深入Linux內核(記憶體篇)—頁表映射
- 一、分頁
- 1.1 頁表存在哪里?
- 1.2 頁表長啥樣?
- 1.3 分頁機制如何完成行程地址空間切換?
- 1.4 實際使用的分頁機制
- 1.5 多級頁表的缺點
- 1.6 Translation Lookside Buffer
- 1.7 頁表多大合適?
- 二、X86中的分頁
- 2.1 32-bit Paging
- 2.2 32-bit Paging頁表長啥樣?
- 2.3 4-Level Paging
- 三、ARM中的分頁
- 3.1 ARMv7 Paging
- 3.2 ARMv7 4KB Paging頁表長啥樣?
- 3.3 ARMv8 分頁配置
- 3.4 ARMv8 Paging
- 四、Kernel中的分頁
- 4.1 X86分頁
- 4.1 ARMv7分頁
- 4.2 ARMv8分頁
作業系統的核心任務是對系統資源的管理,而重中之重的是對CPU和記憶體的管理,為了使行程擺脫系統記憶體的制約,用戶行程運行在虛擬記憶體之上,每個用戶行程都擁有完整的虛擬地址空間,互不干涉,
而實作虛擬記憶體的關鍵就在于建立虛擬地址(Virtual Address,VA)與物理地址(Physical Address,PA)之間的關系,因為無論如何資料終究要存盤到物理記憶體中才能被記錄下來,
如下圖所示,行程1和行程2擁有完整的虛擬地址空間,虛擬地址空間分為了用戶空間和內核空間,對于不同的行程面對的都是同一個內核,其內核空間的地址對于的物理地址都是一樣的,因而行程1和行程2中內核空間的VA K地址都映射到了物理記憶體的PA K地址,而不同的行程的用戶空間是不同的,行程1和行程2相同的虛擬地址VA 1和VA 2分別映射到了不同的物理地址PA 1和PA 2上,
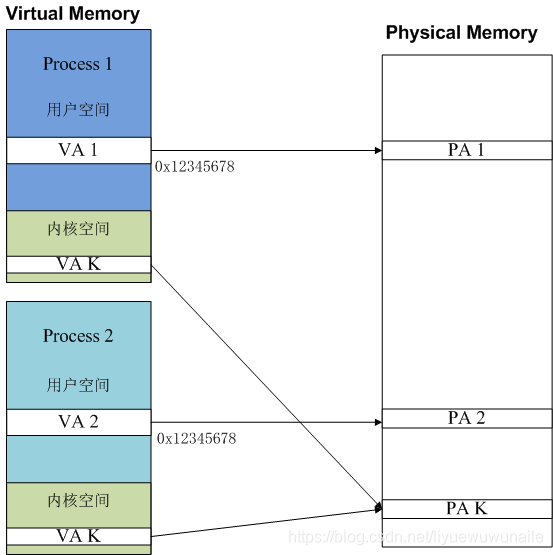
而虛擬地址到物理地址映射關系的實作可以稱之為地址轉換(Address Translation),
為了實作上述地址轉換,作業系統需要借助硬體的幫助,即記憶體管理單元(Memory Management Unit,MMU)的幫助,
對于MMU應當有如下功能:
| 要求 | 說明 |
|---|---|
| 特權模式 | 區分內核空間和用戶空間,用戶行程無法直接訪問內核地址空間 |
| 基址/界限暫存器 | 記錄地址轉換基址的暫存器,用于尋址地址轉換映射表 |
| 地址轉換 | 完成地址轉換程序 |
| 檢查越界 | 完成地址轉換程序中,可以檢查訪問是否越界 |
| 基址/界限暫存器特權操作指令 | 用于修改地址轉換基址的暫存器,可以保證不同行程訪問的映射表不同,從而映射的結果也不同 |
| 觸發例外 | 發生越權,越界訪問時,可以觸發例外通知作業系統 |
| 例外處理特權操作指令 | 作業系統用于處理記憶體訪問例外的入口 |
MMU配合作業系統完成了諸多功能:
- 用戶空間和內核空間,通過特權模式劃分了內核空間和用戶空間,用戶空間無法直接訪問內核空間,必須通過某些手段(系統呼叫,例外,中斷等)切換到特權模式才能間接訪問內核,
- 地址轉換,通過基址/界限暫存器記錄的轉換映射表基址,結合虛擬地址,可以完成地址轉換的功能,從而實作通過虛擬地址訪問到物理地址,
- 行程獨立的虛擬地址空間,通過基址/界限暫存器的訪問指令,在行程切換時修改基址/界限暫存器的值,從而使MMU在做地址轉換時找到各個行程對應的地址映射表,從而實作不同行程虛擬地址完全獨立,
- 缺頁例外,對于行程申請的記憶體,并不需要在其申請記憶體時即建立地址轉換映射表,同時分配對應的物理空間,而是在行程真正訪問記憶體地址時,MMU上報缺頁例外再分配對應的物理空間,當然虛擬地址到物理地址映射表中的一些標志區可以實作更多的缺頁例外型別,例如讀寫權限錯誤,特權錯誤,越界錯誤等例外,
本文重點關注地址轉換,而地址轉換的核心是頁表映射,
一、分頁
分頁即將記憶體劃分為固定長度的單元,每個單元就是一頁,
對于虛擬地址空間,分頁機制將地址空間分割成固定大小的單元,每個單元稱為一頁,對于物理地址空間,物理記憶體被抽象成固定大小的單元,每個單元稱為頁幀(frame),通過分頁管理記憶體可以避免分段帶來的記憶體外碎片問題,
分頁管理記憶體的核心問題是虛擬地址頁到物理地址頁幀的映射關系,
虛擬地址到物理地址的轉換可以抽象簡化成下圖,假設地址是32位的,
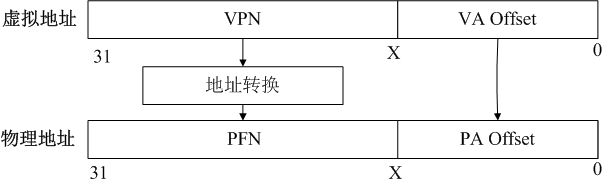
為了將虛擬地址轉換成物理地址,將虛擬地址分割成兩部分:
- 虛擬頁面號,高31-X位組成,VPN(virtual page number);
- 虛擬地址偏移,低X位組成,VA Offset(virtual address offset);
物理地址也抽象成兩部分:
- 物理頁幀號,高31-X位組成,PFN(physical frame number);
- 物理地址偏移,低X位組成,PA Offset(physical address offset);
虛擬頁面號VPN用于索引物理頁幀號PFN,VPN索引PFN的程序就是地址轉換的核心,VA offset通常就是PA offset,即PFN + VA offset就是最終物理地址,
所以,可以說分頁機制的核心就是VPN到PFN的映射,而VPN到PFN的映射關系是通過頁表記錄的,MMU通過頁表記錄的映射關系完成VPN到PFN的轉換,即找到了頁表就找到了物理地址,
1.1 頁表存在哪里?
