Ajax動態網頁加載爬取新浪微博某關鍵詞下的資訊
前言
有些時候我們使用瀏覽器查看頁面正常顯示的資料與使用requests抓取頁面html得到的資料不一致,這是因為requests獲取的是原始的HTML檔案,而瀏覽器中的頁面是經過JavaScript處理資料后的結果,這些處理過的資料可能是通過Ajax加載的,可能包含HTML檔案中,可能經過特定演算法計算后生成的,
一、Ajax原理
1、什么是Ajax?
Ajax全稱為Asynchronous JavaScript and XML,即為異步的JavaScript(JS語言)和XML(萬能的資料傳輸格式),
2、異步化?
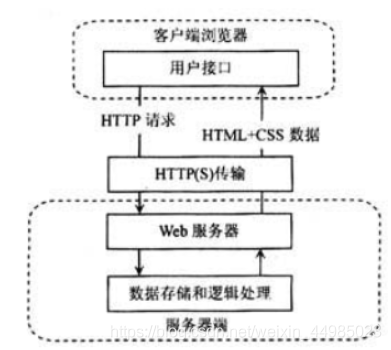
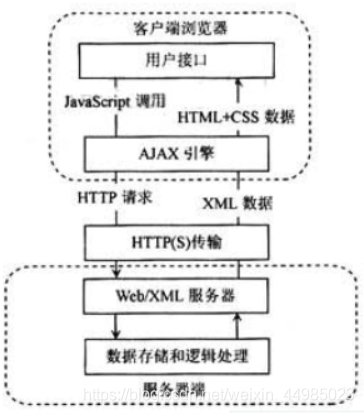
Ajax的作業原理相當于在用戶和服務器之間加了—個中間層(AJAX引擎),使用戶操作與服務器回應異步化,并不是所有的用戶請求都提交給服務器,像—些資料驗證和資料處理等都交給Ajax引擎自己來做,只有確定需要從服務器讀取新資料時再由Ajax引擎代為向服務器提交請求它能夠利用,JavaScript在保證不被重繪,連接不變的情況下,服務器交換資料并更新部分網頁的技術,像傳統的網頁(不使用Ajax)若要更新網頁內容,必須重新加載網頁,比如貓眼、豆瓣等,下圖為對比圖:
3、示例
