Envoy Proxy 在大多數情況下都是作為 Sidecar 與應用部署在同一網路環境中,每個應用只需要與 Envoy(localhost)互動,不需要知道其他服務的地址,然而這并不是 Envoy 僅有的使用場景,它本身就是一個七層代理,通過模塊化結構實作了流量治理、資訊監控等核心功能,比如流量治理功能就包括自動重連、熔斷、全域限速、流量鏡像和例外檢測等多種高級功能,因此 Envoy 也常常被用于邊緣代理,比如 Istio 的 Ingress Gateway、基于 Envoy 實作的 Ingress Controller(Contour、Ambassador、Gloo 等),
我的博客也是部署在輕量級 Kubernetes 集群上的(其實是 k3s 啦),一開始使用 Contour 作為 Ingress Controller,暴露集群內的博客、評論等服務,但好景不長,由于我在集群內部署了各種奇奇怪怪的東西,有些個性化配置 Contour 無法滿足我的需求,畢竟大家都知道,每抽象一層就會丟失很多細節,換一個 Controller 保不齊以后還會遇到這種問題,索性就直接裸用 Envoy 作為邊緣代理,大不了手擼 YAML 唄,
當然也不全是手擼,雖然沒有所謂的控制平面,但儀式感還是要有的,我可以基于檔案來動態更新配置啊,具體的方法參考 Envoy 基礎教程:基于檔案系統動態更新配置,
1. UDS 介紹
說了那么多廢話,下面進入正題,為了提高博客的性能,我選擇將博客與 Envoy 部署在同一個節點上,并且全部使用 HostNetwork 模式,Envoy 通過 localhost 與博客所在的 Pod(Nginx) 通信,為了進一步提高性能,我盯上了 Unix Domain Socket(UDS,Unix域套接字),它還有另一個名字叫 IPC(inter-process communication,行程間通信),為了理解 UDS,我們先來建立一個簡單的模型,
現實世界中兩個人進行資訊交流的整個程序被稱作一次通信(Communication),通信的雙方被稱為端點(Endpoint),工具通訊環境的不同,端點之間可以選擇不同的工具進行通信,距離近可以直接對話,距離遠可以選擇打電話、微信聊天,這些工具就被稱為 Socket,
同理,在計算機中也有類似的概念:
- 在
Unix中,一次通信由兩個端點組成,例如HTTP服務端和HTTP客戶端, - 端點之間想要通信,必須借助某些工具,Unix 中端點之間使用
Socket來進行通信,