以32位地址空間為例,分頁大小為4KB(最常用的分頁大小),上述抽象例子中的X為12,那么VPN長度就是20bit,偏移量為12bit,
20bit的VPN意味著作業系統需要2^20個地址轉換映射,假設每個轉換映射需要4Byte空間存盤,那么所有映射關系需要4MB空間,
開篇我們提到,行程的虛擬地址到物理地址的轉換是不同的,所以每個行程的映射關系也是不同的,就是說每個行程都需要4MB的空間來存盤頁表,如果作業系統運行100個行程,則需要400MB空間,
可見頁表所需要的空間是很大的,所以頁表都存盤在物理記憶體中,即MMU通將虛擬地址轉換為物理地址,需要訪問物理記憶體中對應的頁表,
當然頁表占用物理記憶體大的問題還是需要解決的,這是分頁相對于分段的一個劣勢,解決方案是多級頁表配合缺頁例外的方式,后面再詳細介紹多級頁表的機制,
1.2 頁表長啥樣?
頁表是如何完成VPN到PFN的轉換的,要知道這個問題就得清楚頁表的基本內容,即頁表記錄了什么資訊,
頁表的作用就是通過VPN找到PFN,那么頁表最基本的組成部分需要包含如下內容:
- PFN物理頁幀號;
- 有效位(valid),用于標記頁面是否有效;
- 存在位(present),指示該頁是否存在于物理記憶體,用于頁面換入換出(swap);
- 特權標記,指示頁面訪問的特權等級;
- Dirty位,寫操作時設定該位,表示頁面被寫過,頁面交換時使用;
1.3 分頁機制如何完成行程地址空間切換?
每個行程都擁有自己獨立的地址空間,行程切換時地址空間也會切換,不同行程都擁有自己的一套頁表,因而即使兩個行程虛擬地址相同,映射的物理地址也是不同的,
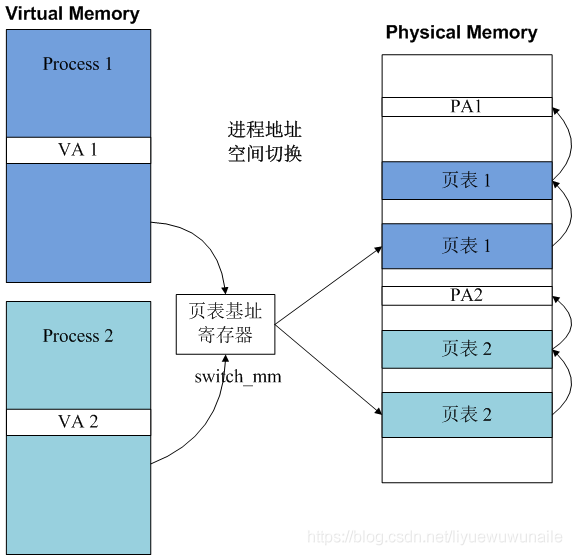
切換地址空間相當于控制MMU訪問不同行程擁有的頁表,MMU找到了頁表就找到了物理地址,
通常CPU會提供若干暫存器供作業系統使用,用于為MMU指示頁表的基地址,
如下圖所示,行程切換時,只需要設定頁表基址暫存器即可完成頁表的切換,也就完成了行程地址空間的切換,
所以CPU會為作業系統提供頁表基址暫存器用于行程地址空間的切換,
X86體系架構提供的暫存器是CR3(Control Register 3);ARM-v7體系架構提供的暫存器是協處理器CP15暫存器TTBR(Tranlation Table Base Register);ARM-v8體系架構提供的暫存器是系統暫存器TTBR(Tranlation Table Base Register),
1.4 實際使用的分頁機制
考慮到分頁機制占用記憶體過多的問題,實際的分頁機制是多級分頁,
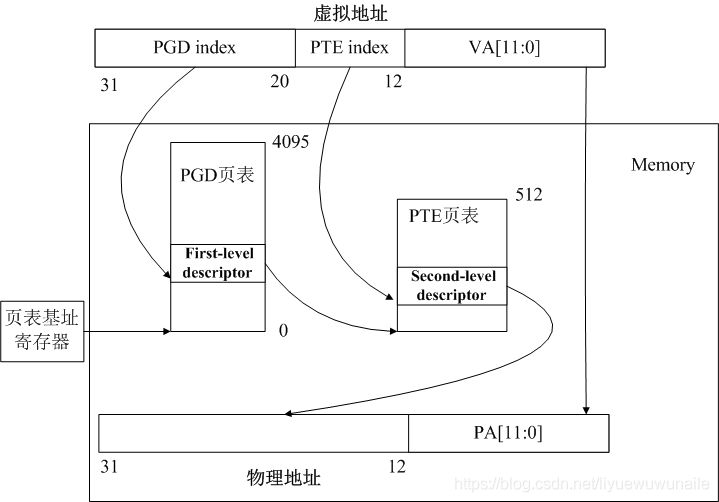
以二級頁表為例,如下圖所示,MMU通過頁表基址暫存器配合虛擬地址中的PGD index(Page Global Directory)找到一級頁表,通過一級頁表配合虛擬地址中的PTE index(Page Table Entry)找到二級頁表,通過二級頁表配合虛擬地址中Offset找到物理地址,
多級頁表要做到節省記憶體,還需要配合缺頁例外,行程往往只需將一級頁表保持到記憶體中,二級頁表在缺頁例外時再分配,
下圖示例中,一級頁表一共4096項(212),二級頁表一共512項(29),因此行程頁表可以只使用4096 X 4Byte空間即可,如果使用一級頁表,則需要2097152 X 4Byte空間,因此多級頁表帶來的最大好處就是降低了記憶體空間的占用,
1.5 多級頁表的缺點
多級頁表帶來了好處,降低了作業系統行程管理,記憶體管理對記憶體空間的占用,當然計算機領域總是沒有那么完美的方案,多級分頁也逃避不了這個宿命,獲得了空間的優勢,也帶來時間上的損失,
多級分頁時間上的損失主要體現在如下幾個方面:
- 用時下發的耗時:對于子行程寫時復制(COW)技術大家比較熟悉,其實多級頁表也利用了類似的思想,多級頁表的后幾級頁表映射關系沒有存在記憶體中,MMU地址轉換中發現頁表不存在需要向作業系統上報缺頁例外,作業系統需要在缺頁例外中下發頁表到記憶體;
- 額外的記憶體訪問:MMU進行地址轉換需要通過頁表基址暫存器找到一級頁表,再依次找到下級頁表,所有的頁表都存放在記憶體中,訪問記憶體是需要額外的時間消耗的,相對于CPU對暫存器的訪問,Cache的訪問速度而言,記憶體的訪問速度是災難性的,何況還是多次訪問,當然額外的記憶體訪問本身是分頁機制相對分段機制的缺陷,一級頁表映射也存在這樣的缺陷,只是多級頁表映射將這個缺點再次放大,
1.6 Translation Lookside Buffer
Translation Lookside Buffer簡稱TLB,按其真實作用應當翻譯為地址轉換快取,
方才抨擊了多級頁表映射基址,提出了它可能導致系統變慢的缺點,那么如何解決這一問題呢?如果使MMU做頁表轉換時不訪問記憶體,是不是就解決問題了?TLB就是干這個事的,
TLB之所以可以解決這個問題是因為TLB是Cache,它將CPU訪問記憶體替換為CPU訪問Cache,也就是說MMU做頁表轉換時不再訪問記憶體的頁表,而是訪問快取在TLB中的頁表,因而降低了時間的消耗,
TLB要實作這個替換,其需要實作的基本作業原理是:
- 從虛擬地址中提取頁號(VPN),檢查TLB是否有該VPN的轉換映射,
- 如果有,則表示TLB命中(TLB hit),意味著從TLB中找到VPN對應的物理頁框號(PFN),PFN與虛擬地址的偏移量組成成物理地址(PA),
- 如果沒有,表示TLB未命中(TLB miss),則需要處理TBL miss,
- TLB miss處理有兩種方法,一種是硬體處理,一種是軟體處理,硬體處理TLB miss會自動更新TLB,軟體處理則是由硬體拋出一個TLB miss例外,軟體進入例外處理程式,查找物理頁表中轉換映射,再由指令更新TLB,并從例外中回傳,
- 軟體處理TLB miss例外與其他例外不同,例外處理回傳后,應繼續執行陷入例外之后的那條指令,而TLB miss例外處理回傳后,從導致陷入例外的執行開始執行,這樣保證TLB一定命中,
誠然,TLB是好,但是也引入了一些麻煩事(既然是Cache,就有一致性問題):行程切換時TLB如何處理?TLB表項滿了如何處理?mmap映射的記憶體被munmap解除TLB怎么處理?……
針對這些話題本文不做深入探討,可以閱讀另一篇為其量身定做的博文《深入Linux內核(記憶體篇)—TLB》,
1.7 頁表多大合適?
