機器學習案例實操——鳶尾花
本文做要給大家回歸一下Numpy的基礎知識,畢竟python 中的sklearn中使用的是這種資料型別,然后用一個鳶尾花分類實體給大家演示機器學習的整個程序,讓你快速入門機器學習,
1.Numpy基礎知識回顧


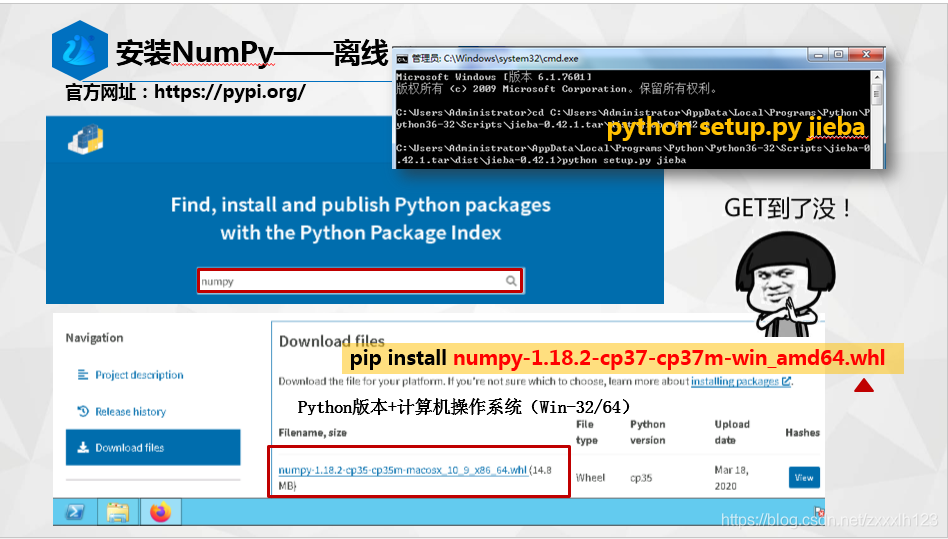
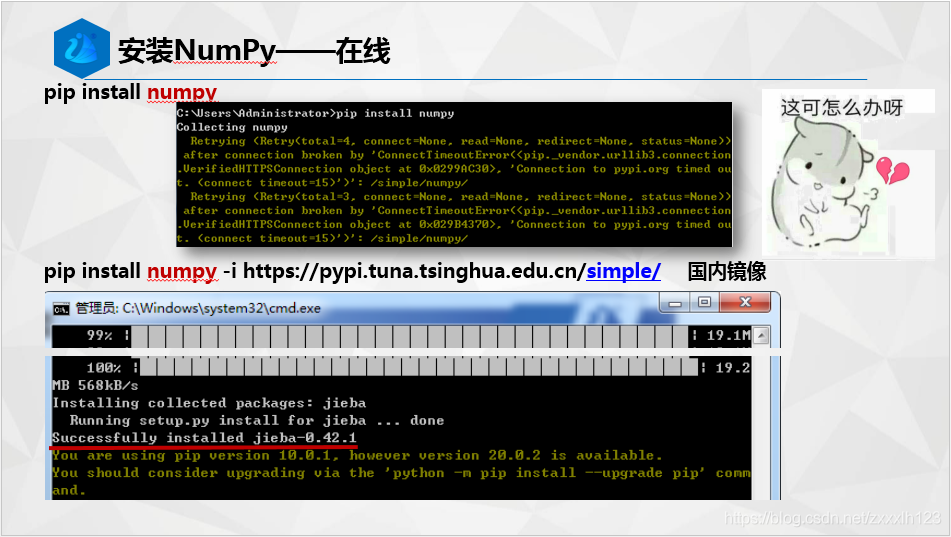

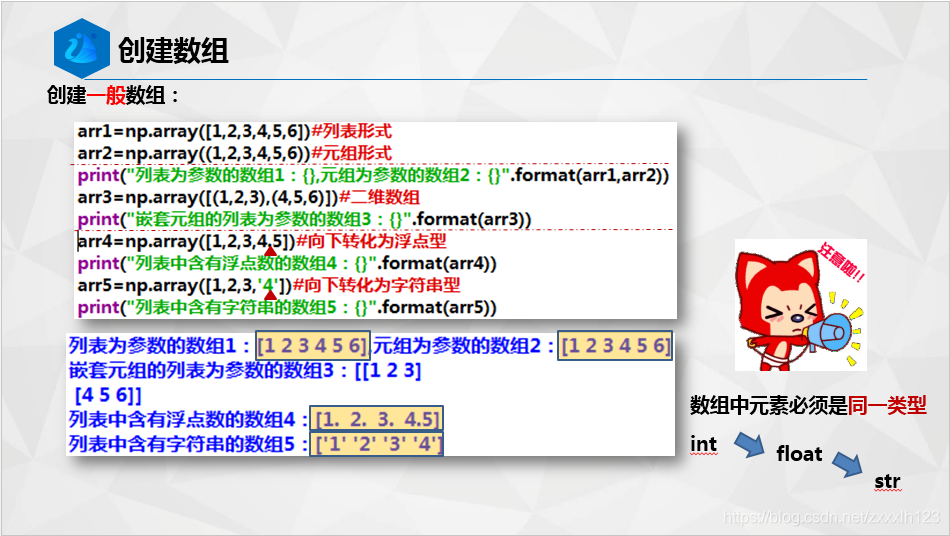

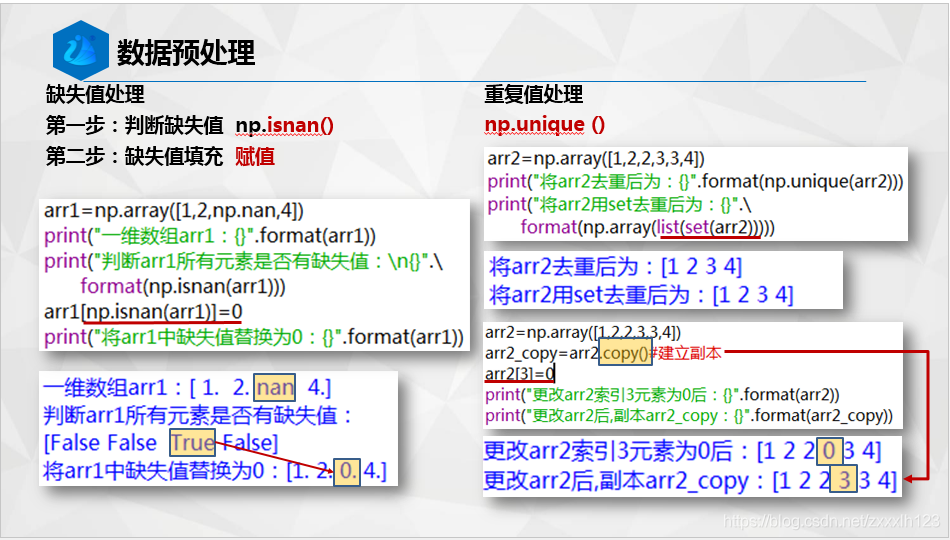
2.辨異識花

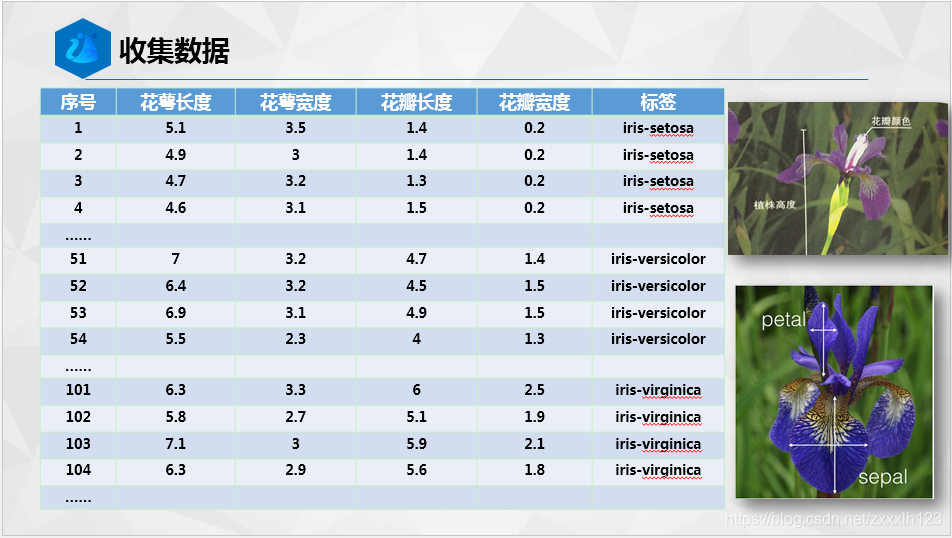
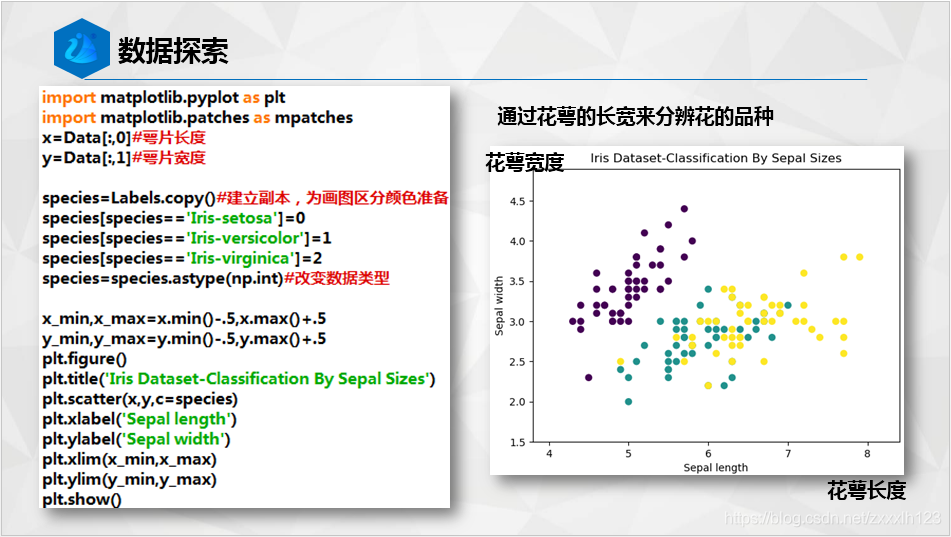