瀏覽網頁的時候,我們發現很多網頁都有下滑查看更多的選項,比如,就拿新浪微博主頁來說,一直往下滑,看到幾個微博之后就沒有了,而是會出現一個加載的影片,很快就出現了新的微博內容,這個程序就是Ajax加載的程序
二、準備環境+爬取網站
ananconda3——spyder
谷歌瀏覽器
https://m.weibo.cn/
三、網頁分析與定位
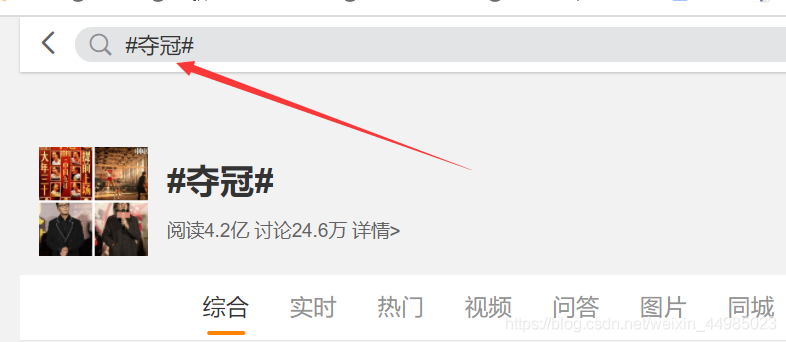
1、本次爬取選取“奪冠”這一關鍵詞
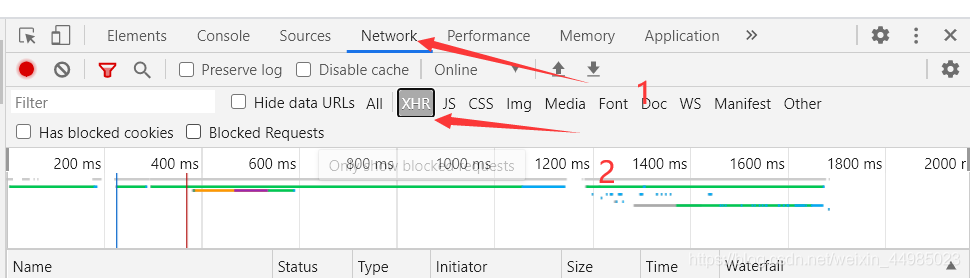
 2、檢查元素——Network——XHR——Ctrl+R
2、檢查元素——Network——XHR——Ctrl+R
 3、滑動頁面,依次查看前三頁page,Request URL中包含多個引數
3、滑動頁面,依次查看前三頁page,Request URL中包含多個引數
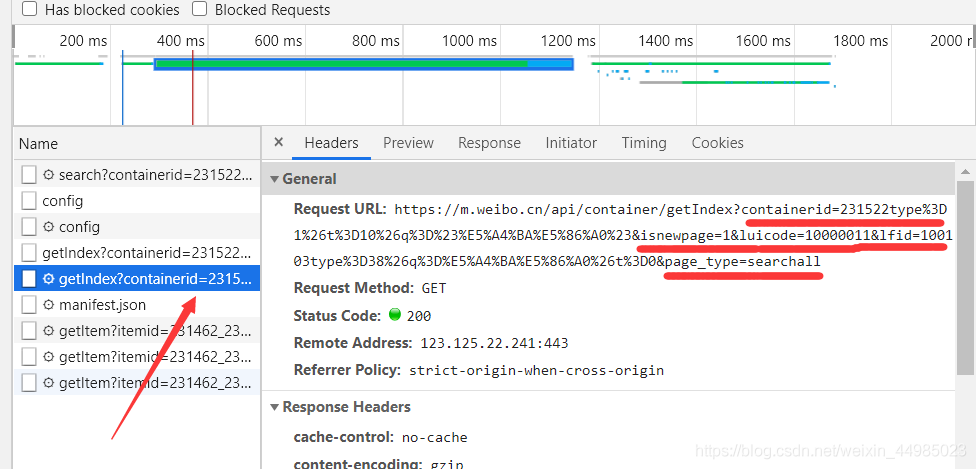
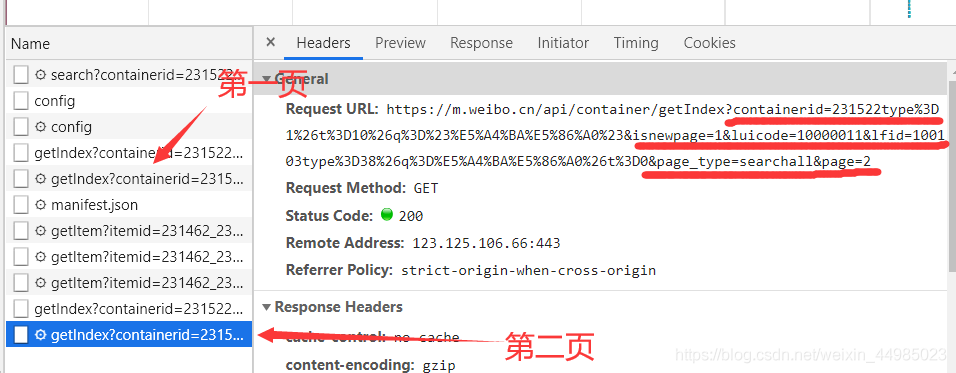
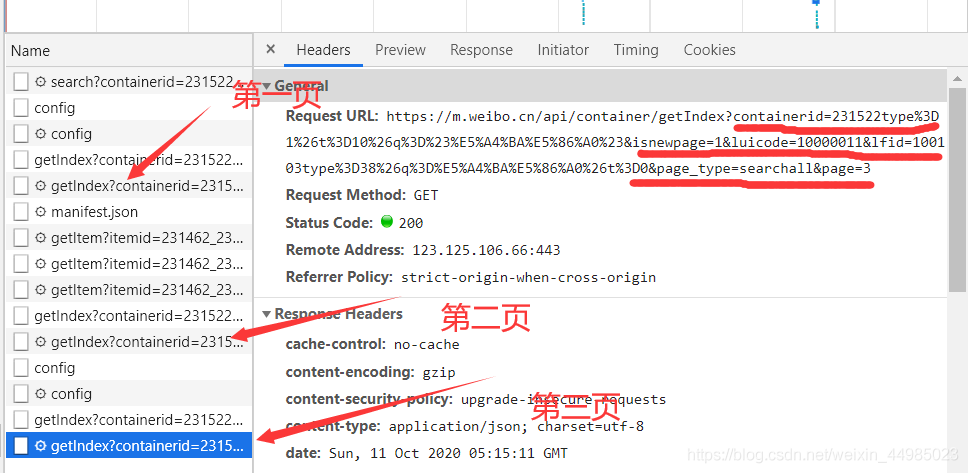 選了前三頁觀察,發現在Request URL里面除了最后page=2,page=3,其他引數都不發生變化
選了前三頁觀察,發現在Request URL里面除了最后page=2,page=3,其他引數都不發生變化
