1. 實作Redis集群
1.1 為什么需要搭建集群
redis分片特點:
1.可以實作Redis記憶體資料的擴容.
2.redis分片本身沒有高可用效果的.如果宕機將直接影響用戶的使用.
redis哨兵特點:
1.Redis哨兵可以實作Redis節點的高可用.但是哨兵本身沒有實作高可用機制.(最好不要引入第三方)
2.Redis哨兵有主從的結構 實作了記憶體資料的備份. 但是沒有實作記憶體擴容的效果.
升級:
需要Redis內容擴容同時需要Redis高可用性所以應該使用Redis集群.
1.2 關于Redis集群搭建問題說明
-
關閉所有的redis服務器
sh stop.sh -
洗掉多余的檔案
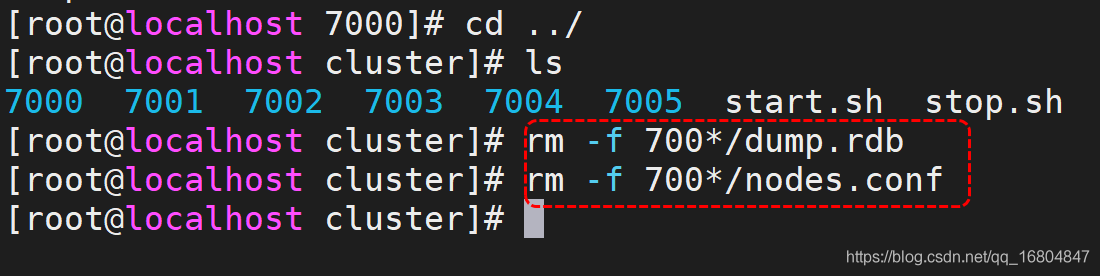
3.重啟redis服務器 執行掛載命令
redis-cli --cluster create --cluster-replicas 1 192.168.126.129:7000 192.168.126.129:7001 192.168.126.129:7002 192.168.126.129:7003 192.168.126.129:7004 192.168.126.129:7005
1.3 Redis入門案例
@Test
public void testCluster(){
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.126.129", 7000));
nodes.add(new HostAndPort("192.168.126.129", 7001));
nodes.add(new HostAndPort("192.168.126.129", 7002));
nodes.add(new HostAndPort("192.168.126.129", 7003));
nodes.add(new HostAndPort("192.168.126.129", 7004));
nodes.add(new HostAndPort("192.168.126.129", 7005));
JedisCluster jedisCluster = new JedisCluster(nodes);
jedisCluster.set("cluster", "集群的測驗!!!!");
System.out.println(jedisCluster.get("cluster"));
}
1.4 關于選舉機制-腦裂現象
說明: 當集群進行選舉時,如果連續3次都出現了平票的結果的則可能出現腦裂的現象.
問題: 出現腦裂現象的概率是多少??? 1/8
數學建模:
拋銀幣連續3次出現平票的概念是多少? 1/8=12.5%
第一次: 正正 正反 反正 反反 1/2
第二次: 正正 正反 反正 反反 1/2
第三次: 正正 正反 反正 反反 1/2
預防: 增加主節點的數量可以有效的降低腦裂現象的發生.
1.5 關于集群面試題
問題1: Redis集群中最多存盤16384個資料???
錯的 磁區只負責資料的劃分 資料的存盤由記憶體決定.
crc16(key1)%16384 = 1000
crc16(key2)%16384 = 1000
問題2: Redis集群中最多有多少臺主機?? 16384主機.