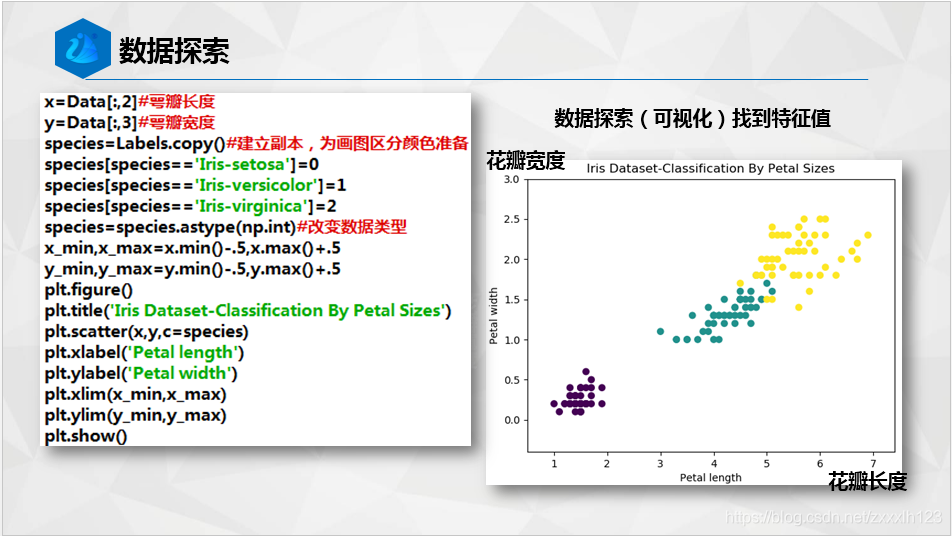


下面附上代碼塊給大家O(∩_∩)O
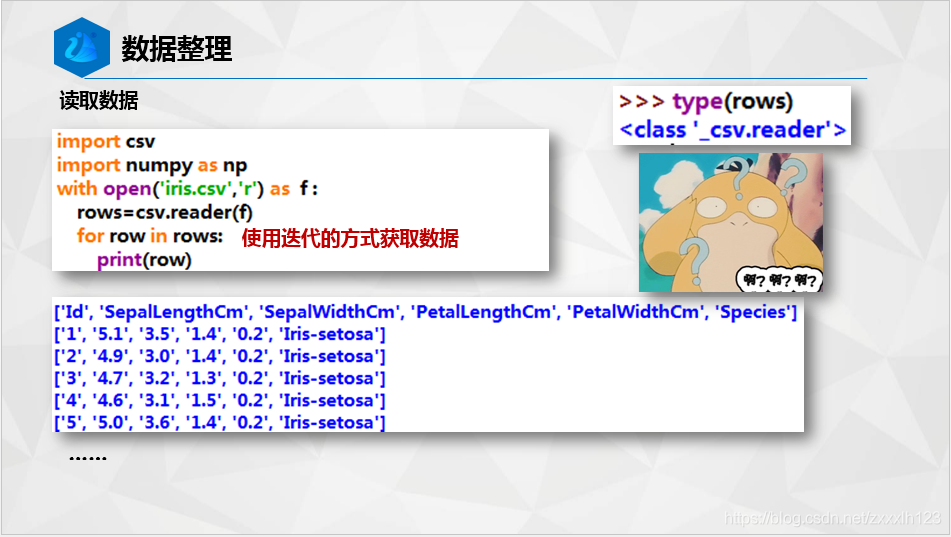
import csv
import numpy as np
with open('iris.csv','r') as f :
rows=csv.reader(f)
for row in rows:
print(row)
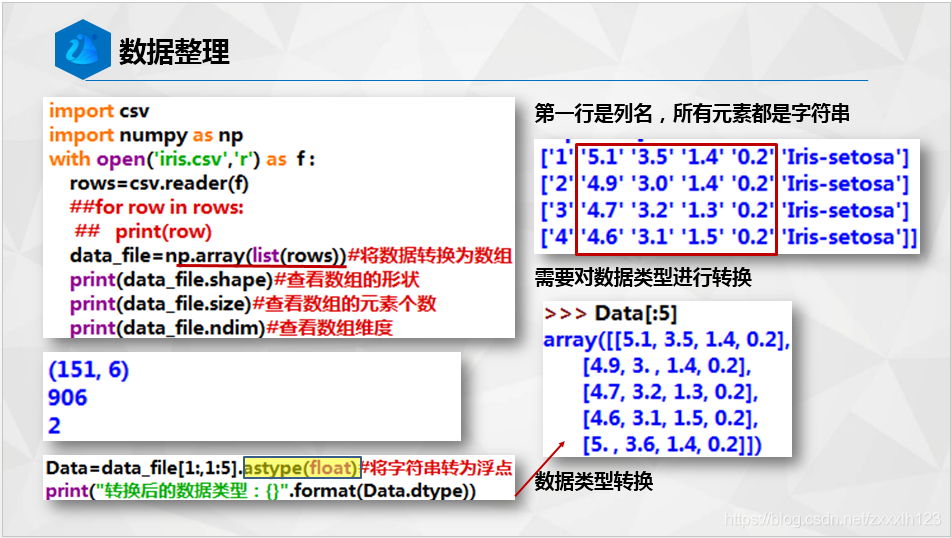
data_file=np.array(list(rows))#將資料轉換為陣列
print(data_file.shape)#查看陣列的形狀
Data=data_file[1:,1:5].astype(float)#將字串轉為浮點