4、觀察Preview里面的資訊
想要獲取的資訊都在data——cards——mblog下面
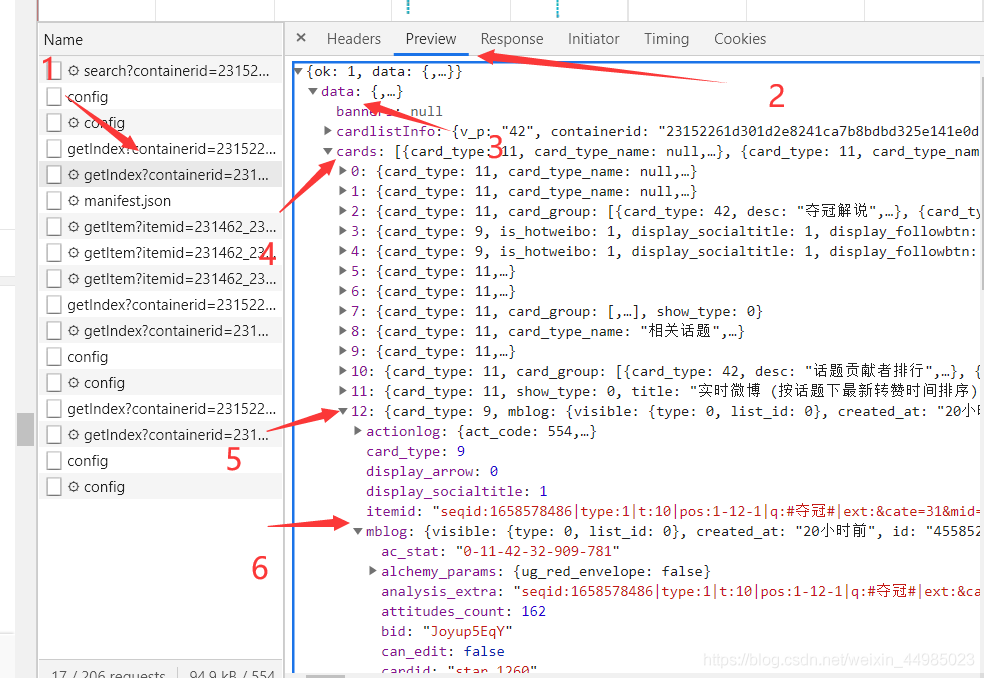
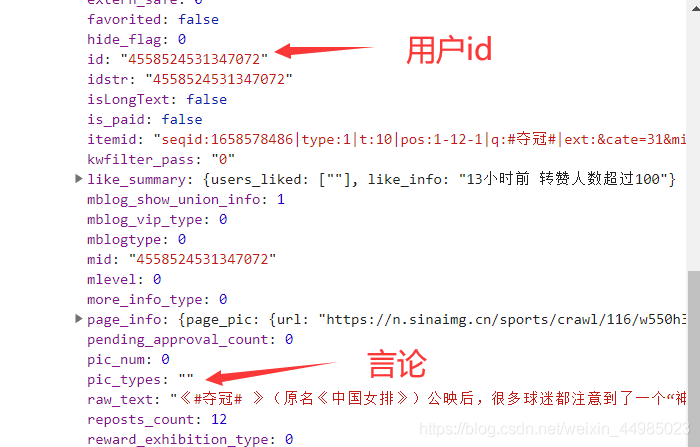
分別查詢三個頁面發現,只有在第一頁中時,有些cards下面不存在mblog,也就是說爬出來的內容可能會為空,所以本次爬取我舍去第一頁內容不全的,從page=2開始,這樣可以保證爬出來的內容比較全,
三、代碼實作
1、匯入庫
from urllib.parse import urlencode
import requests
import json
使用urlencode主要用于正常識別輸入的漢字、空格以及其他特殊字符,由于url中傳入了部分引數,所以需識別引數拼接為完整的url
輸出格式為物件格式:{“key1”:obj,“key2”:obj,“key3”:obj…},所以匯入json包
2、決議頁面
定義一個獲取頁面的函式,其中的引數params包含如下所示
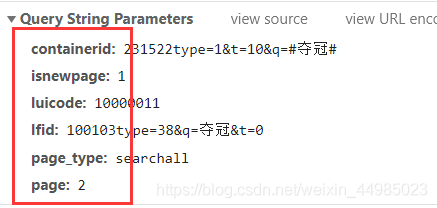
除了page以外,其他引數均不變,定義一個base_url,所有網頁的base_url為同一個,
base_url='https://m.weibo.cn/api/container/getIndex?'
