
本教程涵蓋以下主題:
- 什么是預測不確定性,為什么您要關心它?
- 不確定性的兩個來源是什么?
- 如何使用CatBoost梯度提升庫估算回歸問題的不確定性
什么是不確定性?
機器學習已廣泛應用于一系列任務,但是,在某些高風險應用中,例如自動駕駛,醫療診斷和財務預測,錯誤可能導致致命的后果或重大的財務損失,在這些應用中,重要的是要檢測系統何時犯錯并采取更安全的措施,此外,還希望收集這些“故障場景”,對其進行標記,并教系統通過主動學習做出正確的預測,
預測不確定性估計可用于檢測錯誤,理想情況下,該模型在可能會出錯的情況下表明高度不確定性,這使我們能夠發現錯誤并采取更安全的措施,至關重要的是,行動的選擇取決于模型為何不確定,不確定性的主要來源有兩個:資料不確定性(也稱為偶然不確定性)和知識不確定性(也稱為認知不確定性),如果我們的目標是發現錯誤,則不必將這兩個不確定性分開,但是,如果我們的目標是主動學習,那么我們想發現新的輸入,并且可以將知識不確定性用于此,
資料的不確定性是由于資料固有的復雜性而產生的,例如加性噪聲或重疊類,在這些情況下,模型知道輸入具有多個類別的屬性,或者目標有噪聲,重要的是,無法通過收集更多的訓練資料來減少資料不確定性,當模型的輸入來自訓練資料稀疏或遠離訓練資料的區域時,就會出現知識不確定性,在這些情況下,模型對該區域了解得很少,并且可能會犯錯,與資料不確定性不同,可以通過從一個了解程度不高的區域收集更多的訓練資料來減少知識不確定性,
本教程詳細介紹了如何在CatBoost中量化資料和知識的不確定性,
CatBoost中的資料不確定性
為了說明這些概念,我們將使用一個簡單的綜合示例,
假設我們有兩個分類特征x 1和x 2,每個都有9個值,所以有81種可能的特征組合, 目標取決于以下函式:
y = mean(x?,x?) + eps(x?,x?)
其中平均值(x 1,x 2)是一個未知的固定值,而eps(x 1,x 2)是一個正態分布的噪聲(即資料不確定性),平均值為0,方差為var(x 1,x 2), 在我們的示例中,均值(x 1,x 2)是隨機生成的,而var(x 1,x 2)具有兩個值(0.01和0.04),其分布如下:
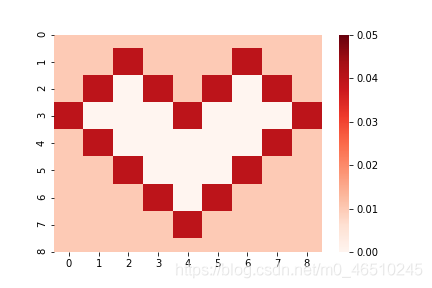
紅心上的點比紅心外的點在目標中具有更多的噪音, 請注意,我們列舉了類別以獲得更好的可視化效果,但是在資料集中,兩個功能都是分類的,即未給出順序,
當我們生成具有這種分布的資料集時,我們假設紅心內沒有任何訓練示例-這些特征組合被認為是我們資料集的例外值,
用RMSE損失優化的標準模型只能預測平均值(x 1,x 2), 好的,但是如果我們要估算y的方差,即資料不確定性,該怎么辦? 換句話說,如果我們想了解哪些預測比較吵雜怎么辦? 為了估計資料的不確定性,必須使用預測均值和方差的概率回歸模型, 為此,CatBoost中有一個名為RMSEWithUncertainty的新損失函式, 有了這個損失,類似于NGBoost演算法[1],CatBoost估計正態分布的均值和方差,優化負對數似然率并使用自然梯度, 對于每個示例,CatBoost模型回傳兩個值:估計平均值和估計方差,
讓我們嘗試將此損失函式應用于我們的簡單示例, 我們得到以下變化:
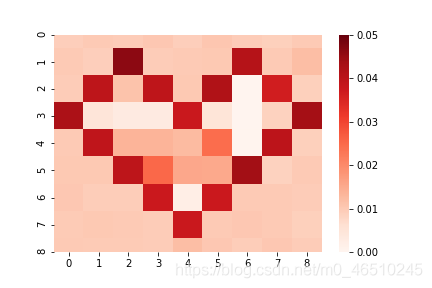
我們可以看到CatBoost成功地預測了心臟及其外部的變化, 在心臟內部,我們沒有訓練資料,因此可以預測任何事情,
CatBoost中的知識不確定性
我們知道如何估算資料中的噪聲, 但是,如何衡量由于特定地區缺乏培訓資料而導致的知識不確定性? 如果我們要檢測例外值該怎么辦? 估計知識不確定性需要模型的整體, 如果所有模型都理解輸入,則它們將給出相似的預測(較低的知識不確定性), 但是,如果模型不理解輸入,則它們可能會提供不同的預測,并且彼此之間會強烈不同意見(知識不確定性很高), 對于回歸,可以通過測量多個模型之間的均值方差來獲得知識不確定性, 請注意,這與單個模型的預測方差不同,后者可以捕獲資料不確定性,
讓我們考慮一下生成的GBDT模型的集合,如下所示:
def ensemble(train_pool, val_pool, num_samples=10, iters=1000, lr=0.2):
ens_preds = []
for seed in range(num_samples):
model = CatBoostRegressor(iterations=iters, learning_rate=lr,
loss_function='RMSEWithUncertainty', posterior_sampling=True,
verbose=False, random_seed=seed)
model.fit(train_pool, eval_set=val_pool)
ens_preds.append(model.predict(test))
return np.asarray(ens_preds)
使用選項posterior_sampling生成模型,因為這可以使獲得的(隨機)預測很好地分布(具有良好的理論屬性,在這里我們參考[2]以獲得詳細資訊),
