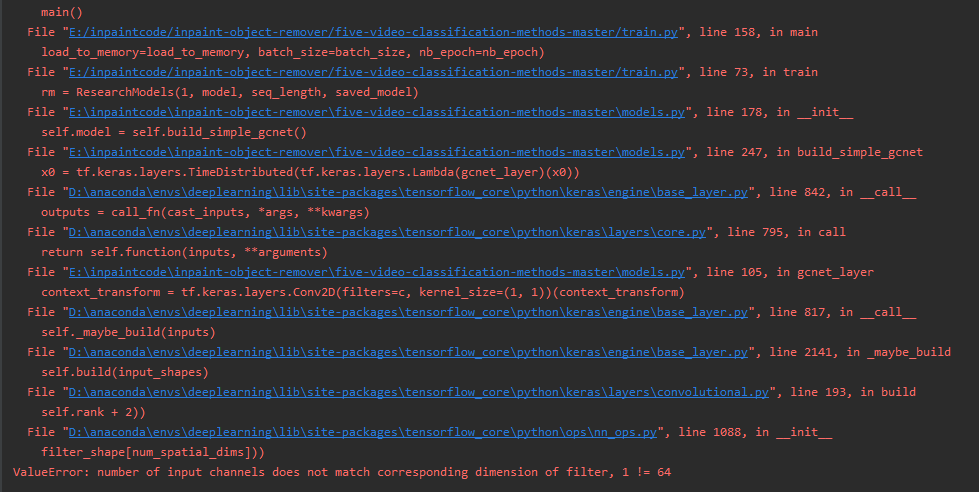
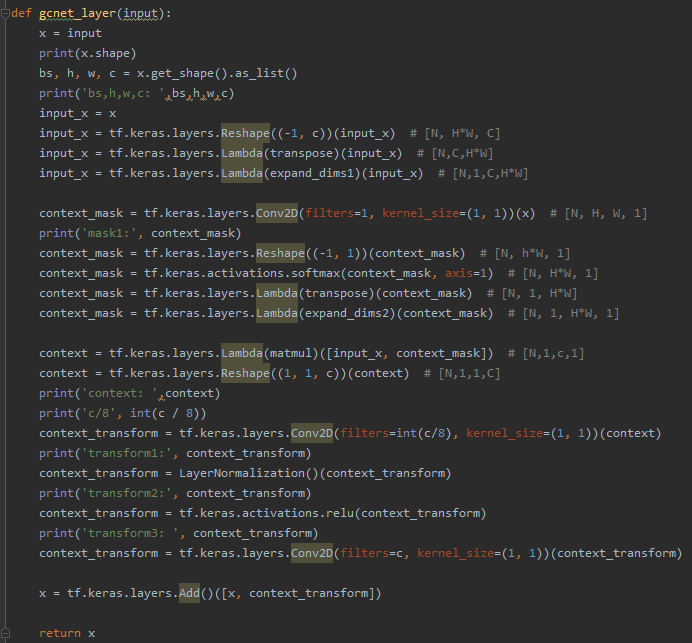
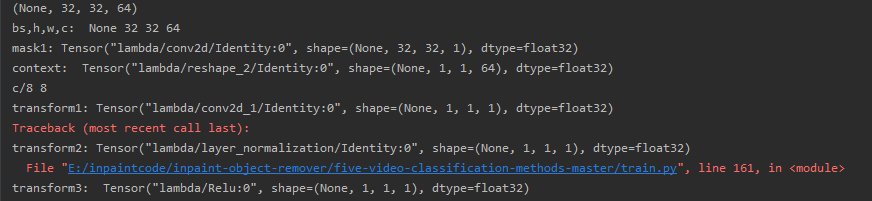
我在做deepfake視頻檢測,每組輸入是6個圖片,設定的batchsize是32,輸入shape是(32,6,128,128,3),我用的是Timedistrubuted層處理的輸入里的每張圖片,然后我打算在給每個影像卷積后加一個注意力層,用的是gcnet layer。加入之后就出現了圖片上的問題:ValueError: number of input channels does not match corresponding dimension of filter, 1 != 64。然后我把gcnet layer里相關的層輸出出來發現是context_transform = tf.keras.layers.Conv2D(filters=int(c/8), kernel_size=(1, 1))(context)這一次卷積得到的特征圖個數不對。c是64,理論上應該得到8個特征圖。但是只得到了1個特征圖。這要怎么解決呀?
問題圖片:
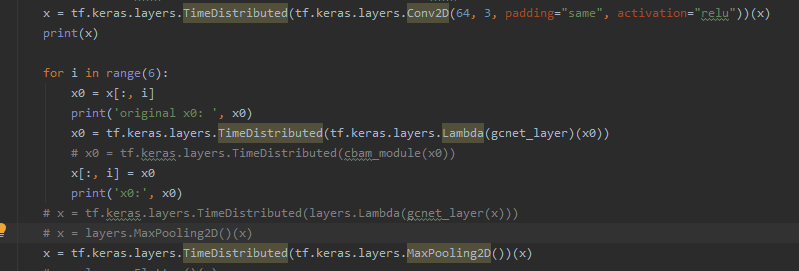
我是這樣對每個圖片加入注意力層的,不知道還有什么其他方法:
gcnet layer:
gcnet layer里print函式的輸出:
我之前在影像分類里用過gcnet layer,可以正常使用。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/172500.html
上一篇:急!!pandas DataFrame 的reindex 不能重新索引的問題
下一篇:windows+python+opencv環境下,cv2.VideoCapture()發現不了usb接入的攝像頭。