作者|GUEST BLOG
編譯|Flin
來源|analyticsvidhya
介紹
物件檢測是計算機視覺社區中研究最廣泛的主題之一,它已經進入了各個行業,涉及從影像安全,監視,自動車輛系統到機器檢查的用例,

當前,基于深度學習的物件檢測可以大致分為兩類:
-
兩級檢測器,例如基于區域的CNN(R-CNN)及其后續產品,
-
一級探測器,例如YOLO系列探測器和SSD
應用于錨框的常規,密集采樣(可能的物體位置)的一級檢測器可能會更快,更簡單,但由于在訓練程序中遇到極端的等級失衡,其精度已經落后于兩級探測器,
FAIR在2018年發表了一篇論文,其中他們引入了焦點損失的概念,用他們稱為RetinaNet的一級探測器來處理此類不平衡問題,
在我們深入探討焦點丟失的本質之前,讓我們首先了解這個類不平衡問題是什么以及它可能引起的問題,
目錄
-
為什么需要焦點損失
-
什么是焦點損失
-
交叉熵損失
- 交叉熵問題
- 例子
-
平衡交叉熵損失
- 平衡交叉熵問題
- 例子
-
焦點損失說明
- 例子
-
交叉熵損失 vs 焦點損失
- 容易正確分類的記錄
- 分類錯誤的記錄
- 非常容易分類的記錄
-
最后的想法
為什么需要焦點損失
兩種經典的一級檢測方法,如增強型檢測器,DPM和最新的方法(如SSD)都可以評估每個影像大約10^4 至 10^5個候選位置,但只有少數位置包含物件(即前景),而其余只是背景物件,這導致了類不平衡的問題,
這種不平衡導致兩個問題
-
訓練效率低下,因為大多數位置都容易被判斷為負類(這意味著檢測器可以輕松將其歸類為背景),這對檢測器的學習沒有幫助,
-
容易產生的負類(概率較高的檢測)占輸入的很大一部分,雖然單獨計算的梯度和損失較小,但它們可能使損耗和計算出的梯度不堪重負,并可能導致模型退化,
什么是焦點損失
簡而言之,焦點損失(Focal Loss,FL)是交叉熵損失(Cross-Entropy Loss,CE)的改進版本,它通過為難分類的或容易錯誤分類的示例(即帶有噪聲紋理的背景或部分物件的或我們感興趣的物件)分配更多的權重來處理類不平衡問題,并對簡單示例(即背景物件)降低權重,
因此,焦點損失減少了簡單示例的損失貢獻,并加強了對糾正錯誤分類的示例的重視,
因此,讓我們首先了解二進制分類的交叉熵損失,
交叉熵損失
交叉熵損失背后的思想是懲罰錯誤的預測,而不是獎勵正確的預測,
二進制分類的交叉熵損失如下:
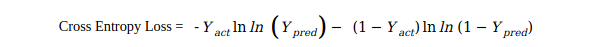
其中:
