作者|Soner Y?ld?r?m
編譯|VK
來源|Towards Data Science
Pandas是一個python資料分析庫,它提供了許多函式和方法來加快資料分析程序,pandas之所以如此普遍,是因為它具有強大的功能,以及他簡單的語法和靈活性,
在這篇文章中,我將舉例來解釋20個常用的pandas函式,有些是很常見的,我敢肯定你以前用過,有些對你來說可能是新的,所有函式都將為你的資料分析程序增加價值,
import numpy as np
import pandas as pd
1.query
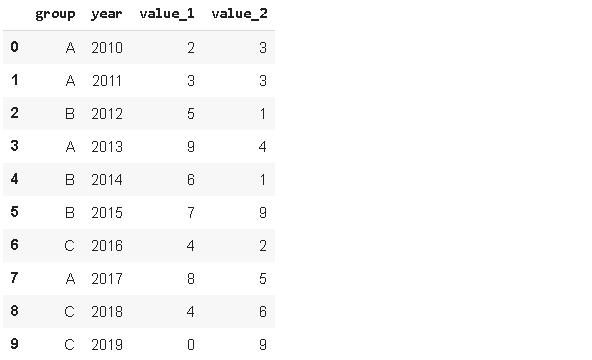
我們有時需要根據條件過濾一個資料幀,過濾資料幀的一個簡單方法是query函式,讓我們首先創建一個示例資料幀,
values_1 = np.random.randint(10, size=10)
values_2 = np.random.randint(10, size=10)
years = np.arange(2010,2020)
groups = ['A','A','B','A','B','B','C','A','C','C']
df = pd.DataFrame({'group':groups, 'year':years, 'value_1':values_1, 'value_2':values_2})
df
使用查詢函式非常簡單,只需要撰寫過濾條件,
df.query('value_1 < value_2')

