作者|Rashida Nasrin Sucky
編譯|VK
來源|Towards Datas Science
例外檢測可以作為例外值分析的一項統計任務來處理,但是如果我們開發一個機器學習模型,它可以像往常一樣自動化,可以節省很多時間,
例外檢測有很多用例,信用卡欺詐檢測、故障機器檢測或基于例外特征的硬體系統檢測、基于醫療記錄的疾病檢測都是很好的例子,還有更多的用例,例外檢測的應用只會越來越多,
在本文中,我將解釋在Python中從頭開始開發例外檢測演算法的程序,
公式和程序
與我之前解釋過的其他機器學習演算法相比,這要簡單得多,該演算法將使用均值和方差來計算每個訓練資料的概率,
如果一個訓練實體的概率很高,這是正常的,如果某個訓練實體的概率很低,那就是一個例外的例子,對于不同的訓練集,高概率和低概率的定義是不同的,我們以后再討論,
如果我要解釋例外檢測的作業程序,這很簡單,
- 使用以下公式計算平均值:
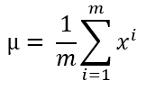
這里m是資料集的長度或訓練資料的數量,而\(x^i\)是一個單獨的訓練例子,如果你有多個訓練特征,大多數情況下都需要計算每個特征能的平均值,
- 使用以下公式計算方差:
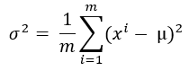
這里,mu是上一步計算的平均值,
- 現在,用這個概率公式計算每個訓練例子的概率,
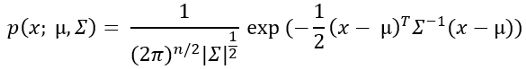
不要被這個公式中的求和符號弄糊涂了!這實際上是Sigma代表方差,
稍后我們將實作該演算法時,你將看到它的樣子,
- 我們現在需要找到概率的臨界值,正如我前面提到的,如果一個訓練例子的概率很低,那就是一個例外的例子,
低概率有多大?
這沒有普遍的限制,我們需要為我們的訓練資料集找出這個,
我們從步驟3中得到的輸出中獲取一系列概率值,對于每個概率,通過閾值的設定得到資料是否例外
然后計算一系列概率的精確度、召回率和f1分數,
精度可使用以下公式計算
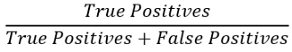
召回率的計算公式如下:
在這里,True positives(真正例)是指演算法檢測到一個例外的例子的數量,而它真實情況也是一個例外,
False Positives(假正例)當演算法檢測到一個例外的例子,但在實際情況中,它不是例外的,就會出現誤報,
False Negative(假反例)是指演算法檢測到的一個例子不是例外的,但實際上它是一個例外的例子,
從上面的公式你可以看出,更高的精確度和更高的召回率總是好的,因為這意味著我們有更多的真正的正例,但同時,假正例和假反例起著至關重要的作用,正如你在公式中看到的那樣,這需要一個平衡點,根據你的行業,你需要決定哪一個對你來說是可以忍受的,
一個好辦法是取平均數,計算平均值有一個獨特的公式,這就是f1分數,f1得分公式為:
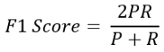
這里,P和R分別表示精確性和召回率,
我不想詳細說明為什么這個公式如此獨特,因為這篇文章是關于例外檢測的,如果你對這篇文章更感興趣的話,可以查看:https://towardsdatascience.com/a-complete-understanding-of-precision-recall-and-f-score-concepts-23dc44defef6
根據f1分數,你需要選擇你的閾值概率,
例外檢測演算法
我將使用Andrew Ng的機器學習課程的資料集,它具有兩個訓練特征,我沒有在本文中使用真實的資料集,因為這個資料集非常適合學習,它只有兩個特征,在任何真實的資料集中,都不可能只有兩個特征,
有兩個特性的好處是可以可視化資料,這對學習者非常有用,請隨意從該鏈接下載資料集,然后繼續:
https://github.com/rashida048/Machine-Learning-With-Python/blob/master/ex8data1.xlsx
首先,匯入必要的包
import pandas as pd
import numpy as np
匯入資料集,這是一個excel資料集,在這里,訓練資料和交叉驗證資料存盤在單獨的表中,所以,讓我們把訓練資料帶來,
df = pd.read_excel('ex8data1.xlsx', sheet_name='X', header=None)
df.head()
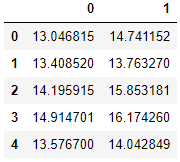
讓我們將第0列與第1列進行比較,
plt.figure()
plt.scatter(df[0], df[1])
plt.show()
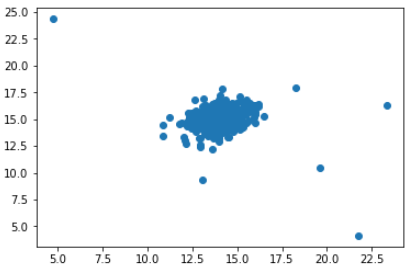
你可能通過看這張圖知道哪些資料是例外的,
檢查此資料集中有多少個訓練示例:
m = len(df)
計算每個特征的平均值,這里我們只有兩個特征:0和1,
s = np.sum(df, axis=0)
mu = s/m
mu
輸出:
0 14.112226
1 14.997711
dtype: float64
根據上面“公式和程序”部分中描述的公式,讓我們計算方差:
vr = np.sum((df - mu)**2, axis=0)
variance = vr/m
variance
輸出:
0 1.832631
1 1.709745
dtype: float64
現在把它做成對角線形狀,正如我在概率公式后面的“公式和程序”一節中所解釋的,求和符號實際上是方差
var_dia = np.diag(variance)
var_dia
輸出:
array([[1.83263141, 0. ],
[0. , 1.70974533]])
計算概率:
k = len(mu)
X = df - mu
p = 1/((2*np.pi)**(k/2)*(np.linalg.det(var_dia)**0.5))* np.exp(-0.5* np.sum(X @ np.linalg.pinv(var_dia) * X,axis=1))
p
訓練部分已經完成,
下一步是找出閾值概率,如果概率低于閾值概率,則示例資料為例外資料,但我們需要為我們的特殊情況找出那個閾值,
對于這一步,我們使用交叉驗證資料和標簽,
對于你的案例,你只需保留一部分原始資料以進行交叉驗證,
現在匯入交叉驗證資料和標簽:
cvx = pd.read_excel('ex8data1.xlsx', sheet_name='Xval', header=None)
cvx.head()
標簽如下:
cvy = pd.read_excel('ex8data1.xlsx', sheet_name='y', header=None)
cvy.head()

我將把'cvy'轉換成NumPy陣列,因為我喜歡使用陣列,不過,資料幀也不錯,
y = np.array(cvy)
輸出:
# 陣列的一部分
array([[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
[0],
這里,y值0表示這是一個正常的例子,y值1表示這是一個例外的例子,
現在,如何選擇一個閾值?