Socket 原本是為網路通信而設計的,但后來在 Socket 的框架上發展出一種 IPC 機制,就是 UDS,使用 UDS 的好處顯而易見:不需要經過網路協議堆疊,不需要打包拆包、計算校驗和、維護序號和應答等,只是將應用層資料從一個行程拷貝到另一個行程,這是因為,IPC 機制本質上是可靠的通訊,而網路協議是為不可靠的通訊設計的,
UDS 與網路 Socket 最明顯的區別在于,網路 Socket 地址是 IP 地址加埠號,而 UDS 的地址是一個 Socket 型別的檔案在檔案系統中的路徑,一般名字以 .sock 結尾,這個 Socket 檔案可以被系統行程參考,兩個行程可以同時打開一個 UDS 進行通信,而且這種通信方式只會發生在系統內核里,不會在網路上進行傳播,下面就來看看如何讓 Envoy 通過 UDS 與上游集群 Nginx 進行通信吧,它們之間的通信模型大概就是這個樣子:
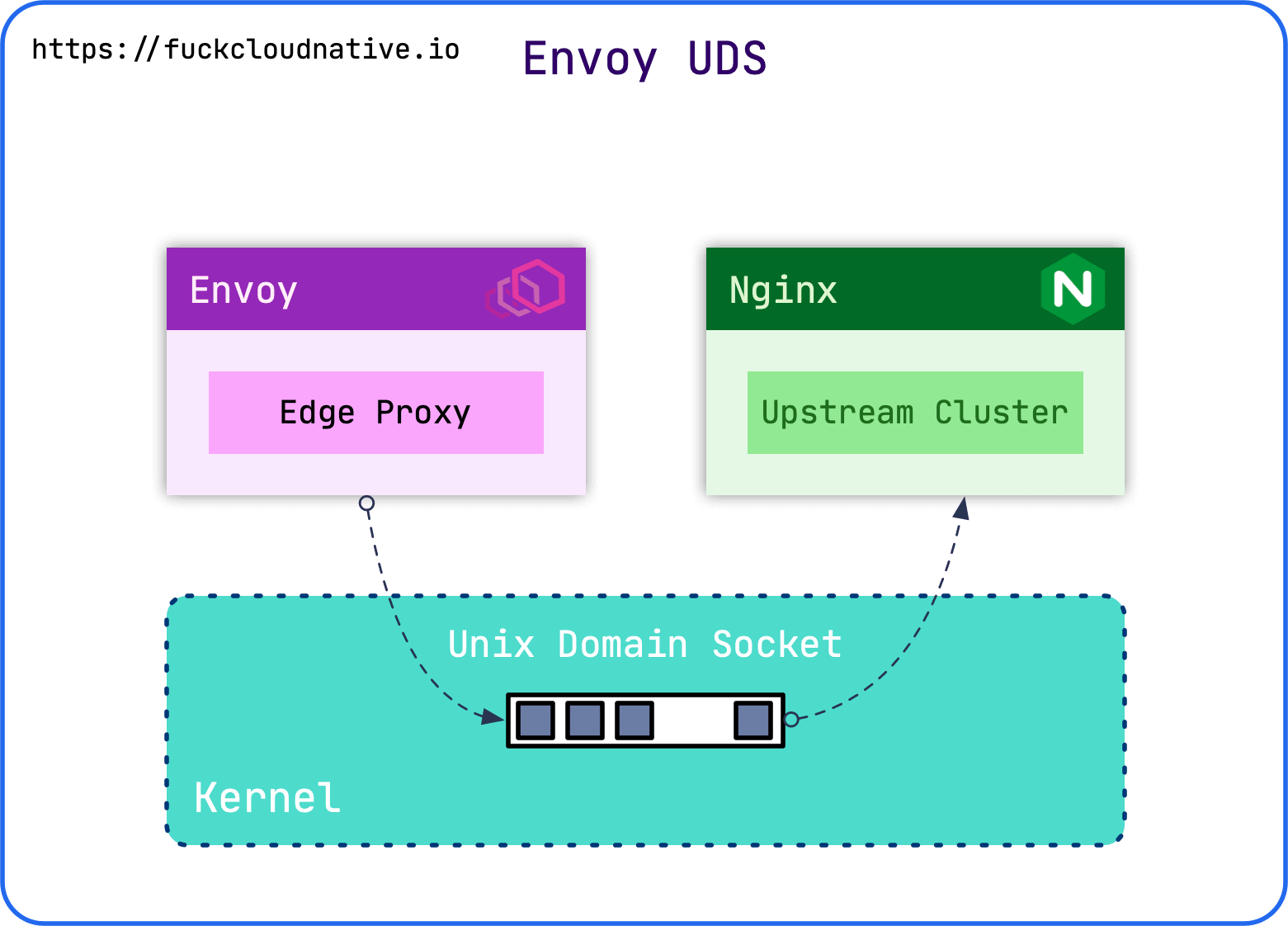
2. Nginx 監聽 UDS
首先需要修改 Nginx 的配置,讓其監聽在 UDS 上,至于 Socket 描述符檔案的存盤位置,就隨你的意了,具體需要修改 listen 引數為下面的形式:
listen unix:/sock/hugo.sock;
當然,如果想獲得更快的通信速度,可以放在 /dev/shm 目錄下,這個目錄是所謂的 tmpfs,它是 RAM 可以直接使用的區域,所以讀寫速度都會很快,下文會單獨說明,
3. Envoy-->UDS-->Nginx
Envoy 默認情況下是使用 IP 地址和埠號和上游集群通信的,如果想使用 UDS 與上游集群通信,首先需要修改服務發現的型別,將 type 修改為 static:
type: static
同時還需將端點定義為 UDS:
- endpoint:
address:
pipe:
path: "/sock/hugo.sock"
最終的 Cluster 配置如下:
- "@type": type.googleapis.com/envoy.api.v2.Cluster
name: hugo
connect_timeout: 15s
type: static
load_assignment:
cluster_name: hugo
endpoints:
- lb_endpoints:
- endpoint:
address:
pipe:
path: "/sock/hugo.sock"
最后要讓 Envoy 能夠訪問 Nginx 的 Socket 檔案,Kubernetes 中可以將同一個 emptyDir 掛載到兩個 Container 中來達到共享的目的,當然最大的前提是 Pod 中的 Container 是共享 IPC 的,配置如下:
spec:
...