大頁表的好處:
- 省記憶體:可以解決分頁機制占用記憶體的問題,取得和多級頁表一樣節省記憶體的效果;
- 對TLB友好:大頁表意味著地址轉換時需要更少的頁表映射表項,頁表映射表項少了意味著TLB快取的表項少,這樣就提高了TLB的命中率;
大頁表的壞處:
- 記憶體內碎片:作業系統申請記憶體時總是申請一大塊記憶體,哪怕實際只需要很小的記憶體,導致大頁記憶體得不到充分利用;而且記憶體很快會被這些大頁侵占,
顯然小頁表的好處和壞處正好與大頁表對立,
因此頁表不是越大越好,也不是越小越好,找到折中的大小是才最適合,通常作業系統的使用的頁大小是4KB,
各種體系架構的CPU都支持很多種頁大小,因此實際頁表的應用可能會更“聰明”,用戶行程在請求地址空間時,可以因需求選擇合適的頁大小,這樣既可以滿足資料的存放,同時占用更少的TLB表項,一個典型的例子,DPDK使用了1GB的大頁記憶體,這樣DPDK行程的頁表映射只占用一個TLB表項,在行程執行程序中杜絕了TLB miss情況的發生,保障了性能,
二、X86中的分頁
X86中定義分頁即將每個線性地址轉換為物理地址,并確定對于每個轉換,允許對線性地址的何種訪問(地址的訪問權限)以及用于此類訪問的快取型別(地址的記憶體型別),
X86支持如下四種分頁模式:
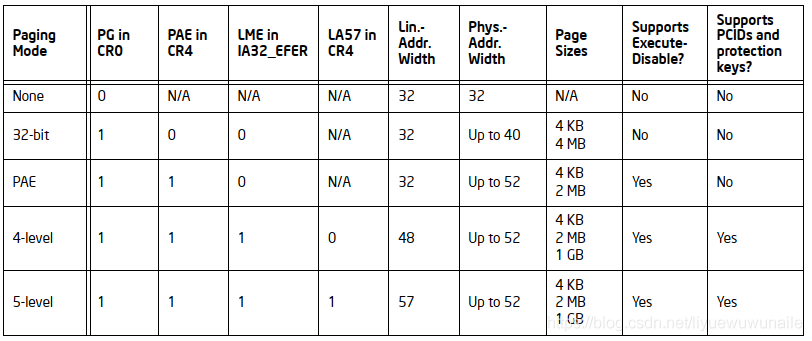
分頁模式的選擇主要由control register CR0,control register CR4,IA32_EFER MSR控制,
由上表可以看出:
- CR0.PG = 0,關閉分頁單元,線性地址被直接解釋成物理地址;
- CR0.PG = 1 && CR4.PAE = 0,使用32-bit分頁機制,線性地址大小是232,物理地址大小可以達到240,支持的頁大小是4KB和4MB;
- CR0.PG = 1 && CR4.PAE = 1,使用PAE(Physical Address Extension)分頁機制,線性地址大小是232,物理地址大小可以達到252,支持的頁大小是4KB和2MB;
- CR0.PG = 1 && CR4.PAE = 1 && IA32_EFER.LME = 1,使用4級分頁機制,線性地址大小是248,物理地址大小可以達到252,支持的頁大小是4KB、2MB和1GB;
- CR0.PG = 1 && CR4.PAE = 1 && IA32_EFER.LME = 1 && CR4.LA57 = 1,使用5級分頁機制,線性地址大小是257,物理地址大小可以達到252,支持的頁大小是4KB、2MB和1GB;
2.1 32-bit Paging
暫存器狀態CR0.PG = 1 && CR4.PAE = 0 && IA32_EFER.LME = 0 時,X86選擇32-BIT PAGING分頁模式,
32-BIT PAGING分頁模式支持頁大小是4KB和4MB兩種,
以4KB大小頁為例,其分頁機制如下圖所示,
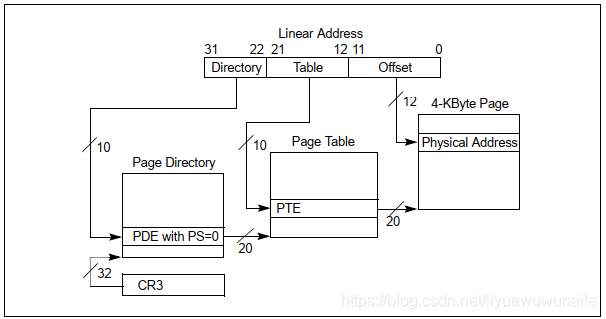
32bit線性地址被劃分為3部分:
- Directory[31:22]:最高10bit;
- Table[21:12]:中間10bit;
- Offset[11:0]:最低12bit,
其原理與第一節所述原理如出一轍,頁表基址暫存器為CR3,用于索引一級頁表Page Directory(PDE),Page Directory用于索引二級頁表Page Table(PTE),Page Table和Offset共同找到Physical Address,
2.2 32-bit Paging頁表長啥樣?
