作者|SHIPRA SAXENA
編譯|Flin
來源|analyticsvidhya
總覽
-
了解什么是分類資料編碼
-
了解不同的編碼技術以及何時使用它們
介紹
機器學習模型的性能不僅取決于模型和超引數,還取決于我們如何處理并將不同型別的變數輸入模型,由于大多數機器學習模型僅接受數值變數,因此對分類變數進行預處理成為必要的步驟,我們需要將這些分類變數轉換為數字,以便該模型能夠理解和提取有價值的資訊,

典型的資料科學家花費70-80%的時間來清理和準備資料,轉換分類資料是不可避免的活動,它不僅可以提高模型質量,而且可以幫助進行更好的特征工程,現在的問題是,我們如何進行?我們應該使用哪種分類資料編碼方法?
在本文中,我將解釋各種型別的分類資料編碼方法以及在Python中的實作,
如果你想學習視頻格式的資料科學概念,請查看我們的課程:
- 資料科學導論
- https://courses.analyticsvidhya.com/courses/introduction-to-data-science-2
目錄
- 什么是分類資料?
- 標簽編碼或有序編碼
- 獨熱編碼
- 虛擬編碼
- 效果編碼
- 二進制編碼
- BaseN編碼
- 哈希編碼
- 目標編碼
什么是分類資料?
由于我們將在本文中處理類別變數,因此這里有一些示例,可以快速復習,分類變數通常表示為“字串”或“類別”,并且數量有限,這里有一些例子:
- 一個人居住的城市:德里,孟買,艾哈邁達巴德,班加羅爾等,
- 一個人作業的部門:財務,人力資源,生產部,
- 一個人擁有的最高學位:高中,學士,碩士,博士學位,
- 學生的成績:A +,A,B +,B,B-等,
在以上示例中,變數僅具有確定的可能值,此外,我們可以看到有兩種分類資料:
有序資料:類別具有固有順序
名義資料:類別沒有固有順序
在有序資料中,在進行編碼時,應保留有關類別提供順序的資訊,就像上面的例子一樣,一個人擁有的最高學位,給出了有關他的資格的重要資訊,學位是決定一個人是否適合擔任職位的重要特征,
在編碼名義資料時,我們必須考慮特征的存在與否,在這種情況下,不存在順序的概念,例如,一個人居住的城市,對于資料,保留一個人居住的位置很重要,在這里,我們沒有任何順序,如果一個人住在德里或班加羅爾,這是平等的,與順序無關,
為了編碼分類資料,我們有一個python包category_encoders,以下代碼可幫助你輕松安裝,
pip install category_encoders
標簽編碼或有序編碼
當分類特征有序時,我們使用這種分類資料編碼技術,在這種情況下,保留順序很重要,因此編碼應該反映順序,
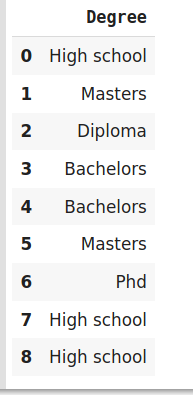