template:
...
spec:
containers:
- name: envoy
...
volumeMounts:
- mountPath: /sock
name: hugo-socket
...
- name: hugo
...
volumeMounts:
- mountPath: /sock
name: hugo-socket
...
volumes:
...
- name: hugo-socket
emptyDir: {}
現在你又可以愉快地訪問我的博客了,查看 Envoy 的日志,成功將請求通過 Socket 轉發給了上游集群:
[2020-04-27T02:49:47.943Z] "GET /posts/prometheus-histograms/ HTTP/1.1" 200 - 0 169949 1 0 "66.249.64.209,45.145.38.4" "Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "9d490b2d-7c18-4dc7-b815-97f11bfc04d5" "fuckcloudnative.io" "/dev/shm/hugo.sock"
嘿嘿,Google 的爬蟲也來湊熱鬧,
你可能會問我:你這里的 Socket 為什么在 /dev/shm/ 目錄下啊?別急,還沒結束呢,先來補充一個背景知識,
4. Linux 共享記憶體機制
共享記憶體(shared memory),是 Linux 上一種用于行程間通信(IPC)的機制,
行程間通信可以使用管道,Socket,信號,信號量,訊息佇列等方式,但這些方式通常需要在用戶態、內核態之間拷貝,一般認為會有 4 次拷貝;相比之下,共享記憶體將記憶體直接映射到用戶態空間,即多個行程訪問同一塊記憶體,理論上性能更高,嘿嘿,又可以改進上面的方案了,
共享記憶體有兩種機制:
POSIX共享記憶體(shm_open()、shm_unlink())System V共享記憶體(shmget()、shmat()、shmdt())
其中,System V 共享記憶體歷史悠久,一般的 UNIX 系統上都有這套機制;而 POSIX 共享記憶體機制介面更加方便易用,一般是結合記憶體映射 mmap 使用,
mmap 和 System V 共享記憶體的主要區別在于:
- System V shm 是持久化的,除非被一個行程明確的洗掉,否則它始終存在于記憶體里,直到系統關機,
mmap映射的記憶體不是持久化的,如果行程關閉,映射隨即失效,除非事先已經映射到了一個檔案上,/dev/shm是 Linux 下 sysv 共享記憶體的默認掛載點,
POSIX 共享記憶體是基于 tmpfs 來實作的,實際上,更進一步,不僅 PSM(POSIX shared memory),而且 SSM(System V shared memory) 在內核也是基于 tmpfs 實作的,
從這里可以看到 tmpfs 主要有兩個作用:
- 用于
