編者按
本文整理自 Johann Schleier-Smith 在 ServerlessDays China 的演講,是來自加州大學伯克利分校計算機科學 Riselab 團隊的研究成果,

ServerlessDays 是由全球 Serverless 開發者發起的國際技識訓議,2020 年由騰訊云 Serverless 團隊引入中國,并承辦了首屆 ServerlessDays China 會議,會上 Johann Schleier-Smith 代表伯克利計算機科學 Riselab 實驗室進行了主題發言,

本次演講主要分為四個部分:首先闡述 UC Berkeley 怎樣來定義 Serverless ,之后會分享一些近期的研究成果和進展,最后提出對云計算未來的一些預測和設想,
一、定義 Serverless
大家對于 Function as a Service 函式即服務應該都比較熟悉,例如騰訊的 SCF,Azure Functions 和 AWS Lambda 等等,這些服務中,你可以將一段代碼(通常是無狀態的應用代碼)上傳到云端,之后基于 API 呼叫或者配置觸發器等方式,隨時在云端執行你上傳的代碼,很棒的一點是,FaaS 服務是按需付費的,根據執行時間和呼叫次數計費,
那么對于 Backend as a Service 后端即服務,相信大家也都聽說過,但并不了解 BaaS 的準確含義,其中的一個重要原因是,BaaS 這個詞對于不同的人來說含義也不同,對我們來說,BaaS 是和 FaaS 相對應的概念,其中“即服務”指的是不以“服務器”的方式來提供服務,例如騰訊云的 COS 物件存盤服務,AWS DynamoDB 等,都算做是后端即服務,
