作者|Yuki Takahashi
編譯|VK
來源|Towards Datas Science

自在ImageNet上推出AlexNet以來,計算機視覺的深度學習已成功應用于各種應用,相反,NLP在深層神經網路應用方面一直落后,許多聲稱使用人工智能的應用程式通常使用某種基于規則的演算法和傳統的機器學習,而不是使用深層神經網路,
2018年,在一些NLP任務中,一種名為BERT的最先進(STOA)模型的表現超過了人類的得分,在這里,我將幾個模型應用于情緒分析任務,以了解它們在我所處的金融市場中有多大用處,代碼在jupyter notebook中,在git repo中可用:https://github.com/yuki678/financial-phrase-bert
介紹
NLP任務可以大致分為以下幾類,
-
文本分類——過濾垃圾郵件,對檔案進行分類
-
詞序——詞翻譯,詞性標記,命名物體識別
-
文本意義——主題模型,搜索,問答
-
seq2seq——機器翻譯、文本摘要、問答
-
對話系統
不同的任務需要不同的方法,在大多數情況下是多種NLP技術的組合,在開發機器人時,后端邏輯通常是基于規則的搜索引擎和排名演算法,以形成自然的通信,
這是有充分理由的,語言有語法和詞序,可以用基于規則的方法更好地處理,而機器學習方法可以更好地學習單詞相似性,向量化技術如word2vec、bag of word幫助模型以數學方式表達文本,最著名的例子是:
King - Man + Woman = Queen
Paris - France + UK = London
第一個例子描述了性別關系,第二個例子描述了首都的概念,然而,在這些方法中,由于在任何文本中同一個詞總是由同一個向量表示,因此背景關系不能被捕獲,這在許多情況下是不正確的,
回圈神經網路(RNN)結構利用輸入序列的先驗資訊,處理時間序列資料,在捕捉和記憶背景關系方面表現良好,LSTM是一種典型的結構,它由輸入門、輸出門和遺忘門組成,克服了RNN的梯度問題,有許多基于LSTM的改進模型,例如雙向LSTM,不僅可以從前面的單詞中捕捉背景關系,而且可以從后面捕獲背景關系,這些方法對于某些特定的任務是有用的,但在實際應用中卻不太適用,
2017年,我們看到了一種新的方法來解決這個問題,BERT是Google在2018年推出的一個多編碼器堆疊的掩碼語言模型,在GLUE、SQuAD和SWAG基準測驗中實作了STOA,并有了很大的改進,有很多文章和博客解釋了這種架構,比如Jay Alammar的文章:http://jalammar.github.io/illustrated-bert/
我在金融行業作業,在過去的幾年里,我很難看到我們在NLP上的機器學習模型在交易系統中的生產應用方面有足夠的強勁表現,現在,基于BERT的模型正在變得成熟和易于使用,這要歸功于Huggingface的實作和許多預訓練的模型已經公開,
我的目標是看看這個NLP的最新開發是否達到了在我的領域中使用的良好水平,在這篇文章中,我比較了不同的模型,這是一個相當簡單的任務,即對金融文本的情緒分析,以此作為基線來判斷是否值得在真正的解決方案中嘗試另一個研發,
此處比較的模型有:
-
基于規則的詞典方法
-
基于Tfidf的傳統機器學習方法
-
作為一種回圈神經網路結構的LSTM
-
BERT(和ALBERT)
輸入資料
在情緒分析任務中,我采用以下兩種輸入來表示行業中的不同語言,
-
財經新聞標題——正式
-
來自Stocktwits的Tweets——非正式
我將為后者寫另一篇文章,所以這里關注前者的資料,這是一個包含更正式的金融領域特定語言的文本示例,我使用了Malo等人的FinancialPhraseBank(https://www.researchgate.net/publication/251231107_Good_Debt_or_Bad_Debt_Detecting_Semantic_Orientations_in_Economic_Texts)包括4845篇由16人手寫的標題文本,并提供同意等級,我使用了75%的同意等級和3448個文本作為訓練資料,
## 輸入文本示例
positive "Finnish steel maker Rautaruukki Oyj ( Ruukki ) said on July 7 , 2008 that it won a 9.0 mln euro ( $ 14.1 mln ) contract to supply and install steel superstructures for Partihallsforbindelsen bridge project in Gothenburg , western Sweden."
neutral "In 2008 , the steel industry accounted for 64 percent of the cargo volumes transported , whereas the energy industry accounted for 28 percent and other industries for 8 percent."
negative "The period-end cash and cash equivalents totaled EUR6 .5 m , compared to EUR10 .5 m in the previous year."

