作者|Ajit Rajasekharan
編譯|VK
來源|Towards Data Science

從檔案中獲取的句子片段的嵌入可以作為該檔案的提取摘要方面,并可能加速搜索,特別是當用戶輸入是一個句子片段時,這些片段嵌入不僅比傳統的文本匹配系統產生更高質量的結果,也是問題的內在驅動的搜索方法,現代向量化表示挑戰創建有效的檔案嵌入,捕捉所有型別的檔案,使其通過使用嵌入在檔案級別進行搜索,
例如“蝙蝠是冠狀病毒的來源”、“穿山甲中的冠狀病毒”,由介詞、形容詞等連接一個或多個名詞短語的短序列,這些突出顯示的連接詞在很大程度上被傳統搜索系統忽略,它們不僅可以在捕獲用戶意圖方面發揮關鍵作用(例如,“蝙蝠中的冠狀病毒”不同于“蝙蝠是冠狀病毒的來源”或“蝙蝠中不存在冠狀病毒”)的搜索意圖,但是,保留它們的句子片段也可以是有價值的候選索引,可以用作檔案的摘要提取方面(子摘要),通過將這些句子片段嵌入到適當的嵌入空間(如BERT)中,我們可以使用搜索輸入片段作為對該嵌入空間的探測,以發現相關檔案,
需要改進使用片段的搜索
找到一個有文獻證據支持的綜合答案來回答“COVID-19來源什么動物?”或者“冠狀病毒與之結合的受體”,即使是在最近發布的covid19資料集這樣的小資料集上(約500 MB的語料庫大小,約13k檔案,8500多萬單詞,文本中約有100萬個不同的單詞),也是一個挑戰,
傳統的檔案搜索方法對于通過使用一個或多個名詞短語搜索從幾個檔案中獲得答案的典型用例非常有效,傳統的檔案搜索方法也滿足以下對單詞和短語的用戶體驗約束:
我們看到的(結果)是我們輸入的(搜索的)
例如,當我們搜索單詞和短語(連續的單詞序列,如New York,Rio De Janeiro)時,結果通常包含我們輸入的詞匯或它們的同義詞(例如,COVID-19搜索產生Sars-COV-2或新型冠狀病毒等結果),