如下圖所示是32-BIT PAGING分頁模式下,CR3暫存器和一級頁表PDE,二級頁表PTE的長相,
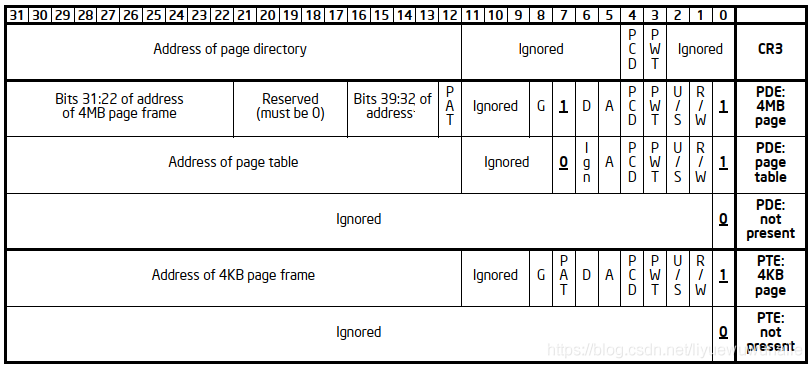
CR3暫存器
- Address of page directory[31:12]:線性地址轉換一級頁表物理地址,用于配合線性地址Page Directory找到一級頁表物理地址;
- PCD[4]:Page-level cache disable
- PWT[4]:Page-level write-through
PDE
- Page size[7]:指定頁大小,為1則頁大小為4MB,為0則頁大小為4KB,頁大小不同則PDE的結構也不同,我們只看PS=0的情況,即4KB頁大小;
- Present[0]:存在位,為1表示此頁在記憶體中,為0表示此頁不在記憶體中,地址轉換時,發現此位為0,則MMU將該地址放入CR2暫存器,并產生缺頁例外,
- Read/write[1]:讀寫權限,為0表示該頁表只讀;
- User/supervisor[2]:特權等級,為0則用戶模式無法訪問該頁表;
- Page-level write-through[3]:控制Cache處理頁表方式,指定Cache直寫和回寫策略;
- Page-level cache disable[4]:控制Cache處理頁表方式,指定Cache是否禁用;
- Accessed[5]:訪問頁框時置位;
- Address of page table[31:12]:線性地址轉換二級頁表物理地址,用于配合線性地址Page Table找到二級頁表物理地址;
PTE
- [5:0]:與PDE一樣;
- Dirty[6]:對頁框進行寫操作時置位;
- Global[8]:CR4.PGE = 1時有效,防止常用頁從TLB中Flush掉,
- Address of page table[31:12]:線性地址轉換物理地址,用于配合線性地址Offset找到物理地址;
其長相與第一節所述如出一轍,
2.3 4-Level Paging
再來看一個4級頁表分頁模式,支持的頁大小是4KB、2MB和1GB,
以4KB頁大小為例,如下圖所示,顯然相比于32-bit Paging,4-Level Paging擴展了線性地址(48bit)和物理地址(52bit),
隨著計算機的發展,32bit的地址空間顯很局促,尤其是物理尋址范圍也只有32bit,即4GB物理地址空間,在計算機發展初期4GB空間是天文數字,現在已經淪落到選擇個人PC都看不上4GB記憶體,起碼是8GB記憶體起步,這也是為什么X86 32位CPU支持PAE(Physical Address Extension)的原因,同樣的,ARM-v7也支持了LPAE(Large Physical Address Extension),名字雖不同,但困境如出一轍,
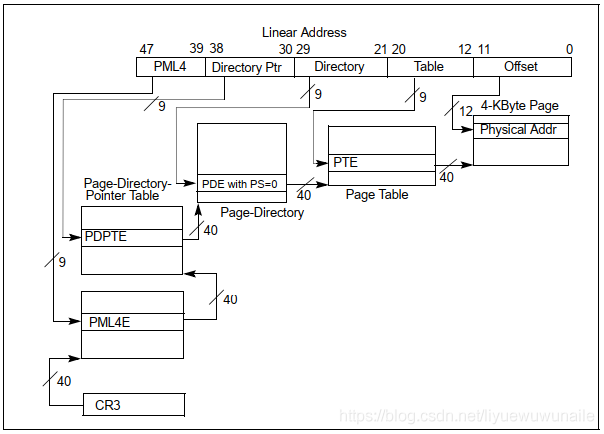
4級頁表映射其原理與32bit Paging是一樣的,將47bit線性地址被劃分為5部分:
- PML4[47:39]:最高9bit;
- Directory Ptr[38:30]:中間9bit;
- Directory [29:21]:中間9bit;
- Table[20:12]:中間9bit;
- Offset[11:0]:最低12bit,
地址轉換程序也是一樣,從CR3開始逐級找到Physical Address,這里不再贅述了,
其原理真是如出一轍,
三、ARM中的分頁
看完了X86中的分頁,再看ARM中分頁,
3.1 ARMv7 Paging
ARMv7架構支持三種頁大小:1MB,64KB和4KB,同時ARMv7支持LPAE,可以將物理地址范圍擴大到40bit,
以4KB頁大小,未開啟LPAE為例,如下圖所示,
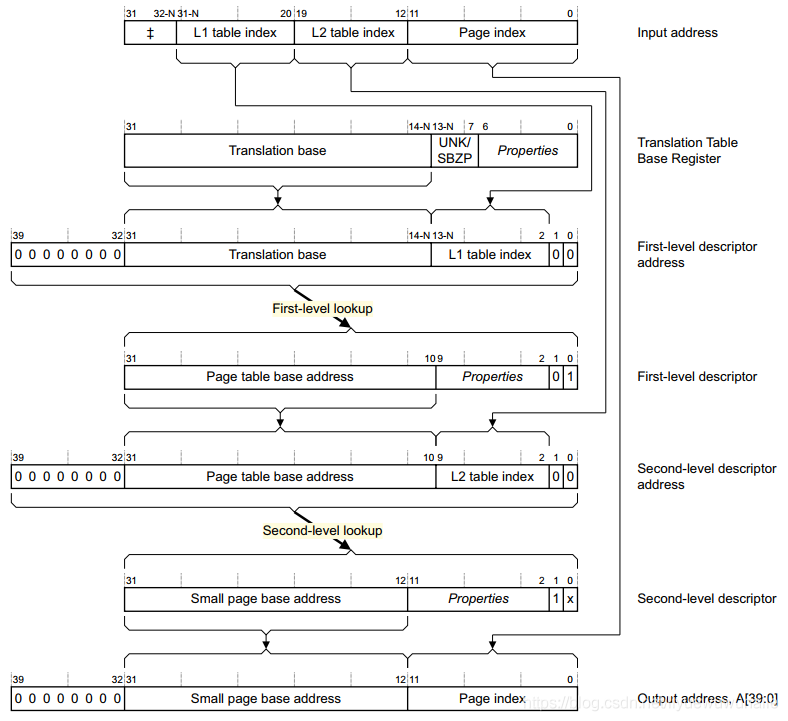
32bit線性地址被劃分為3部分:
- L1 Table Index[31:20]:最高12bit;
- L2 Table Index[19:12]:中間8bit;
- Page Index[11:0]:最低12bit,
地址轉換程序,TTBR暫存器Translation base[31:14]和虛擬地址的L1 Table Index[31:20]索引到一級頁表物理地址,一級頁表Page table base address[31:10]和虛擬地址L2 Table Index[19:12]索引到二級頁表物理地址,二級頁表Small page base address[31:12]和虛擬地址的Page Index[11:0]索引到物理地址,