從定義可以看出,FaaS 和 BaaS 的特點相互呼應和緊密結合,例如 FaaS 是無狀態的,而 BaaS 是有狀態的;FaaS 基本上可以支持所有運行時的代碼,而 BaaS 對編程模型的限制更嚴格,或者幾乎不涉及編程模型,例如物件存盤服務,但可以看到,雙方的相同點在于彈性伸縮和按需付費,

可以認為 Serverless Computing 是一種用云的簡化方式,我們可以用下面這張圖來說明,從最底下開始,在最底層你需要硬體,要有 CPU,網路,存盤,和一些加速器(如 GPU 或者機器學習的加速器),在這之上云通過虛擬化技術提供了抽象層,硬體服務器被分隔成了多個互相隔離的虛擬機/虛擬私有網路,這一層的服務形態和底層架構是類似的,對于應用層面來說使用起來也有一些復雜,所以出現了 Serverless 的概念,在這一層中 Serverless 化的服務讓呼叫基礎設施變得更加簡單,
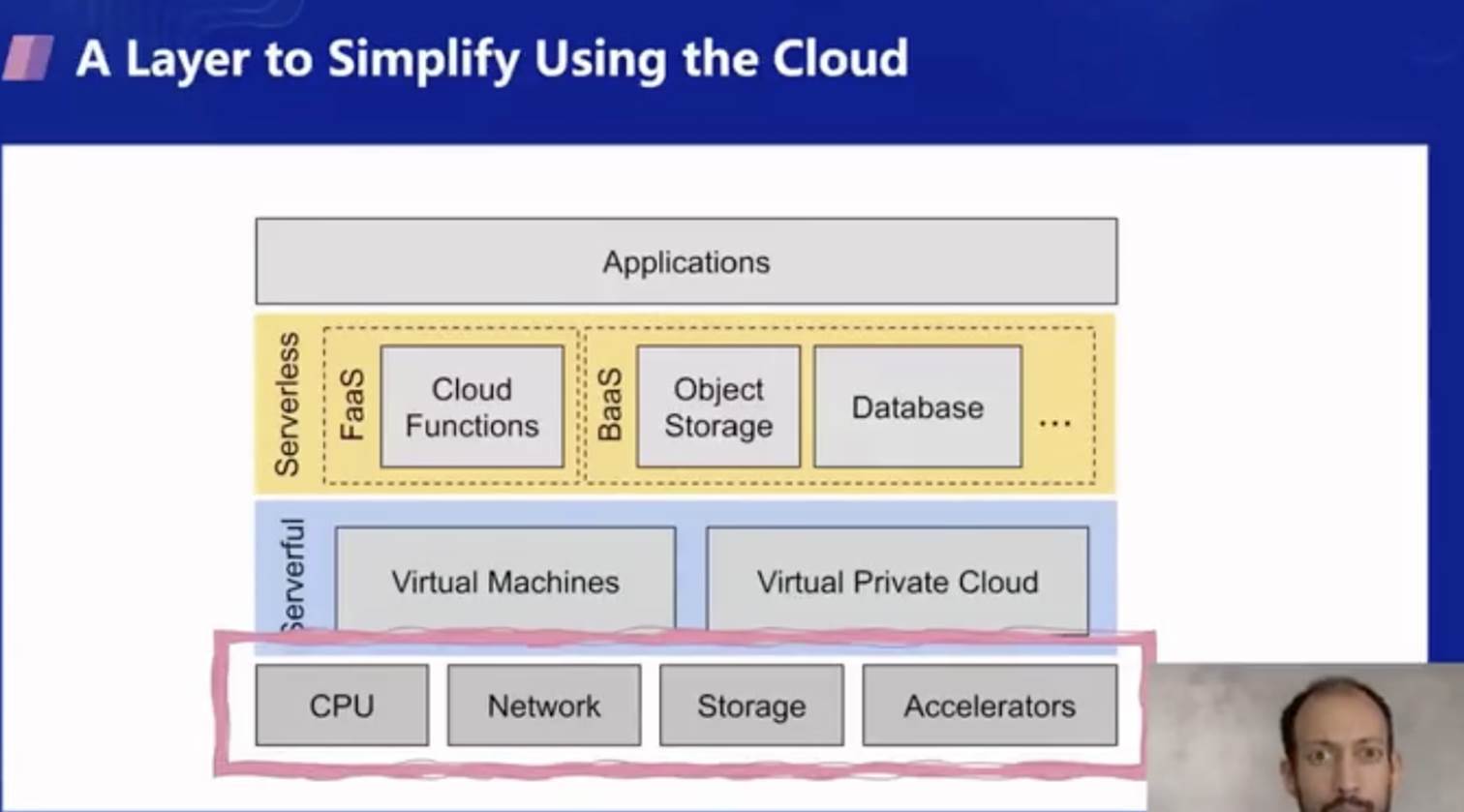
接下來我們可以看下,為什么說傳統的服務器托管比較復雜呢?主要是因為有太多方面需要考慮,即使對于一個簡單的應用而言,你也要考慮下面這些方面:可用性,多地域部署,擴縮容,監控告警和排障,系統升級和安全漏洞,遷移策略等等,

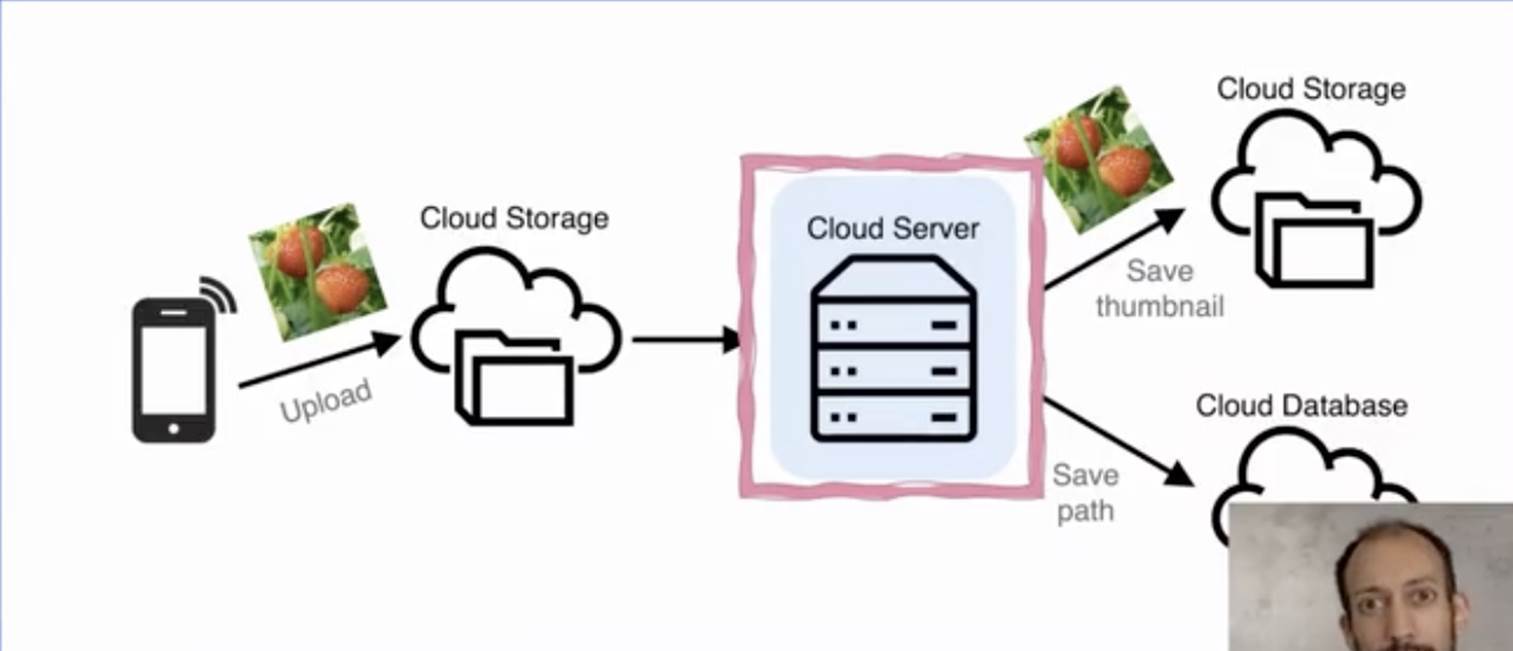
