作者|Marcellus Ruben
編譯|VK
來源|Towards Datas Science

當你聽到“茶”和“咖啡”這個詞時,你會怎么看這兩個詞?也許你會說它們都是飲料,含有一定量的咖啡因,關鍵是,我們可以很容易地認識到這兩個詞是相互關聯的,然而,當我們把“tea”和“coffee”兩個詞提供給計算機時,它無法像我們一樣識別這兩個詞之間的關聯,
單詞不是計算機自然就能理解的東西,為了讓計算機理解單詞背后的意思,這個單詞需要被編碼成數字形式,這就是詞嵌入的用武之地,
詞嵌入是自然語言處理中常用的一種技術,將單詞轉換成向量形式的數值,這些向量將以一定的維數占據嵌入空間,
如果兩個詞有相似的語境,比如“tea”和“coffee”,那么這兩個詞在嵌入空間中的距離將彼此接近,而與具有不同語境的其他詞之間的距離則會更遠,
在這篇文章中,我將逐步向你展示如何可視化嵌入這個詞,由于本文的重點不是詳細解釋詞嵌入背后的基本理論,你可以在本文和本文中閱讀更多關于該理論的內容,
為了可視化詞嵌入,我們將使用常見的降維技術,如PCA和t-SNE,為了將單詞映射到嵌入空間中的向量表示,我們使用預訓練詞嵌入GloVe ,
加載預訓練好的詞嵌入模型
在可視化詞嵌入之前,通常我們需要先訓練模型,然而,詞嵌入訓練在計算上是非常昂貴的,因此,通常使用預訓練好的詞嵌入模型,它包含嵌入空間中的單詞及其相關的向量表示,
GloVe是斯坦福大學研究人員在Google開發的word2vec之外開發的一種流行的預訓練詞嵌入模型,在本文中,實作了GloVe預訓練的詞嵌入,你可以在這里下載它,
https://nlp.stanford.edu/projects/glove/
同時,我們可以使用Gensim庫來加載預訓練好的詞嵌入模型,可以使用pip命令安裝庫,如下所示,
pip install gensim
作為第一步,我們需要將GloVe檔案格式轉換為word2vec檔案格式,通過word2vec檔案格式,我們可以使用Gensim庫將預訓練好的詞嵌入模型加載到記憶體中,由于每次呼叫此命令時,加載此檔案都需要一些時間,因此,如果僅為此目的而使用單獨的Python檔案,則會更好,
import pickle
from gensim.test.utils import datapath, get_tmpfile
from gensim.models import KeyedVectors
from gensim.scripts.glove2word2vec import glove2word2vec
glove_file = datapath('C:/Users/Desktop/glove.6B.100d.txt')
word2vec_glove_file = get_tmpfile("glove.6B.100d.word2vec.txt")
glove2word2vec(glove_file, word2vec_glove_file)
model = KeyedVectors.load_word2vec_format(word2vec_glove_file)
filename = 'glove2word2vec_model.sav'
pickle.dump(model, open(filename, 'wb'))
創建輸入詞并生成相似單詞
現在我們有了一個Python檔案來加載預訓練的模型,接下來我們可以在另一個Python檔案中呼叫它來根據輸入詞生成最相似的單詞,輸入詞可以是任何詞,
輸入單詞后,下一步就是創建一個代碼來讀取它,然后,我們需要根據模型生成的每個輸入詞指定相似單詞的數量,最后,我們將相似單詞的結果存盤在一個串列中,下面是實作此目的的代碼,
import pickle
filename = 'glove2word2vec_model.sav'
model = pickle.load(open(filename, 'rb'))
def append_list(sim_words, words):
list_of_words = []
for i in range(len(sim_words)):
sim_words_list = list(sim_words[i])
sim_words_list.append(words)
sim_words_tuple = tuple(sim_words_list)
list_of_words.append(sim_words_tuple)
return list_of_words
input_word = 'school'
user_input = [x.strip() for x in input_word.split(',')]
result_word = []
for words in user_input:
sim_words = model.most_similar(words, topn = 5)
sim_words = append_list(sim_words, words)
result_word.extend(sim_words)
similar_word = [word[0] for word in result_word]
similarity = [word[1] for word in result_word]
similar_word.extend(user_input)
labels = [word[2] for word in result_word]
label_dict = dict([(y,x+1) for x,y in enumerate(set(labels))])