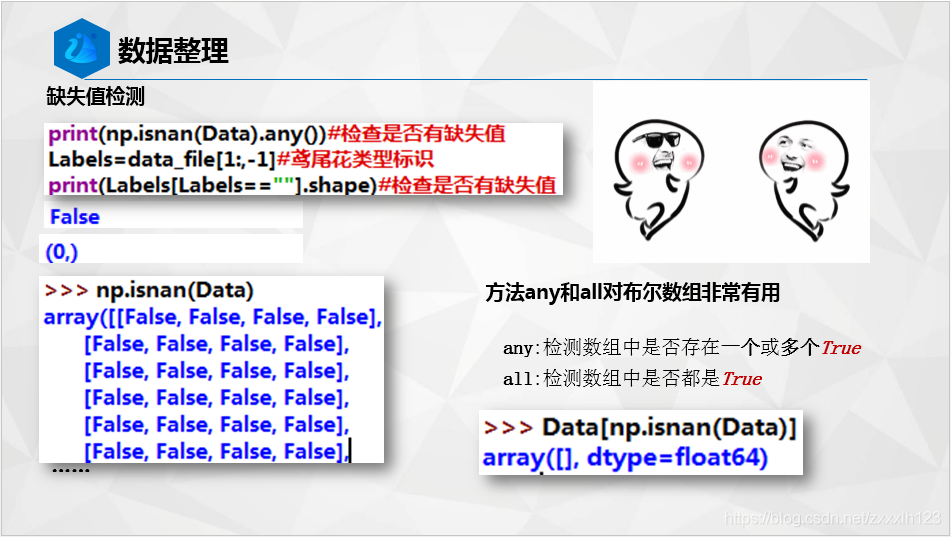
print(np.isnan(Data).any())#檢查是否有缺失值
Labels=data_file[1:,-1]#鳶尾花型別標識
print(Labels[Labels==""].shape)#檢查是否有缺失值
from sklearn.neighbors import KNeighborsClassifier
np.random.seed(0)#設定隨機種子,產生的亂數一樣
indices = np.random.permutation(len(Data))#隨機打亂陣列
print(indices)
Data_train = Data[indices[:-10]]#隨機選取140樣本作為訓練集
Labels_train = Labels[indices[:-10]]#隨機選取140樣本標簽作為訓練集