2.insert
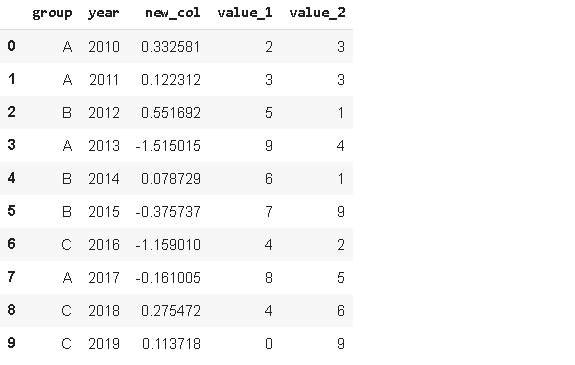
當我們想向dataframe添加一個新列時,默認情況下會在末尾添加它,但是,pandas提供了使用insert函式使得我們可以在任何位置添加新列,
我們需要通過傳遞索引作為第一個引數來指定位置,此值必須是整數,列索引從零開始,就像行索引一樣,第二個引數是列名,第三個引數是物件,這些物件可以是Series 或陣列,
#新建列
new_col = np.random.randn(10)
#在位置2插入新列
df.insert(2, 'new_col', new_col)
df
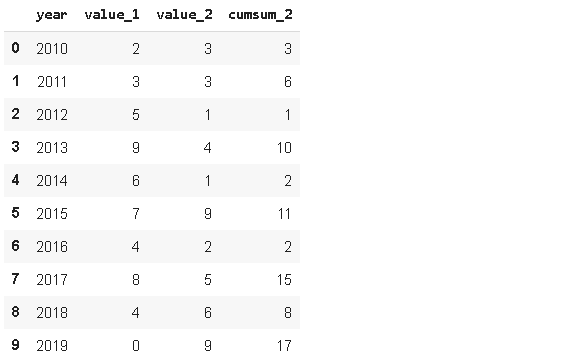
3.Cumsum
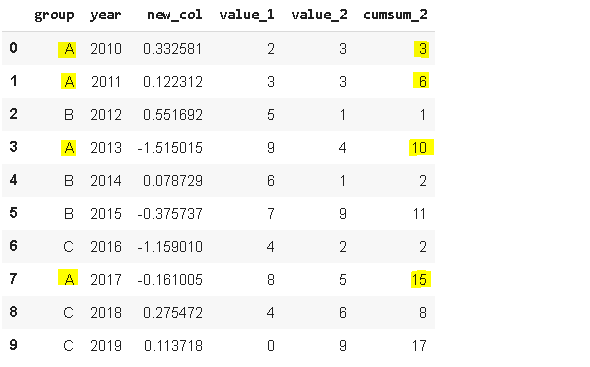
資料幀包含3個不同組的年份值,我們可能只對某些情況下的累積值感興趣,Pandas提供了一個易于使用的函式來計算累計和,即cumsum,
如果我們只應用cumsum函式,group里的(A,B,C)將被忽略,因為我們無法區分不同的組,我們可以應用groupby和cumsum函式,這樣就可以區分出不同的組,
df['cumsum_2'] = df[['value_2','group']].groupby('group').cumsum()
df
4.Sample
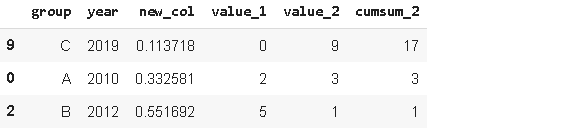
Sample方法允許你從序列或資料幀中隨機選擇值,當我們想從一個分布中選擇一個隨機樣本時,它很有用,
sample1 = df.sample(n=3)
sample1
我們用n引數指定值的數目,但我們也可以將比率傳遞給frac引數,例如,0.5將回傳一半的行,
sample2 = df.sample(frac=0.5)
sample2
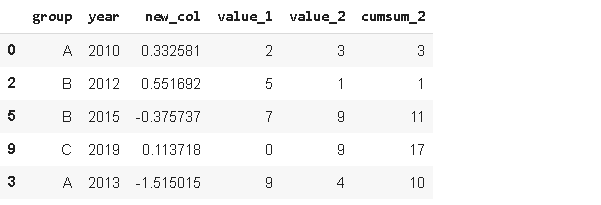
為了獲得可重復的樣本,我們可以使用隨機的狀態引數,如果將整數值傳遞給random_state,則每次運行代碼時都將生成相同的示例,
5. Where
“Where”用于根據條件替換行或列中的值,默認的替換值是NaN,但是我們也可以指定替換的值,
df['new_col'].where(df['new_col'] > 0 , 0)

“where”的作業方式是選擇符合條件的值,其余值替換為指定值,
where(df[‘new_col’]>0, 0)選擇“new_col”中大于0的所有值,其余值替換為0,因此,這里也可以視為掩碼操作,
重要的一點是,Pandas 和Numpy的“where”并不完全相同,我們可以用稍微不同的語法來達到相同的效果,DataFrame.where按原資料選擇符合條件的值,其他值將替換為指定的值,Np.where還需要指定一個新資料,以下兩行回傳相同的結果:
df['new_col'].where(df['new_col'] > 0 , 0)
np.where(df['new_col'] < 0, df['new_col'], 0)
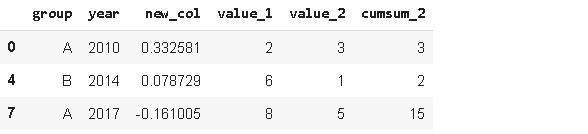
6.Isin
在處理資料幀時,我們經常使用過濾或選擇方法,Isin方法是一種先進的過濾方法,例如,我們可以根據選擇串列過濾值,
years = ['2010','2014','2017']
df[df.year.isin(years)]
7.Loc and iloc
Loc和iloc用于選擇行和列,
-
loc:按標簽選擇
-
iloc:按位置選擇
loc用于按標簽選擇資料,列的標簽是列名,行標簽要分情況,如果我們不分配任何特定的索引,pandas默認創建整數索引,iloc 按位置索引資料
使用iloc選擇前3行和前2列:

使用loc選擇前3行和前2列:

注:當使用loc時,切片得到的結果包括索引的邊界,而使用iloc則不包括這些邊界,

8.Pct_change
此函式用于計算一系列值的變化百分比,假設我們有一個包含[2,3,6]的序列,如果我們對這個序列應用pct_change,則回傳的序列將是[NaN,0.5,1.0],
從第一個元素到第二個元素增加了50%,從第二個元素到第三個元素增加了100%,Pct_change函式用于比較元素時間序列中的變化百分比,
df.value_1.pct_change()