一臺主機占用一個槽道
1.6 SpringBoot整合Redis集群
1.6.1 編輯pro組態檔
# 配置redis單臺服務器
redis.host=192.168.126.129
redis.port=6379
# 配置redis分片機制
redis.nodes=192.168.126.129:6379,192.168.126.129:6380,192.168.126.129:6381
# 配置哨兵節點
redis.sentinel=192.168.126.129:26379
# 配置redis集群
redis.clusters=192.168.126.129:7000,192.168.126.129:7001,192.168.126.129:7002,192.168.126.129:7003,192.168.126.129:7004,192.168.126.129:7005
1.6.2 編輯RedisConfig配置類
@Configuration
@PropertySource("classpath:/properties/redis.properties")
public class JedisConfig {
@Value("${redis.clusters}")
private String clusters;
@Bean
public JedisCluster jedisCluster(){
Set<HostAndPort> nodes = new HashSet<>();
String[] nodesArray = clusters.split(",");
for (String node : nodesArray){
String host = node.split(":")[0];
int port = Integer.parseInt(node.split(":")[1]);
HostAndPort hostAndPort = new HostAndPort(host,port);
nodes.add(hostAndPort);
}
return new JedisCluster(nodes);
}
}
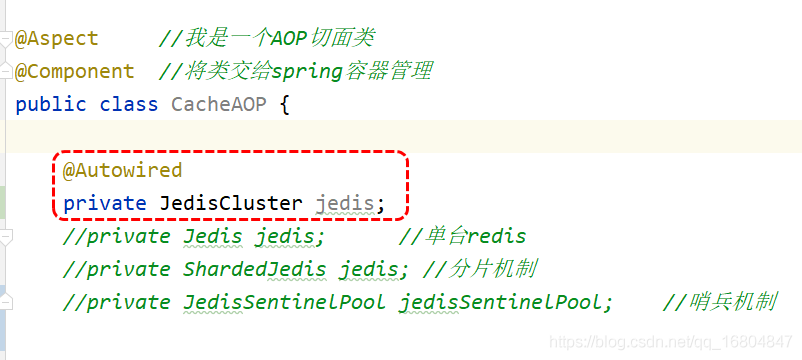
1.6.3 編輯CacheAOP
1.7 關于京淘專案后臺說明
知識點概括:
1.框架加強階段
1.1SpringBoot 各個組態檔的說明 pom.xml配置 常用注解 springboot啟動執行的流程
1.2 關于SpringBoot常見用法 屬性賦值 @Value , 開發環境優化 ,組態檔引入 ,整合Mybatis , 整合MybatisPlus ,整合web資源(JSP)
1.3京淘后臺專案搭建
1.3.1分布式思想 按照模塊/ 按照層級拆分
1.3.2 聚合工程創建的思路 父級專案 統一管理jar包 ,工具API專案, 業務功能系統
1.4 UI工具 前端與后端進行資料互動時 如果想要展現特定的格式結構,則必須按照要求回傳VO物件.
1.5 JSON結構形式 1.Object型別 2.Array型別 3. 復雜型別(可以進行無限層級的嵌套)
1.6 后臺商品/商品分類的CURD操作.
1.7 引入富文本編輯器 /實作檔案上傳業務.
1.8 反向代理/正向代理
1.9 NGINX 實作圖片回顯, NGINX安裝/命令/行程項說明/域名的代理/負載均衡機制/相關屬性說明
1.10 windows tomcat服務器集群部署.