在標簽編碼中,每個標簽都被轉換成一個整數值,我們將創建一個變數,該變數包含代表一個人的教育資格的類別,
import category_encoders as ce
import pandas as pd
train_df=pd.DataFrame({'Degree':['High school','Masters','Diploma','Bachelors','Bachelors','Masters','Phd','High school','High school']})
# 創建Ordinalencoding的物件
encoder= ce.OrdinalEncoder(cols=['Degree'],return_df=True,
mapping=[{'col':'Degree',
'mapping':{'None':0,'High school':1,'Diploma':2,'Bachelors':3,'Masters':4,'phd':5}}])
#原始資料
train_df
# 調整并轉換資料
df_train_transformed = encoder.fit_transform(train_df)

獨熱編碼
當特征沒有任何順序時,我們使用這種分類資料編碼技術,在獨熱編碼中,對于一個分類特征的每個級別,我們創建一個新的變數,每個類別都映射有一個包含0或1的二進制變數,在這里,0代表該類別不存在,1代表該類別存在,
這些新創建的二進制特性稱為虛擬變數,虛擬變數的數量取決于類別變數中的級別,這聽起來可能很復雜,
讓我們舉個例子來更好地理解這一點,假設我們有一個動物分類資料集,有不同的動物,如狗、貓、羊、牛、獅子,現在我們必須對這些資料進行獨熱編碼,
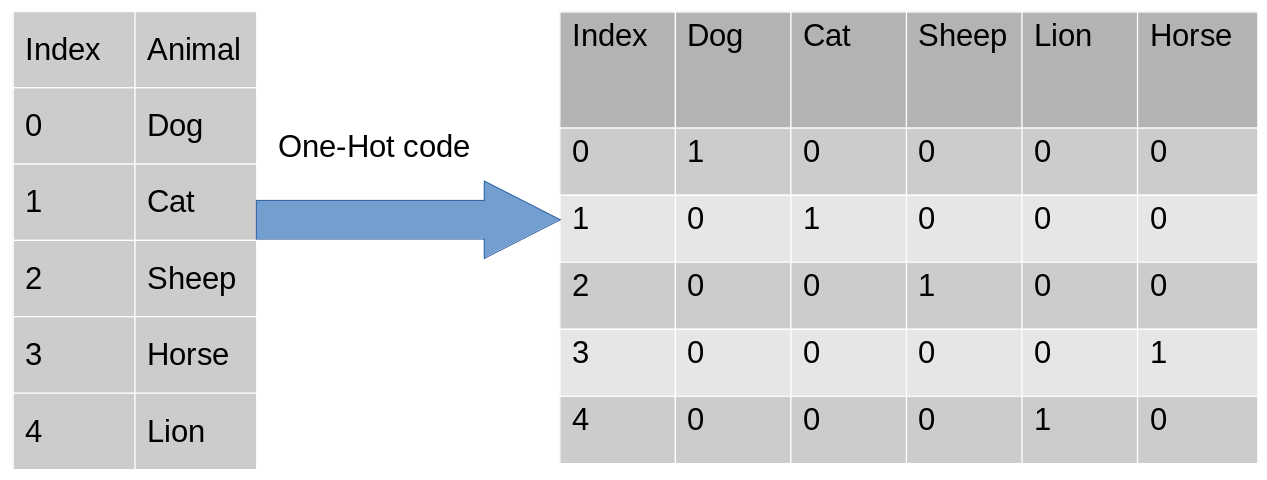
編碼后,在第二個表中,我們有一個虛擬變數,每個變數代表動物的類別,現在,對于每個存在的類別,我們在該類別的列中都有1,其他列為0,讓我們看看如何在python中實作獨熱編碼,
import category_encoders as ce
import pandas as pd
data=https://www.cnblogs.com/panchuangai/p/pd.DataFrame({'City':[
'Delhi','Mumbai','Hydrabad','Chennai','Bangalore','Delhi','Hydrabad','Bangalore','Delhi'
]})
#創建用于獨熱編碼的物件
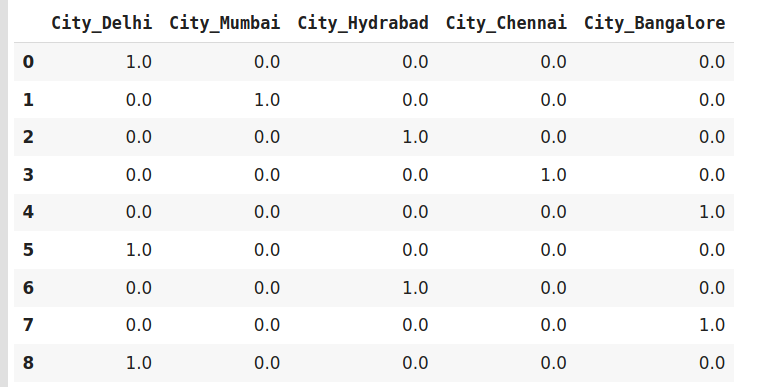