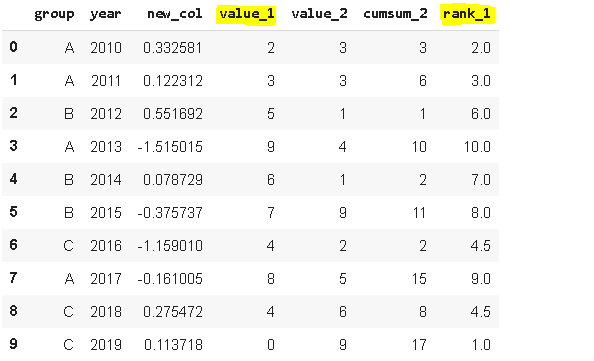
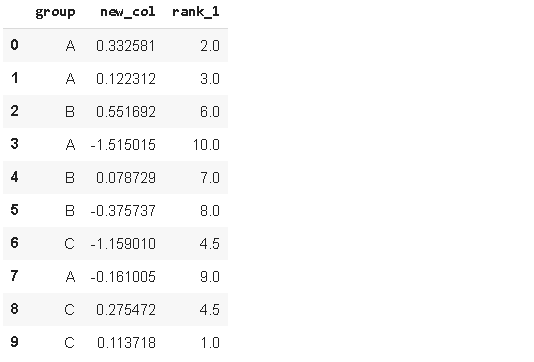
9.Rank
Rank函式為值分配序,假設我們有一個包含[1,7,5,3]的序列s,分配給這些值的序為[1,4,3,2],可以用這些序作排序操作
df['rank_1'] = df['value_1'].rank()
df
10.Melt
Melt用于將寬資料幀轉換為窄資料幀,我所說的wide是指具有大量列的資料幀,
一些資料幀的結構是連續的度量或變數用串列示,在某些情況下,將這些串列示為行可能更適合我們的任務,考慮以下資料幀:
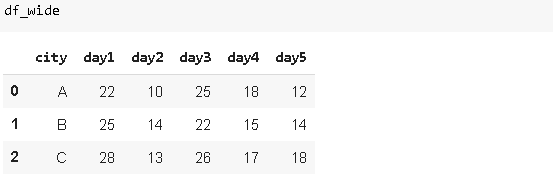
我們有三個不同的城市,在不同的日子進行測量,我們決定將這些日子表示為列中的行,還將有一列顯示測量值,我們可以通過使用Melt函式輕松實作:
df_wide.melt(id_vars=['city'])
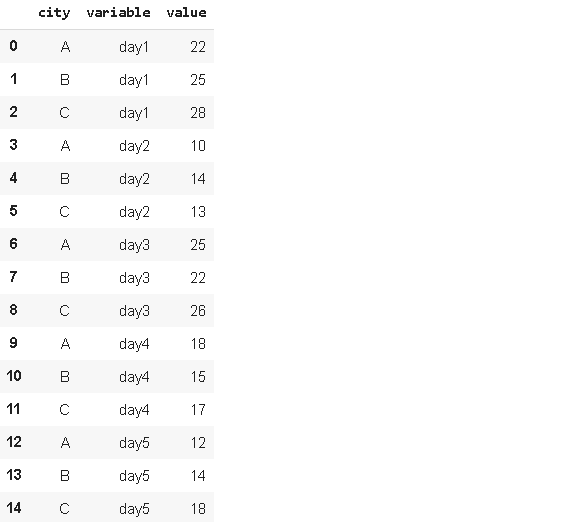
默認情況下,會給出變數和值列名,我們可以使用melt函式的var_name和value_name引數來指定新的列名,
11.Explode
假設你的資料集在一個觀測(行)中包含一個要素的多個條目,但你希望在單獨的行中分析它們,