有個非常經典的案例可以說明傳統和 Serverless 架構的區別,在這個例子中,希望實作非常簡單的功能:上傳圖片,對圖片做壓縮后,提取并存盤圖片的點贊和路徑等資訊到資料庫等,如果你要用服務器來做,則需要非常長的處理和搭建流程;但是如果用 Serverless 架構來做,則只需要負責 FaaS 的代碼處理邏輯即可,但是這里要強調的是,該應用的實作不只需要 FaaS 的處理,也同樣需要 BaaS 服務的配合,才能實作完整的 Serverless 架構,
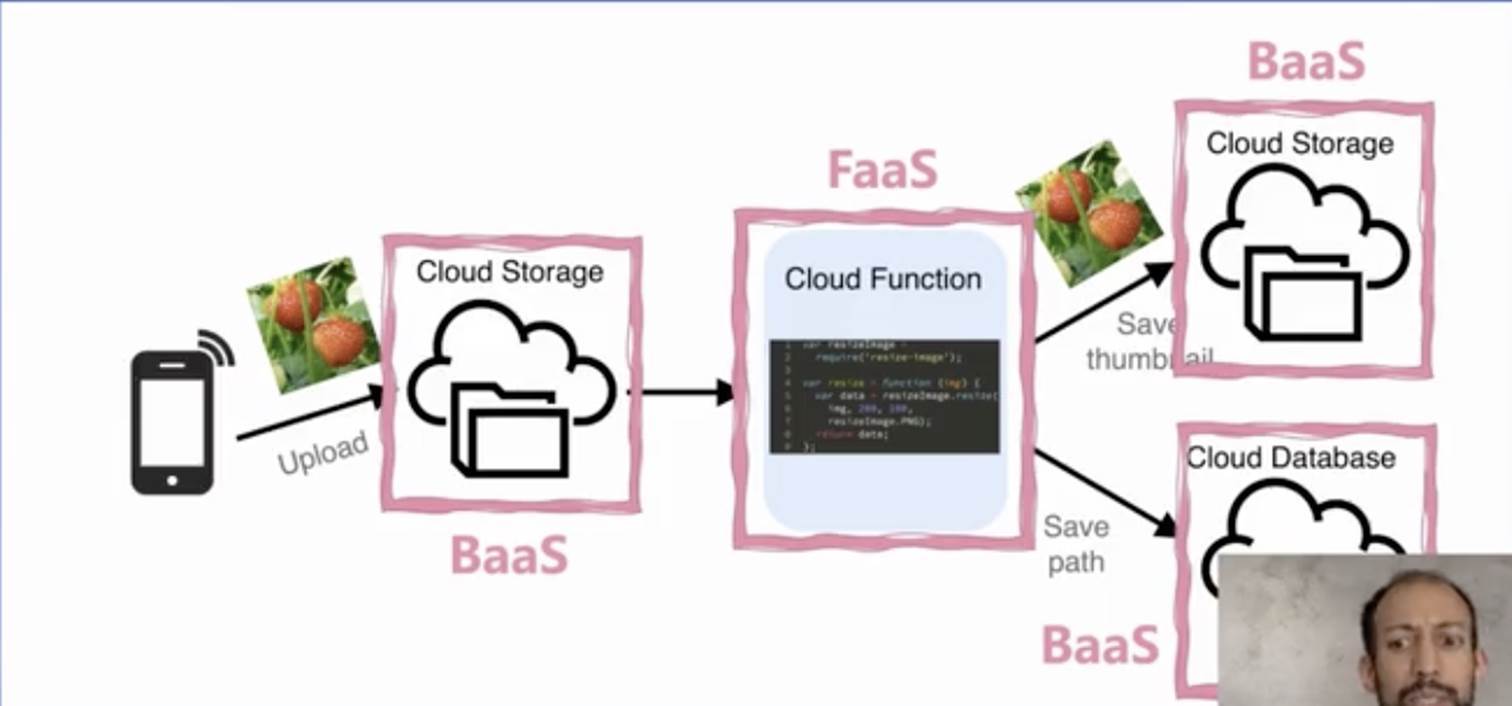
總結起來,在 UC Berkeley 我們認為 Serverless 需要滿足下面三個關鍵特性:
-
隱藏了服務器的概念,雖然服務器依然存在,但開發者不感知,也無需針對服務器進行繁瑣開發和運維操作
-
提供了一種按需付費的計費模型,并且在資源空閑時不收費
-
提供極致的彈性伸縮能力,從而讓資源的提供完美適配業務需求
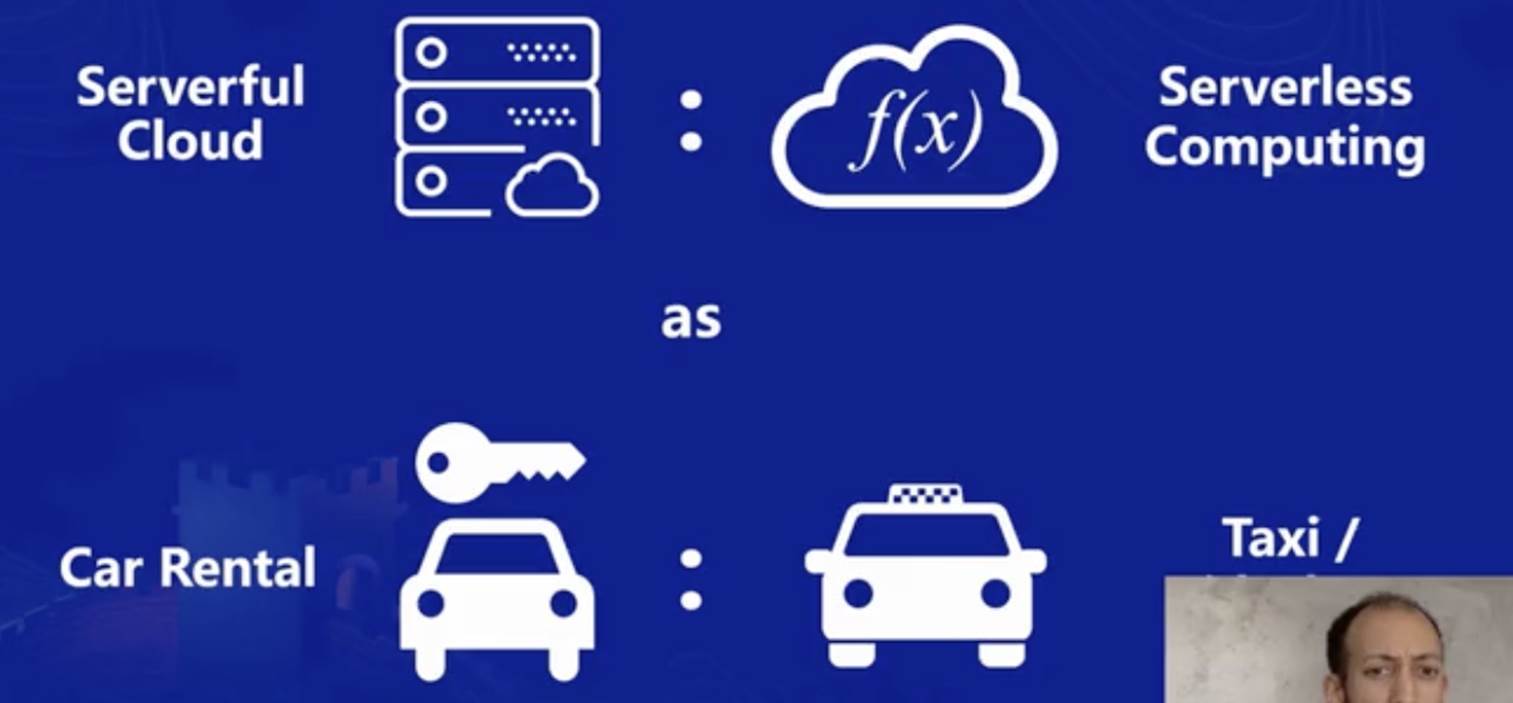
如果舉例說明,可以將傳統服務器和 Serverless 用租車和打車來做對比,(不展開)
云計算的進化歷程可以從資源的分配和收費模型中看出,在傳統的硬體時代,需要預分配物理資源來承載業務;而在服務器時代,則需要通過粒度較粗的服務器實體來進行擴縮容和計費,用于承載業務;在 Serverless 時代,才能真正做到極致彈性和按需付費,
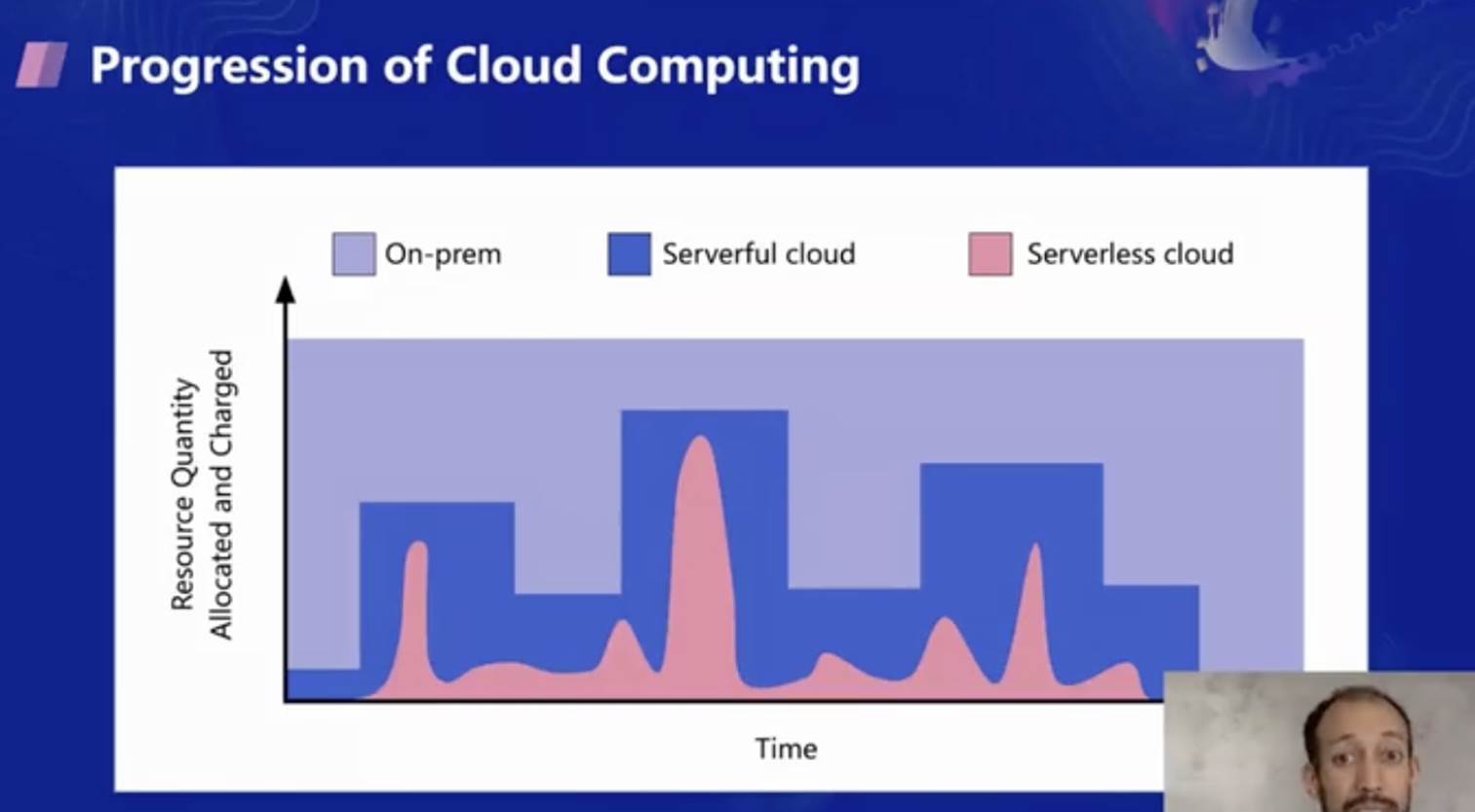
因此,在 Berkeley 我們認為 Serverless 是云計算的下一個階段,不僅因為彈性伸縮和按需付費的特點,還有個重要原因是,我們認為 Serverless 改變了人和電腦協作的方式,