然而,隨著搜索輸入的單詞數量的增加,搜索結果的質量往往會下降,特別是名詞短語之間使用連接詞的情況下,即使搜索引擎在結果中會突出顯示術語,但是這種結果質量的下降是還是顯而易見,
例如,在下圖中,當前搜索引擎選擇性地突出顯示了“蝙蝠作為冠狀病毒的來源”(“bats as a source of coronavirus”)中的名詞,有時甚至沒有遵循輸入序列中這些單詞的順序, 盡管檔案相關性排序通常可以在很大程度上緩解這種情況,但我們仍然需要檢查每個檔案的摘要,因為檔案不滿足我們的搜索意圖,
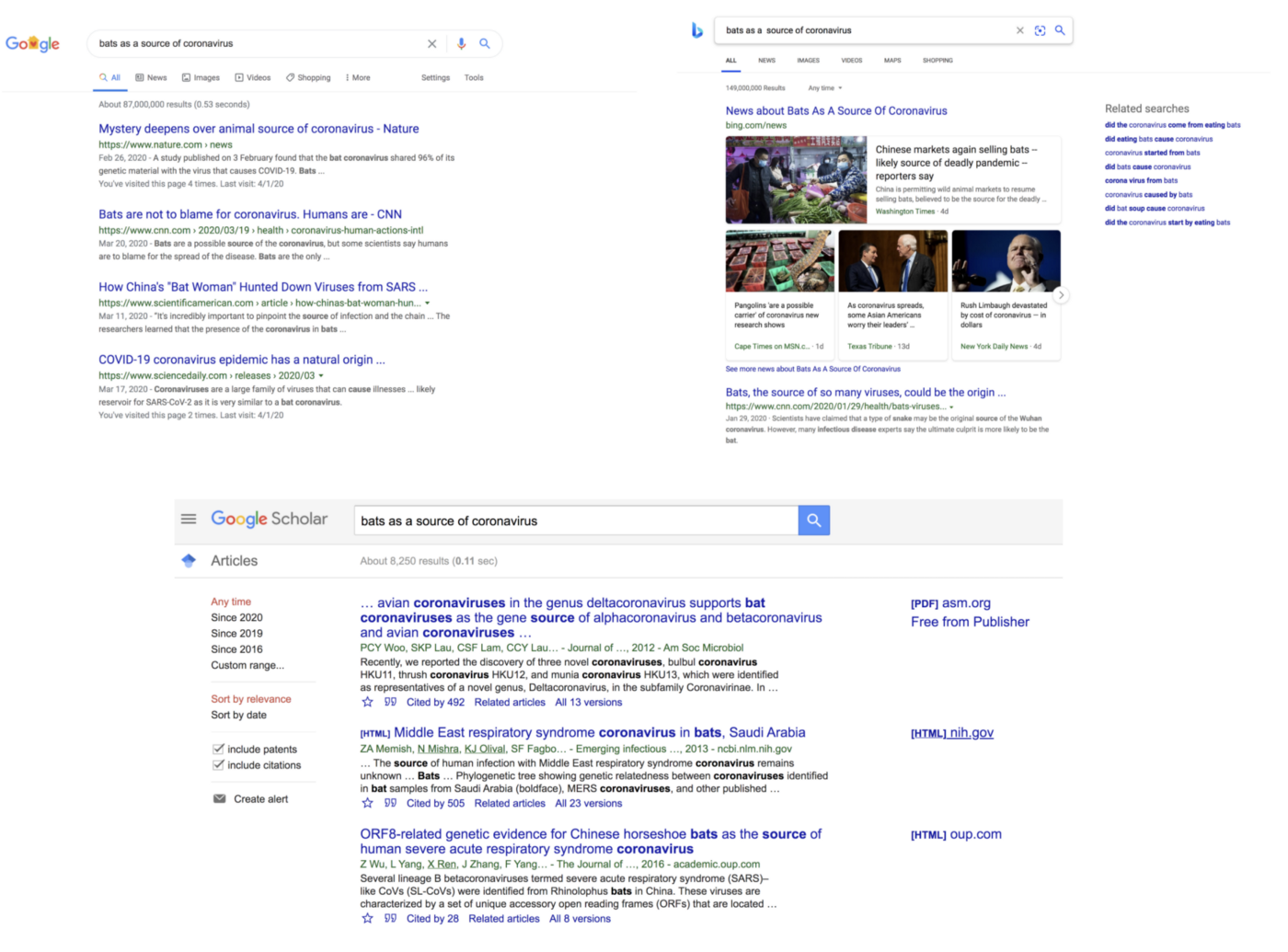
本文所述的檔案搜索方法除產生更相關的結果外,還可以減少搜索系統中存在的這種認知負擔,尤其是在搜索句子片段時, 作為說明,我們在上面的現有搜索系統中使用的相同查詢可以產生如下所示形式的結果(該界面僅是用于說明搜索方法的示意圖), 值得注意的是,以下示意圖中的要點是,摘要是檔案中的實際匹配項(括號中的數字是包含片段的檔案數以及帶有輸入搜索片段的片段的余弦距離),而不是在傳統搜索系統中顯示的建議查詢或相關搜索查詢, 這些摘要方面為結果空間提供了全景視圖,減少了無用的檔案導航并加快了對感興趣檔案的聚合,

輸入片段可以是完整或部分的句子,對其組成或樣式沒有限制, 例如,與上面的肯定性查詢相反,它們可能是疑問詞,我們可以通過搜索“冠狀病毒結合的受體是什么?”來找到冠狀病毒結合的蛋白受體

上面的搜索系統之間的比較僅用于說明檔案發現的基本方法之間的差異, 否則,鑒于語料庫大小的數量級差異,這將是不公平的比較,因為我們一定會在一個微小的語料庫中獲得更多相關的結果,
嵌入在檔案搜索中的作用