color_map = [label_dict[x] for x in labels]
舉個例子,假設我們想找出與“school”相關聯的5個最相似的單詞,因此,“school”將是我們的輸入詞,我們的結果是‘college’, ‘schools’, ‘elementary’, ‘students’, 和‘student’,
基于PCA的可視化詞嵌入
現在,我們已經有了輸入詞和基于它生成的相似詞,下一步,是時候讓我們把它們在嵌入空間中可視化了,
通過預訓練的模型,每個單詞都可以用向量表示映射到嵌入空間中,然而,詞嵌入具有很高的維數,這意味著無法可視化單詞,
通常采用主成分分析(PCA)等方法來降低詞嵌入的維數,簡言之,PCA是一種特征提取技術,它將變陣列合起來,然后在保留變數中有價值的部分的同時去掉最不重要的變數,如果你想深入研究PCA,我推薦這篇文章,
https://towardsdatascience.com/a-one-stop-shop-for-principal-component-analysis-5582fb7e0a9c
有了PCA,我們可以在2D或3D中可視化詞嵌入,因此,讓我們創建代碼,使用我們在上面代碼塊中呼叫的模型來可視化詞嵌入,在下面的代碼中,只顯示三維可視化,為了在二維可視化主成分分析,只應用微小的改變,你可以在代碼的注釋部分找到需要更改的部分,
import plotly
import numpy as np
import plotly.graph_objs as go
from sklearn.decomposition import PCA
def display_pca_scatterplot_3D(model, user_input=None, words=None, label=None, color_map=None, topn=5, sample=10):
if words == None:
if sample > 0:
words = np.random.choice(list(model.vocab.keys()), sample)
else:
words = [ word for word in model.vocab ]
word_vectors = np.array([model[w] for w in words])
three_dim = PCA(random_state=0).fit_transform(word_vectors)[:,:3]
# 對于2D,將three_dim變數改為two_dim,如下所示:
# two_dim = PCA(random_state=0).fit_transform(word_vectors)[:,:2]
data = https://www.cnblogs.com/panchuangai/archive/2020/10/13/[]
count = 0
for i in range (len(user_input)):
trace = go.Scatter3d(
x = three_dim[count:count+topn,0],
y = three_dim[count:count+topn,1],
z = three_dim[count:count+topn,2],
text = words[count:count+topn],
name = user_input[i],
textposition ="top center",
textfont_size = 20,
mode = 'markers+text',
marker = {
'size': 10,
'opacity': 0.8,
'color': 2
}
)
#對于2D,不是使用go.Scatter3d,我們需要用go.Scatter并洗掉變數z,另外,不要使用變數three_dim,而是使用前面宣告的變數(例如two_dim)
data.append(trace)
count = count+topn
trace_input = go.Scatter3d(
x = three_dim[count:,0],
y = three_dim[count:,1],
z = three_dim[count:,2],
text = words[count:],
name = 'input words',
textposition = "top center",
textfont_size = 20,
mode = 'markers+text',
marker = {
'size': 10,
'opacity': 1,
'color': 'black'
}
)
# 對于2D,不是使用go.Scatter3d,我們需要用go.Scatter并洗掉變數z,另外,不要使用變數three_dim,而是使用前面宣告的變數(例如two_dim)
data.append(trace_input)
# 配置布局
layout = go.Layout(
margin = {'l': 0, 'r': 0, 'b': 0, 't': 0},
showlegend=True,
legend=dict(
x=1,
y=0.5,
font=dict(
family="Courier New",
size=25,
color="black"
)),
font = dict(
family = " Courier New ",
size = 15),
autosize = False,