2.Linux學習
2.1 什么是VM虛擬機. 網路配置說明 橋接/NAT模式
2.2 介紹Linux發展, 介紹Linux基本命令 安裝Linux JDK tomcatLinux部署. Linux安裝Mysql資料
2.3 Linux安裝Nginx服務器. 整個專案Linux部署.
3.專案真實部署
3.1 實作資料的讀寫分離/負載均衡/資料庫高可用 mycat
3.2 Redis 命令/redis單臺操作/redis分片/redis哨兵/redis集群/
3.3 AOP相關知識.
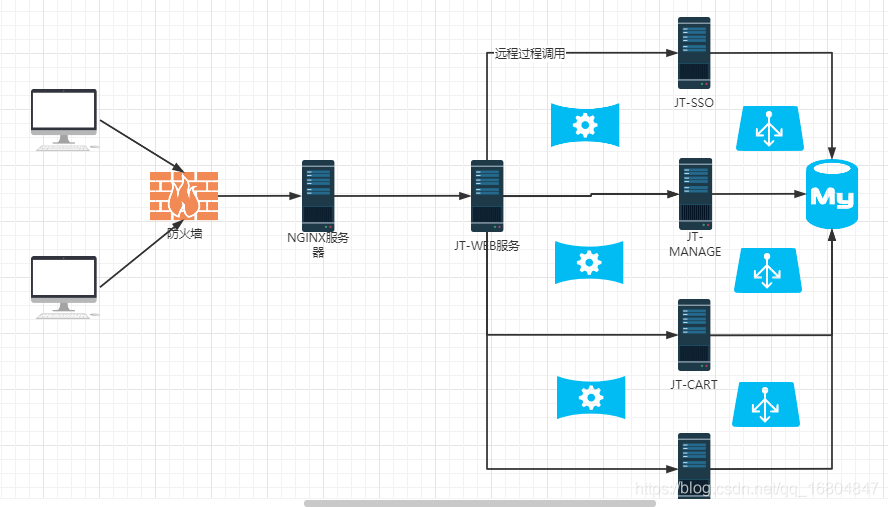
2. 京淘專案前臺搭建
2.1 京淘專案架構圖
2.2 京淘前臺專案構建
2.2.1 創建專案
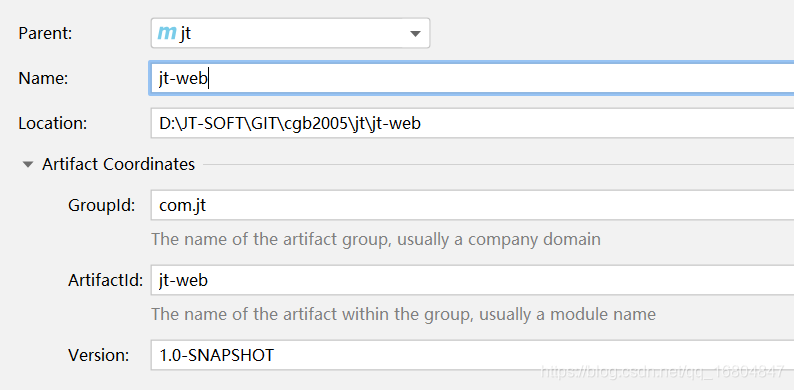
2.2.2 添加繼承/依賴/插件
說明:編輯jt-web的pom.xml組態檔 其中打包方式注意改為war 其次 添加繼承/依賴/插件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<artifactId>jt-web</artifactId>
<packaging>war</packaging>
<parent>
<artifactId>jt</artifactId>
<groupId>com.jt</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<!--2.添加依賴資訊-->
<dependencies>
<!--依賴實質依賴的是jar包檔案-->
<dependency>
<groupId>com.jt</groupId>
<artifactId>jt-common</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
<!--3.添加插件-->
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
將課前資料中的檔案匯入.如圖所示.
2.2.3 關于web專案資料源報錯的說明
SpringBoot程式啟動時需要加載資料庫但是沒有資料源的配置資訊.導致報錯.