 這里需要用到urlencode對引數進行轉化拼接,使其轉化并生成出每一頁完整的url
這里需要用到urlencode對引數進行轉化拼接,使其轉化并生成出每一頁完整的url
def get_page(page):
params = {
'containerid':'231522type=1&t=10&q=#奪冠#',
'page_type':'searchall',
'isnewpage':'1',
'luicode':'10000011',
'lfid':'100103type=38&q=奪冠&t=0',
'page_type': 'searchall',
'page':page
}
url = base_url + urlencode(params)
try:
rq = requests.get(url,headers = headers)
if rq.status_code == 200 :
return rq.json()
except rq.ConnectionError as e:
print('程式錯誤',e.args)
3、定位id和raw_text
第一個函式回傳rq.json(),目的是獲取如下界面的全部決議碼
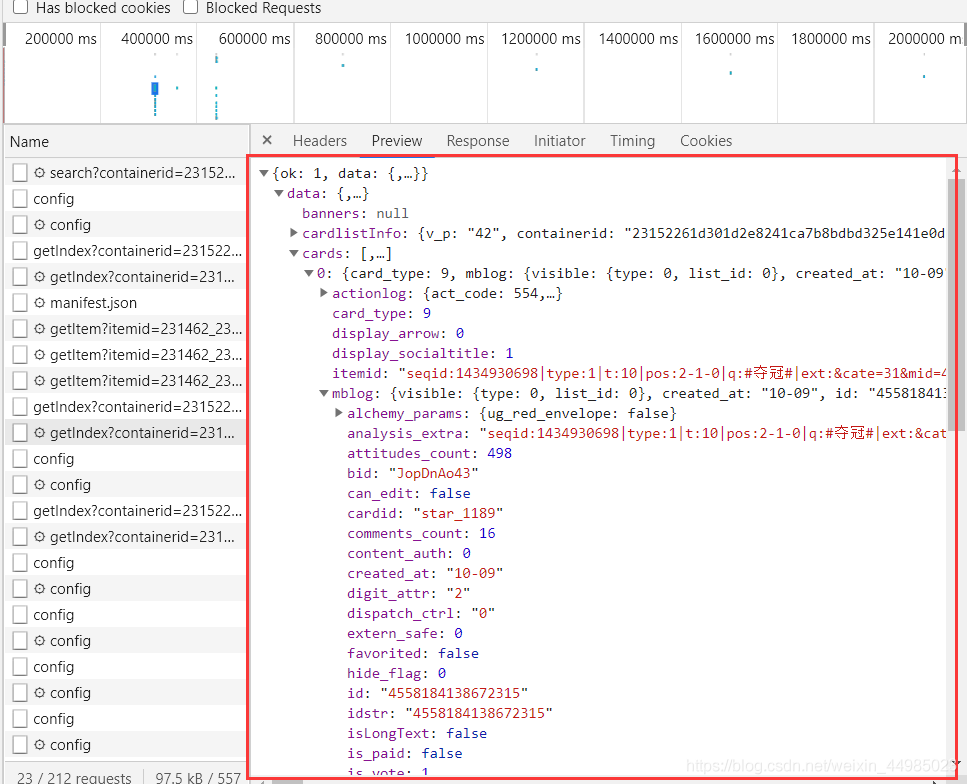 print(re.json())后,輸出全部內容
print(re.json())后,輸出全部內容
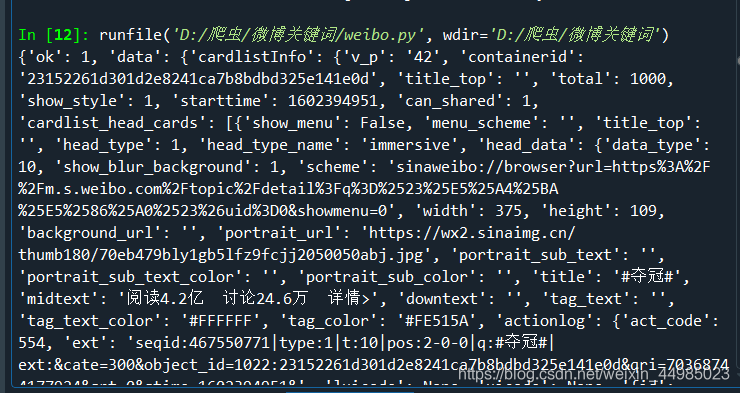
j = get_page(page)回傳那個決議頁面,從決議頁面里面找data——cards,items為cards下面所有的東西,我只想獲得mblog下的id和raw_text,所以用了一個回圈,先找到mblog用item接收,再再item下找到id用id接收,再找raw_text用raw_text接收,用append進行串列的依次添加,得到 all_id和all_raw_text,最后轉化為字典形式
def parse_page(j):
items = j['data']['cards']
all_id=[]
all_raw_text=[]