我不想只檢查概率表中的所有概率,這可能是不必要的,讓我們再檢查一下概率值,
p.describe()
輸出:
count 3.070000e+02
mean 5.905331e-02
std 2.324461e-02
min 1.181209e-23
25% 4.361075e-02
50% 6.510144e-02
75% 7.849532e-02
max 8.986095e-02
dtype: float64
如圖所示,我們沒有太多例外資料,所以,如果我們從75%的值開始,這應該是好的,但為了安全起見,我會從平均值開始,
因此,我們將從平均值和更低的概率范圍,我們將檢查這個范圍內每個概率的f1分數,
首先,定義一個函式來計算真正例、假正例和假反例:
def tpfpfn(ep):
tp, fp, fn = 0, 0, 0
for i in range(len(y)):
if p[i] <= ep and y[i][0] == 1:
tp += 1
elif p[i] <= ep and y[i][0] == 0:
fp += 1
elif p[i] > ep and y[i][0] == 1:
fn += 1
return tp, fp, fn
列出低于或等于平均概率的概率,
eps = [i for i in p if i <= p.mean()]
檢查一下串列的長度
len(eps)
輸出:
133
根據前面討論的公式定義一個計算f1分數的函式:
def f1(ep):
tp, fp, fn = tpfpfn(ep)
prec = tp/(tp + fp)
rec = tp/(tp + fn)
f1 = 2*prec*rec/(prec + rec)
return f1
所有函式都準備好了!
現在計算所有epsilon或我們之前選擇的概率值范圍的f1分數,
f = []
for i in eps:
f.append(f1(i))
f
輸出:
[0.14285714285714285,
0.14035087719298248,
0.1927710843373494,
0.1568627450980392,
0.208955223880597,
0.41379310344827586,
0.15517241379310345,
0.28571428571428575,
0.19444444444444445,
0.5217391304347826,
0.19718309859154928,
0.19753086419753085,
0.29268292682926833,
0.14545454545454545,
這是f分數表的一部分,長度應該是133,
f分數通常在0到1之間,其中f1得分越高越好,所以,我們需要從剛才計算的f分數串列中取f的最高分數,
現在,使用“argmax”函式來確定f分數值最大值的索引,
np.array(f).argmax()
輸出:
131
現在用這個索引來得到閾值概率,
e = eps[131]
e
輸出:
6.107184445968581e-05
找出例外實體
我們有臨界概率,我們可以從中找出我們訓練資料的標簽,
如果概率值小于或等于該閾值,則資料為例外資料,否則為正常資料,我們將正常資料和例外資料分別表示為0和1,
label = []
for i in range(len(df)):
if p[i] <= e:
label.append(1)
else:
label.append(0)
label
輸出:
[0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
這是標簽串列的一部分,
我將在上面的訓練資料集中添加此計算標簽:
df['label'] = np.array(label)
df.head()
我在標簽為1的地方用紅色繪制資料,在標簽為0的地方用黑色繪制,以下是結果,
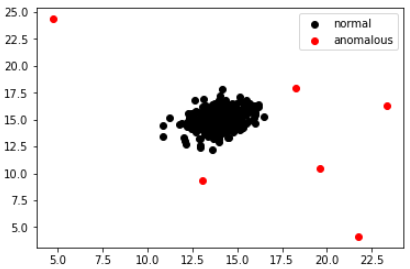
有道理嗎?
是的,對吧?紅色的資料明顯例外,
結論
我試圖一步一步地解釋開發例外檢測演算法的程序,我希望這是可以理解的,如果你僅僅通過閱讀就無法理解,我建議你運行每一段代碼,那就很清楚了,
原文鏈接:https://towardsdatascience.com/a-complete-anomaly-detection-algorithm-from-scratch-in-python-step-by-step-guide-e1daf870336e
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/172566.html
標籤:其他
上一篇:DNS作業原理