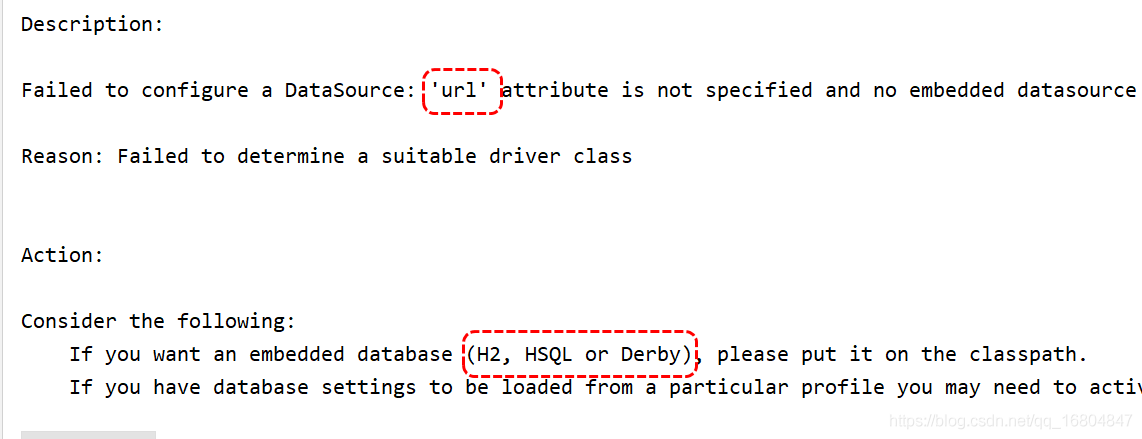
如何解決: 添加排除資料源啟動.
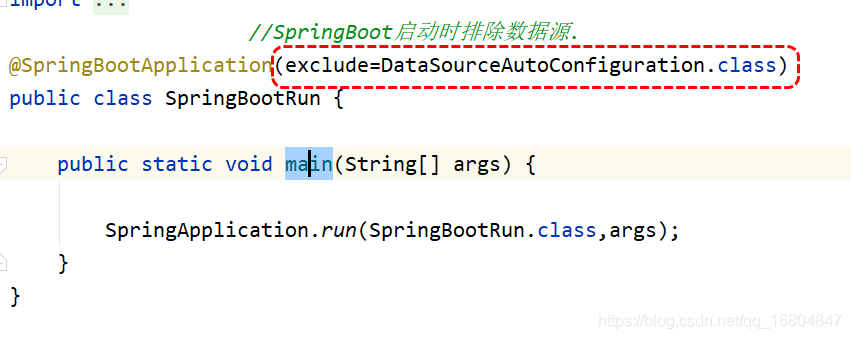
2.2.4 修改SpringBoot啟動項
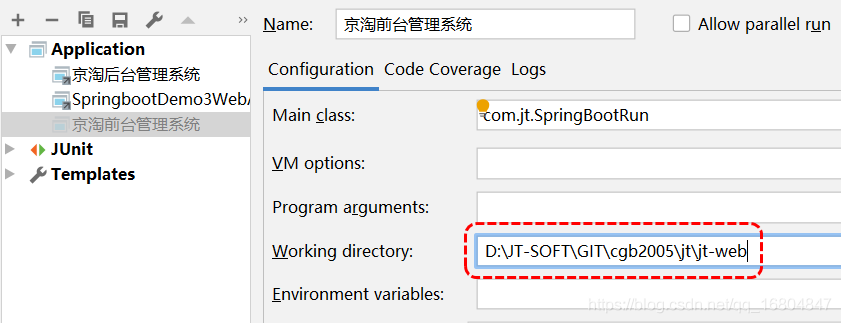
2.2.5 啟動效果測驗
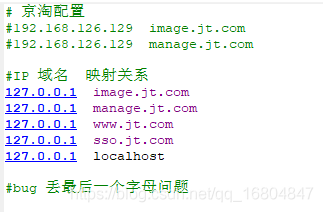
2.2.6 編輯Nginx組態檔
說明: 要求用戶通過http://www.jt.com 訪問localhost:8092服務器.
修改nginx服務器之后重啟即可.
#配置jt-web服務器
server {
listen 80;
server_name www.jt.com;
location / {
proxy_pass http://127.0.0.1:8092;
}
}
編輯hosts檔案.