encoder=ce.OneHotEncoder(cols='City',handle_unknown='return_nan',return_df=True,use_cat_names=True)
# 原始資料
data

# 調整和轉換資料
data_encoded = encoder.fit_transform(data)
data_encoded
現在,讓我們轉到另一種非常有趣且廣泛使用的編碼技術,即虛擬編碼,
虛擬編碼
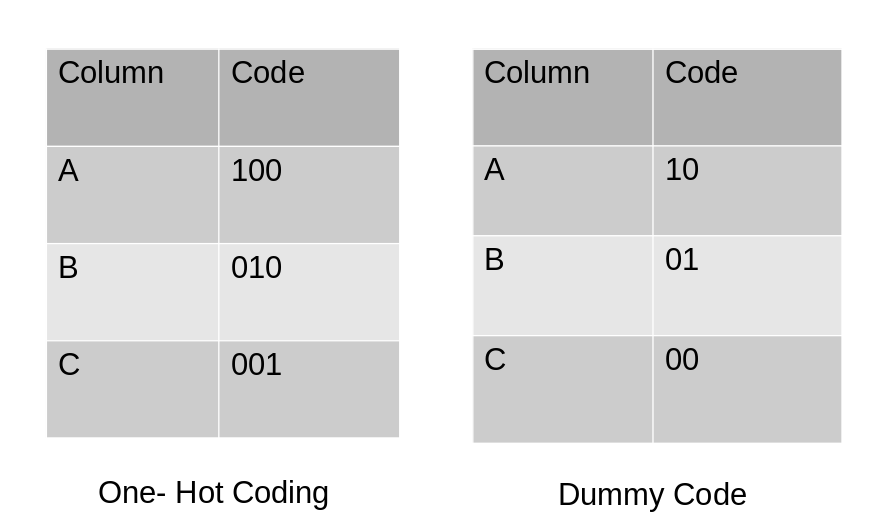
虛擬編碼方案類似于獨熱編碼,這種分類資料編碼方法將分類變數轉換為一組二進制變數(也稱為虛擬變數),在獨熱編碼的情況下,對于變數中的N個類別,它使用N個二進制變數,虛擬編碼是對獨熱編碼的一個小改進,虛擬編碼使用N-1個特征來表示N個標簽/類別,
為了更好地理解這一點,讓我們看下面的圖片,在這里,我們使用獨熱編碼和虛擬編碼技術對相同的資料進行編碼,獨熱編碼使用3個變數表示資料,而虛擬編碼使用2個變數編碼3個類別,
讓我們在python中實作它,
import category_encoders as ce
import pandas as pd
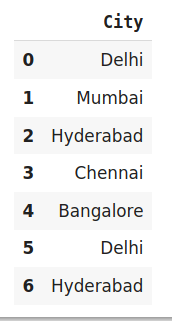
data=https://www.cnblogs.com/panchuangai/p/pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi,'Hyderabad']})
# 原始資料
data
#編碼資料
data_encoded=pd.get_dummies(data=https://www.cnblogs.com/panchuangai/p/data,drop_first=True)
data_encoded
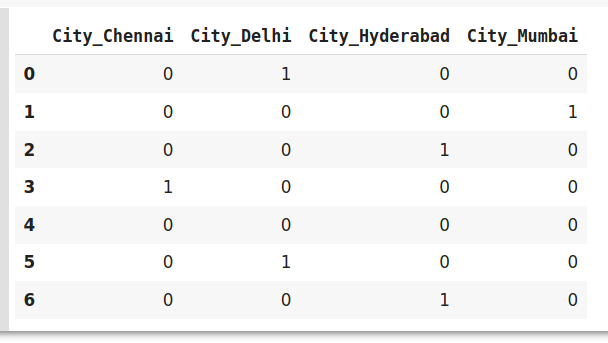
在這里,使用drop_first引數,我們使用0表示第一個標簽Bangalore,
獨熱和虛擬編碼的缺點
獨熱編碼器和虛擬編碼器是兩種功能強大且有效的編碼方案,它們在資料科學家中也很受歡迎,但在以下這些情況下可能不那么有效:
-
資料中存在大量級別,在這種情況下,如果一個特征變數中有多個類別,則我們需要相似數量的虛擬變數來對資料進行編碼,例如,具有30個不同值的列將需要30個新變數進行編碼,
-
如果我們在資料集中具有多個分類特征,則將發生類似的情況,并且我們最侄訓有幾個二進制特征,每一個都代表分類特征和它們的多個類別,例如一個包含10個或更多分類列的資料集,
在以上兩種情況下,這兩種編碼方案都會在資料集中引入稀疏性,即幾列為0,而另幾列為1,換句話說,它在資料集中創建了多個虛擬特征而無需添加太多資訊,