for item in items:
item = item['mblog']
id=item['id']
raw_text=item['raw_text']
all_id.append(id)
all_raw_text.append(raw_text)
weibo = dict(zip(all_id,all_raw_text)) #zip,將兩個串列合并成一個字典
return weibo
4、存入txt檔案
存入為json格式
def write_text(result):
with open('關鍵詞資訊.txt','a',encoding='utf-8') as f:
f.write(json.dumps(result, ensure_ascii=False) + '\n')
f.write('\n')
f.close()
5、主函式呼叫
Referer,User-Agent,X-Reuestes-With均在網頁里
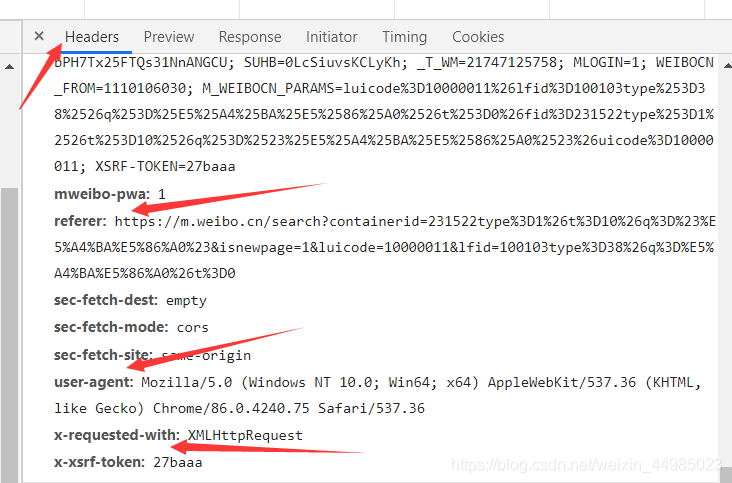
if __name__ == '__main__':
base_url = 'https://m.weibo.cn/api/container/getIndex?'
headers = {"Referer": 'https://m.weibo.cn/search?containerid=100103type%3D1%26q%3D%E5%A4%BA%E5%86%A0',
"User-Agent":'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36',
"X-Requested-With":'XMLHttpRequest'}
for page in range(2,50):
j = get_page(page)
result = parse_page(j)
print(result)
write_text(result)
四、結果展示
每個id對應一條微博資訊

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/169991.html
標籤:其他