width = 1000,
height = 1000
)
plot_figure = go.Figure(data = https://www.cnblogs.com/panchuangai/archive/2020/10/13/data, layout = layout)
plot_figure.show()
display_pca_scatterplot_3D(model, user_input, similar_word, labels, color_map)
舉個例子,讓我們假設我們想把最相似的5個詞與“ball”、“school”和“food”聯系起來,下面是二維可視化的例子,
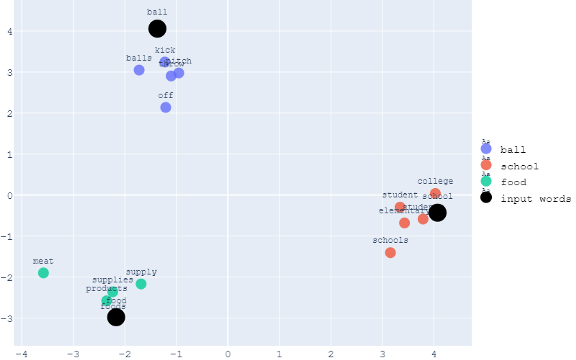
下面是同一組單詞的三維可視化,
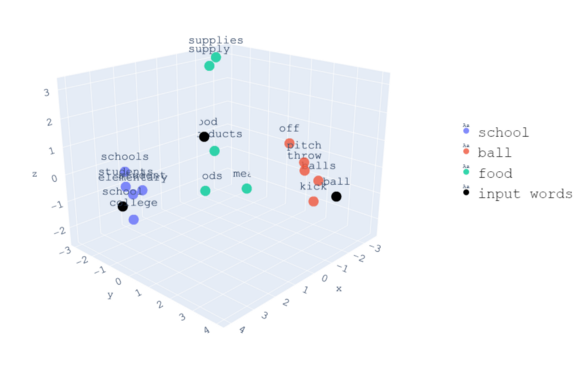
從視覺上,我們現在可以看到關于這些詞所占空間的模式,與“ball”相關的單詞彼此靠近,因為它們具有相似的背景關系,同時,它們與“學校”和“食物”相關的詞之間的距離因它們的語境不同而進一步不同,
基于t-SNE的可視化詞嵌入
除了PCA,另一種常用的降維技術是t分布隨機鄰域嵌入(t-SNE),PCA和t-SNE的區別是它們實作降維的基本技術,
PCA是一種線性降維方法,將高維空間中的資料線性映射到低維空間,同時使資料的方差最大化,同時,t-SNE是一種非線性降維方法,該演算法利用t-SNE計算高維和低維空間的相似性,其次,利用一種優化方法,例如梯度下降法,最小化兩個空間中的相似性差異,
用t-SNE實作詞嵌入的可視化代碼與PCA的代碼非常相似,在下面的代碼中,只顯示三維可視化,為了使t-SNE在2D中可視化,只需應用微小的更改,你可以在代碼的注釋部分找到需要更改的部分,
import plotly
import numpy as np
import plotly.graph_objs as go
from sklearn.manifold import TSNE
def display_tsne_scatterplot_3D(model, user_input=None, words=None, label=None, color_map=None, perplexity = 0, learning_rate = 0, iteration = 0, topn=5, sample=10):
if words == None:
if sample > 0:
words = np.random.choice(list(model.vocab.keys()), sample)
else:
words = [ word for word in model.vocab ]
word_vectors = np.array([model[w] for w in words])
three_dim = TSNE(n_components = 3, random_state=0, perplexity = perplexity, learning_rate = learning_rate, n_iter = iteration).fit_transform(word_vectors)[:,:3]
# 對于2D,將three_dim變數改為two_dim,如下所示:
# two_dim = TSNE(n_components = 2, random_state=0, perplexity = perplexity, learning_rate = learning_rate, n_iter = iteration).fit_transform(word_vectors)[:,:2]
data = https://www.cnblogs.com/panchuangai/archive/2020/10/13/[]
count = 0
for i in range (len(user_input)):
trace = go.Scatter3d(
x = three_dim[count:count+topn,0],
y = three_dim[count:count+topn,1],
z = three_dim[count:count+topn,2],
text = words[count:count+topn],
name = user_input[i],
textposition ="top center",
textfont_size = 20,
mode = 'markers+text',
marker = {
'size': 10,
'opacity': 0.8,
'color': 2
}
)
# 對于2D,不是使用go.Scatter3d,我們需要用go.Scatter并洗掉變數z,另外,不要使用變數three_dim,而是使用前面宣告的變數(例如two_dim)
data.append(trace)
count = count+topn
trace_input = go.Scatter3d(
x = three_dim[count:,0],
y = three_dim[count:,1],
z = three_dim[count:,2],
text = words[count:],
name = 'input words',
textposition = "top center",
textfont_size = 20,
mode = 'markers+text',
marker = {