由于向量化表示相對于傳統的純符號搜索方法的優勢,它已經成為任何搜索形式不可或缺的一部分,現代搜索系統越來越多地利用它們來補充符號搜索方法,如果我們將檔案搜索廣泛地視為檔案空間的廣度優先和深度優先遍歷的組合,那么這兩種形式的遍歷需要具有特定于這些遍歷的特征的嵌入,例如,我們可以從引起冠狀病毒的動物開始,然后深入到蝙蝠,然后再擴展到爬行動物等,
-
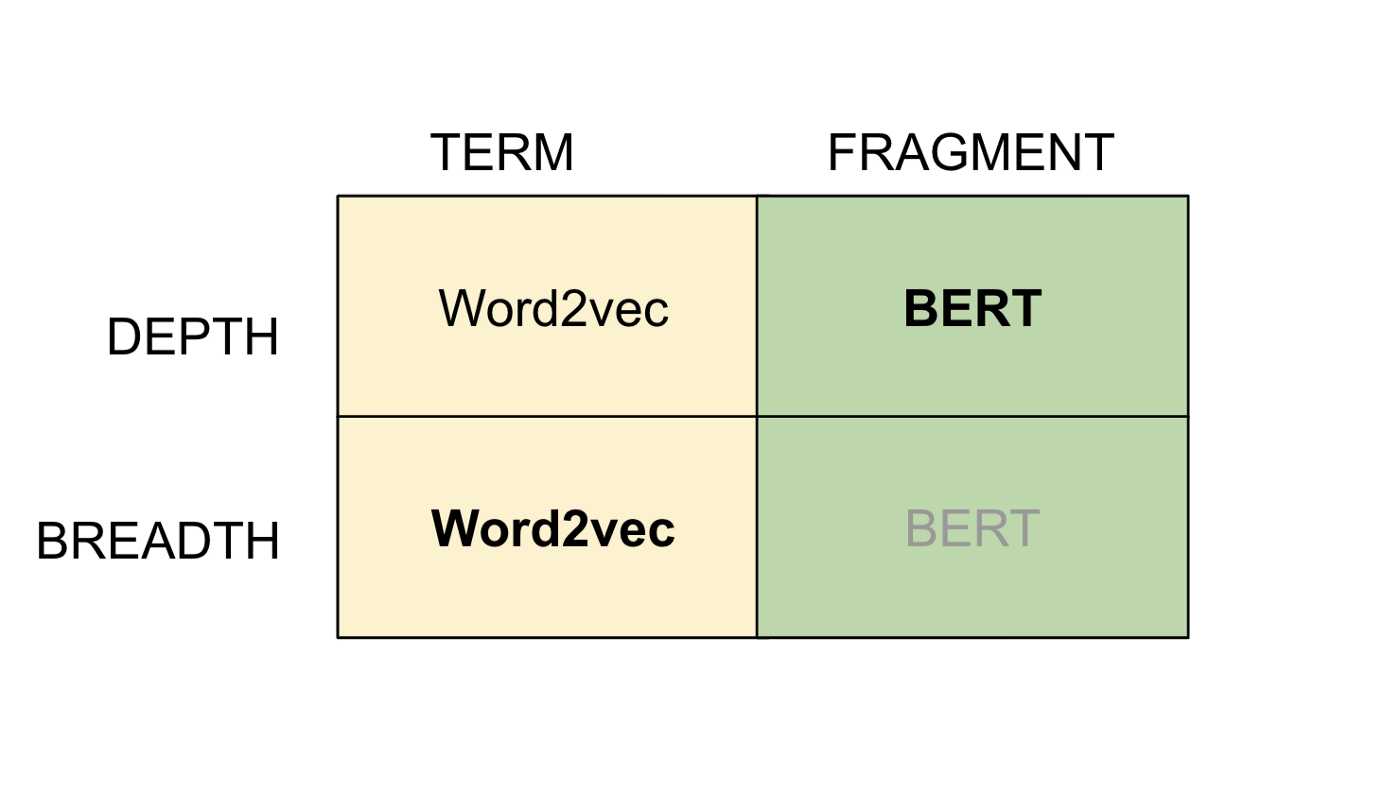
檔案的向量化表示——從Word2vec和BERT的嵌入空間中提取的單詞、短語或句子片段都具有獨特的互補屬性,這些屬性對于執行廣泛而深入的搜索非常有用,具體地說,詞的Word2vec嵌入(詞指的是詞和短語,如蝙蝠、果子貍等)是廣度優先搜索的有效方法,基于物體的聚類應用于結果,搜索“蝙蝠”或“麝香貓”這個詞,會得到其他動物,如穿山甲、駱駝等,
-
BERT嵌入的句子片段(“穿山甲中的冠狀病毒”,“蝙蝠作為冠狀病毒的來源”等)是有用的,可以發現片段變體,很大程度上保留原始名詞,這取決于它們在語料庫中的存在,例如,“蝙蝠作為冠狀病毒的來源”將產生片段的變異,如“蝙蝠冠狀病毒”、“由蝙蝠產生的冠狀病毒”等,
-
這些嵌入雖然在很大程度上是互補的,但也有重疊的特性,word2vec嵌入可以產生深度優先的結果,BERT嵌入在統計結果的分布尾端產生廣度優先結果,,例如,使用word2vec嵌入搜索蝙蝠,除了可以搜索到駱駝、穿山甲等其他動物之外,還可以搜索到蝙蝠物種(如果蝠、狐蝠、飛狐、翼龍等),使用BERT對“孔雀冠狀病毒”進行片段搜索,得到“貓冠狀病毒病”、“獵豹冠狀病毒”,盡管結果主要是鳥類冠狀病毒,
-
BERT模型允許搜索輸入(術語或片段)不在詞匯表中,從而使任何用戶輸入都可以找到相關檔案,
這種方法是如何作業的?