我們想在不同的行上看到“day"1在ID為c上的測量值,用explode來完成,
df1.explode('measurement').reset_index(drop=True)
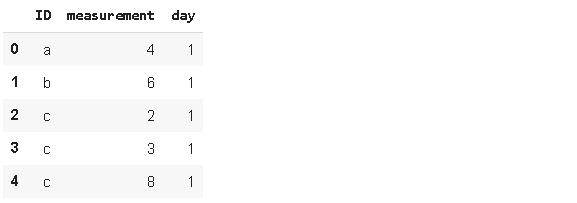
12.Nunique
Nunique統計列或行上的唯一條目數,它在分類特征中非常有用,特別是在我們事先不知道類別數量的情況下,讓我們看看我們的初始資料幀:

df.year.nunique()
10
df.group.nunique()
3
我們可以直接將nunique函式應用于dataframe,并查看每列中唯一值的數量:

如果axis引數設定為1,nunique將回傳每行中唯一值的數目,
13.lookup
它可以用于根據其他行-列對上的值在資料幀中查找值,假設我們有以下資料幀:
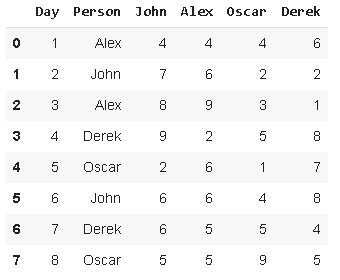
每天,我們有4個人的測量資料和一個列,其中包括這4個人的名字,
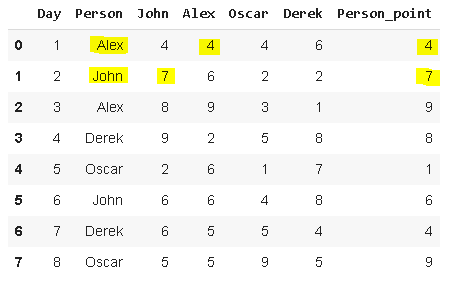
我們要創建一個新列,該列顯示“person”列中人員對應他們的度量,因此,對于第一行,新列中的值將是4(“Alex”列中的值),
df['Person_point'] = df.lookup(df.index, df['Person'])
df
14.Infer_objects
Pandas支持廣泛的資料型別,其中之一就是object,物件包含文本或混合(數字和非數字)值,
但是,如果有其他選項可用,則不建議使用物件資料型別,使用更具體的資料型別,某些操作執行得更快,例如,對于數值,我們更喜歡使用整數或浮點資料型別,
infer_objects嘗試為物件列推斷更好的資料型別,考慮以下資料幀:

df2.dtypes
A object
B object
C object
D object
dtype: object
所有的資料型別都是object,讓我們看看推斷的資料型別是什么:
df2.infer_objects().dtypes
A int64
B float64
C bool
D object
dtype: object
它可能看起來沒什么用,但在有很多列時絕對有用,
15.Memory_usage
Memory_usage回傳每行使用的記憶體量(以位元組為單位),它非常有用,尤其是當我們處理大型資料幀時,考慮下面的資料幀,其中有一百萬行,
df_large = pd.DataFrame({'A': np.random.randn(1000000),
'B': np.random.randint(100, size=1000000)})
df_large.shape
(1000000, 2)
以及每列的記憶體使用情況(以位元組為單位):
df_large.memory_usage()
Index 128
A 8000000
B 8000000
dtype: int64
整個資料幀的記憶體使用量(MB):
df_large.memory_usage().sum() / (1024**2)
15.2589111328125
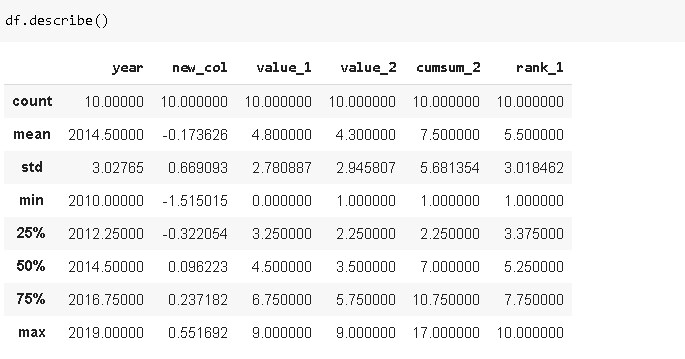
16.Describe
描述函式計算數字列的基本統計資訊,這些列包括計數、平均值、標準差、最小值和最大值、中值、第一個和第三個四分位數,因此,它提供了資料幀的統計摘要,
17.Merge
Merge()根據共享列中的值組合資料幀,考慮以下兩個資料幀,
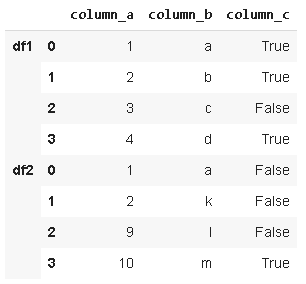
我們可以根據列中的共享值合并它們,設定合并條件的引數是“on”引數,

