的訪問操作;集群中的 DataNode 管理存盤的資料, HDFS 允許用戶以檔案的形式存盤資料,
從內部來看,檔案被分為若干資料塊,而且這若干個資料塊存放在一組 DataNode上,NameNode 執行檔案系統的命名空間操作,比如打開、關閉、重命名檔案或目錄等,它也負責資料塊到具體 DataNode 的映射 ,DataNode 負責處理檔案系統客戶端的檔案讀寫請求,并在 NameNode 的統一調度下進行資料塊的創建、洗掉和復制作業,
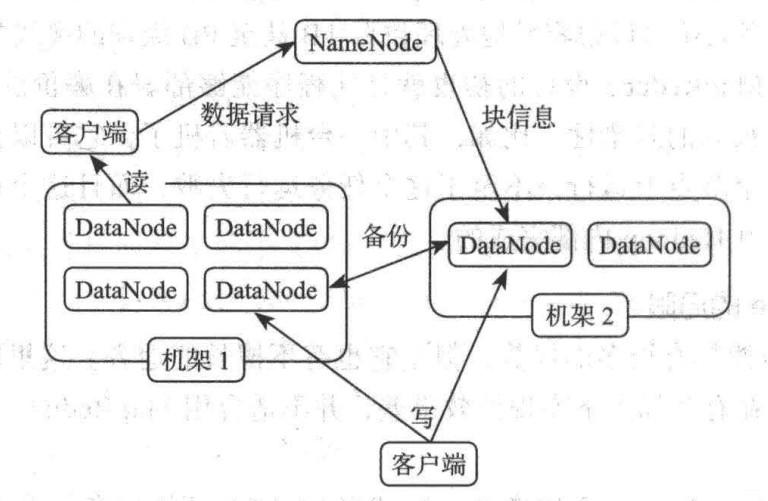
NameNode 和 DataNode 都被設計成可以在普通商用計算機上運行,而且這些計算機通常運行的是 Linux作業系統 ,HDFS 采用 Java 語言開發, 因此任何支持 Java 的機器都可以部署 NameNode 和 DataNode ,
一個典型的部署場景是集群中的一個機器運行一個NameNode 實體,其他機器分別運行一個 DataNode 實體,
MapReduce 也是采用 Master/Slave 的主從架構,其架構圖如圖:
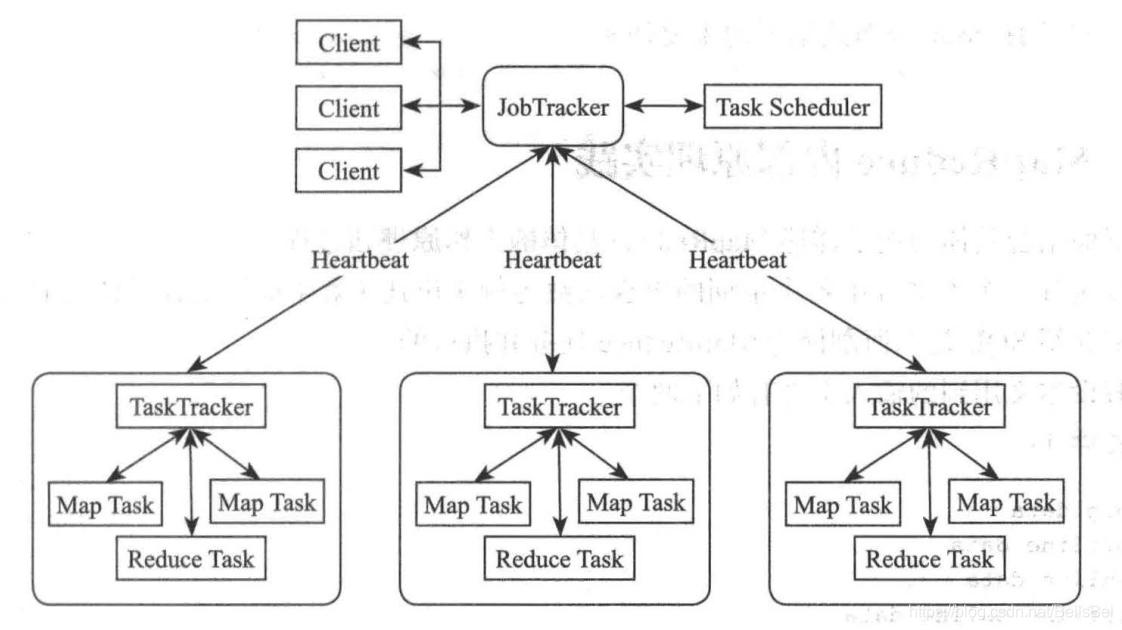
MapReduce 包含4個組成部分,分別為 Client、 JobTracker、TaskTracker 和 Task,
三、MapReduce 內部原理實踐
從上述 MapReduce 架構可以看出, MapReduce 作業執行主要由 JobTracker 和 Task-Tracker 負責完成,
-