此外,它們可能會導致虛擬變數陷阱,這是特征高度相關的現象,這意味著使用其他變數,我們可以輕松預測變數的值,
由于資料集的大量增加,編碼使模型的學習變慢,并且整體性能下降,最終使模型的計算昂貴,此外,在使用基于樹的模型時,這些編碼不是最佳選擇,
效果編碼(Effect Encoding)
這種編碼技術也稱為偏差編碼(Deviation Encoding)或求和編碼(Sum Encoding),效果編碼幾乎與虛擬編碼類似,只是有一點點差異,在虛擬編碼中,我們使用0和1表示資料,但在效果編碼中,我們使用三個值,即1,0和-1,
在虛擬編碼中僅包含0的行在效果編碼中被編碼為-1,在虛擬編碼示例中,索引為4的班加羅爾城市被編碼為0000,而在效果編碼中,它是由-1-1-1-1表示的,
讓我們看看我們如何在python中實作它
import category_encoders as ce
import pandas as pd
data=https://www.cnblogs.com/panchuangai/p/pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi,'Hyderabad']}) encoder=ce.sum_coding.SumEncoder(cols='City',verbose=False,)
# 原始資料
data
encoder.fit_transform(data)
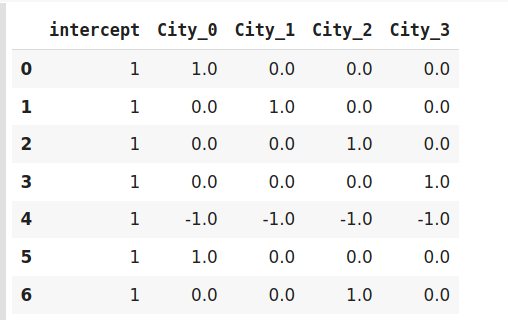
效果編碼是一種先進的技術,如果你有興趣了解更多關于效果編碼的資訊,請參閱這篇有趣的文章,
- https://www.researchgate.net/publication/256349393_Categorical_Variables_in_Regression_Analysis_A_Comparison_of_Dummy_and_Effect_Coding
哈希編碼器
要理解哈希編碼,就必須了解哈希,哈希是以固定大小值的形式對任意大小的輸入進行的轉換,我們使用哈希演算法來執行哈希操作,即生成輸入的哈希值,
此外,哈希是一個單向程序,換句話說,不能從哈希表示生成原始輸入,
散列有幾個應用,如資料檢索、檢查資料損壞以及資料加密,我們有多個哈希函式可用,例如訊息摘要(MD、MD2、MD5)、安全哈希函式(SHA0、SHA1、SHA2)等等,
就像獨熱編碼一樣,哈希編碼器使用新的維度來表示分類特性,在這里,用戶可以使用n_component引數來確定轉換后的維度數量,這就是我的意思——一個有5個類別的特征可以用N個新特征來表示,同樣,一個有100個類別的特征也可以用N個新特征來轉換,聽起來不錯吧?