請注意,所有資料都屬于來源,用戶必須遵守其著作權和許可條款,
模型
下面是我比較了四款模型的性能,
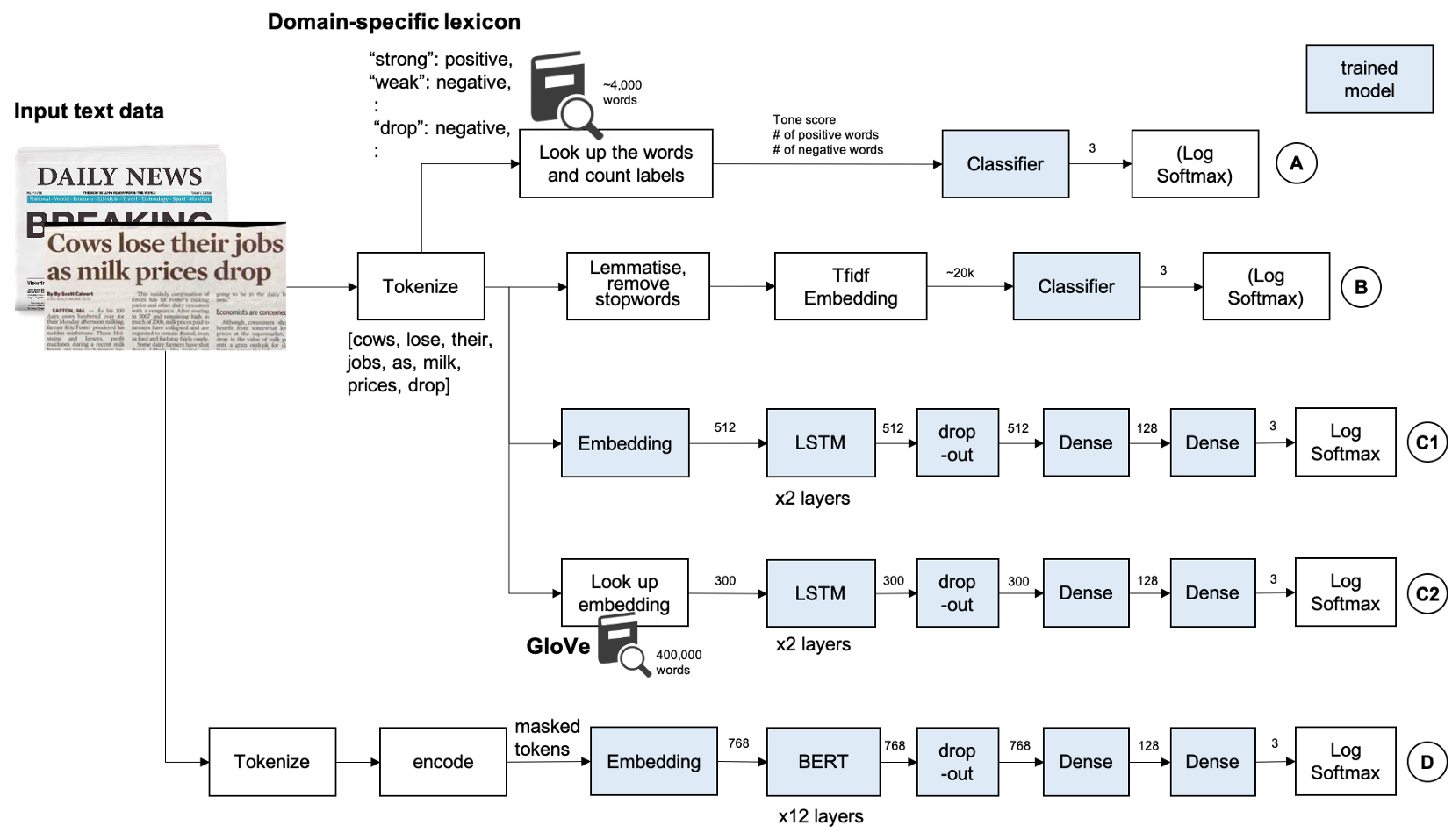
A、 基于詞匯的方法
創建特定于領域的詞典是一種傳統的方法,在某些情況下,如果源代碼來自特定的個人或媒體,則這種方法簡單而強大,Loughran和McDonald情感詞串列,這個串列包含超過4k個單詞,這些單詞出現在帶有情緒標簽的財務報表上,注:此資料需要許可證才能用于商業應用,請在使用前檢查他們的網站,
## 樣本
negative: ABANDON
negative: ABANDONED
constraining: STRICTLY
我用了2355個消極單詞和354個積極單詞,它包含單詞形式,因此不要對輸入執行詞干分析和詞干化,對于這種方法,考慮否定形式是很重要的,比如not,no,don,等等,這些詞會把否定詞的意思改為肯定的,如果前面三個詞中有否定詞,這里我簡單地把否定詞的意思轉換成肯定詞,
然后,情感得分定義如下,
tone_score = 100 * (pos_count — neg_count) / word_count
用默認引數訓練14個不同的分類器,然后用網格搜索交叉驗證法對隨機森林進行超引數整定,
classifiers = []
classifiers.append(("SVC", SVC(random_state=random_state)))
classifiers.append(("DecisionTree", DecisionTreeClassifier(random_state=random_state)))
classifiers.append(("AdaBoost", AdaBoostClassifier(DecisionTreeClassifier(random_state=random_state),random_state=random_state,learning_rate=0.1)))
classifiers.append(("RandomForest", RandomForestClassifier(random_state=random_state, n_estimators=100)))
classifiers.append(("ExtraTrees", ExtraTreesClassifier(random_state=random_state)))
classifiers.append(("GradientBoosting", GradientBoostingClassifier(random_state=random_state)))
classifiers.append(("MultipleLayerPerceptron", MLPClassifier(random_state=random_state)))
classifiers.append(("KNeighboors", KNeighborsClassifier(n_neighbors=3)))
classifiers.append(("LogisticRegression", LogisticRegression(random_state = random_state)))
classifiers.append(("LinearDiscriminantAnalysis", LinearDiscriminantAnalysis()))
classifiers.append(("GaussianNB", GaussianNB()))
classifiers.append(("Perceptron", Perceptron()))
classifiers.append(("LinearSVC", LinearSVC()))
classifiers.append(("SGD", SGDClassifier()))
cv_results = []
for classifier in classifiers :
cv_results.append(cross_validate(classifier[1], X_train, y=Y_train, scoring=scoring, cv=kfold, n_jobs=-1))
# 使用隨機森林分類器
rf_clf = RandomForestClassifier()
# 執行網格搜索
param_grid = {'n_estimators': np.linspace(1, 60, 10, dtype=int),
'min_samples_split': [1, 3, 5, 10],
'min_samples_leaf': [1, 2, 3, 5],
'max_features': [1, 2, 3],
