前言
一般來說,現在的互聯網應用網站或者APP,它的整體流程可以用我們這個圖里展示的來表示,用戶請求開始,從這個界面是最里面的瀏覽器和APP,到網路轉發,再到應用服務,最后到存盤,這純屬可能是資料庫檔案系統,然后再回傳到界面呈現內容,
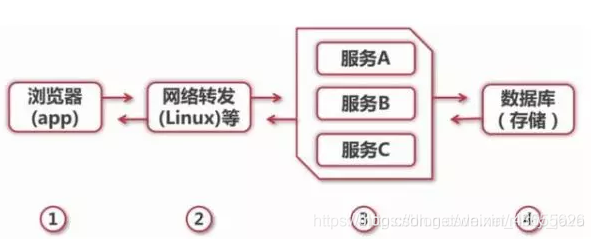
隨著互聯網的普及,內容資訊越來越復雜,用戶數和訪問量越來越大,我們的應用需要支撐更多的并發量,同時,我們的應用服務器和資料庫服務器所做的計算也越來越多,但是,往往我們的應用服務器的資源是有限的,而且技術變革是緩慢的,所以每秒能接收請求次數也是有限的,或者說檔案的讀寫也是有限的,
如何能有效利用有限的資源來提供盡可能大的吞吐量呢?一個有效的辦法就是引入快取,打破圖中的標準的流程,每個環節中請求可以從快取中直接獲取目標資料并回傳,從而減少他們的計算量,來有效提升回應速度,讓有限的資源服務更多的用戶,像我們這個圖里展示的快取的使用,它其實可以出現在1到4的各個環節中,
由于時間關系,可能沒有寫的很詳細,有需要完整版的朋友可以點一點下方鏈接免費領取
鏈接:1103806531暗號:CSDN

1 快取一致性問題
當資料時效性要求很高時,需要保證快取中的資料與資料庫中的保持一致,而且需要保證快取節點和副本中的資料也保持一致,不能出現差異現象,
這就比較依賴快取的過期和更新策略,一般會在資料發生更改的時,主動更新快取中的資料或者移除對應的快取,

2 快取并發問題
快取過期后將嘗試從后端資料庫獲取資料,這是一個看似合理的流程,但是,在高并發場景下,有可能多個請求并發的去從資料庫獲取資料,對后端資料庫造成極大的沖擊,甚至導致 “雪崩”現象,
此外,當某個快取key在被更新時,同時也可能被大量請求在獲取,這也會導致一致性的問題,那如何避免類似問題呢?
我們會想到類似“鎖”的機制,在快取更新或者過期的情況下,先嘗試獲取到鎖,當更新或者從資料庫獲取完成后再釋放鎖,其他的請求只需要犧牲一定的等待時間,即可直接從快取中繼續獲取資料,

3 快取穿透問題
快取穿透在有些地方也稱為“擊穿”,很多朋友對快取穿透的理解是:由于快取故障或者快取過期導致大量請求穿透到后端資料庫服務器,從而對資料庫造成巨大沖擊,
這其實是一種誤解,真正的快取穿透應該是這樣的:
在高并發場景下,如果某一個key被高并發訪問,沒有被命中,出于對容錯性考慮,會嘗試去從后端資料庫中獲取,從而導致了大量請求達到資料庫,而當該key對應的資料本身就是空的情況下,這就導致資料庫中并發的去執行了很多不必要的查詢操作,從而導致巨大沖擊和壓力,
可以通過下面的幾種常用方式來避免快取傳統問題:
(1)快取空物件
對查詢結果為空的物件也進行快取,如果是集合,可以快取一個空的集合(非null),如果是快取單個物件,可以通過欄位標識來區分,這樣避免請求穿透到后端資料庫,
同時,也需要保證快取資料的時效性,這種方式實作起來成本較低,比較適合命中不高,但可能被頻繁更新的資料,
(2)單獨過濾處理
對所有可能對應資料為空的key進行統一的存放,并在請求前做攔截,這樣避免請求穿透到后端資料庫,這種方式實作起來相對復雜,比較適合命中不高,但是更新不頻繁的資料,

4 快取顛簸問題
快取的顛簸問題,有些地方可能被成為“快取抖動”,可以看做是一種比“雪崩”更輕微的故障,但是也會在一段時間內對系統造成沖擊和性能影響,一般是由于快取節點故障導致,業內推薦的做法是通過一致性Hash演算法來解決,
5 快取的雪崩現象
快取雪崩就是指由于快取的原因,導致大量請求到達后端資料庫,從而導致資料庫崩潰,整個系統崩潰,發生災難,
導致這種現象的原因有很多種,上面提到的“快取并發”,“快取穿透”,“快取顛簸”等問題,其實都可能會導致快取雪崩現象發生,這些問題也可能會被惡意攻擊者所利用,
還有一種情況,例如某個時間點內,系統預加載的快取周期性集中失效了,也可能會導致雪崩,為了避免這種周期性失效,可以通過設定不同的過期時間,來錯開快取過期,從而避免快取集中失效,
從應用架構角度,我們可以通過限流、降級、熔斷等手段來降低影響,也可以通過多級快取來避免這種災難,
此外,從整個研發體系流程的角度,應該加強壓力測驗,盡量模擬真實場景,盡早的暴露問題從而防范,

6 快取無底洞現象
該問題由 facebook 的作業人員提出的, facebook 在 2010 年左右,memcached 節點就已經達3000 個,快取數千 G 內容,
他們發現了一個問題—memcached 連接頻率,效率下降了,于是加 memcached 節點,添加了后,發現因為連接頻率導致的問題,仍然存在,并沒有好轉,稱之為”無底洞現象”,

目前主流的資料庫、快取、Nosql、搜索中間件等技術堆疊中,都支持“分片”技術,來滿足“高性能、高并發、高可用、可擴展”等要求,
有些是在client端通過Hash取模(或一致性Hash)將值映射到不同的實體上,有些是在client端通過范圍取值的方式映射的,當然,也有些是在服務端進行的,
但是,每一次操作都可能需要和不同節點進行網路通信來完成,實體節點越多,則開銷會越大,對性能影響就越大,
主要可以從如下幾個方面避免和優化:
(1)資料分布方式
有些業務資料可能適合Hash分布,而有些業務適合采用范圍分布,這樣能夠從一定程度避免網路IO的開銷,
(2)IO優化
可以充分利用連接池,NIO等技術來盡可能降低連接開銷,增強并發連接能力,
(3)資料訪問方式
一次性獲取大的資料集,會比分多次去獲取小資料集的網路IO開銷更小,
當然,快取無底洞現象并不常見,在絕大多數的公司里可能根本不會遇到,
總結
希望這篇文章對大家有幫助!
這邊還有各個知識點模塊整理檔案和更多大廠面試真題,有需要的朋友可以點一點下方鏈接免費領取
鏈接:1103806531暗號:CSDN

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/171584.html
標籤:其他