默認情況下,哈希編碼器使用md5哈希演算法,但用戶可以傳遞他選擇的任何演算法,如果你想探索md5演算法,我建議你閱讀這篇文章,
- https://ieeexplore.ieee.org/document/5474379
import category_encoders as ce
import pandas as pd
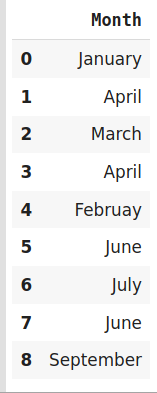
#Create the dataframe
data=https://www.cnblogs.com/panchuangai/p/pd.DataFrame({'Month':['January','April','March','April','Februay','June','July','June','September']})
#Create object for hash encoder
encoder=ce.HashingEncoder(cols='Month',n_components=6)
# 調整和轉換資料
encoder.fit_transform(data)
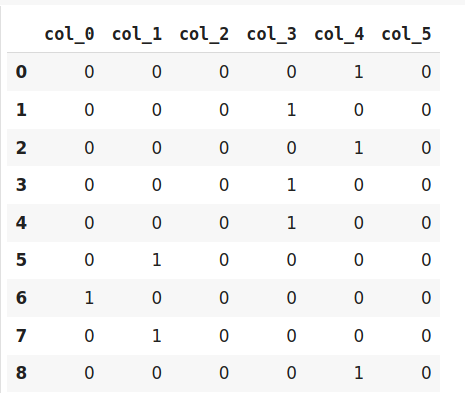
由于哈希將資料轉換為較小的維度,因此可能導致資訊丟失,哈希編碼器面臨的另一個問題是沖突,由于此處將大量特征描繪成較小的尺寸,因此可以用相同的哈希值表示多個值,這稱為沖突,
此外,哈希編碼器在某些Kaggle比賽中非常成功,最好嘗試一下資料集是否具有高基數特征,
二進制編碼
二進制編碼是哈希編碼和獨熱編碼的組合,在這種編碼方案中,首先使用有序編碼器將分類特征轉換為數值,然后將數字轉換為二進制數,之后,該二進制值將拆分為不同的列,
當類別很多時,二進制編碼的效果很好,例如,公司提供產品的國家/地區的城市,
#Import the libraries
import category_encoders as ce
import pandas as pd
#Create the Dataframe
data=https://www.cnblogs.com/panchuangai/p/pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi','Hyderabad','Mumbai','Agra']})
#Create object for binary encoding
encoder= ce.BinaryEncoder(cols=['city'],return_df=True)
# 原始資料
data
# 調整和轉換資料
data_encoded=encoder.fit_transform(data)
data_encoded
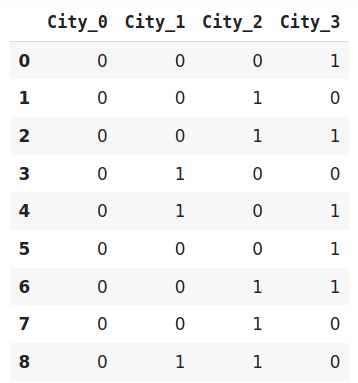
二進制編碼是一種節省記憶體的編碼方案,因為它比獨熱編碼使用更少的特性,此外,它還減少了高基數資料的維數災難,
BaseN編碼
在開始使用BaseN編碼之前,我們首先嘗試了解什么是Base,
在數字系統中,“底數”或“基數”是數字的數目或用于表示數字的數字和字母的組合,我們一生中最常用的基數是10或十進制,因為在這里我們使用10個唯一數字,即0到9來代表所有數字,另一個廣泛使用的系統是二進制,即基數為2,它使用0和1,即2位數字來表示所有數字,
對于二進制編碼,基數為2,這意味著它將類別的數值轉換為其各自的二進制形式,如果要更改基本編碼方案,則可以使用BaseN編碼器,如果類別更多,而二進制編碼無法處理維數,則可以使用更大的底數,例如4或8,
#Import the libraries
import category_encoders as ce
import pandas as pd
#Create the dataframe