'max_depth': [None],
'criterion': ['gini'],
'bootstrap': [False]}
model = GridSearchCV(rf_clf, param_grid=param_grid, cv=kfold, scoring=scoring, verbose=verbose, refit=refit, n_jobs=-1, return_train_score=True)
model.fit(X_train, Y_train)
rf_best = model.best_estimator_
B、 基于Tfidf向量的傳統機器學習
輸入被NLTK word_tokenize()標記化,然后詞干化和洗掉停用詞,然后輸入到TfidfVectorizer ,通過Logistic回歸和隨機森林分類器進行分類,
### 邏輯回歸
pipeline1 = Pipeline([
('vec', TfidfVectorizer(analyzer='word')),
('clf', LogisticRegression())])
pipeline1.fit(X_train, Y_train)
### 隨機森林與網格搜索
pipeline2 = Pipeline([
('vec', TfidfVectorizer(analyzer='word')),
('clf', RandomForestClassifier())])
param_grid = {'clf__n_estimators': [10, 50, 100, 150, 200],
'clf__min_samples_leaf': [1, 2],
'clf__min_samples_split': [4, 6],
'clf__max_features': ['auto']
}
model = GridSearchCV(pipeline2, param_grid=param_grid, cv=kfold, scoring=scoring, verbose=verbose, refit=refit, n_jobs=-1, return_train_score=True)
model.fit(X_train, Y_train)
tfidf_best = model.best_estimator_
C、 LSTM
由于LSTM被設計用來記憶表達背景關系的長期記憶,因此使用自定義的tokenizer并且輸入是字符而不是單詞,所以不需要詞干化或輸出停用詞,輸入先到一個嵌入層,然后是兩個lstm層,為了避免過擬合,應用dropout,然后是全連接層,最后采用log softmax,
class TextClassifier(nn.Module):
def __init__(self, vocab_size, embed_size, lstm_size, dense_size, output_size, lstm_layers=2, dropout=0.1):
"""
初始化模型
"""
super().__init__()
self.vocab_size = vocab_size
self.embed_size = embed_size
self.lstm_size = lstm_size
self.dense_size = dense_size
self.output_size = output_size
self.lstm_layers = lstm_layers
self.dropout = dropout
self.embedding = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, lstm_size, lstm_layers, dropout=dropout, batch_first=False)
self.dropout = nn.Dropout(dropout)
if dense_size == 0:
self.fc = nn.Linear(lstm_size, output_size)
else:
self.fc1 = nn.Linear(lstm_size, dense_size)
self.fc2 = nn.Linear(dense_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def init_hidden(self, batch_size):
"""
初始化隱藏狀態
"""
weight = next(self.parameters()).data
hidden = (weight.new(self.lstm_layers, batch_size, self.lstm_size).zero_(),