System V共享記憶體,還有匿名記憶體映射;這部分由內核管理,用戶不可見, - 用于
POSIX共享記憶體,由用戶負責mount,而且一般 mount 到/dev/shm,依賴于CONFIG_TMPFS,
雖然 System V 與 POSIX 共享記憶體都是通過 tmpfs 實作,但是受的限制卻不相同,也就是說 /proc/sys/kernel/shmmax 只會影響 System V 共享記憶體,/dev/shm 只會影響 POSIX 共享記憶體,實際上,System V 與 POSIX 共享記憶體本來就是使用的兩個不同的 tmpfs 實體,
System V 共享記憶體能夠使用的記憶體空間只受 /proc/sys/kernel/shmmax 限制;而用戶通過掛載的 /dev/shm,默認為物理記憶體的 1/2,
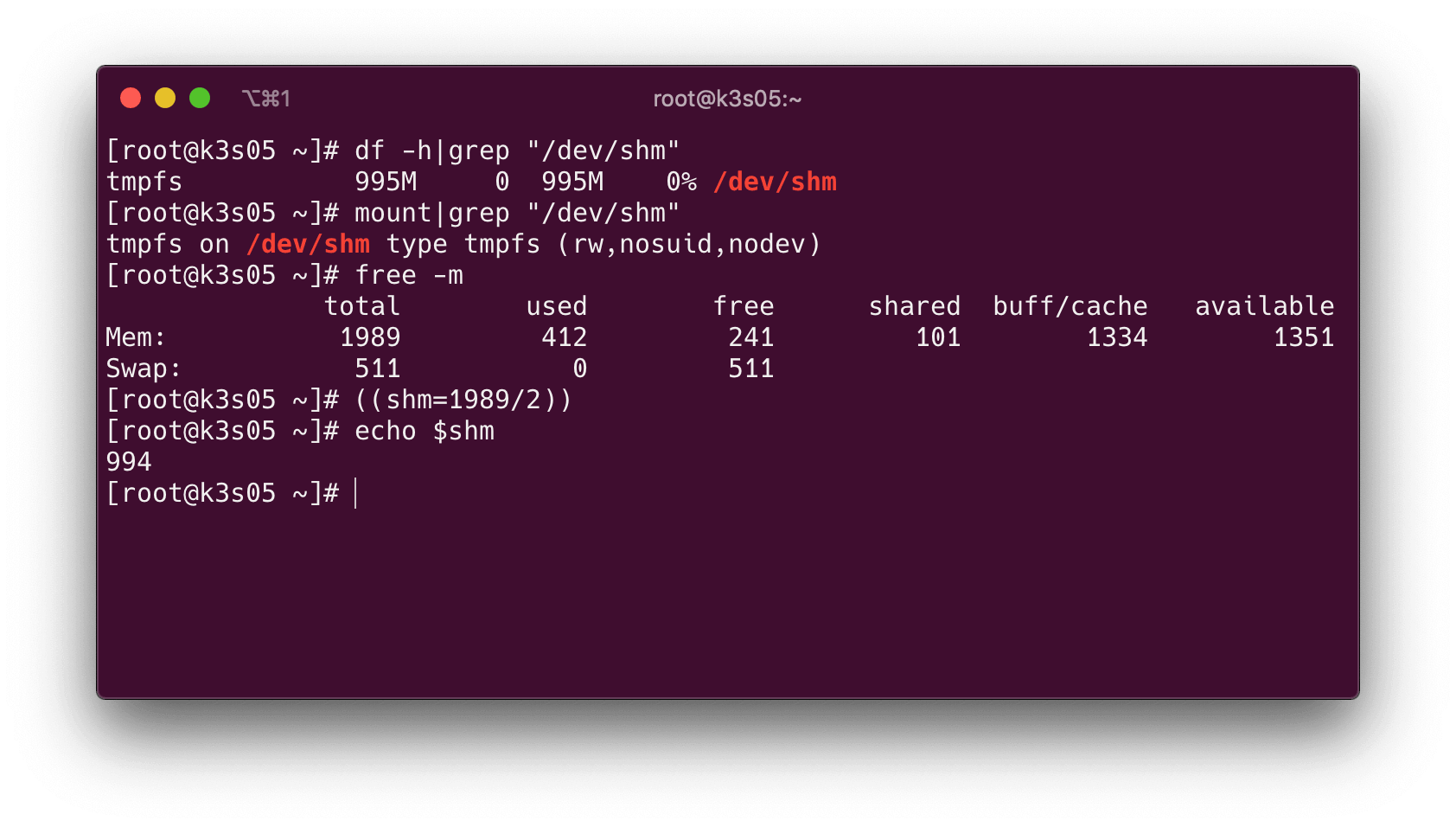
概括一下:
POSIX共享記憶體與System V共享記憶體在內核都是通過tmpfs實作,但對應兩個不同的tmpfs實體,相互獨立,- 通過
/proc/sys/kernel/shmmax可以限制System V共享記憶體的最大值,通過/dev/shm可以限制POSIX共享記憶體的最大值,
5. Kubernetes 共享記憶體
Kubernetes 創建的 Pod,其共享記憶體默認 64MB,且不可更改,
為什么是這個值呢?其實,Kubernetes 本身是沒有設定共享記憶體的大小的,64MB 其實是 Docker 默認的共享記憶體的大小,
Docker run 的時候,可以通過 --shm-size 來設定共享記憶體的大小:
?? → docker run --rm centos:7 df -h |grep shm
shm 64M 0 64M 0% /dev/shm
?? → docker run --rm --shm-size 128M centos:7 df -h |grep shm
shm 128M 0 128M 0% /dev/shm
然而,Kubernetes 并沒有提供設定 shm 大小的途徑,在這個 issue 里社區討論了很久是否要給 shm 增加一個引數,但是最終并沒有形成結論,只是有一個 workgroud 的辦法:將 Memory 型別的 emptyDir 掛載到 /dev/shm 來解決,
Kubernetes 提供了一種特殊的 emptyDir:可以將 emptyDir.medium 欄位設定為 "Memory",以告訴 Kubernetes 使用 tmpfs(基于 RAM 的檔案系統)作為介質,用戶可以將 Memory 介質的 emptyDir 掛到任何目錄,然后將這個目錄當作一個高性能的檔案系統來使用,當然也可以掛載到 /dev/shm,這樣就可以解決共享記憶體不夠用的問題了,
使用 emptyDir 雖然可以解決問題,但也是有缺點的:
- 不能及時禁止用戶使用記憶體,雖然過 1~2 分鐘