在云計算的第一階段,極大的簡化了系統管理員的職責,人們可以通過 API 的方式獲得服務器,無需自建機房,這種獲取資源的方式十分簡單,開發者都可以輕易的實作資源的購買和配置,而在這一階段,云服務商則負責管理并保證這些資源的穩定性,
在云計算的第二階段,在運維/管理員之外,進一步簡化了開發者的職責,開發者不需要關心復雜的資源分配/運維邏輯,只需要寫好原生業務邏輯,上傳到云端后就可以執行,無需擔心擴縮容的問題,而云服務商則承擔了系統管理員和資源管理的角色,在這階段,云計算對開發者編程模式的改變,就好像十年前的第一階段中,云計算對系統管理員的職責轉變一樣,是十分重大的轉折,這一轉變也極大的激勵了開發者,拓展了他們的能力邊界,開發者可以專注于業務實作,無需擔心底層資源的運維,

二、Serverless 研究成果和亮點
在第二部分,我想分享一些 Berkeley 最近的研究成果,我們發現,Serverless 中 FaaS 部分很難解決所有問題,因為函式即服務從平臺層面有諸多限制:
首先是運行時間的限制,當前各云平臺對于 FaaS 的運行時間都有 10-15分鐘的限制,這種限制影響了許多場景的實作,尤其是一些強狀態依賴的場景,例如長時間保持資料庫連接的情況等,
此外,FaaS 平臺只能支持短暫的有狀態性(Ephemeral State),沒有磁盤可以存盤或者永久保存狀態資訊,