weight.new(self.lstm_layers, batch_size, self.lstm_size).zero_())
return hidden
def forward(self, nn_input_text, hidden_state):
"""
在nn_input上執行模型的前項傳播
"""
batch_size = nn_input_text.size(0)
nn_input_text = nn_input_text.long()
embeds = self.embedding(nn_input_text)
lstm_out, hidden_state = self.lstm(embeds, hidden_state)
# 堆疊LSTM輸出,應用dropout
lstm_out = lstm_out[-1,:,:]
lstm_out = self.dropout(lstm_out)
# 全連接層
if self.dense_size == 0:
out = self.fc(lstm_out)
else:
dense_out = self.fc1(lstm_out)
out = self.fc2(dense_out)
# Softmax
logps = self.softmax(out)
return logps, hidden_state
作為替代,還嘗試了斯坦福大學的GloVe詞嵌入,這是一種無監督的學習演算法,用于獲取單詞的向量表示,在這里,用6百萬個標識、40萬個詞匯和300維向量對Wikipedia和Gigawords進行了預訓練,在我們的詞匯表中,大約90%的單詞都是在這個GloVe里找到的,其余的都是隨機初始化的,
D、 BERT和ALBERT
我使用了Huggingface中的transformer實作BERT模型,現在他們提供了tokenizer和編碼器,可以生成文本id、pad掩碼和段id,可以直接在BertModel中使用,我們使用標準訓練程序,
與LSTM模型類似,BERT的輸出隨后被傳遞到dropout,全連接層,然后應用log softmax,如果沒有足夠的計算資源預算和足夠的資料,從頭開始訓練模型不是一個選擇,所以我使用了預訓練的模型并進行了微調,預訓練的模型如下所示:
-
BERT:bert-base-uncased
-
ALBERT:albert-base-v2
預訓練過的bert的訓練程序如下所示,
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=3)
def train_bert(model, tokenizer)
# 移動模型到GUP/CPU設備
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
model = model.to(device)
# 將資料加載到SimpleDataset(自定義資料集類)
train_ds = SimpleDataset(x_train, y_train)
valid_ds = SimpleDataset(x_valid, y_valid)
# 使用DataLoader批量加載資料集中的資料
train_loader = torch.utils.data.DataLoader(train_ds, batch_size=batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid_ds, batch_size=batch_size, shuffle=False)
# 優化器和學習率衰減
num_total_opt_steps = int(len(train_loader) * num_epochs)
optimizer = AdamW_HF(model.parameters(), lr=learning_rate, correct_bias=False)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=num_total_opt_steps*warm_up_proportion, num_training_steps=num_total_opt_steps) # PyTorch scheduler
# 訓練
model.train()
# Tokenizer 引數
param_tk = {
'return_tensors': "pt",
'padding': 'max_length',
'max_length': max_seq_length,
'add_special_tokens': True,
'truncation': True
}
# 初始化
best_f1 = 0.