'size': 10,
'opacity': 1,
'color': 'black'
}
)
# 對于2D,不是使用go.Scatter3d,我們需要用go.Scatter并洗掉變數z,另外,不要使用變數three_dim,而是使用前面宣告的變數(例如two_dim)
data.append(trace_input)
# 配置布局
layout = go.Layout(
margin = {'l': 0, 'r': 0, 'b': 0, 't': 0},
showlegend=True,
legend=dict(
x=1,
y=0.5,
font=dict(
family="Courier New",
size=25,
color="black"
)),
font = dict(
family = " Courier New ",
size = 15),
autosize = False,
width = 1000,
height = 1000
)
plot_figure = go.Figure(data = https://www.cnblogs.com/panchuangai/archive/2020/10/13/data, layout = layout)
plot_figure.show()
display_tsne_scatterplot_3D(model, user_input, similar_word, labels, color_map, 5, 500, 10000)
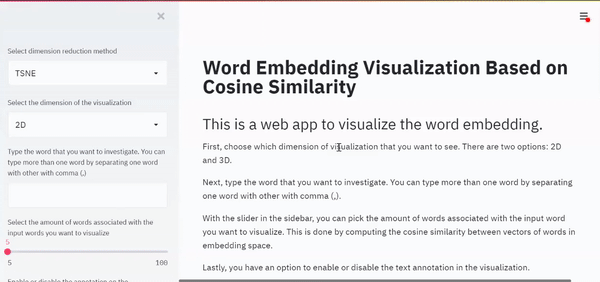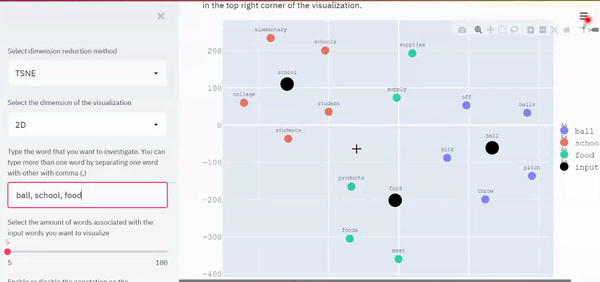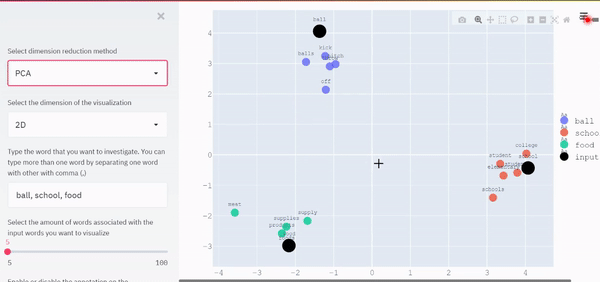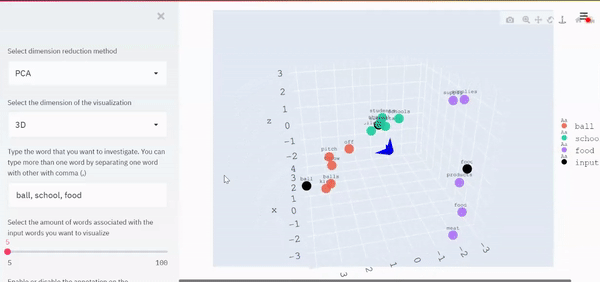
與PCA可視化中相同的示例,即與“ball”、“school”和“food”相關的前5個最相似的單詞的可視化結果如下所示,
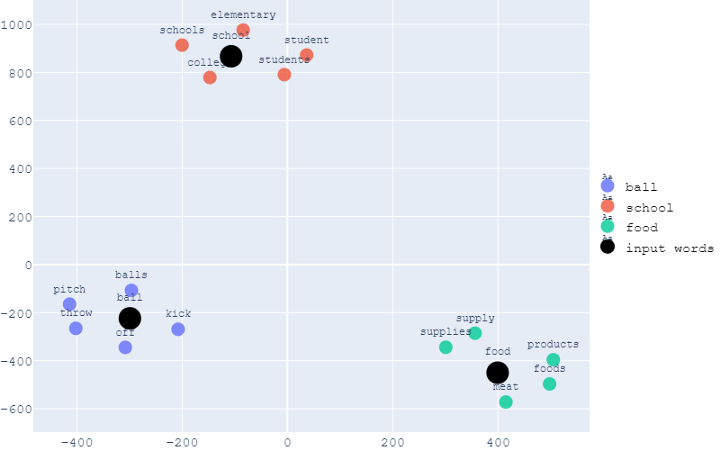
下面是同一組單詞的三維可視化,
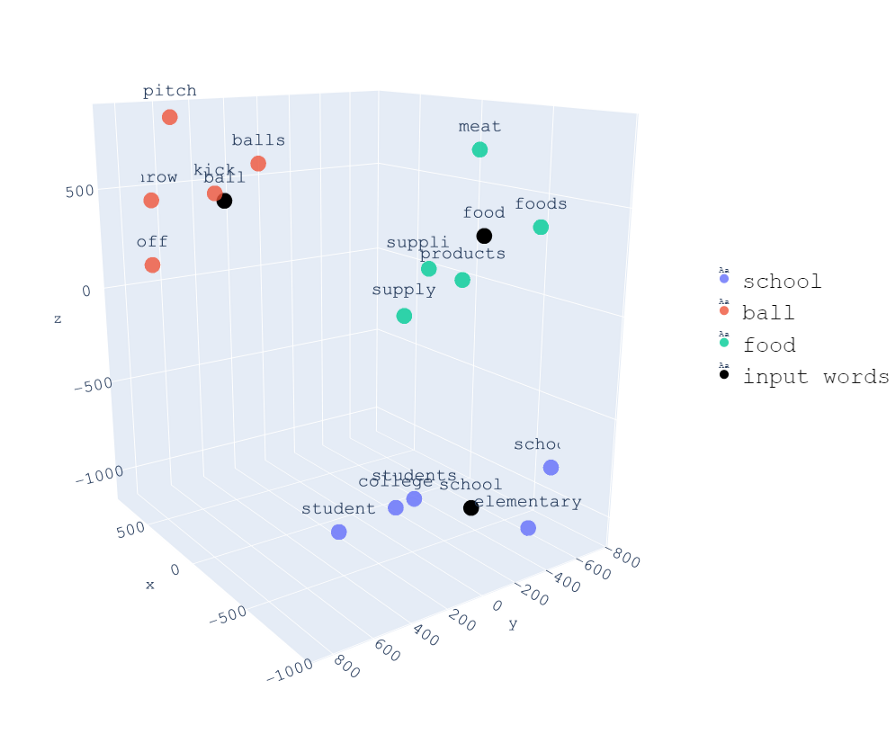
與PCA相同,注意具有相似背景關系的單詞彼此靠近,而具有不同背景關系的單詞則距離更遠,
創建一個Web應用來可視化詞嵌入
到目前為止,我們已經成功地創建了一個Python腳本,用PCA或t-SNE將詞嵌入到2D或3D中,接下來,我們可以創建一個Python腳本來構建一個web應用程式,以獲得更好的用戶體驗,
這個web應用程式使我們能夠用大量的功能和互動性來可視化詞嵌入,例如,用戶可以鍵入自己的輸入詞,也可以選擇與將回傳的每個輸入詞相關聯的前n個最相似的單詞,
可以使用破折號或Streamlit創建web應用程式,在本文中,我將向你展示如何構建一個簡單的互動式web應用程式,以可視化Streamlit的詞嵌入,
首先,我們將使用之前創建的所有Python代碼,并將它們放入一個Python腳本中,接下來,我們可以開始創建幾個用戶輸入引數,如下所示:
-
降維技術,用戶可以選擇使用PCA還是t-SNE,因為只有兩個選項,所以我們可以使用Streamlit中的selectbox屬性,
-
可視化的維度,在這個維度中,用戶可以選擇將詞嵌入2D還是3D顯示,與之前一樣,我們可以使用selectbox屬性,
-
輸入單詞,這是一個用戶輸入引數,它要求用戶鍵入他們想要的輸入詞,例如“ball”、“school”和“food”,因此,我們可以使用text_input屬性,
-
Top-n最相似的單詞,其中用戶需要指定將回傳的每個輸入單詞關聯的相似單詞的數量,因為我們可以選擇任何數字,
接下來,我們需要考慮在我們決定使用t-SNE時會出現的引數,在t-SNE中,我們可以調整一些引數以獲得最佳的可視化結果,這些引數是復雜度、學習率和優化迭代次數,因此,在每個情況下,讓用戶指定這些引數的最佳值是不存在的,
因為我們使用的是Scikit learn,所以我們可以參考檔案來找出這些引數的默認值,perplexity 的默認值是30,但是我們可以在5到50之間調整該值,學習率的默認值是300,但是我們可以在10到1000之間調整該值,最后,迭代次數的默認值是1000,但我們可以將該值調整為250,我們可以使用slider屬性來創建這些引數值,
import streamlit as st
dim_red = st.sidebar.selectbox(
'Select dimension reduction method',
('PCA','TSNE'))
dimension = st.sidebar.selectbox(
"Select the dimension of the visualization",
('2D', '3D'))
user_input = st.sidebar.text_input("Type the word that you want to investigate. You can type more than one word by separating one word with other with comma (,)",'')
top_n = st.sidebar.slider('Select the amount of words associated with the input words you want to visualize ',