第三點,當前不能直接和函式服務進行網路通信,函式即服務可以提供外訪能力,但對于入流量的支持不夠友好,例如在你開發的應用中,獲取到函式中的一些資料會比較困難,從而可能會影響軟體原本的開發方式,需要欄位外的適配,
最后一個限制是在硬體層面的,例如一個機器學習方面的應用利用了 GPU 硬體,在當前的 Serverless 計算層面是難以提供 Serverless GPU 計算資源的,

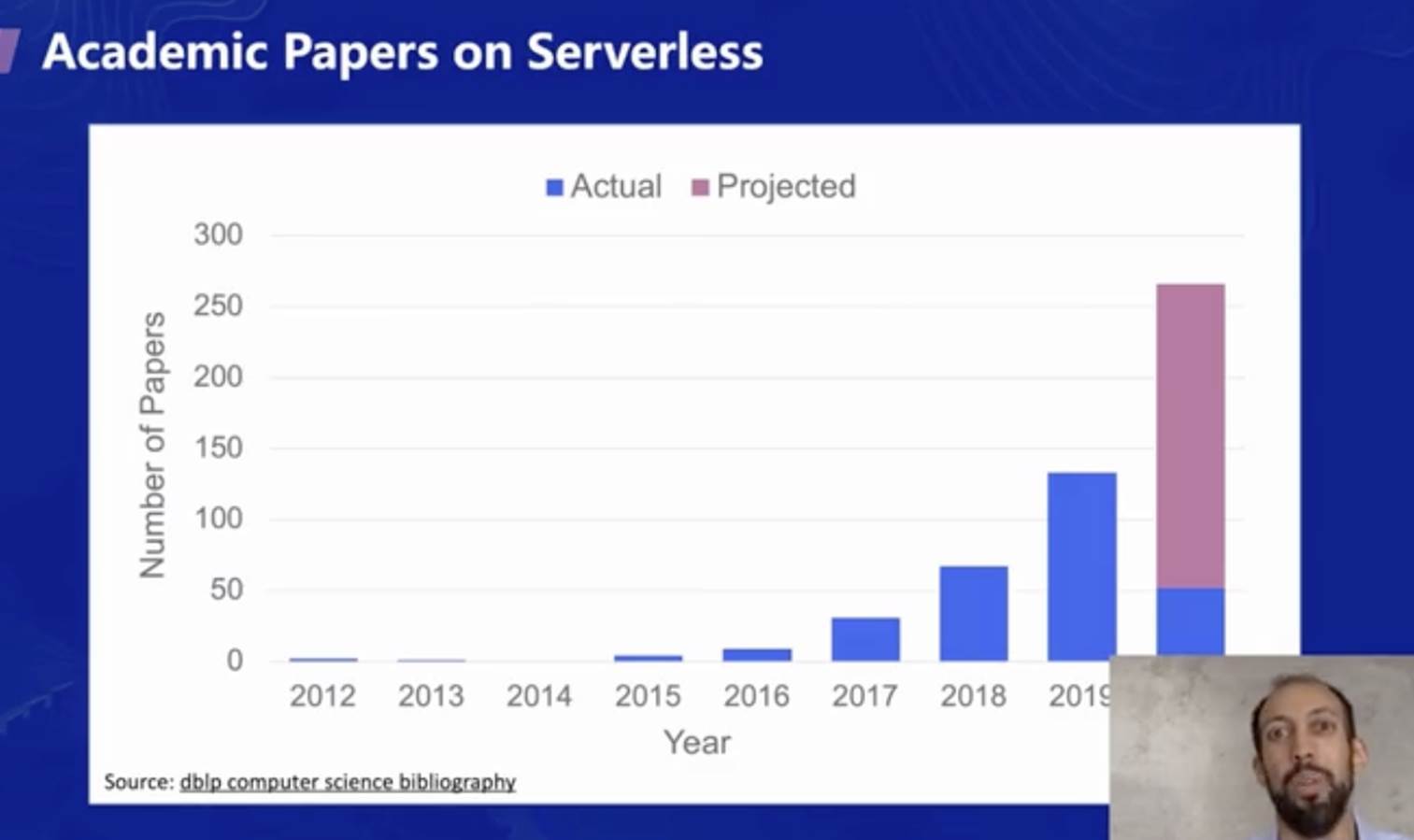
當新的技術趨勢出現時,學術界往往非常活躍,從近幾年的對 Serverless 方向研究的論文數就可以看出,如下圖所示,最近幾年來,Serverless 方向的論文數每年都在翻倍增長,在 2020 年,已發表+計劃發表的論文將繼續翻倍,達到近 300 篇,
在分享一些具體研究成果之前,我想先簡單介紹下幾種不同的 Serverless 研究方向:
- 具體應用的抽象:選取一個場景,將其 Serverless 化,不會做太多通用層面的抽象,例如針對大資料檢索并生成報表等,只要用 Serverless 解決該場景下的問題即可,
- 通用的抽象:我認為這個層面的研究最有意思,并且自己也在做這方面的研究,即通過滿足一些條件,即可讓任意業務適配 Serverless 架構,本質上說,這就涉及到怎樣針對分布式系統進行開發模式的簡化,
- 實作層面:當函式即服務剛推出的時候,在效率等方面有很多待提升的地方,目前雖然已經有一些改善,但從學術層面依然有非常多可深入優化的地方,例如 FaaS 平臺將不斷追求更低的延遲,更好地狀態共享,租戶隔離,極致的彈性擴展等方面,