early_stop = 0
train_losses = []
valid_losses = []
for epoch in tqdm(range(num_epochs), desc="Epoch"):
# print('================ epoch {} ==============='.format(epoch+1))
train_loss = 0.
for i, batch in enumerate(train_loader):
# 傳輸到設備
x_train_bt, y_train_bt = batch
x_train_bt = tokenizer(x_train_bt, **param_tk).to(device)
y_train_bt = torch.tensor(y_train_bt, dtype=torch.long).to(device)
# 重設梯度
optimizer.zero_grad()
# 前饋預測
loss, logits = model(**x_train_bt, labels=y_train_bt)
# 反向傳播
loss.backward()
# 損失
train_loss += loss.item() / len(train_loader)
# 梯度剪切
torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)
# 更新權重和學習率
optimizer.step()
scheduler.step()
train_losses.append(train_loss)
# 評估模式
model.eval()
# 初始化
val_loss = 0.
y_valid_pred = np.zeros((len(y_valid), 3))
with torch.no_grad():
for i, batch in enumerate(valid_loader):
# 傳輸到設備
x_valid_bt, y_valid_bt = batch
x_valid_bt = tokenizer(x_valid_bt, **param_tk).to(device)
y_valid_bt = torch.tensor(y_valid_bt, dtype=torch.long).to(device)
loss, logits = model(**x_valid_bt, labels=y_valid_bt)
val_loss += loss.item() / len(valid_loader)
valid_losses.append(val_loss)
# 計算指標
acc, f1 = metric(y_valid, np.argmax(y_valid_pred, axis=1))
# 如果改進了,保存模型,如果沒有,那就提前停止
if best_f1 < f1:
early_stop = 0
best_f1 = f1
else:
early_stop += 1
print('epoch: %d, train loss: %.4f, valid loss: %.4f, acc: %.4f, f1: %.4f, best_f1: %.4f, last lr: %.6f' %
(epoch+1, train_loss, val_loss, acc, f1, best_f1, scheduler.get_last_lr()[0]))
if device == 'cuda:0':
torch.cuda.empty_cache()
# 如果達到耐心數,提前停止
if early_stop >= patience:
break
# 回傳訓練模式
model.train()
return model
評估
首先,輸入資料以8:2分為訓練組和測驗集,測驗集保持不變,直到所有引數都固定下來,并且每個模型只使用一次,由于資料集不用于計算交叉集,因此驗證集不用于計算,此外,為了克服資料集不平衡和資料集較小的問題,采用分層K-Fold交叉驗證進行超引數整定,
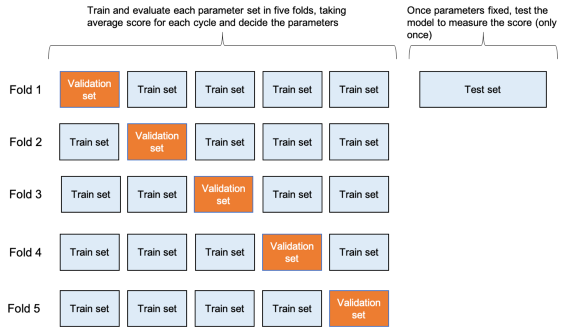
由于輸入資料不平衡,因此評估以F1分數為基礎,同時也參考了準確性,
def metric(y_true, y_pred):
acc = accuracy_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred, average='macro')