Data_test = Data[indices[-10:]]#剩下10個樣本作為測驗集
Labels_test = Labels[indices[-10:]]#剩下10個樣本標簽作為測驗集
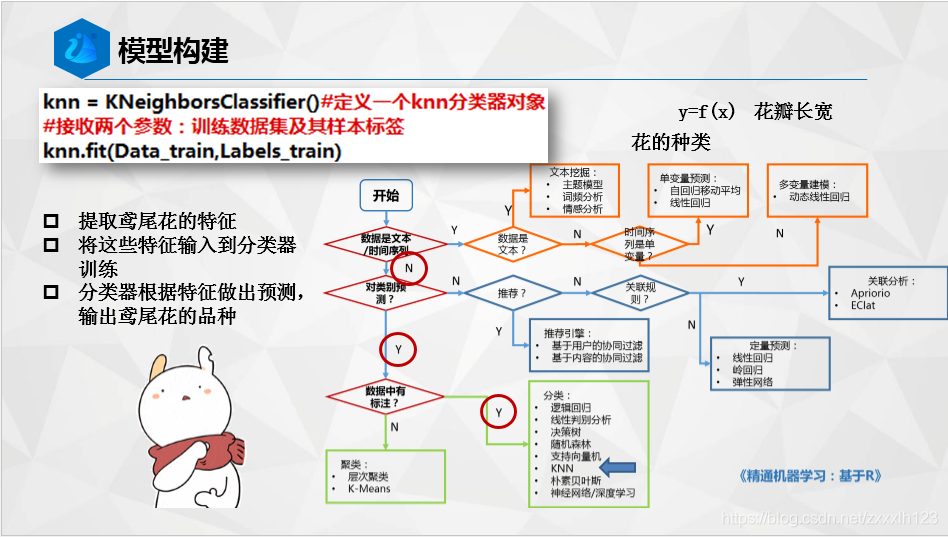
knn = KNeighborsClassifier()#定義一個knn分類器物件
knn.fit(Data_train,Labels_train)#接收兩個引數:訓練資料集及其樣本標簽
Labels_predict = knn.predict(Data_test) #呼叫該物件的測驗方法,主要接收一個引數:測驗資料集
probility=knn.predict_proba(Data_test)#計算各測驗樣本基于概率的預測
neighborpoint=knn.kneighbors(Data_test[-1],5,False)
score=knn.score(Data_test,Labels_test,sample_weight=None)#呼叫該物件的打分方法,計算出準確率
print('Labels_predict = ')
print(Labels_predict )#輸出測驗的結果
print('Labels_test = ')
print(Labels_test)#輸出原始測驗資料集的正確標簽
print('Accuracy:',score)#輸出準確率計算結果
print(probility)
撰寫打磨課件不易,走過路過別忘記給咱點個贊,小女子在此(?′ω`?)謝過!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/179506.html
標籤:其他