接下來我將分享 Berkeley 近期在以下五個方面的研究成果,分別是 Serverless 機器學習,以及用于支持機器學習的 GPU 相關的內核即服務,之后會分享狀態性相關的云函式檔案系統和 Starburst,最后會通過展望 Serverless 資料中心來收尾,

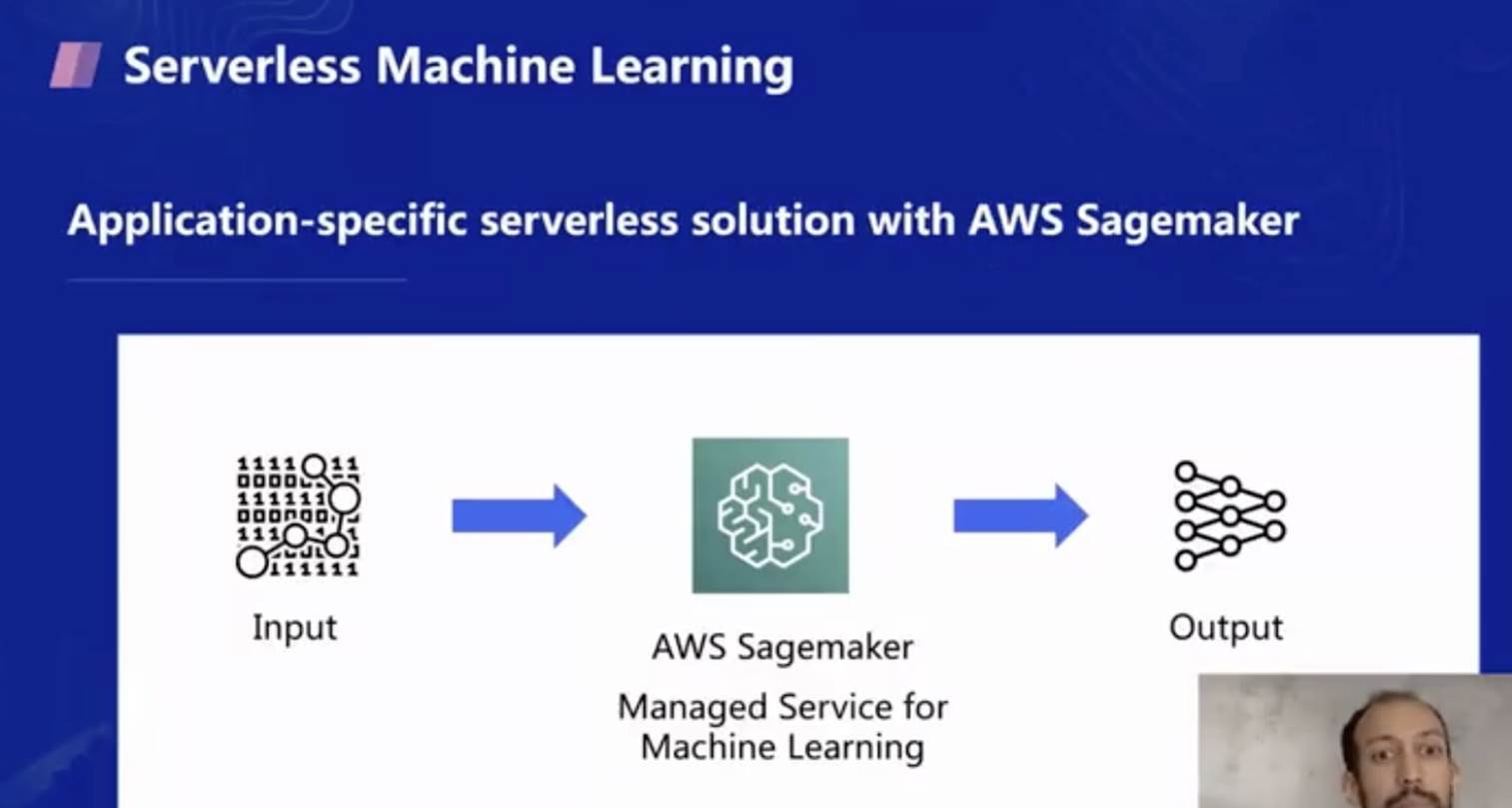
第一個是機器學習方面的研究,當前其實在云端已經提供了應用層面的 Serverless 機器學習服務,例如 AWS 的 Sagemaker 服務,用戶只要輸入資料,設定好模型,Sagemaker 就會幫忙做訓練,并按照模型的訓練時間來計費,但這個服務僅是針對機器學習這個特定場景的,并不具備普適性,此外,對于模型有定制化需求,或者訓練步驟有改動場景(例如 Berkeley 的一些新的訓練演算法),這個服務并不能完全滿足需求,
那么是否可以推出更加通用的機器學習解決方案呢?例如把資料或者代碼作為函式的輸入,并將其運行在 AWS Lambda 函式服務及 Cirrus 上進行機器學習訓練,因此團隊開發了 Cirrus 的機器學習庫,可以讓用戶方便的在 Lambda 上端到端地進行機器學習訓練,滿足定制化需求,
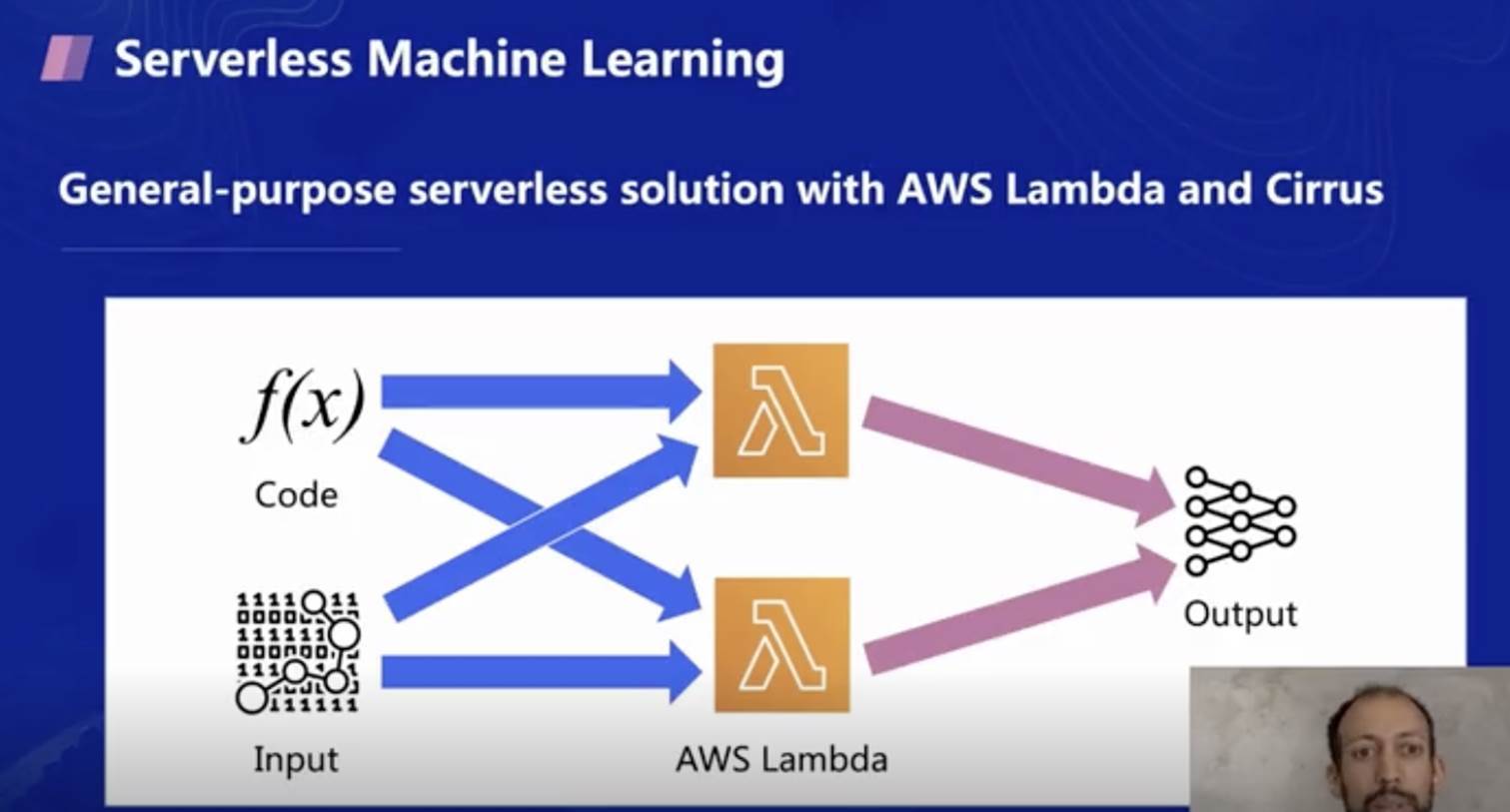
Cirrus 團隊在 FaaS 平臺上做了很多嘗試,也遇到了非常多平臺的限制,例如記憶體過小,上傳的代碼包大小有限制,不支持 P2P (peer to peer) 點對點傳輸,沒有快速的存盤介質,實體的生命周期有限,會被回收和重啟等,