5, 100, (5))
annotation = st.sidebar.radio(
"Enable or disable the annotation on the visualization",
('On', 'Off'))
if dim_red == 'TSNE':
perplexity = st.sidebar.slider('Adjust the perplexity. The perplexity is related to the number of nearest neighbors that is used in other manifold learning algorithms. Larger datasets usually require a larger perplexity',
5, 50, (30))
learning_rate = st.sidebar.slider('Adjust the learning rate',
10, 1000, (200))
iteration = st.sidebar.slider('Adjust the number of iteration',
250, 100000, (1000))
現在我們已經介紹了構建我們的web應用程式所需的所有部分,最后,我們可以把這些東西打包成一個完整的腳本,如下所示,
import plotly
import plotly.graph_objs as go
import numpy as np
import pickle
import streamlit as st
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
filename = 'glove2word2vec_model.sav'
model = pickle.load(open(filename, 'rb'))
def append_list(sim_words, words):
list_of_words = []
for i in range(len(sim_words)):
sim_words_list = list(sim_words[i])
sim_words_list.append(words)
sim_words_tuple = tuple(sim_words_list)
list_of_words.append(sim_words_tuple)
return list_of_words
def display_scatterplot_3D(model, user_input=None, words=None, label=None, color_map=None, annotation='On', dim_red = 'PCA', perplexity = 0, learning_rate = 0, iteration = 0, topn=0, sample=10):
if words == None:
if sample > 0:
words = np.random.choice(list(model.vocab.keys()), sample)
else:
words = [ word for word in model.vocab ]
word_vectors = np.array([model[w] for w in words])
if dim_red == 'PCA':
three_dim = PCA(random_state=0).fit_transform(word_vectors)[:,:3]
else:
three_dim = TSNE(n_components = 3, random_state=0, perplexity = perplexity, learning_rate = learning_rate, n_iter = iteration).fit_transform(word_vectors)[:,:3]
color = 'blue'
quiver = go.Cone(
x = [0,0,0],
y = [0,0,0],
z = [0,0,0],
u = [1.5,0,0],
v = [0,1.5,0],
w = [0,0,1.5],
anchor = "tail",
colorscale = [[0, color] , [1, color]],
showscale = False
)
data = https://www.cnblogs.com/panchuangai/archive/2020/10/13/[quiver]
count = 0
for i in range (len(user_input)):
trace = go.Scatter3d(
x = three_dim[count:count+topn,0],
y = three_dim[count:count+topn,1],
z = three_dim[count:count+topn,2],
text = words[count:count+topn] if annotation =='On' else '',
name = user_input[i],
textposition = "top center",
textfont_size = 30,
mode = 'markers+text',
marker = {
'size': 10,
'opacity': 0.8,
'color': 2
}
)
data.append(trace)