客戶端撰寫好的 MapReduce 程式井配置好的 MapReduce 作業是一個 Job, Job 被提交給 JobTracker ,JobTracker 會給該 Job 一個新的 ID 值,接著檢查該 Job 指定的輸出目錄是否存在、輸入檔案是否存在, 如果不存在,則拋出錯誤,
-
同時, JobTracker 會根據輸入檔案計算輸入分片 ( input split ),這些都檢查通過后, JobTracker 就會配置 Job 需要的資源并分配資源,然后 JobTracker 就會初始化作業,也就是將 Job 放入一個內部的佇列,讓配置好的作業調度器能調度到這個作業,作業調度器會初始化這個 Job ,初始化就是創建一個正在運行的 Job 物件(封裝任務和記錄資訊),以便 JobTracker 跟蹤 Job 的狀態和行程,
-
Job 被作業調度器調度時,作業調度器會獲取輸入分片資訊,每個分片創建一個 Map 任務,并根據 TaskTracker 的忙閑情況和空閑資源等分配 Map 任務和 Reduce 任務到 TaskTraker ,同時通過心跳機制也可以監控到 TaskTracker 的狀態和進度 ,也能計算出整個Job 的狀態和進度,
-
當JobTracker 獲得了最后一個完成指定任務的 TaskTracker 操作成功的通知時候, Jo Tracker 會把整個 Job 狀態置為成功,然后當查詢 Job 運行狀態時(注意:這個是異步操作),客戶端會查到 Job 完成的通知 ,
-
如果 Job 中途失敗, MapReduce 會有相應的機制處理 ,一般而言,如果不是程式員程式本身有 bug ,MapReduce 錯誤處理機制都能保證提交的 Job 能正常完成,