3.2 ARMv7 4KB Paging頁表長啥樣?
ARMv7 4KB分頁機制采用二級頁表管理,其一級頁表屬性如下圖所示,

- Page table base address[31:10]:線性地址轉換二級頁表物理地址,用于配合線性地址Page Table找到二級頁表物理地址;
- NS[3]:Non-secure,非安全模式下忽略;
- Domain[8:5]:域,記憶體區域的集合,可以定義16個域,劃分其訪問權限,超越域訪問權限時會觸發Permission fault,
二級頁表屬性如下圖所示,

- Small page base address[31:12]:線性地址轉換物理地址,用于配合線性地址offset找到物理地址;
- XN[0]:Execute-never;
- C,B[3:2]:定義內部cache屬性,
- TEX[8:6]:定義外部cache屬性,
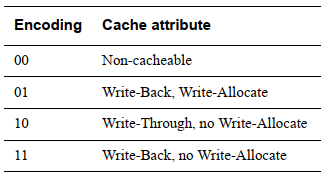
- AP[9,5:4]:Access Permissions,當高位設定為1,則頁表為只讀權限;

- S[10]:Shareable;
- nG[11]:not global,指定頁表是否是全域的,用于TLB;
3.3 ARMv8 分頁配置
ARMv8架構AArm64支持三種頁大小:64KB,16KB和4KB,
頁大小選擇由系統暫存器TCR控制,如下圖所示為TCR_EL1暫存器,

比較重要的bit位說明:
- T0SZ[5:0]:The size offset of the memory region addressed by TTBR0_EL1,TTBR0_EL1尋址的記憶體區域的大小偏移量,記憶體區域大小計算方法2(64-T0SZ);
- T1SZ[21:16]:The size offset of the memory region addressed by TTBR1_EL1,TTBR1_EL1尋址的記憶體區域的大小偏移量,記憶體區域大小計算方法2(64-T0SZ);
- IRGN0[9:8]/IRGN1[25:24]:Inner cacheability attribute for memory associated,控制內部Cache訪問模式,直寫和回寫;
- ORGN0[11:10]/ORGN1[27:26]:Outer cacheability attribute for memory associated,控制外部Cache訪問模式,直寫和回寫;
- TG0[15:14]:Granule size for the TTBR0_EL1,頁大小,為0表示4KB,1表示64KB,2表示16KB;
- TG1[31:30]:Granule size for the TTBR1_EL1,頁大小,為0表示4KB,1表示64KB,3表示16KB;
- A1[22]:ASID選擇,為0選擇TTBR0_EL1.ASID ,為1選擇TTBR1_EL1.ASID;
- IPS[34:32]:Intermediate Physical Address Size,中間物理地址大小;
- AS[36]:ASID Size,ASID大小,為0表示8bit,為1表示16bit;
- HA[39]:Hardware Access flag update,Access使能位;
- HD[40]:Hardware management of dirty state,Dirty使能位;
說明:
- ARM架構提供了兩個頁表基址暫存器TTBR0和TTBR1,可以分別用于用戶態和內核態,
- ASID用于標識行程,可以根據ASID劃分TLB entry,避免TLB entry頻繁Flush,
顯然系統暫存器TCR控制了頁表映射的引數,其中TCR.TG0/TG1決定了頁大小,
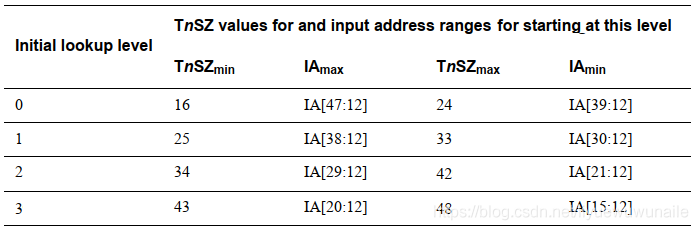
當頁大小為4KB時,分頁單元每級頁表的地址范圍如下,其中TnSZmin和TnSZmax分別表示TCR_ELx.TnSZ的最小最大值,IA表示Input Address,即虛擬地址:
3.4 ARMv8 Paging
以頁大小為4KB,虛擬地址位寬為48bit為例,符合上一節中TCR_ELx.TnSZ為最小值的情況,如下圖所示,
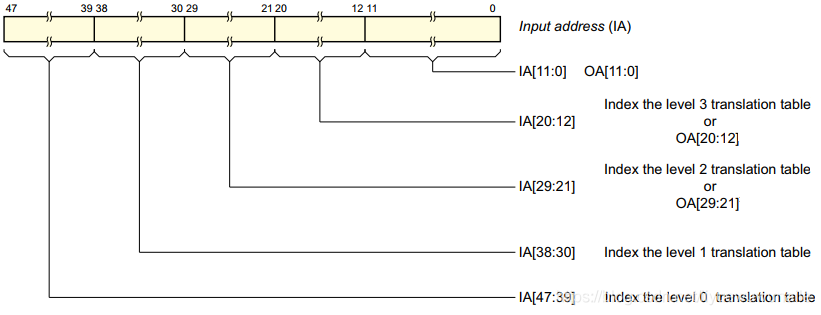
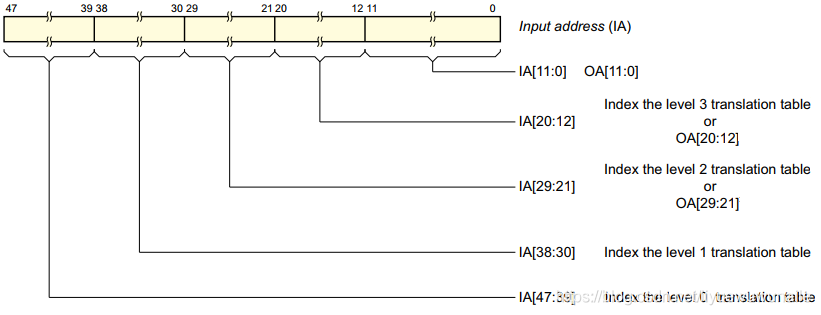
ARMv8對IA(input address)劃分成了五部分:
- Index the level 0 translation table[47:39]:最高9bit;
- Index the level 1 translation table[38:30]:中間9bit;
- Index the level 2 translation table [29:21]:中間9bit;
- Index the level 3 translation table[20:12]:中間9bit;
- OA[11:0]:output address,最低12bit,
這個劃分方法與X86 4-Level Paging一樣,
其地址轉換程序,與前述的地址轉換程序并無差別,從頁表基址暫存器TTBR_ELx開始逐級查找到物理地址,如下圖所示,

四、Kernel中的分頁
Linux Kernel分頁為了支持不同的CPU體系架構,設計了五級分頁模型,如下圖所示,五級分頁模型是為了兼容X86-64體系架構中的5-Level Paging分頁模式,見第二節,

五級分頁每級命名分別為頁全域目錄(PGD)、頁4級目錄(P4D)、頁上級目錄(PUD)、頁中間目錄(PMD)、頁表(PTE),對應的相關宏定義命名如下:
#define PGDIR_SHIFT
#define P4D_SHIFT
#define PUD_SHIFT
#define PMD_SHIFT
#define PAGE_SHIFT
這些宏定義與具體體系架構相關,如果體系架構只使用了4級,3級或者更少的分級映射,則將其中的某幾個定義忽略即可,
Linux對于頁表的操作主要定義了以下函式或宏,這些操作方法也是與體系架構相關的,因此需要按照體系架構的硬體定義去實作,
| 宏或函式 | 說明 |
|---|---|
| pgd_offset(mm, addr) | 根據入參記憶體描述符mm和虛擬地址address,找到address在頁全域目錄中相應表項的線性地址, |
| pgd_offset_k(addr) | 根據入參虛擬地址address和init_mm,找到address在頁全域目錄中相應表項的線性地址,僅用于內核頁表, |
| p4d_offset(pgd, addr) | 根據入參pgd和虛擬地址address,找到address在頁四級目錄中相應表項的線性地址, |
| pud_offset(p4d,addr) | 根據入參p4d和虛擬地址address,找到address在頁上級目錄中相應表項的線性地址, |
| pmd_offset(pud, address) | 根據入參pud和虛擬地址address,找到address在頁中間目錄中相應表項的線性地址, |
| pte_index(address) | 根據入參虛擬地址address,找到address在頁表中索引, |
| set_pgd(pgdp, pgd) | 向PGD寫入指定的值 |
| set_p4d(p4dp, p4d) | 向P4D寫入指定的值 |
| set_pud(pudp, pud) | 向PUD寫入指定的值 |
| set_pmd(pmdp, pmd) | 向PMD寫入指定的值 |
| set_pte(ptep, pte) | 向PTE寫入指定的值 |
| pte_dirty(pte) | 讀Dirty標志 |
| pte_mkdirty(pte) | 寫Dirty標志 |
分頁機制與CPU體系架構強相關,因此分析Linux Kernel分頁時還是需要根據體系架構分析,
4.1 X86分頁
X86架構中支持四種分頁模式:32-bit,PAE,4-Level Paging和5-Level Paging,對于ARM體系架構最多用到了4級分頁,而X86架構可以用到5級分頁,Linux對于X86分頁定義如下,