count = count+topn
trace_input = go.Scatter3d(
x = three_dim[count:,0],
y = three_dim[count:,1],
z = three_dim[count:,2],
text = words[count:],
name = 'input words',
textposition = "top center",
textfont_size = 30,
mode = 'markers+text',
marker = {
'size': 10,
'opacity': 1,
'color': 'black'
}
)
data.append(trace_input)
# 配置布局
layout = go.Layout(
margin = {'l': 0, 'r': 0, 'b': 0, 't': 0},
showlegend=True,
legend=dict(
x=1,
y=0.5,
font=dict(
family="Courier New",
size=25,
color="black"
)),
font = dict(
family = " Courier New ",
size = 15),
autosize = False,
width = 1000,
height = 1000
)
plot_figure = go.Figure(data = https://www.cnblogs.com/panchuangai/archive/2020/10/13/data, layout = layout)
st.plotly_chart(plot_figure)
def horizontal_bar(word, similarity):
similarity = [ round(elem, 2) for elem in similarity ]
data = go.Bar(
x= similarity,
y= word,
orientation='h',
text = similarity,
marker_color= 4,
textposition='auto')
layout = go.Layout(
font = dict(size=20),
xaxis = dict(showticklabels=False, automargin=True),
yaxis = dict(showticklabels=True, automargin=True,autorange="reversed"),
margin = dict(t=20, b= 20, r=10)
)
plot_figure = go.Figure(data = https://www.cnblogs.com/panchuangai/archive/2020/10/13/data, layout = layout)
st.plotly_chart(plot_figure)
def display_scatterplot_2D(model, user_input=None, words=None, label=None, color_map=None, annotation='On', dim_red = 'PCA', perplexity = 0, learning_rate = 0, iteration = 0, topn=0, sample=10):
if words == None:
if sample > 0:
words = np.random.choice(list(model.vocab.keys()), sample)
else:
words = [ word for word in model.vocab ]
word_vectors = np.array([model[w] for w in words])
if dim_red == 'PCA':
two_dim = PCA(random_state=0).fit_transform(word_vectors)[:,:2]
else:
two_dim = TSNE(random_state=0, perplexity = perplexity, learning_rate = learning_rate, n_iter = iteration).fit_transform(word_vectors)[:,:2]
data = https://www.cnblogs.com/panchuangai/archive/2020/10/13/[]
count = 0
for i in range (len(user_input)):
trace = go.Scatter(
x = two_dim[count:count+topn,0],
y = two_dim[count:count+topn,1],
text = words[count:count+topn] if annotation =='On' else '',
name = user_input[i],
textposition = "top center",
textfont_size = 20,
mode = 'markers+text',
marker = {
'size': 15,
'opacity': 0.8,
'color': 2
}
)
data.append(trace)
count = count+topn
trace_input = go.Scatter(