return acc, f1
scoring = {'Accuracy': 'accuracy', 'F1': 'f1_macro'}
refit = 'F1'
kfold = StratifiedKFold(n_splits=5)
模型A和B使用網格搜索交叉驗證,而C和D的深層神經網路模型使用自定義交叉驗證,
# 分層KFold
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=rand_seed)
# 回圈
for n_fold, (train_indices, valid_indices) in enumerate(skf.split(y_train, y_train)):
# 模型
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=3)
# 輸入資料
x_train_fold = x_train[train_indices]
y_train_fold = y_train[train_indices]
x_valid_fold = x_train[valid_indices]
y_valid_fold = y_train[valid_indices]
# 訓練
train_bert(model, x_train_fold, y_train_fold, x_valid_fold, y_valid_fold)
結果
基于BERT的微調模型在花費了或多或少相似的超引數調整時間之后,明顯優于其他模型,
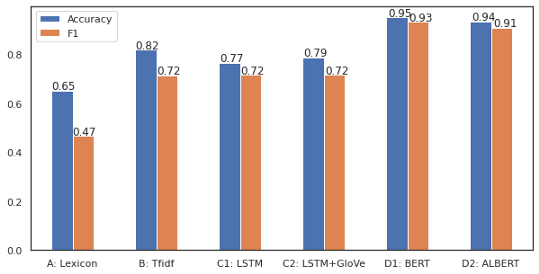
模型A表現不佳,因為輸入過于簡化為情感得分,情感分數是判斷情緒的單一值,而隨機森林模型最終將大多數資料標記為中性,簡單的線性模型只需對情感評分應用閾值就可以獲得更好的效果,但在準確度和f1評分方面仍然很低,
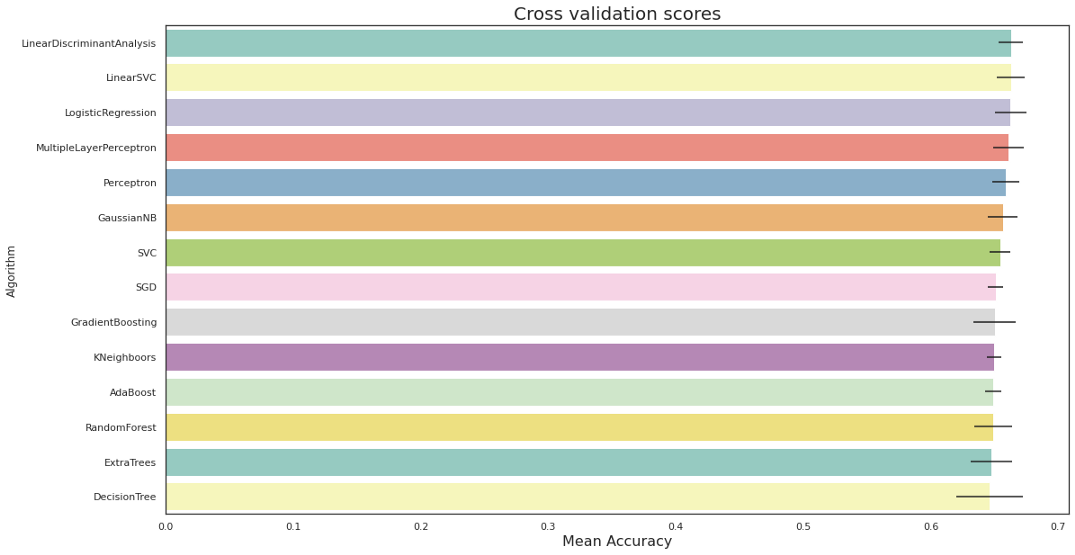
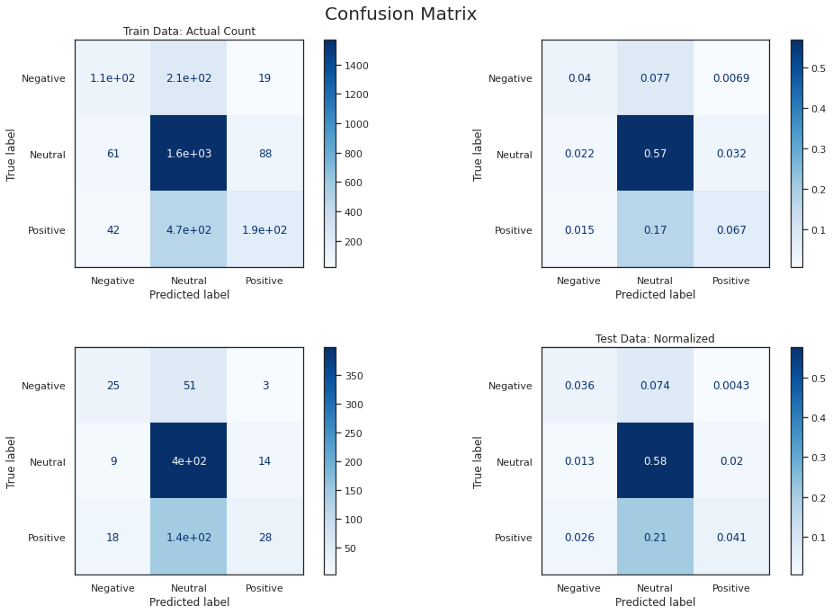
我們沒有使用欠采樣/過采樣或SMOTE等方法來平衡輸入資料,因為它可以糾正這個問題,但會偏離存在不平衡的實際情況,如果可以證明為每個要解決的問題建立一個詞典的成本是合理的,這個模型的潛在改進是建立一個自定義詞典,而不是L-M詞典,