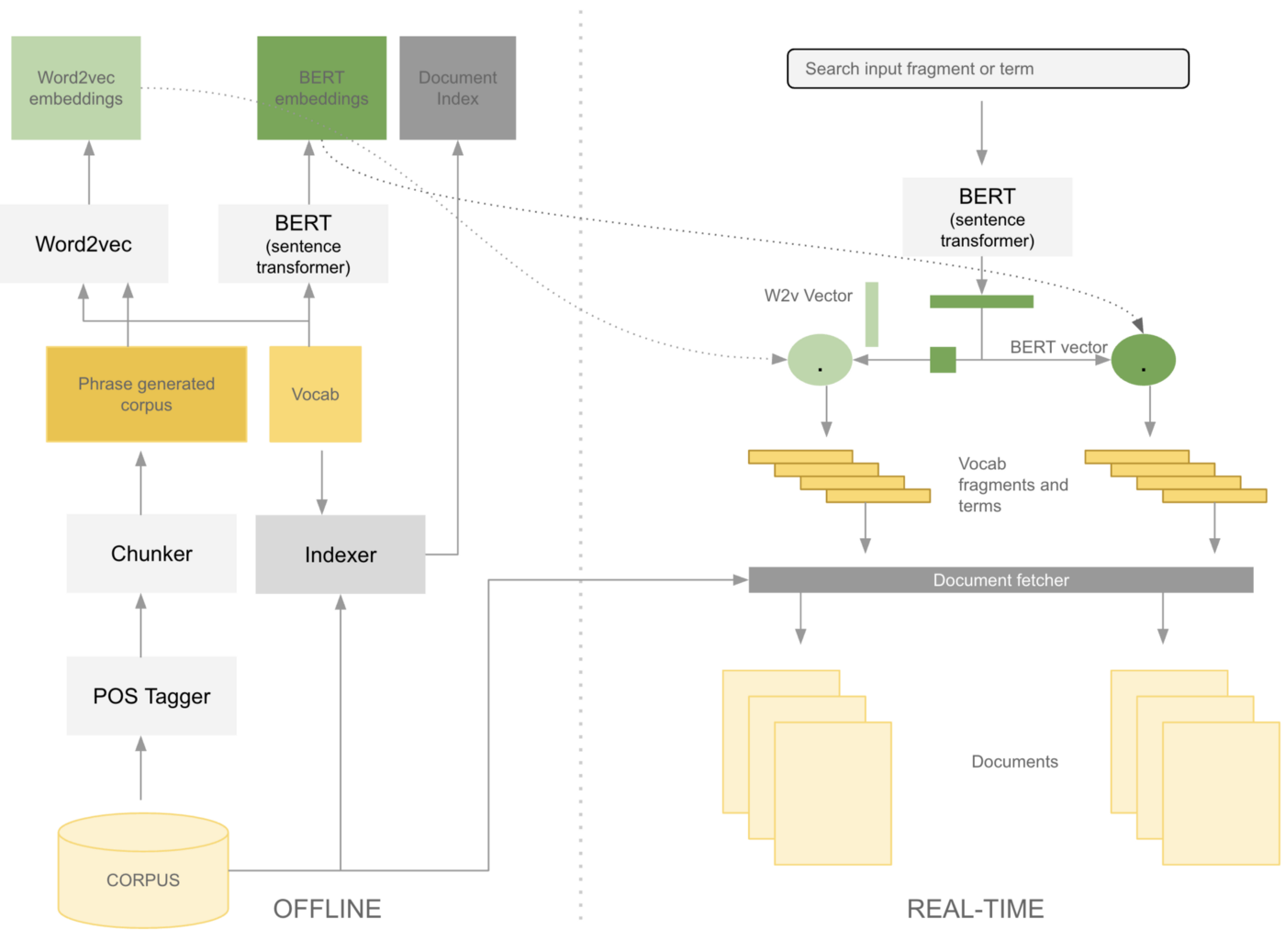
從word2vec/BERT嵌入中獲取的擴展術語或片段,用于精確匹配已使用這些術語或片段離線索引的檔案,在離線狀態下,使用詞性標記器和分塊器的組合從語料庫中獲取片段,并使用word2vec和BERT這兩種模型為其創建嵌入,
-
將用戶輸入映射到術語和片段嵌入不僅具有增加搜索廣度和深度的優勢,而且還避免了創建與用戶輸入匹配的高質量檔案嵌入的問題,具體來說,片段扮演檔案索引的雙重角色,并使單個檔案具有可搜索的多個“提取摘要”,因為片段嵌入在檔案中,與純粹使用術語或短語查找此類檔案相比,使用片段還會增加找到大篇幅檔案中目標關鍵詞的幾率,例如尋找冠狀病毒的潛在動物來源就是在大篇幅檔案中找到目標的一個明確的案例,我們可以在上面的圖中看到片段與單個檔案匹配(這在下面的notes部分中進行了詳細的檢查),
-
使用嵌入純粹是為了發現候選術語/片段,并利用傳統的搜索索引方法來尋找匹配這些術語/片段的檔案,這使我們能夠大規模地執行檔案搜索,
-