#ifdef CONFIG_X86_5LEVEL
/*
* PGDIR_SHIFT determines what a top-level page table entry can map
*/
#define PGDIR_SHIFT pgdir_shift
#define PTRS_PER_PGD 512
/*
* 4th level page in 5-level paging case
*/
#define P4D_SHIFT 39
#define MAX_PTRS_PER_P4D 512
#define PTRS_PER_P4D ptrs_per_p4d
#define P4D_SIZE (_AC(1, UL) << P4D_SHIFT)
#define P4D_MASK (~(P4D_SIZE - 1))
#define MAX_POSSIBLE_PHYSMEM_BITS 52
#else /* CONFIG_X86_5LEVEL */
/*
* PGDIR_SHIFT determines what a top-level page table entry can map
*/
#define PGDIR_SHIFT 39
#define PTRS_PER_PGD 512
#define MAX_PTRS_PER_P4D 1
#endif /* CONFIG_X86_5LEVEL */
/*
* 3rd level page
*/
#define PUD_SHIFT 30
#define PTRS_PER_PUD 512
/*
* PMD_SHIFT determines the size of the area a middle-level
* page table can map
*/
#define PMD_SHIFT 21
#define PTRS_PER_PMD 512
/*
* entries per page directory level
*/
#define PTRS_PER_PTE 512
#define PMD_SIZE (_AC(1, UL) << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE - 1))
#define PUD_SIZE (_AC(1, UL) << PUD_SHIFT)
#define PUD_MASK (~(PUD_SIZE - 1))
#define PGDIR_SIZE (_AC(1, UL) << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE - 1))
我們以4級分頁為例,其對虛擬地址的劃分如下圖所示,在2.3節中已經說明,從Linux宏定義可以看出PGDIR_SHIFT對應PML4,值為39;PUD_SHIFT對應Directory Ptr,值為30;PMD_SHIFT對應Directory,值為21;使用4KB也大小時,PAGE_SIZE為4KB,即PAGE_SHIFT大小為12,對應Table,
PTRS_PER_PGD,PTRS_PER_PUD,PTRS_PER_PMD分別對應每級表項的個數,都是512個表項(2^9),
4.1 ARMv7分頁
ARMv7作為32bit CPU架構,其分頁一般采用兩級分頁,第一級為頁目錄(PGD),第二級為頁映射表(PTE),頁大小為4KB,
如下圖所示為ARMv7頁表映射示意圖,與ARMv7硬體4KB分頁機制相對應,頁表基址暫存器TTBRx(x為0或1),
TTBRx(Translation Table Base Register x)即頁表轉換基址暫存器,ARMv7提供了TTBR0和TTBR1兩個暫存器,Linux分別將其應用于內核態和用戶態,行程地址空間切換實質就是將TTBR0暫存器中Translation Table Base 0 Address修改為當前行程的PGD(頁全域目錄),一級頁表數量為4096,二級頁表數量為256,
頁表映射程序是MMU通過TTBRx和虛擬地址VA[31:20]索引到PGD一級頁表,再由PGD一級頁表和虛擬地址VA[19:12]索引到PTE頁映射表,在由PTE頁映射表和虛擬地址VA[11:0]索引到物理地址,

Linux對于上述PGD,PTE等資料的定義位于ARM體系架構目錄,如下所示:
/*
* PMD_SHIFT determines the size of the area a second-level page table can map
* PGDIR_SHIFT determines what a third-level page table entry can map
*/
#define PMD_SHIFT 21
#define PGDIR_SHIFT 21
#define PMD_SIZE (1UL << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE-1))
#define PGDIR_SIZE (1UL << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE-1))
這里會有一個疑惑,PMD和PGD沒有定義成20,和之前分析的不一致?
之前分析了ARMv7硬體分頁機制,4KB頁表大小進行分頁時,采用二級頁表結構,第一級有4096個表項,第二級有256個表項,二級頁表中的屬性沒有“dirty”位,
而Linux有一個三層的頁表結構,可以很容易地將其包裝成適合兩層的頁表結構—只使用PGD和PTE,但是,Linux還要求每個頁面有一個“PTE”表,而且至少要有一個“dirty”位,對于“dirty”位我們前面也講到了,“dirty”位在寫操作時被置位,表示頁面被寫過,頁面交換時會使用該標記,
因此,在這里稍微調整了實作—告訴Linux在第一級有2048個條目,每個都是8位元組,二級頁表包含兩個連續排列的硬體PTE表項,前面的表項是包含Linux需要的狀態資訊的Linux PTE,因此,最終在“PTE”級別上有512個表項,宏定義如下所示,
#define PTRS_PER_PTE 512
#define PTRS_PER_PMD 1
#define PTRS_PER_PGD 2048
#define PTE_HWTABLE_PTRS (PTRS_PER_PTE)
#define PTE_HWTABLE_OFF (PTE_HWTABLE_PTRS * sizeof(pte_t))
#define PTE_HWTABLE_SIZE (PTRS_PER_PTE * sizeof(u32))
當頁面在Linux PTE中被標記為“可寫”和“dirty”時,“dirty”位通過授予硬體寫權限模擬,也就是說ARM頁表設定時將權限設定為只讀,當向頁面寫入時,會觸發缺頁例外(Linux PTE頁面表項標記了可寫權限,但是ARM硬體頁面表項是只讀權限),在缺頁例外處理函式handle_pte_fault()中會在該頁的Linux PTE頁面表項標記為“dirty”,為了讓硬體注意到權限的更改,必須重繪TLB條目,而ptep_set_access_flags()為我們完成了這項作業,
ARMv7頁表屬性的定義分為Linux版本的頁表和ARMv7硬體的頁表,
Linux版本的PTE頁表屬性定義加入前綴L_,如下所示:
/*
* "Linux" PTE definitions.
*
* We keep two sets of PTEs - the hardware and the linux version.
* This allows greater flexibility in the way we map the Linux bits
* onto the hardware tables, and allows us to have YOUNG and DIRTY
* bits.
*
* The PTE table pointer refers to the hardware entries; the "Linux"
* entries are stored 1024 bytes below.