x = two_dim[count:,0],
y = two_dim[count:,1],
text = words[count:],
name = 'input words',
textposition = "top center",
textfont_size = 20,
mode = 'markers+text',
marker = {
'size': 25,
'opacity': 1,
'color': 'black'
}
)
data.append(trace_input)
# 配置布局
layout = go.Layout(
margin = {'l': 0, 'r': 0, 'b': 0, 't': 0},
showlegend=True,
hoverlabel=dict(
bgcolor="white",
font_size=20,
font_family="Courier New"),
legend=dict(
x=1,
y=0.5,
font=dict(
family="Courier New",
size=25,
color="black"
)),
font = dict(
family = " Courier New ",
size = 15),
autosize = False,
width = 1000,
height = 1000
)
plot_figure = go.Figure(data = https://www.cnblogs.com/panchuangai/archive/2020/10/13/data, layout = layout)
st.plotly_chart(plot_figure)
dim_red = st.sidebar.selectbox('Select dimension reduction method',
('PCA','TSNE'))
dimension = st.sidebar.selectbox(
"Select the dimension of the visualization",
('2D', '3D'))
user_input = st.sidebar.text_input("Type the word that you want to investigate. You can type more than one word by separating one word with other with comma (,)",'')
top_n = st.sidebar.slider('Select the amount of words associated with the input words you want to visualize ',
5, 100, (5))
annotation = st.sidebar.radio(
"Enable or disable the annotation on the visualization",
('On', 'Off'))
if dim_red == 'TSNE':
perplexity = st.sidebar.slider('Adjust the perplexity. The perplexity is related to the number of nearest neighbors that is used in other manifold learning algorithms. Larger datasets usually require a larger perplexity',
5, 50, (30))
learning_rate = st.sidebar.slider('Adjust the learning rate',
10, 1000, (200))
iteration = st.sidebar.slider('Adjust the number of iteration',
250, 100000, (1000))
else:
perplexity = 0
learning_rate = 0
iteration = 0
if user_input == '':
similar_word = None
labels = None
color_map = None
else:
user_input = [x.strip() for x in user_input.split(',')]
result_word = []
for words in user_input:
sim_words = model.most_similar(words, topn = top_n)
sim_words = append_list(sim_words, words)
result_word.extend(sim_words)
similar_word = [word[0] for word in result_word]
similarity = [word[1] for word in result_word]
similar_word.extend(user_input)
labels = [word[2] for word in result_word]
label_dict = dict([(y,x+1) for x,y in enumerate(set(labels))])
color_map = [label_dict[x] for x in labels]