模型B比前一個模型好得多,但是它以幾乎100%的準確率和f1分數擬合了訓練集,但是沒有被泛化,我試圖降低模型的復雜度以避免過擬合,但最終在驗證集中的得分較低,平衡資料可以幫助解決這個問題或收集更多的資料,

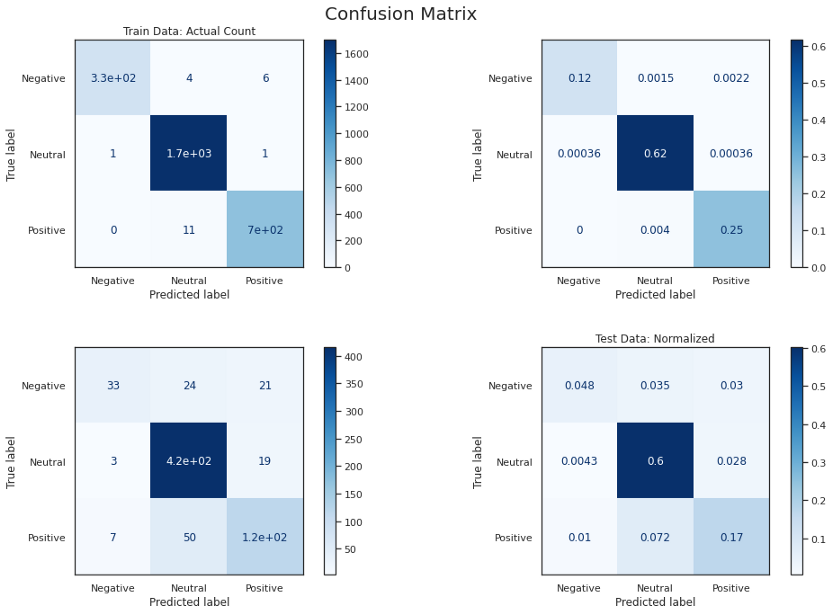
模型C產生了與前一個模型相似的結果,但改進不大,事實上,訓練資料的數量不足以從零開始訓練神經網路,需要訓練到多個epoch,這往往會過擬合,預訓練的GloVe并不能改善結果,對后一種模型的一個可能的改進是使用類似領域的大量文本(如10K、10Q財務報表)來訓練GloVe,而不是使用維基百科中預訓練過的模型,

模型D在交叉驗證和最終測驗中的準確率和f1分數均達到90%以上,它正確地將負面文本分類為84%,而正面文本正確分類為94%,這可能是由于輸入的數量,但最好仔細觀察以進一步提高性能,這表明,由于遷移學習和語言模型,預訓練模型的微調在這個小資料集上表現良好,
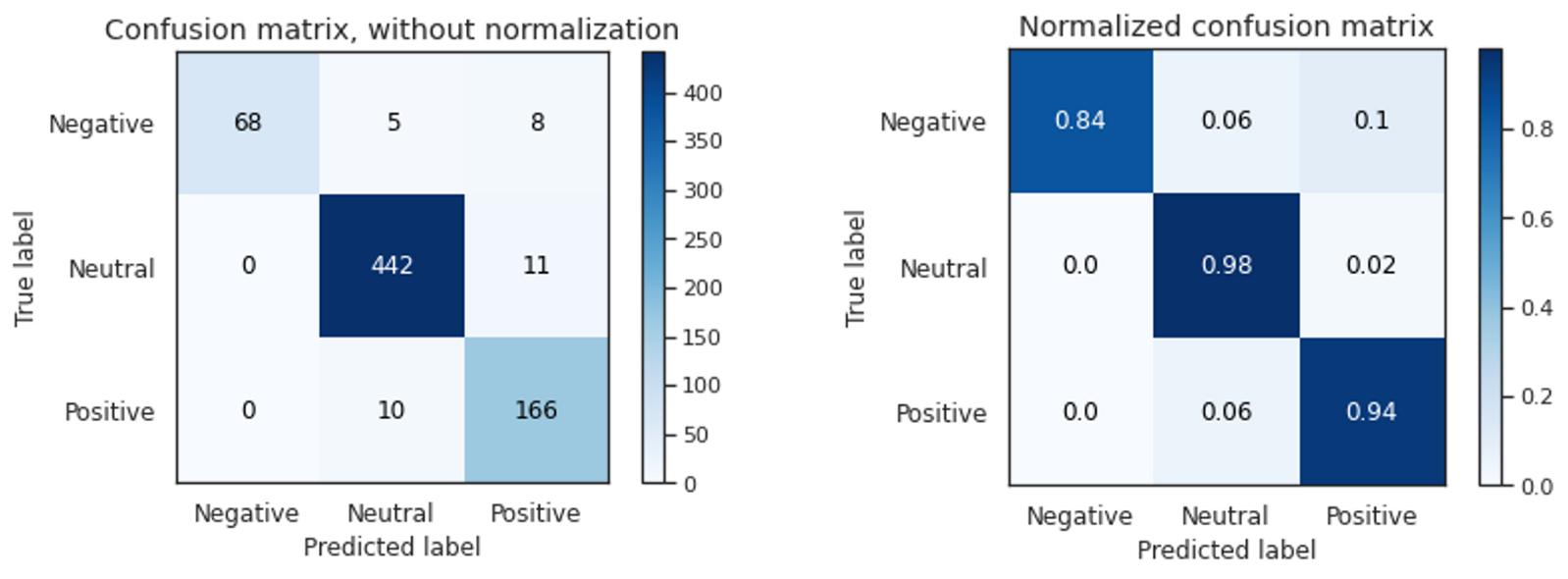
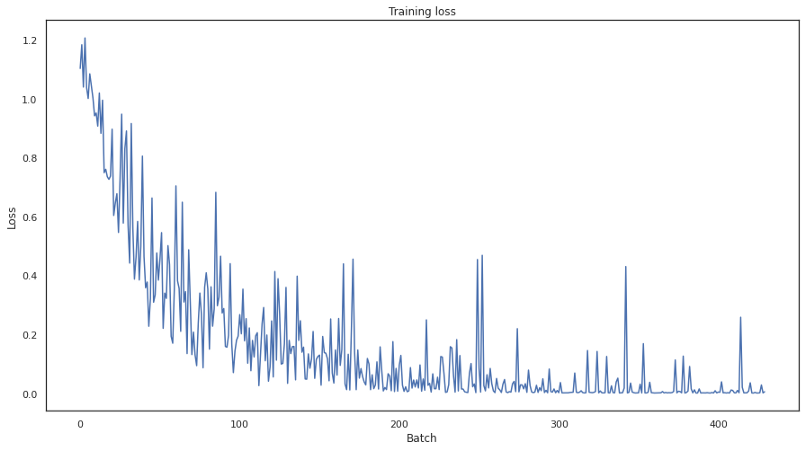

結論
這個實驗展示了基于BERT的模型在我的領域中應用的潛力,以前的模型沒有產生足夠的性能,然而,結果不是確定性的,如果調整下超引數,結果可能會有所不同,
值得注意的是,在實際應用中,獲取正確的輸入資料也相當重要,沒有高質量的資料(通常被稱為“垃圾輸入,垃圾輸出”)就不能很好地訓練模型,
我下次再談這些問題,這里使用的所有代碼都可以在git repo中找到:https://github.com/yuki678/financial-phrase-bert
原文鏈接:https://towardsdatascience.com/nlp-in-the-financial-market-sentiment-analysis-9de0dda95dc
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/173181.html
標籤:其他
上一篇:Pandas教程