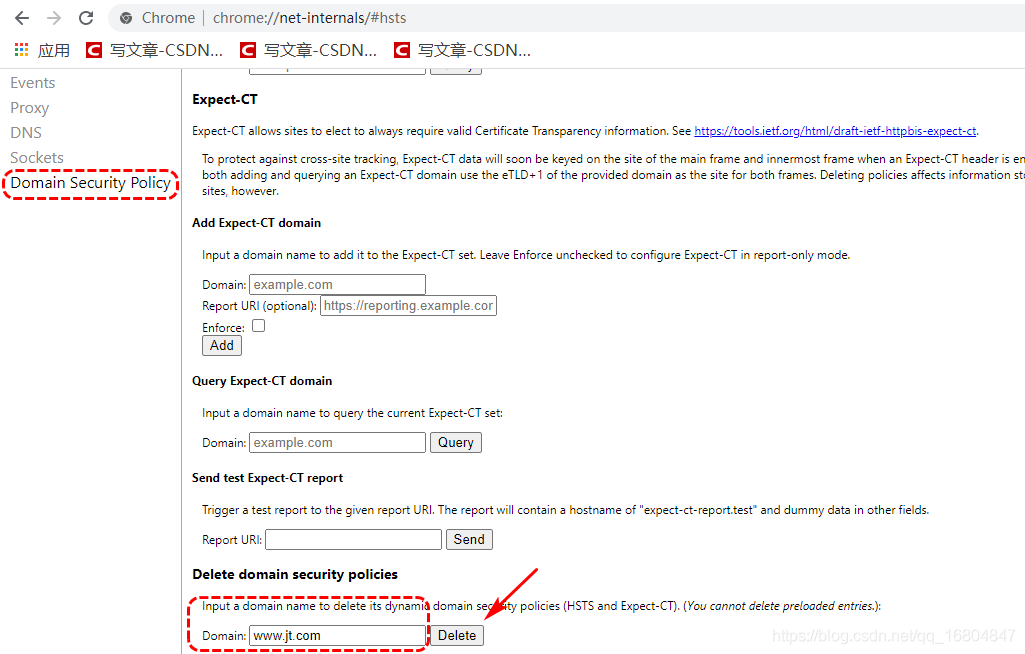
2.2.7 關于谷歌瀏覽器https禁用問題
谷歌瀏覽器鍵入: chrome://net-internals/#hsts:
修改完成之后,重啟瀏覽器即可.
2.3 關于偽靜態的說明
2.3.1 業務說明
問題1: 京東的商品有很多,如果都采用靜態頁面的形式為用戶展現資料,如果有100萬的商品,那么就需要100萬個商品的xxx.html頁面. 問:京東是這么做的嗎???
實作規則:
應該動態獲取商品的ID號.之后查詢資料庫,然后調整指定的頁面,將資料進行填充即可.
問題2: 為什么京東采用.html結尾的請求展現商品呢?
答案: 采用.html結尾的頁面,更加容易被搜索引擎收錄,提高網站的曝光率.
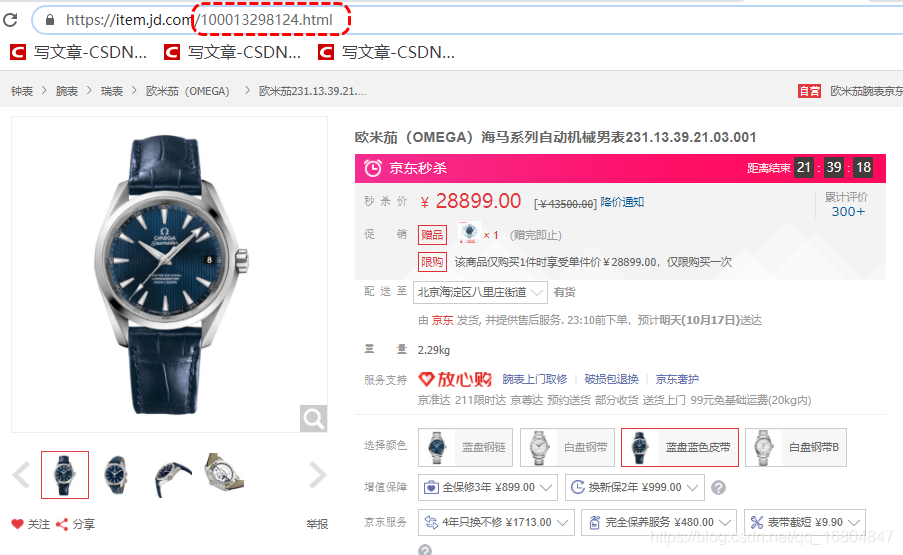
2.3.2 搜索引擎作業原理
作業原理核心: 倒排索引機制. 根據關鍵字檢索文章的位置.