Yact = Y的實際值
Ypred = Y的預測值
為了標記方便,我們記 Yact = Y 且 Ypred = p ,
Y∈{0,1},這是正確標注
p∈[0,1],是模型對Y = 1的類別的估計概率,
為了符號上的方便,我們可以將上述方程式改寫為:
pt = {-ln(p) ,當Y=1 -ln(1-p) ,當 Y=}
CE(p,y)= CE(pt)=-ln?(pt)
交叉熵問題
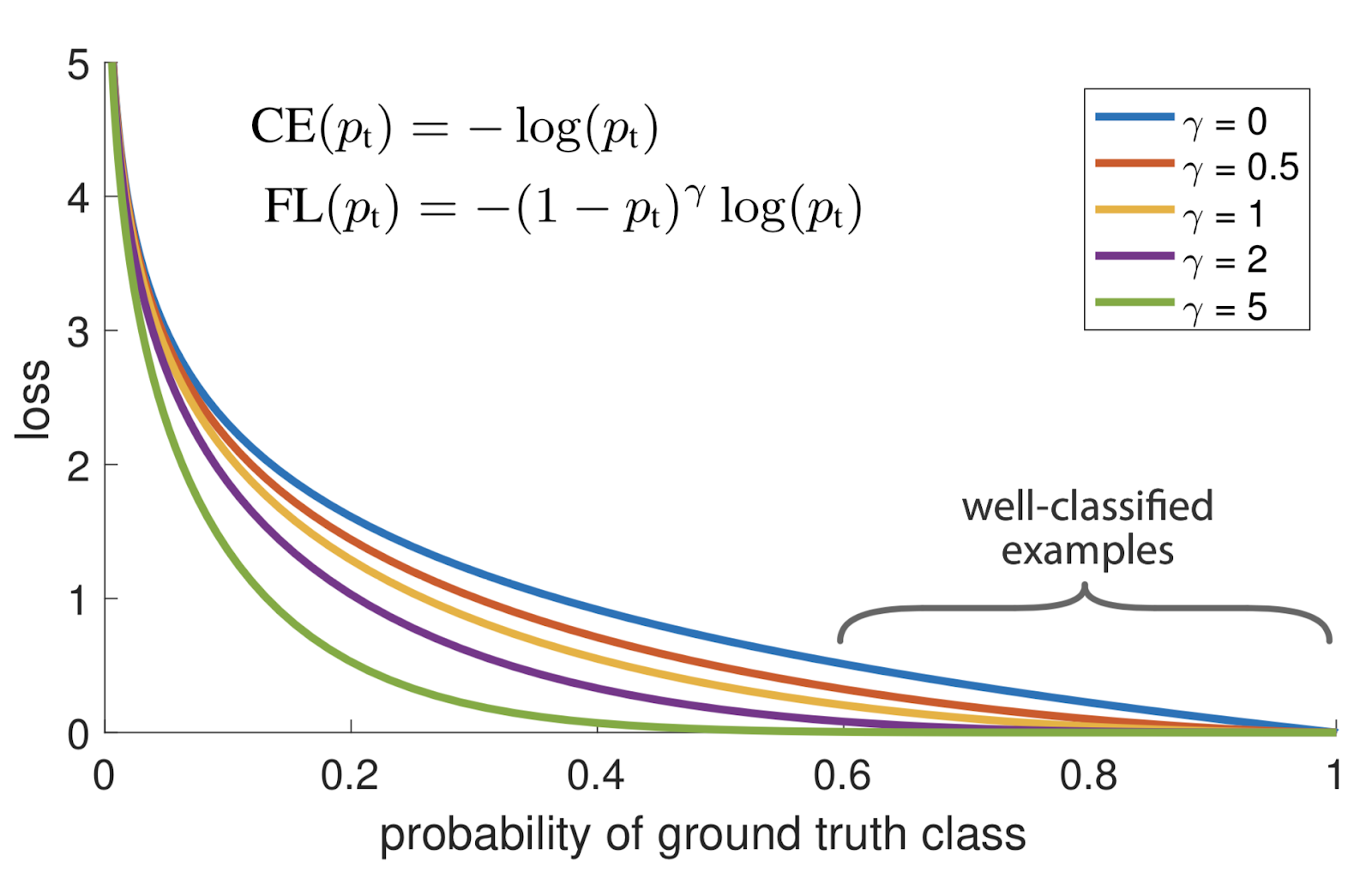
如你所見,下圖中的藍線表示當p非常接近0(當Y = 0時)或1時,容易分類的pt > 0.5的示例可能會產生不小的幅度的損失,
讓我們用下面的例子來理解它,
例子
假設,前景(我們稱其為類1)正確分類為p = 0.95 ——
CE(FG)= -ln(0.95)= 0.05
并且背景(我們稱其為類0)正確分類為p = 0.05 ——
CE(BG)=-ln(1- 0.05)= 0.05
問題是,對于類不平衡的資料集,當這些小的損失在整個影像上相加時,可能會使整體損失(總損失)不堪重負,因此,將導致模型退化,
平衡交叉熵損失
解決類別不平衡問題的一種常見方法是為類別引入權重因子∝[0,1]
為了標記方便,我們可以在損失函式中定義 ∝t 如下:
CE(pt)= -∝t ln ln(pt)
如你所見,這只是交叉熵的擴展,
平衡交叉熵的問題
我們的實驗將表明,在密集檢測器訓練程序中遇到的大類不平衡壓倒了交叉熵損失,
容易分類的負類占損耗的大部分,并主導梯度,雖然平衡了正例/負例的重要性,但它并沒有區分簡單/困難的示例,
讓我們通過一個例子來理解這一點
例子
假設,前景(我們稱其為類1)正確分類為p = 0.95 ——
CE(FG)= -0.25 * ln(0.95)= 0.0128
正確分類為p = 0.05的背景(我們稱之為類0)——
CE(BG)=-(1-0.25)* ln(1- 0.05)= 0.038
雖然可以很好地正確區分正類和負類,但仍然不能區分簡單/困難的例子,
這就是焦點損失(擴展到交叉熵)起作用的地方,
焦點損失說明
焦點損失只是交叉熵損失函式的擴展,它將降低簡單示例的權重,并將訓練重點放在困難的負樣本上,
為此,研究人員提出:
(1- pt)γ 為交叉熵損失,且可調聚焦引數γ≥0,
RetinaNet物體檢測方法使用焦點損失的α平衡變體,其中α = 0.25,γ= 2效果最佳,
因此,焦點損失可以定義為——
FL (pt) = -αt(1- pt)γ log log(pt).