最后,在找到諸如“ COVID-19的動物來源是什么?”之類的廣泛問題的答案時鑒于此任務的范圍和處理時間很大,因此可以自動且脫機完成此操作,此處介紹的片段嵌入驅動的搜索方法適用于“并不太寬廣”的實時搜索用例,例如在給定足夠的計算資源和有效的散列方法的情況下,使用“受體冠狀病毒的受體”的嵌入大規模執行嵌入空間搜索,
當前方法的局限性
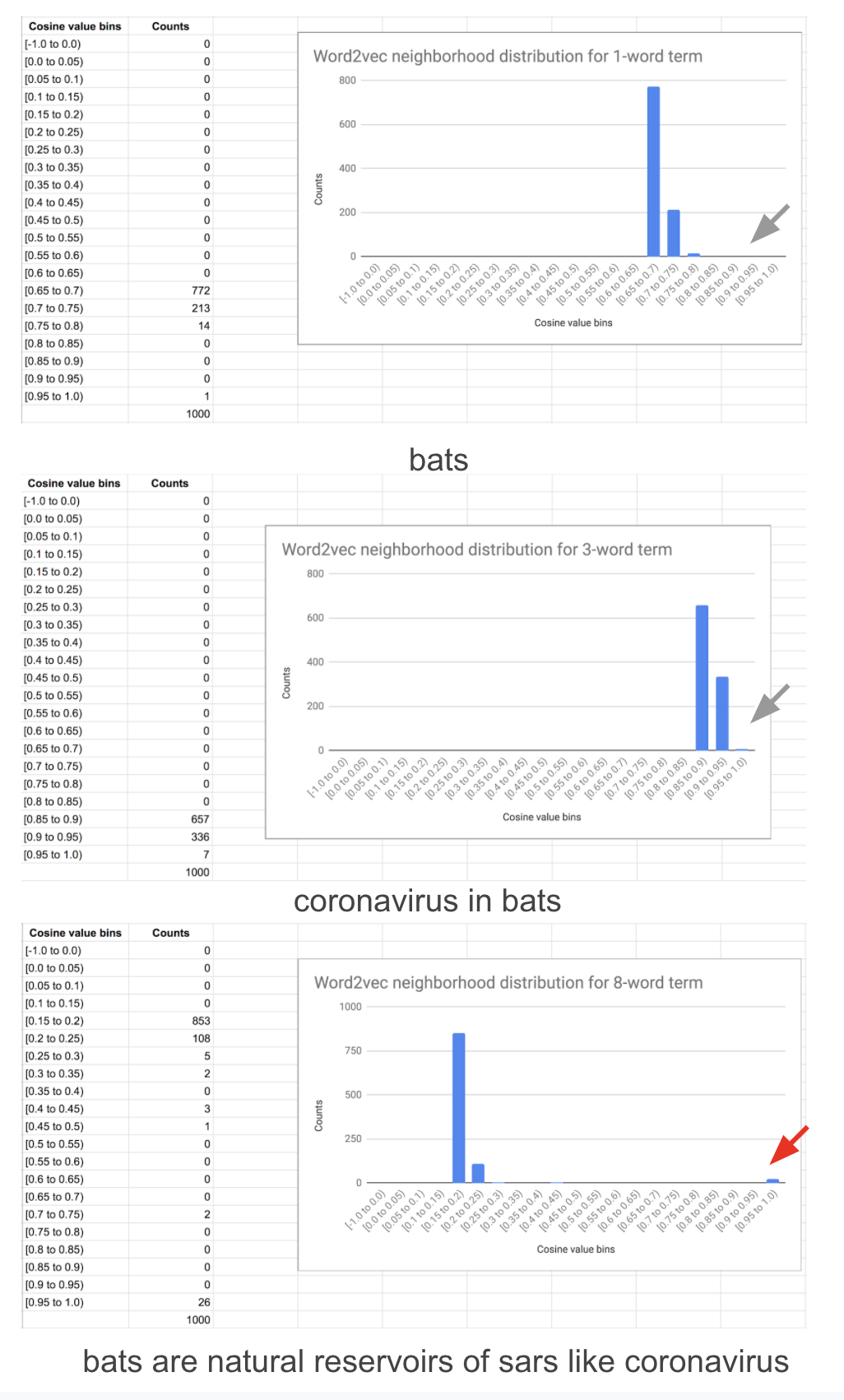
如前所述,word2vec嵌入擴展了單詞和短語的搜索范圍,它們不會擴展片段搜索的廣度——鄰域區域的直方圖經常缺少一個明顯的尾部(下面的圖),這是因為片段由于其長度而沒有足夠的鄰域背景關系來學習高質量的嵌入,這一缺陷可以通過擴展訓練的視窗大小和忽略句子邊界來增加周圍的背景關系來部分地解決,但是在實踐中仍然是不夠的,因為片段的出現次數很低,
BERT嵌入在很大程度上只增加了搜索的深度,特別是對于片段和短語(使用BERT嵌入擴展單詞的搜索深度在實踐中是沒有用的),雖然它們確實在一定程度上增加了寬度,例如,“獼猴中的冠狀病毒”的查詢擴展為“棕櫚果子貍中的冠狀病毒”,包含在統計結果的分布尾端,但其寬度不如word2vec提供的單詞和短語,下面的圖說明了它的不足之處,實作注釋中還有一些關于片段搜索缺乏廣度的例子,以及一些規避這一限制的方法,
結尾
Word2vec可能是大約七年前第一個明確建立向量化表示能力的模型,這個簡單模型的“架構”實際上是兩個向量陣列,它輸出的embeddings對于下游應用程式(如上面描述的檔案搜索方法)仍然具有巨大的價值,
Word2vec與BERT嵌入合作,為檔案搜索提供了一種解決方案,這種解決方案在搜索結果的質量和收斂時間方面都有可能改進傳統方法(這種要求需要進行量化),搜索系統可以使用該向量表示不僅選擇特定的檔案,而且還可以找到與所選檔案類似的檔案,
在選擇檔案之前,可以使用嵌入(無論是單詞、短語還是句子片段)來擴大/深化搜索,詞和短語的Word2vec嵌入在很大程度上增加了檔案搜索的廣度,BERT嵌入大大增加了句子片段的搜索深度,BERT嵌入還消除了生僻詞場景,并促進了對檔案中不同的重要片段的可搜索提取摘要,從而加快了對相關檔案的聚合,
參考
- The animal source of COVID-19 is not confirmed to date.