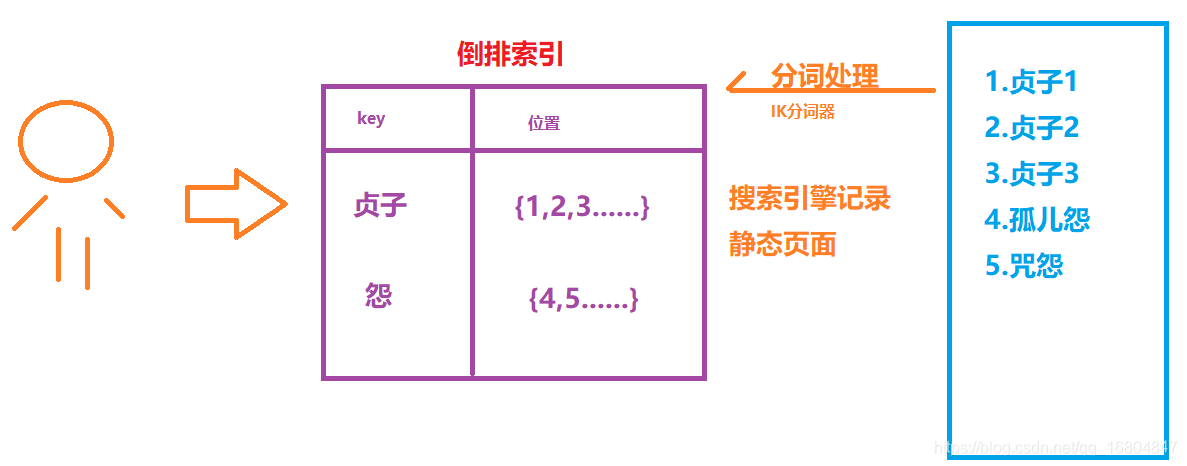
2.3.3 偽靜態思想
偽靜態是相對真實靜態來講的,通常我們為了增強搜索引擎的友好面,都將文章內容生成靜態頁面,但是有的朋友為了實時的顯示一些資訊,或者還想運用動態腳本解決一些問題,不能用靜態的方式來展示網站內容,但是這就損失了對搜索引擎的友好面,怎么樣在兩者之間找個中間方法呢,這就產生了偽靜態技術,偽靜態技術是指展示出來的是以html一類的靜態頁面形式,但其實是用ASP一類的動態腳本來處理的,
總結: 以.html結尾的動態頁面.增強搜索引擎的友好性.
2.3.4 偽靜態實作
說明:如果需要實作偽靜態,則需要攔截.html結尾的請求即可. 否則程式認為你訪問的是具體的靜態資源如圖所示
配置類介紹
@Configuration //web.xml組態檔
public class MvcConfigurer implements WebMvcConfigurer{
//開啟匹配后綴型配置
@Override
public void configurePathMatch(PathMatchConfigurer configurer) {
//開啟后綴型別的匹配. xxxx.html
configurer.setUseSuffixPatternMatch(true);
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/177351.html
標籤:其他