對于γ∈[0,5]的幾個值,可以看到焦點損失,請參見圖1,
我們將注意到焦點損失的以下特性:
- 當示例分類錯誤并且pt小時,調制因數接近1,并且損失不受影響,
- 當 pt →1 時,該因子變為0,并且對分類良好的示例的損失進行了權衡,
- 聚焦引數γ平滑地調整了簡單示例的權重,
隨著增加,調制因數的作用同樣增加,(經過大量實驗和試驗,研究人員發現γ = 2效果最佳)
注意:當γ= 0時,FL等效于CE,參考圖中藍色曲線,
直觀上,調制因數減少了簡單示例的損耗貢獻,并擴展了示例接收低損耗的范圍,
讓我們通過一個例子來了解上述焦點損失的特性,
例子
- 當記錄(前景或背景)被正確分類時,
-
前景正確分類,預測概率p=0.99,背景正確分類,預測概率p=0.01,
pt = {0.99,當Yact = 1 時 1-0.01,當Y act = 0時}調制因數(FG)=(1-0.99)2 = 0.0001
調制因數(BG)=(1-(1-0.01))2 = 0.0001,如你所見,調制因數接近于0,因此損耗將被權重降低, -
前景被錯誤分類,預測概率p = 0.01,背景物件被錯誤分類,預測概率p = 0.99,
pt = {0.01,當Yact = 1 時 1-0.99,當Y act = 0時}調制因數(FG)=(1-0.01)2 = 0.9801
調制因數(BG)=(1-(1-0.99))2 = 0.9801如你所見,調制因數接近于1,因此損耗不受影響,
現在,讓我們使用一些示例比較交叉熵和焦點損失,并查看焦點損失在訓練程序中的影響,
交叉熵損失 vs 焦點損失
讓我們通過考慮以下幾種情況來進行比較,
容易正確分類的記錄
假設前景正確分類的預測概率為p = 0.95,背景正確分類的背景為預測概率p = 0.05,
pt = {0.95, 當 Yact=1時 1-0.05 ,當 Yact = 0時} CE(FG)= -ln (0.95) = 0.0512932943875505
讓我們考慮在∝ = 0.25和γ= 2時的焦點損失,
FL(FG)= -0.25 * (1-0.95)2 * ln (0.95) = 3.2058308992219E-5
FL(BG)= -0.75 * (1-(1-0.05))2 * ln (1-0.05) = 9.61E-5
分類錯誤的記錄
假設預測概率p=0.05的前景被分類為預測概率p=0.05的背景物件,
pt = {0.95,當Y act = 1 1-0.05時,當Y act = 0時}
CE(FG)= -ln(0.05)= 2.995732273553991
CE(BG)= -ln(1-0.95)= 2.995732273553992
讓我們考慮相同的場景,即∞=0.25和γ=2,
FL(FG)= -0.25 * (1-0.05)2 * ln(0.05)= 0.675912094220619
FL(BG)= -0.75 * (1-(1-0.95))2 * ln(1-0.95)= 2.027736282661858
非常容易分類的記錄
假設對預測概率p=0.01的背景物件,用預測概率p=0.99對前景進行分類,
pt = {0.99, 當 Yact=1時 1-0.01 ,當 Yact = 0時}CE(FG)= -ln (0.99) = 0.0100503358535014
CE(BG)= -ln(1-0.01)= 0.0100503358535014
讓我們考慮相同的場景,即∞=0.25和γ=2,
FL(FG)= -0.25 * (1-0.01)2 * ln(0.99)= 2.51 * 10 -7
FL(BG)= -0.75 * (1-(1-0.01))2 * ln(1-0.01) = 7.5377518901261E-7
最后的想法
方案1:0.05129 / 3.2058 * 10 -7 =小1600倍
方案2:2.3 / 0.667 =小4.5倍
方案3:0.01 / 0.00000025 =小40,000倍,
這三個案例清楚地說明了焦點損失如何減小分類良好的記錄的權重,另一方面又為錯誤分類或較難分類的記錄賦予較大的權重,
經過大量的試驗和實驗,研究人員發現 ∝ = 0.25和 γ = 2 效果最佳,
尾注
在物件檢測中,我們經歷了從交叉熵損失到焦點損失的整個進化程序,我已經盡力解釋了目標檢測中的焦點損失,
感謝閱讀!
參考
-
https://arxiv.org/ftp/arxiv/papers/2006/2006.01413.pdf
-
https://medium.com/@14prakash/the-intuition-behind-retinanet-eb636755607d
-
https://developers.arcgis.com/python / guide / how-retinanet-works /
原文鏈接:https://www.analyticsvidhya.com/blog/2020/08/a-beginners-guide-to-focal-loss-in-object-detection/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/176535.html
標籤:其他
上一篇:力扣初級演算法(四)【樹】