Sentence BERT - Unsupervised NER using BERT
- An answer explaining how word2vec works
實作的注意事項
1. 此方法中使用的NLP方法/模型是什么?
詞性標記來標記一個句子(基于CRF的比目前F1度量的STOA方法快一個數量級,并且模型的召回率也已經滿足任務的要求)
分塊器(chunker)創建短語
Word2vec表示單詞和短語的嵌入
BERT用于片段嵌入(句子轉換)
BERT用于無監督物體標記
2. 如何計算檔案結果的相關性?
可以通過片段基于到輸入片段的余弦距離的排序,并且集中匹配每個片段的檔案將被優先挑選出來,并按照與輸入片段順序相同的順序列出,
3.這種搜索方法是否適用于實時搜索?
實時搜索的計算密集型步驟是嵌入空間中的相似度搜索(Word2vec或BERT),現有的開放原始碼解決方案已經可以大規模地執行此操作,我們可以做一些優化來減少時間/計算周期,比如根據輸入搜索長度只搜索兩個嵌入空間中的一個,因為這些模型的優缺點依賴于搜索長度,
4. 一個片段不就是一個很長的短語嗎?如果是,為什么要換一種叫法呢?
a)片段本質上是一個長短語,與短語的區別之所以有用,有一個原因,片段可以是完整的句子,而不只是部分句子
b)這些模型的強度依賴于我們前面看到的輸入長度,Word2vec在詞/短語方面表現良好,BERT在片段區域表現最好(≥5個單詞)
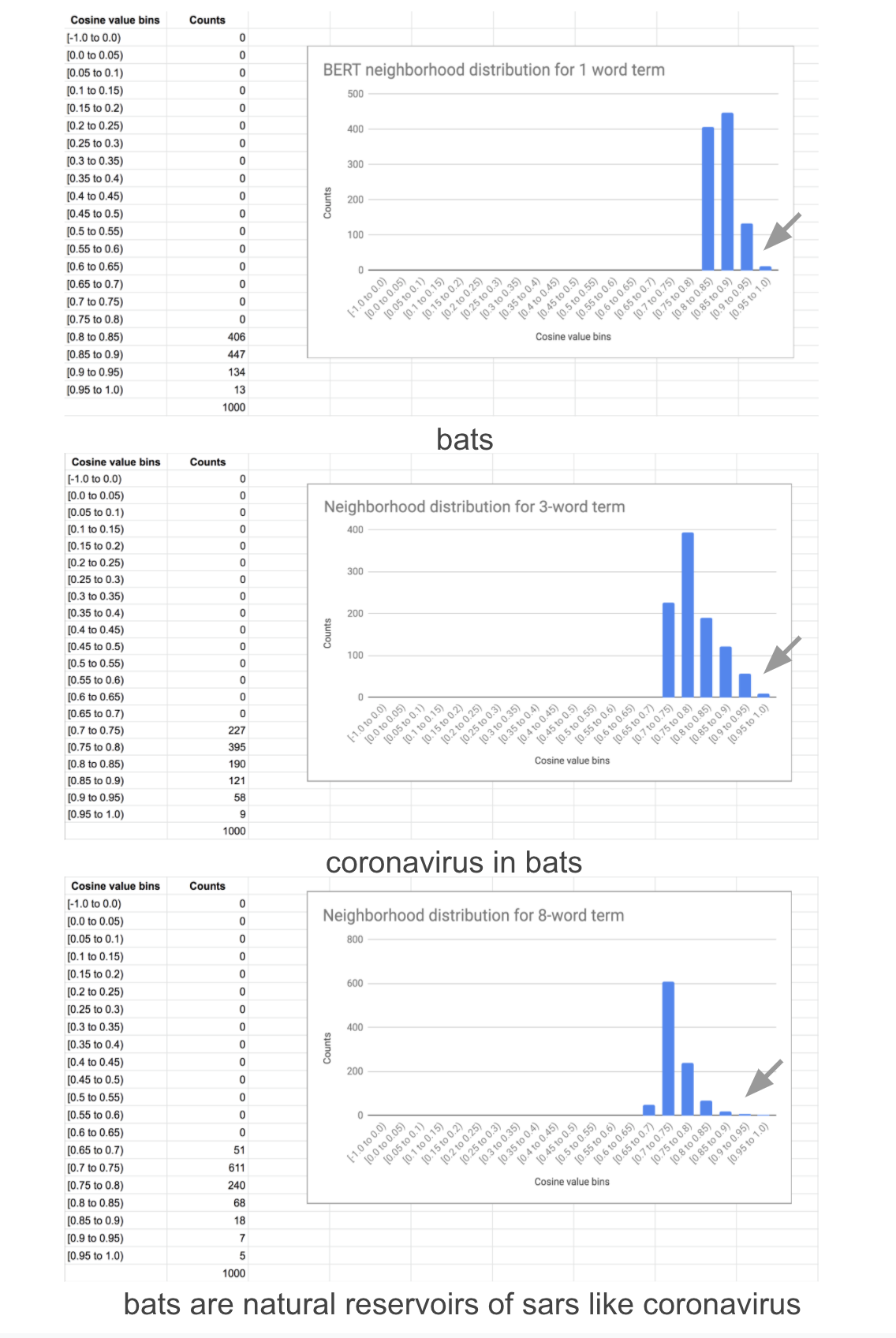
5. 鄰域的直方圖分布如何查找術語和片段?