那么, MapReduce 到底是如何運行的呢?
我們按照時間順序, MapReduce 任務執行包括:
輸入分片 Map 、Shuffle 和 Reduce 等階段,一個階段的輸出正好是下一階段的輸入,
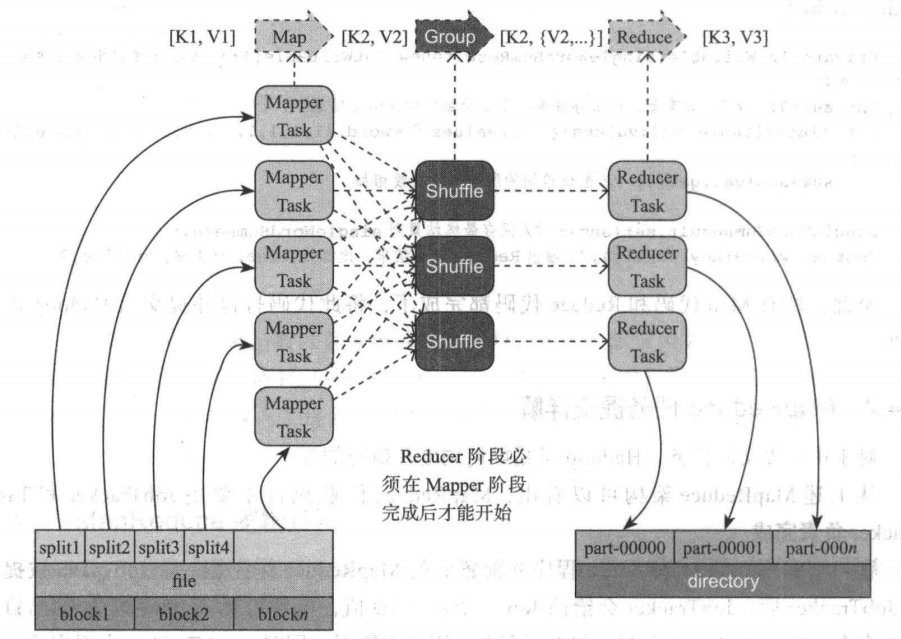
上圖從整體角度很好地表示了 MapReduce 的大致階段劃分和概貌,
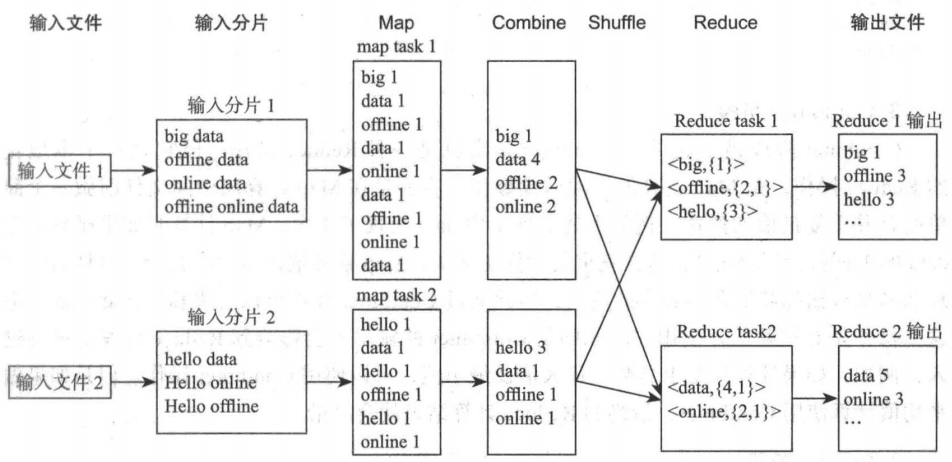
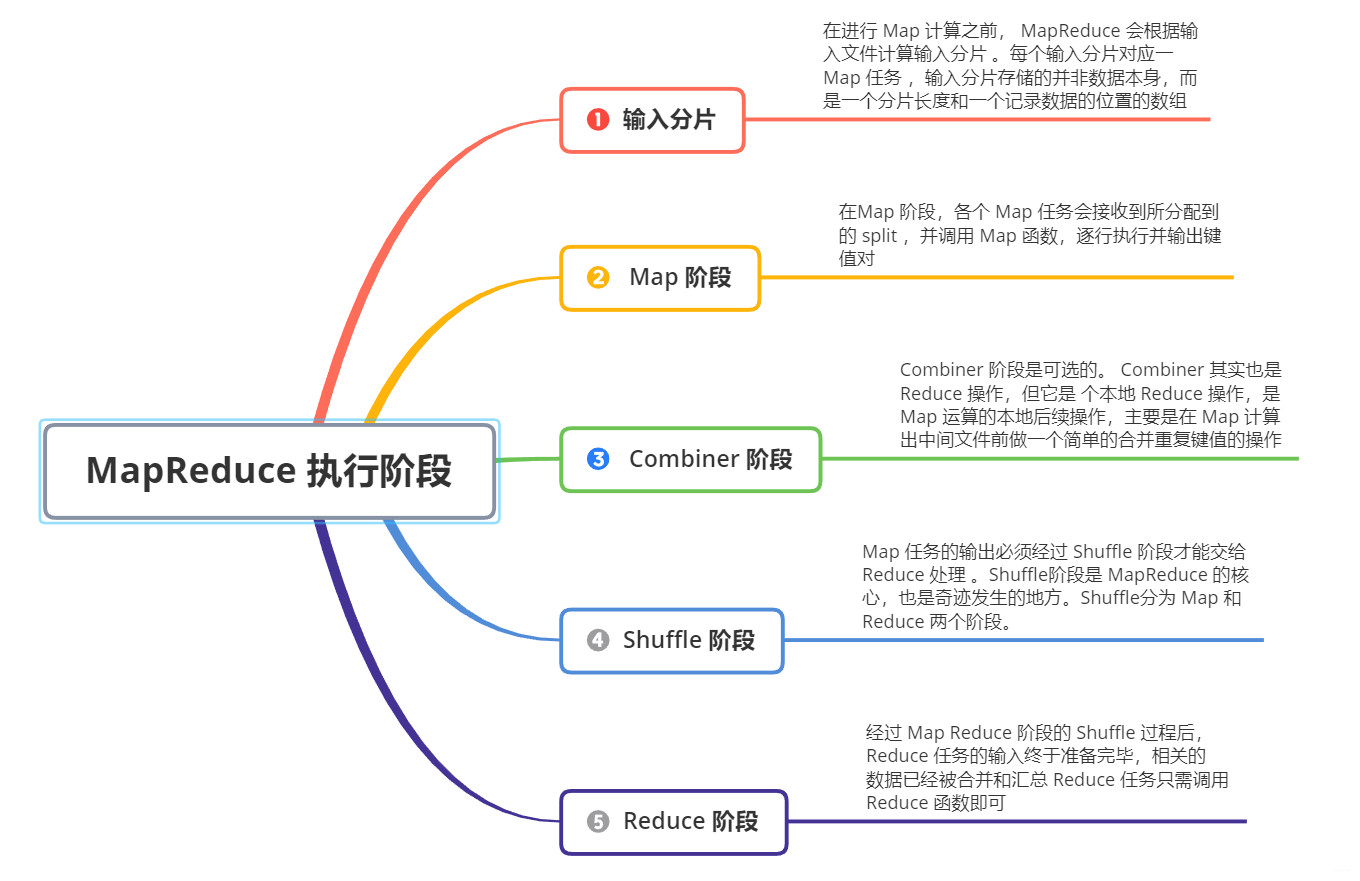
而具體各階段的作用,可參考如下:
四、小結
這一章節,主要還是從資料處理角度集中介紹了 Hadoop 的相關知識,Hadoop 的 HDFS 和 MapReduce 是離線資料處理的底層技術,實際開發中大家還是很少通過撰寫 MapReduce 程式來處理大資料,相反大家主要用基 MapReduce 的高級別抽象 Hive ,效率更高,而且更容易使用,這也是下面會重點和大家講的離線資料處理中的主要技術—— Hive,
 CSDN認證博客專家
Flink
Spark
資料中臺
CSDN認證博客專家
Flink
Spark
資料中臺
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/166687.html
標籤:其他
上一篇:云計算運維之Shell條件陳述句(if 陳述句+case陳述句及實體詳解)
下一篇:2.1 Python運行環境