st.title('Word Embedding Visualization Based on Cosine Similarity')
st.header('This is a web app to visualize the word embedding.')
st.markdown('First, choose which dimension of visualization that you want to see. There are two options: 2D and 3D.')
st.markdown('Next, type the word that you want to investigate. You can type more than one word by separating one word with other with comma (,).')
st.markdown('With the slider in the sidebar, you can pick the amount of words associated with the input word you want to visualize. This is done by computing the cosine similarity between vectors of words in embedding space.')
st.markdown('Lastly, you have an option to enable or disable the text annotation in the visualization.')
if dimension == '2D':
st.header('2D Visualization')
st.write('For more detail about each point (just in case it is difficult to read the annotation), you can hover around each points to see the words. You can expand the visualization by clicking expand symbol in the top right corner of the visualization.')
display_pca_scatterplot_2D(model, user_input, similar_word, labels, color_map, annotation, dim_red, perplexity, learning_rate, iteration, top_n)
else:
st.header('3D Visualization')
st.write('For more detail about each point (just in case it is difficult to read the annotation), you can hover around each points to see the words. You can expand the visualization by clicking expand symbol in the top right corner of the visualization.')
display_pca_scatterplot_3D(model, user_input, similar_word, labels, color_map, annotation, dim_red, perplexity, learning_rate, iteration, top_n)
st.header('The Top 5 Most Similar Words for Each Input')
count=0
for i in range (len(user_input)):
st.write('The most similar words from '+str(user_input[i])+' are:')
horizontal_bar(similar_word[count:count+5], similarity[count:count+5])
count = count+top_n
現在可以使用Conda提示符運行web應用程式,在提示符中,轉到Python腳本的目錄并鍵入以下命令:
$ streamlit run your_script_name.py
接下來,會自動彈出一個瀏覽器視窗,你可以在這里本地訪問你的web應用程式,下面是你可以使用該web應用程式執行的操作的快照,
就這樣!你已經創建了一個簡單的web應用程式,它具有很多互動性,可以用PCA或t-SNE可視化詞嵌入,
如果你想看到這個詞嵌入可視化的全部代碼,你可以在我的GitHub頁面上訪問它,
https://github.com/marcellusruben/Word_Embedding_Visualization
原文鏈接:https://towardsdatascience.com/visualizing-word-embedding-with-pca-and-t-sne-961a692509f5
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/169938.html
標籤:其他
上一篇:如何使用paramiko模塊進行遠程互動?需要輸入yes/no的情況
下一篇:爬蟲