以下是BERT和Word2vec的單詞、短語(3個單詞)和片段(8個單詞)的鄰域,它們說明了這兩個模型的互補性,分布的尾部隨著BERT單詞長度的增加而增加,而與短語或單詞相比,片段的尾部明顯不同,當計數項較低時,有時分布可能有很厚的尾部,這表示結果較差,由sentence-transformers產生的嵌入往往有一個獨特的尾巴,與bert-as-service產生的嵌入相反,盡管都使用對子詞進行求和作為池化方法(也有其他池方法),因為sentence-transfomers的監督訓練使用句子對的標簽帶有蘊含,中性和矛盾的語意,
Word2vec對單詞和短語很感興趣,對于長短語,即使出現的次數很高,這種向量化幾乎可以分解為一種“病態形式”,在高端聚集,其余的集中在低端,長短語的分布形狀也有所不同,然而,不管形狀如何,鄰域結果都清楚地表明了這種質量下降,
6. 結果對輸入片段變化的敏感性,這就是我們使用輸入變數來收斂于相同結果成為可能,
雖然針對同一問題的不同變體檢索到的片段集是不同的,但是檢索到的片段集中可能有很多交集,但是,由于前面討論的片段的廣度有限,有些問題可能不會產生任何涉及所有搜索的名詞的片段,例如,“作為冠狀病毒來源的翼龍”或“翼龍冠狀病毒”可能不會產生任何含有蝙蝠的片段(翼龍屬于蝙蝠科),當片段不包含所有名詞時,需要考慮的一種方法是找到該術語的Word2vec的近義詞并使用這些術語重建查詢,
7. 使用術語、短語和片段在大篇幅檔案,這些模型分別表現如何呢?
Word2vec嵌入在這種情況下并不直接有用,因為單個出現項/短語的向量沒有足夠的背景關系來學習豐富的表示,BERT嵌入沒有這個缺點,單詞有足夠的背景關系來學習好的表示,然而,Word2vec仍然可以在搜索中為一個名詞找到近義詞,例如,如果檔案空間中只有一個對果蝠冠狀病毒的參考,那么在翼龍中搜索冠狀病毒可能不會得到該檔案,然而,在果蝠中搜索冠狀病毒片段(使用Word2vec創建)可以找到該檔案,但是如果一個片段出現在一個分布尾部使它成為一個候選者,那么就可能會被篩出去,大多數片段固有的可解釋性提供了一個優勢,而一個單詞或短語不一定具備這個優勢,
8. 關于提取動物冠狀病毒資訊的更多細節
使用Word2vec和物體標記,大約獲得了1000(998)個生物物體,這些被用來收集195個帶有病毒的片段,這里顯示了一個包含30個片段的示例

這些片段的樣本有動物作為冠狀病毒潛在來源的證據

原文鏈接:https://towardsdatascience.com/document-search-with-fragment-embeddings-7e1d73eb0104
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/178338.html
標籤:其他
上一篇:云平臺內部網路資源整合技術