但是根據右邊的實驗結果可以看出,在越短的執行時間內,Cirrus 的性能表現越好,甚至優于其他幾種機器學習技術,因此你可以根據自己的訓練模型和需求選擇要不要使用 Cirrus 作為 Serverless 機器學習的訓練方案,
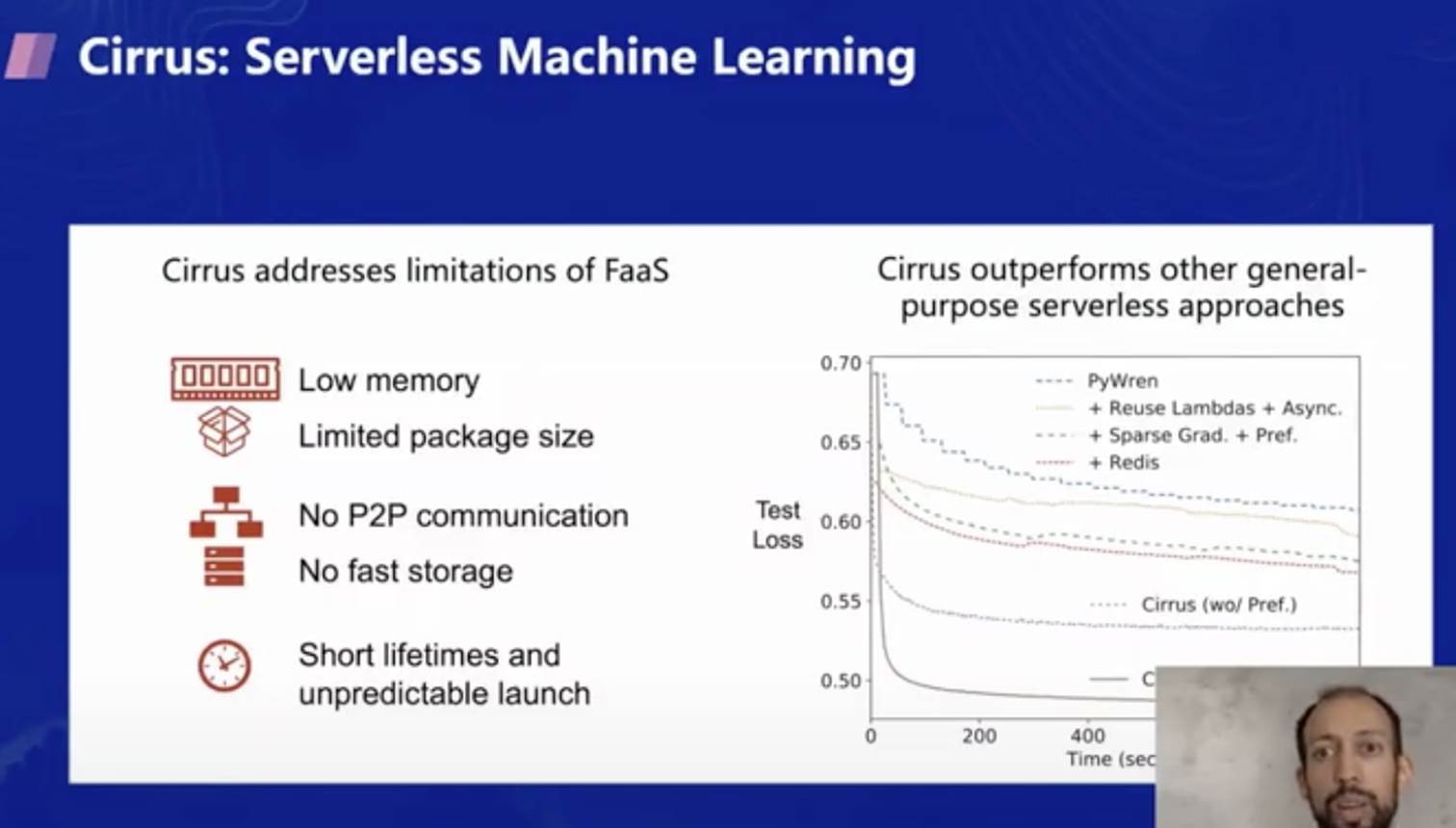
參考文獻:
- ucbrise/cirrus
- [Cirrus: a Serverless Framework for End-to-end ML Workflows]https://people.eecs.berkeley.edu/~joao/p13-Carreira.pdf)
第二個研究課題是關于機器學習作為容器即服務 (Kernel as a Service) 的,大家都知道當前 FaaS 主要運行在 CPU 的硬體上,而在機器學習領域,GPU 針對許多演算法和作業流提供了非常重要的加速作用,因此 Berkeley 團隊希望提供一種方案,將 GPU 和 Serverless 計算更好地結合在一起,
由于成本/價格原因,目前商業化的云函式服務不提供 GPU 函式,因為 GPU 服務器價格高昂,需要針對機器利用率做進一步優化后才能真正進行商業化使用,因此,我們提出了 KaaS 容器即服務的概念,和 FaaS 的 Node.js 和 Python 等運行時一樣,只不過 KaaS 中運行時支持的是面向 GPU 的語言如 CUDA 或 OpenCL,但當前研究的挑戰在于,是否可以完全通過純GPU 語言來撰寫 KaaS 服務,完全擺脫對 CPU 代碼的依賴呢?
