def get_url(html):
url_list = []
pattern = re.compile("this.id,'(.*?)'", re.S)
ids = pattern.findall(html)
for id in ids:
url_list.append('http://www.wanfangdata.com.cn/details/detail.do?_type=conference&id=' + id)
return url_list
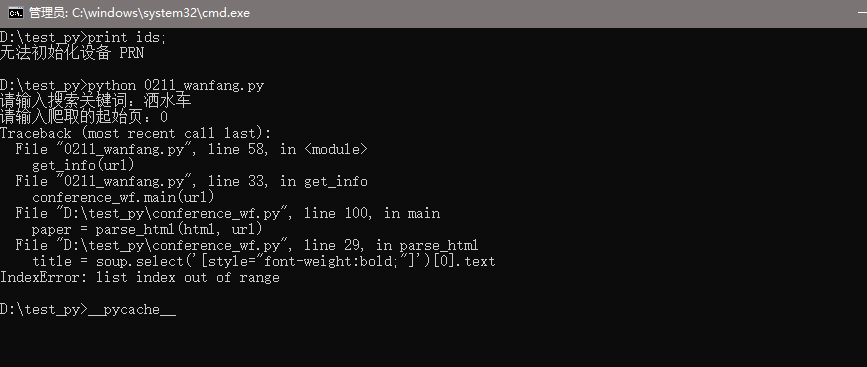
個人感覺是這一部分問題,但是不太懂,小白剛開始學習
uj5u.com熱心網友回復:
https://blog.csdn.net/weixin_42565135/article/details/104266743這是原始碼
uj5u.com熱心網友回復:
是soup獲取文本時的錯誤,所以直接取[0],肯定會報錯呀。。。uj5u.com熱心網友回復:
麻煩指導一下如何修改.我是剛開始學習.轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/173500.html
上一篇:linux – 如何配置docker的iptables規則DOCKER-USER來限制輸出?
下一篇:為什么vscode里面輸入了alert卻沒有彈出提示框(代碼都正確,但是吧alert換成console.log就可以)