然后,為了估計知識的不確定性,我們只計算模型預測的平均值的方差:
knowledge = np.var(ens_preds, axis=0)[:, 0]
我們得到以下結果:
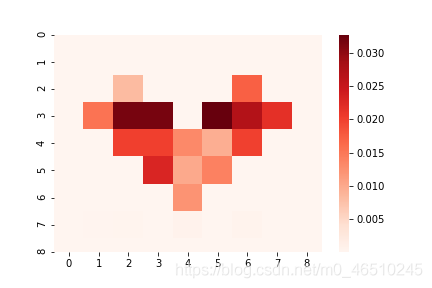
該模型正確檢測到心臟內部的知識不確定性(我們看不到原始心臟邊界的痕跡), 這說明了如何通過估計知識的不確定性來檢測例外輸入,
實際上,訓練多個CatBoost模型的集成可能太昂貴了, 理想情況下,我們希望訓練一個模型,但仍然能夠檢測例外值, 有一個解決方案:我們可以使用從單個訓練模型中獲得的虛擬集合:
def virt_ensemble(train_pool, val_pool, num_samples=10, iters=1000, lr=0.2):
ens_preds = []
model = CatBoostRegressor(iterations=iters, learning_rate=lr,
loss_function='RMSEWithUncertainty', posterior_sampling=True,
verbose=False, random_seed=0)
model.fit(train_pool, eval_set=val_pool)
ens_preds = model.virtual_ensembles_predict(test, prediction_type='VirtEnsembles',
virtual_ensembles_count=num_samples)
return np.asarray(ens_preds)
CatBoost通過一個訓練完成的模型回傳多個預測, 這些預測是通過截斷模型獲得的:

同樣,我們使用選項posterior_sampling來保證裁剪預測的理想分布, 讓我們看看我們得到了什么:
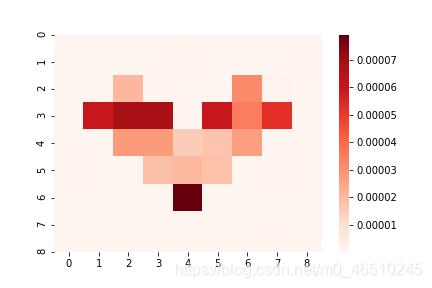
注意,由于虛擬集合元素是相關的,因此知識不確定性的預測絕對值現在要小得多, 但是,它仍然可以成功檢測到未被占用的區域(例外值),
代替回傳幾個模型的預測的prediction_type =“ VirtEnsembles”,我們可以使用prediction_type =“ TotalUncertainty”并使相同的結果更容易, 對于這種預測型別,CatBoost使用虛擬集合計算所有型別的不確定性, 即,對于RMSEWithUncertainty,它回傳以下統計資訊:[均值預測,知識不確定性,資料不確定性]:
model = CatBoostRegressor(iterations=1000, learning_rate=0.2,
loss_function='RMSEWithUncertainty', posterior_sampling=True,
verbose=False, random_seed=0)
model.fit(train_pool, eval_set=val_pool)
preds = model.virtual_ensembles_predict(test, prediction_type='TotalUncertainty',
virtual_ensembles_count=10)
mean_preds = preds[:,0] # mean values predicted by a virtual ensemble
knowledge = preds[:,1] # knowledge uncertainty predicted by a virtual ensemble
data = preds[:,2] # average estimated data uncertainty
感謝您的關注! 我希望本教程可以幫助您更好地了解不確定性的概念以及如何使用CatBoost進行估算, 我們將在以后的文章中詳細介紹不確定性的應用, 敬請期待😺
參考
[1] T. Duan et al., NGBoost: Natural Gradient Boosting for Probabilistic Prediction (2020), ICML 2020
[2] A. Ustimenko, L. Prokhorenkova and A. Malinin, Uncertainty in Gradient Boosting via Ensembles” (2020), arXiv preprint arXiv:2006.10562
本文代碼:https://github.com/catboost/catboost/blob/master/catboost/tutorials/uncertainty/uncertainty_regression.ipynb
作者:Liudmila Prokhorenkova
deephub翻譯組
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/168173.html
標籤:其他
上一篇:國慶后的第一天上班
下一篇:第六章 訪問權限控制