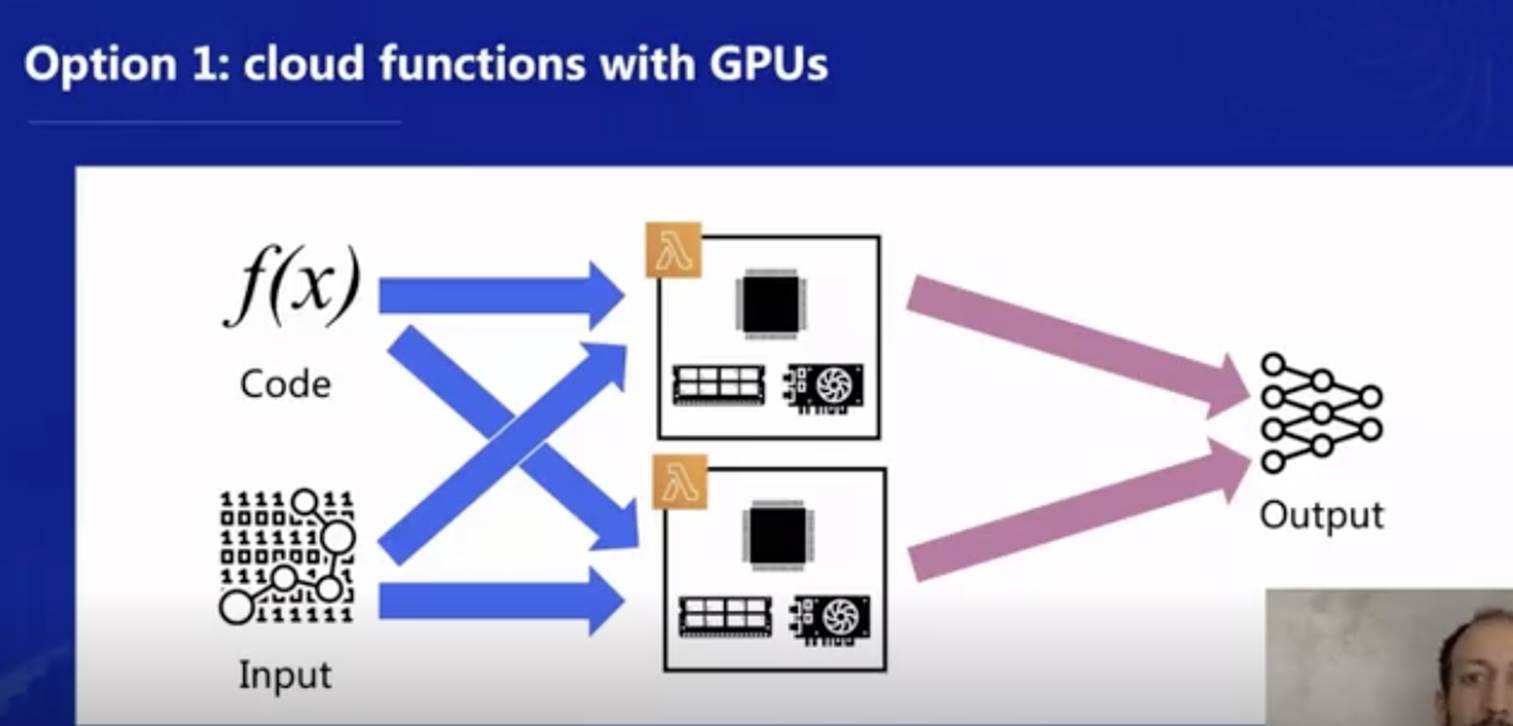
下圖可以進一步解釋這個理念,一種方式是在函式平臺中同時提供 CPU 和 GPU 的支持,即每個函式的底層架構中既有 CPU、記憶體卡,也有 GPU 加速器,
但是有挑戰的地方在于,是否可以像下圖一樣,提供一個 GPU-only 的純 GPU 底層來運行函式呢?這樣可以徹底區分 CPU/記憶體型函式和 GPU 型函式,由于當前從通訊模式上還比較難將 CPU 和 GPU 從硬體上徹底分開,這將是研究中比較大的一個挑戰,
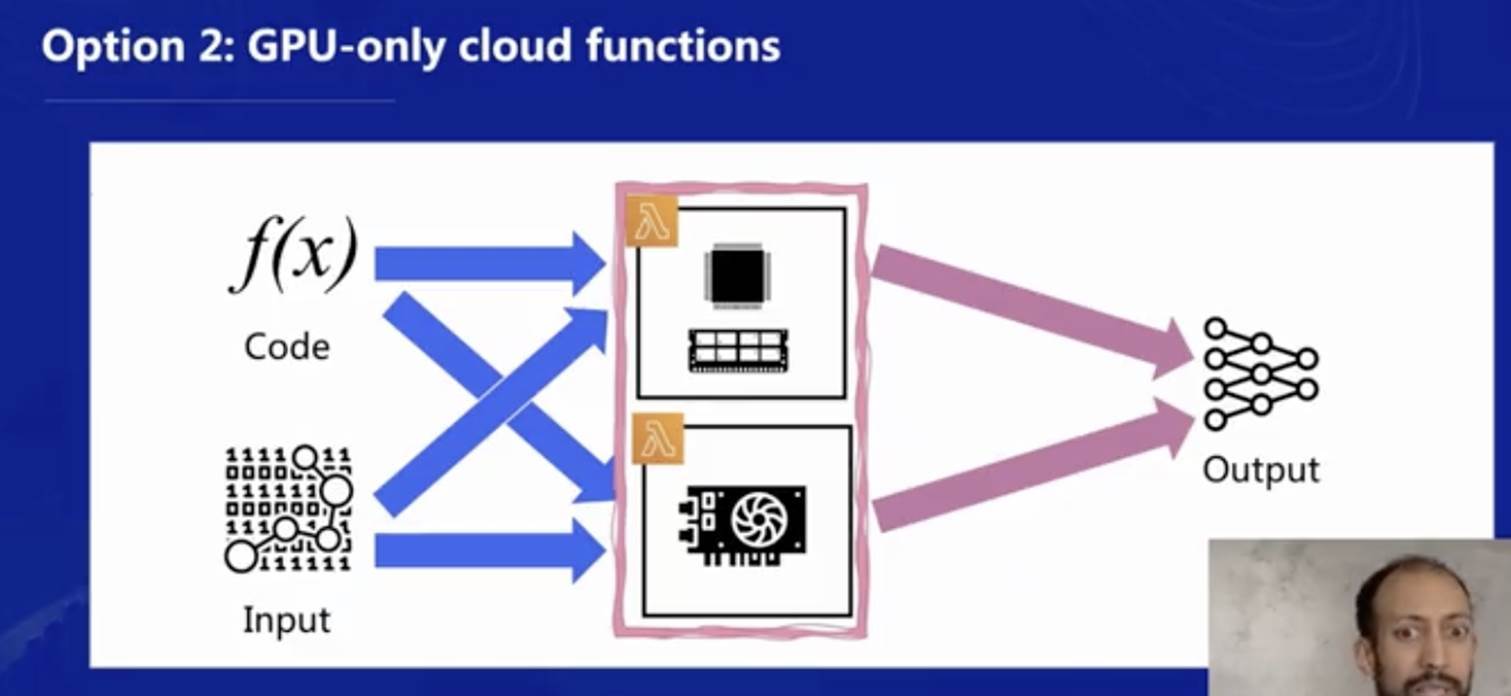
參考文獻:PyPlover: A System for GPU-enabled Serverless Instances
第三個研究課題主要是 Serverless 檔案系統 —— 狀態性方面的優化,也是非常有價值的一個方向, 見下篇:《權威指南:Serverless 未來十年發展解讀 — 伯克利分校實驗室分享(下)》
One More Thing
立即體驗騰訊云 Serverless Demo,領取 Serverless 新用戶禮包 ?? serverless/start
歡迎訪問:Serverless 中文網!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/173174.html
標籤:其他