*/
#define L_PTE_VALID (_AT(pteval_t, 1) << 0) /* Valid */
#define L_PTE_PRESENT (_AT(pteval_t, 1) << 0)
#define L_PTE_YOUNG (_AT(pteval_t, 1) << 1)
#define L_PTE_DIRTY (_AT(pteval_t, 1) << 6)
#define L_PTE_RDONLY (_AT(pteval_t, 1) << 7)
#define L_PTE_USER (_AT(pteval_t, 1) << 8)
#define L_PTE_XN (_AT(pteval_t, 1) << 9)
#define L_PTE_SHARED (_AT(pteval_t, 1) << 10) /* shared(v6), coherent(xsc3) */
#define L_PTE_NONE (_AT(pteval_t, 1) << 11)
ARMv7硬體的頁表屬性定義如下所示:
/*
* - extended small page/tiny page
*/
#define PTE_EXT_XN (_AT(pteval_t, 1) << 0) /* v6 */
#define PTE_EXT_AP_MASK (_AT(pteval_t, 3) << 4)
#define PTE_EXT_AP0 (_AT(pteval_t, 1) << 4)
#define PTE_EXT_AP1 (_AT(pteval_t, 2) << 4)
#define PTE_EXT_AP_UNO_SRO (_AT(pteval_t, 0) << 4)
#define PTE_EXT_AP_UNO_SRW (PTE_EXT_AP0)
#define PTE_EXT_AP_URO_SRW (PTE_EXT_AP1)
#define PTE_EXT_AP_URW_SRW (PTE_EXT_AP1|PTE_EXT_AP0)
#define PTE_EXT_TEX(x) (_AT(pteval_t, (x)) << 6) /* v5 */
#define PTE_EXT_APX (_AT(pteval_t, 1) << 9) /* v6 */
#define PTE_EXT_COHERENT (_AT(pteval_t, 1) << 9) /* XScale3 */
#define PTE_EXT_SHARED (_AT(pteval_t, 1) << 10) /* v6 */
#define PTE_EXT_NG (_AT(pteval_t, 1) << 11) /* v6 */
ARMv7硬體的頁表屬性定義與3.2節中描述的硬體頁表的屬性是相互對應的,其含義與硬體頁表屬性含義一致,
通過對比Linux版本的頁表和ARMv7硬體的頁表會發現,ARMv7硬體的頁表缺少“dirty”位和“young”位,“dirty”位前邊已經講過,“young”位用于標志頁面剛剛被訪問過,在頁面換出時,如果頁面“young”位被標記,則不會將該頁換出,同時清除“young”位標記,“young”位的模擬方法與“dirty”位類似,也是利用了兩套PTE頁表模擬,一套用于Linux,一套用于ARM硬體,
ARMv7頁表如何下發到硬體?是通過set_pte_ext()函式實作的,
#define set_pte_ext(ptep,pte,ext) cpu_set_pte_ext(ptep,pte,ext)
#define cpu_set_pte_ext PROC_TABLE(set_pte_ext)
不同CPU有不同的實作方式,以Cortex-A9為例,其實作是匯編函式cpu_v7_set_pte_ext:
/*
* cpu_v7_set_pte_ext(ptep, pte)
*
* Set a level 2 translation table entry.
*
* - ptep - pointer to level 2 translation table entry
* (hardware version is stored at +2048 bytes)
* - pte - PTE value to store
* - ext - value for extended PTE bits
*/
ENTRY(cpu_v7_set_pte_ext)
#ifdef CONFIG_MMU
str r1, [r0] @ linux version @Linux PTE設定到r0指向的記憶體
bic r3, r1, #0x000003f0
bic r3, r3, #PTE_TYPE_MASK
orr r3, r3, r2
orr r3, r3, #PTE_EXT_AP0 | 2
tst r1, #1 << 4
orrne r3, r3, #PTE_EXT_TEX(1)
eor r1, r1, #L_PTE_DIRTY
tst r1, #L_PTE_RDONLY | L_PTE_DIRTY
orrne r3, r3, #PTE_EXT_APX @模擬“dirty”位,如果L_PTE_DIRTY置位,
@則設定ARM硬體頁表APX位置位,設定頁表為只讀權限
tst r1, #L_PTE_USER
orrne r3, r3, #PTE_EXT_AP1
tst r1, #L_PTE_XN
orrne r3, r3, #PTE_EXT_XN
tst r1, #L_PTE_YOUNG
tstne r1, #L_PTE_VALID
eorne r1, r1, #L_PTE_NONE
tstne r1, #L_PTE_NONE
moveq r3, #0 @模擬“young”位,如果L_PTE_YONG清除且L_PTE_PRESENT置位,
@則保持Linux版本頁表不變,ARM硬體頁表清除(r3置0即清空頁表)
ARM( str r3, [r0, #2048]! ) @ARM PTE設定到r0+2048指向的記憶體
THUMB( add r0, r0, #2048 )
THUMB( str r3, [r0] )
ALT_SMP(W(nop))
ALT_UP (mcr p15, 0, r0, c7, c10, 1) @ flush_pte
#endif
bx lr
ENDPROC(cpu_v7_set_pte_ext)
暫存器r0是PTE表項指標,Linux使用的表項即r0所指記憶體,ARM硬體使用的表項地址是r0+2048,暫存器r1表示要寫入記憶體的Linux PTE表項的內容,其屬性bit位設定均使用L_前綴的宏定義,
第一句陳述句將Linux PTE設定到r0指向的記憶體,
str r1, [r0]
str為記憶體操作指令,表示將資料從暫存器寫的記憶體,
如下陳述句將ARM PTE設定到r0+2048指向的記憶體,
ARM( str r3, [r0, #2048]! )
[r0, #2048]為前索引尋址模式,地址為暫存器R0中的值+立即數2048,偏移量為2048,計算出的新地址回寫到R0中,
關于記憶體操作指令詳細內容請看《ARM體系架構—ARMv7-A指令集:記憶體操作指令》
如下陳述句為ARMv7協處理器指令,指令含義為Data Cache Clean by MVA to PoC,即清除cache,
ALT_UP (mcr p15, 0, r0, c7, c10, 1)
CP15協處理器保護c0-c15共16個暫存器,暫存器32位的組織形式如下: C R n , o p c 1 , C R m , o p c 2 {CRn, opc1, CRm, opc2} CRn,opc1,CRm,opc2 對于匯編陳述句“mcr p15, 0, r0, c7, c10, 1”指示四個運算元結果如下:
- CRn:第一個協處理器暫存器c7;
- opc1:協處理器操作碼0;
- CRm:第二個協處理器暫存器c10;
- opc2:協處理器操作碼1,

關于協處理指令詳細內容請看《ARM體系架構—ARMv7-A協處理器》
4.2 ARMv8分頁
ARMv8頁表支持三種粒度:4KB,16KB和64KB,
ARMv8支持48bit虛擬地址空間, 實作ARMv8.2-LVA( Large Virtual Address)并使用64KB頁大小時虛擬地址尋址空間可達52bit,當使用64KB頁大小時,ARMv8使用三級頁表;當使用4KB和16KB頁大小時,ARMv8使用四級頁表,正如下圖所示,
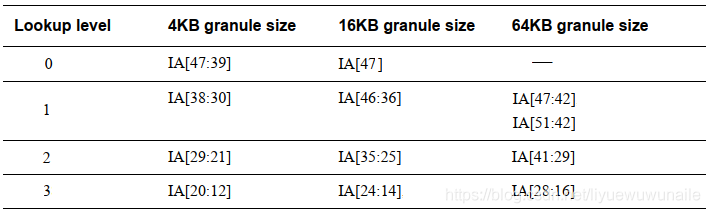
ARMv8采用4KB頁大小,使用4級頁表時,記憶體分布如下,內核空間和用戶空間大小分別為256TB,內核空間地址范圍從0xffff000000000000到0xffffffffffffffff,共256TB空間,用戶空間地址范圍從0x0000000000000000到0x0000ffffffffffff,共256TB空間,
AArch64 Linux memory layout with 4KB pages + 4 levels (48-bit)::
Start End Size Use
-----------------------------------------------------------------------
0000000000000000 0000ffffffffffff 256TB user
ffff000000000000 ffff7fffffffffff 128TB kernel logical memory map
ffff800000000000 ffff9fffffffffff 32TB kasan shadow region
ffffa00000000000 ffffa00007ffffff 128MB bpf jit region
ffffa00008000000 ffffa0000fffffff 128MB modules
ffffa00010000000 fffffdffbffeffff ~93TB vmalloc
fffffdffbfff0000 fffffdfffe5f8fff ~998MB [guard region]
fffffdfffe5f9000 fffffdfffe9fffff 4124KB fixed mappings
fffffdfffea00000 fffffdfffebfffff 2MB [guard region]
fffffdfffec00000 fffffdffffbfffff 16MB PCI I/O space
fffffdffffc00000 fffffdffffdfffff 2MB [guard region]
fffffdffffe00000 ffffffffffdfffff 2TB vmemmap
ffffffffffe00000 ffffffffffffffff 2MB [guard region]
ARM提供了兩個頁表基址暫存器TTBR0和TTBR1,在Linux中分別用于用戶空間和內核空間,內核空間地址高16位全為1,用戶空間地址高16位全為0,,如下圖所示,TTBR1和TTBR0分別管理0xffff000000000000到0xffffffffffffffff和0x0000000000000000到0x0000ffffffffffff兩部分地址空間,其余地址空間訪問則會發生例外,MMU做地址轉換時選擇TTBR1和TTBR0是根據虛擬地址VA[63],如果63bit為1則選擇TTBR1,為0則選擇TTBR0,

ARMv8采用4KB頁大小,4級頁表映射,其虛擬地址劃分為,在3.4節中已經做過說明,
Linux上述 Index the level 0 & 1 & 2 & 3 translation table等資料的定義位于ARM體系架構目錄,如下所示,
#define VA_BITS (CONFIG_ARM64_VA_BITS)
#define ARM64_HW_PGTABLE_LEVEL_SHIFT(n) ((PAGE_SHIFT - 3) * (4 - (n)) + 3)
#define PTRS_PER_PTE (1 << (PAGE_SHIFT - 3))
/*
* PMD_SHIFT determines the size a level 2 page table entry can map.