Kubelet會將Pod擠出,但是這個時間內,其實對Node還是有風險的, - 影響 Kubernetes 調度,因為
emptyDir并不涉及 Node 的Resources,這樣會造成 Pod “偷偷”使用了 Node 的記憶體,但是調度器并不知曉, - 用戶不能及時感知到記憶體不可用,
由于共享記憶體也會受 Cgroup 限制,我們只需要給 Pod 設定 Memory limits 就可以了,如果將 Pod 的 Memory limits 設定為共享記憶體的大小,就會遇到一個問題:當共享記憶體被耗盡時,任何命令都無法執行,只能等超時后被 Kubelet 驅逐,
這個問題也很好解決,將共享記憶體的大小設定為 Memory limits 的 50% 就好,綜合以上分析,最終設計如下:
- 將 Memory 介質的
emptyDir掛載到/dev/shm/, - 配置 Pod 的
Memory limits, - 配置
emptyDir的sizeLimit為Memory limits的 50%,
6. 最終配置
根據上面的設計,最終的配置如下,
Nginx 的配置改為:
listen unix:/dev/shm/hugo.sock;
Envoy 的配置改為:
- "@type": type.googleapis.com/envoy.api.v2.Cluster
name: hugo
connect_timeout: 15s
type: static
load_assignment:
cluster_name: hugo
endpoints:
- lb_endpoints:
- endpoint:
address:
pipe:
path: "/dev/shm/hugo.sock"
Kubernetes 的 manifest 改為:
spec:
...
template:
...
spec:
containers:
- name: envoy
resources:
limits:
memory: 256Mi
...
volumeMounts:
- mountPath: /dev/shm
name: hugo-socket
...
- name: hugo
resources:
limits:
memory: 256Mi
...
volumeMounts:
- mountPath: /dev/shm
name: hugo-socket
...
volumes:
...
- name: hugo-socket
emptyDir:
medium: Memory
sizeLimit: 128Mi
7. 參考資料
- 設定kubernetes Pod的shared memory
- Kubernetes中Pod間共享記憶體方案
微信公眾號
掃一掃下面的二維碼關注微信公眾號,在公眾號中回復?加群?即可加入我們的云原生交流群,和孫宏亮、張館長、陽明等大佬一起探討云原生技術

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/18012.html
標籤:其他