df1和df2是基于column_a中的公共值進行合并的,merge函式的how引數允許以不同的方式組合資料幀,“內部”、“外部”、“左側”、“右側”的可能值,
-
inner:僅在on引數指定的列中具有相同值的行(how引數的默認值)
-
outer:所有行
-
left:左資料幀中的所有行
-
right:右資料幀中的所有行
類似于sql陳述句中的join
18.Select_dtypes
Select_dtypes函式根據對資料型別設定的條件回傳資料幀列的子集,它允許使用include和exlude引數包含或排除某些資料型別,
df.select_dtypes(include='int64')
df.select_dtypes(exclude='int64')
19.replace
顧名思義,它允許替換資料幀中的值,
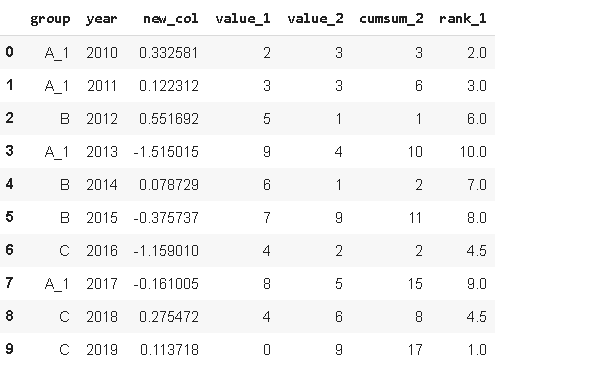
df.replace('A', 'A_1')
第一個引數是要替換的值,第二個引數是新值,
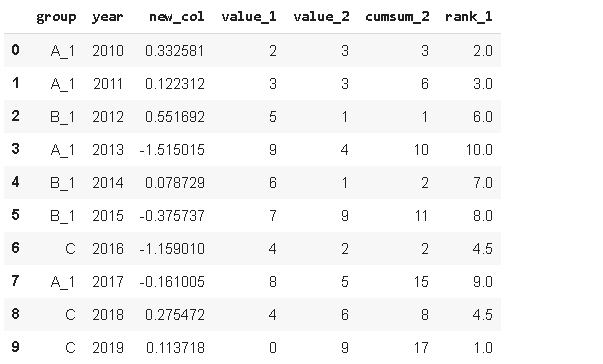
我們也可以在一個字典中同時進行多個替換,
df.replace({'A':'A_1', 'B':'B_1'})
20.Applymap
Applymap函式用于將函式應用于dataframe元素,
請注意,如果操作的向量化版本可用,那么它應該優先于applymap,例如,如果我們想將每個元素乘以一個數字,我們不需要也不應該使用applymap函式,在這種情況下,簡單的向量化操作(例如df*4)要快得多,
然而,在某些情況下,我們可能無法選擇向量化操作,例如,我們可以使用pandas dataframes的Style屬性來更改dataframe的樣式,以下函式將負值的顏色更改為紅色,
def color_negative_values(val):
color = 'red' if val < 0 else 'black'
return 'color: %s' % color
我們需要使用applymap函式將此函式應用于資料幀,
df3.style.applymap(color_negative_values)

原文鏈接:https://towardsdatascience.com/20-pandas-functions-that-will-boost-your-data-analysis-process-f5dfdb2f9e05
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/173542.html
標籤:其他
上一篇:用Python構建個性化智能鬧鐘