*/
#if CONFIG_PGTABLE_LEVELS > 2
#define PMD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(2)
#define PMD_SIZE (_AC(1, UL) << PMD_SHIFT)
#define PMD_MASK (~(PMD_SIZE-1))
#define PTRS_PER_PMD PTRS_PER_PTE
#endif
/*
* PUD_SHIFT determines the size a level 1 page table entry can map.
*/
#if CONFIG_PGTABLE_LEVELS > 3
#define PUD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(1)
#define PUD_SIZE (_AC(1, UL) << PUD_SHIFT)
#define PUD_MASK (~(PUD_SIZE-1))
#define PTRS_PER_PUD PTRS_PER_PTE
#endif
/*
* PGDIR_SHIFT determines the size a top-level page table entry can map
* (depending on the configuration, this level can be 0, 1 or 2).
*/
#define PGDIR_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(4 - CONFIG_PGTABLE_LEVELS)
#define PGDIR_SIZE (_AC(1, UL) << PGDIR_SHIFT)
#define PGDIR_MASK (~(PGDIR_SIZE-1))
#define PTRS_PER_PGD (1 << (VA_BITS - PGDIR_SHIFT))
PGDIR_SHIFT宏對應了 Index the level 0 translation table,當4KB頁大小,4級頁表映射時(PAGE_SHIFT = 12;CONFIG_PGTABLE_LEVELS = 4),通過計算可得PGDIR_SHIFT宏為39,與硬體分頁定義一致,
PGDIR_SHIFT = (12-3)*(4-0)+3 = 39
CONFIG_PGTABLE_LEVELS表示使用頁表級數,當前使用的是4級頁表,所以CONFIG_PGTABLE_LEVELS>3,因此PUD定義為:
#define ARM64_HW_PGTABLE_LEVEL_SHIFT(n) ((PAGE_SHIFT - 3) * (4 - (n)) + 3)
#define PUD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(1)
PUD_SHIFT宏對應了 Index the level 1 translation table,帶入計算可知PUD_SHIFT為30,與硬體分頁定義一致,
PUD_SHIFT = (12-3)*(4-1)+3 = 30
CONFIG_PGTABLE_LEVELS表示使用頁表級數,當前使用的是4級頁表,所以CONFIG_PGTABLE_LEVELS>2,因此PMD定義為:
#define ARM64_HW_PGTABLE_LEVEL_SHIFT(n) ((PAGE_SHIFT - 3) * (4 - (n)) + 3)
#define PMD_SHIFT ARM64_HW_PGTABLE_LEVEL_SHIFT(2)
PMD_SHIFT宏對應了 Index the level 3 translation table,帶入計算可知PUD_SHIFT為21,與硬體分頁定義一致,
PMD_SHIFT = (12-3)*(4-2)+3 = 21
至此,PGD,PUD,PMD都已獲悉,對應的其他宏的值也可以順利計算出結果,
#define PGDIR_SIZE 512GB
#define PTRS_PER_PGD 512
#define PUD_SIZE 1GB
#define PTRS_PER_PUD 512
#define PMD_SIZE 2MB
#define PTRS_PER_PMD 512
ARMv8 Linux下發PGD,PUD,PMD,PTE并沒有使用匯編語言,而是使用C語言實作,對應的函式如下,其實作原理都是將對應的表項內容寫入表項所在地址,
/* 向記憶體下發PGD頁表,入參分別為pgd頁表虛擬地址和pgd表項*/
static inline void set_pgd(pgd_t *pgdp, pgd_t pgd)
{
if (in_swapper_pgdir(pgdp)) {
set_swapper_pgd(pgdp, pgd); /* 將pgd寫入swapper_pg_dir所指地址 */
return;
}
WRITE_ONCE(*pgdp, pgd); /* 將pgd寫入pgdp所指地址 */
dsb(ishst); /* 資料記憶體屏障 */
isb(); /* 指令記憶體屏障 */
}
static inline void set_pud(pud_t *pudp, pud_t pud)
{
#ifdef __PAGETABLE_PUD_FOLDED
if (in_swapper_pgdir(pudp)) {
set_swapper_pgd((pgd_t *)pudp, __pgd(pud_val(pud)));
return;
}
#endif /* __PAGETABLE_PUD_FOLDED */
WRITE_ONCE(*pudp, pud); /* 將pud寫入pudp所指地址 */
if (pud_valid(pud)) {
dsb(ishst);
isb();
}
}
static inline void set_pmd(pmd_t *pmdp, pmd_t pmd)
{
#ifdef __PAGETABLE_PMD_FOLDED
if (in_swapper_pgdir(pmdp)) {
set_swapper_pgd((pgd_t *)pmdp, __pgd(pmd_val(pmd)));
return;
}
#endif /* __PAGETABLE_PMD_FOLDED */
WRITE_ONCE(*pmdp, pmd); /* 將pmd寫入pmdp所指地址 */
if (pmd_valid(pmd)) {
dsb(ishst);
isb();
}
}
static inline void set_pte(pte_t *ptep, pte_t pte)
{
WRITE_ONCE(*ptep, pte); /* 將pte寫入ptep所指地址 */
/*
* Only if the new pte is valid and kernel, otherwise TLB maintenance
* or update_mmu_cache() have the necessary barriers.
*/
if (pte_valid_not_user(pte)) {
dsb(ishst);
isb();
}
}
本文內核版本為Linux5.6.4,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/171744.html
標籤:其他
上一篇:linux arm32 mmu 啟動代碼分析(匯編部分)
下一篇:SQL 常用資料型別匯總