data=https://www.cnblogs.com/panchuangai/p/pd.DataFrame({'City':['Delhi','Mumbai','Hyderabad','Chennai','Bangalore','Delhi','Hyderabad','Mumbai','Agra']})
#Create an object for Base N Encoding
encoder= ce.BaseNEncoder(cols=['city'],return_df=True,base=5)
# 原始資料
data
# 調整和轉換資料
data_encoded=encoder.fit_transform(data)
data_encoded
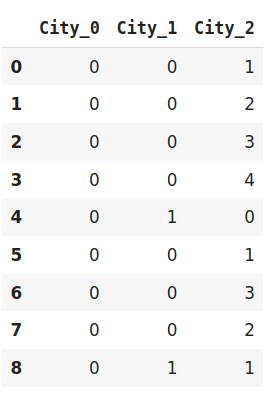
在上面的例子中,我使用了base5,也就是所謂的五元體系,它類似于二進制編碼的例子,二進制編碼用4個新特性表示相同的資料,而BaseN編碼只使用3個新變數,
因此,BaseN編碼技術進一步減少了有效表示資料和提高記憶體使用率所需的特征數量,基數N的默認基數是2,這相當于二進制編碼,
目標編碼
目標編碼是一種貝葉斯編碼技術,
貝葉斯編碼器使用來自相關/目標變數的資訊對分類資料進行編碼,
在目標編碼中,我們計算每個類別的目標變數的平均值,并用平均值替換類別變數,在分類目標變數的情況下,目標的后驗概率代替每個類別,
#import the libraries
import pandas as pd
import category_encoders as ce
#創建資料框
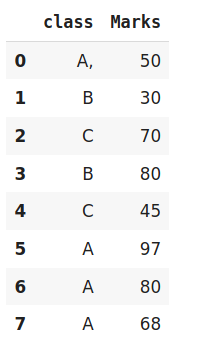
data=https://www.cnblogs.com/panchuangai/p/pd.DataFrame({'class':['A,','B','C','B','C','A','A','A'],'Marks':[50,30,70,80,45,97,80,68]})
#創建目標編碼物件
encoder=ce.TargetEncoder(cols='class')
# 原始資料
Data
# 調整并轉換資料
encoder.fit_transform(data['class'],data['Marks'])
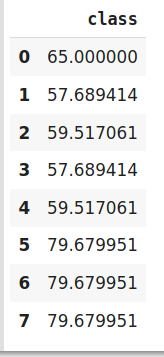
我們僅對訓練資料執行目標編碼,并使用從訓練資料集中獲得的結果對測驗資料進行編碼,盡管這是一種非常高效的編碼系統,但它具有以下問題,這些問題會導致模型性能下降
-
它可能導致目標泄漏( target leakage)或過擬合,為了解決過擬合問題,我們可以使用不同的技術,
- 在留一法編碼中,將當前目標值從目標的整體平均值中減小以避免泄漏,
- 在另一種方法中,我們可能會在目標統計資訊中引入一些高斯噪聲,這種噪聲的值是模型的超引數,
-
我們可能面臨的第二個問題是訓練和測驗資料中類別的不正確分配,在這種情況下,類別可能采用極端值,因此,類別的目標平均值與目標的邊際平均值混合在一起,
尾注
總而言之,對分類資料進行編碼是特征工程中不可避免的部分,知道我們應該使用哪種編碼方案更為重要,考慮到我們正在使用的資料集和將要使用的模型,在本文中,我們已經看到了各種編碼技術以及它們的問題和合適的用例,
如果你想了解有關處理分類變數的更多資訊,請參閱本文
- 預測建模中處理分類變數的簡單方法
- https://www.analyticsvidhya.com/blog/2015/11/easy-methods-deal-categorical-variables-predictive-modeling
原文鏈接:https://www.analyticsvidhya.com/blog/2020/08/types-of-categorical-data-encoding/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/178584.html
標籤:其他