Kafka一般被稱為“分布式提交日志”或者“分布式流平臺”,檔案系統或資料庫提交日志用來提供所有事務的持久記錄,通過重放這些日志可以重建系統的狀態,同樣地,Kafka的資料是按照一定順序持久化保存的,可以按需讀取,此外,Kafka的資料分布在整個系統里,具備資料故障保護和性能伸縮能力,
1.2.1 訊息和批次
Kafka的資料單元被稱為訊息,為了提高效率,訊息被分批次寫入Kafka,批次就是一組訊息,這些訊息屬于同一個主題和磁區,如果每一個訊息都單獨穿行于網路,會導致大量的網路開銷,把訊息分成批次傳輸可以減少網路開銷,不過,這要在時間延遲和吞吐量之間做出權衡:批次越大,單位時間內處理的訊息就越多,單個訊息的傳輸時間就越長,
1.2.2 模式
訊息模式有許多可用的選項,像JSON和XML,易用可讀性好,但缺乏強型別處理能力,版本間兼容性也不是很好,
資料格式的一致性對于Kafka來說很重要,它消除了訊息讀寫操作之間的耦合性,如果讀寫操作緊密的耦合在一起,訊息訂閱者需要升級應用程式才能同時處理新舊兩種資料格式,在訊息訂閱者升級了之后,訊息發布者才能跟著升級,以便使用新的資料格式,
1.2.3 主題和磁區
Kafka的訊息通過主題進行分類,主題可以被分為若干個磁區,一個磁區就是一個提交日志,訊息以追加的方式寫入磁區,然后以先入先出的順序讀取,要注意,由于一個主題一般包含幾個磁區,因此無法在整個主題范圍內保證訊息的順序,但可以保證訊息在單個磁區內的順序,
Kafka通過磁區來實作資料冗余和伸縮性,磁區可以分布在不同的服務器上,一個主題可以橫跨多個服務器,以此來提供比單個服務器更強大的性能,

流是一組從生產者移動到消費者的資料,
1.2.4 生產者和消費者
Kafka的客戶端被分為兩種基本型別:生產者和消費者,此外還有高級客戶端API,用于資料集成的Kafka Connect API和用于流式處理的Kafka Streams,
偏移量是一種元資料,它是一個遞增的整數值,保存在Zookeeper或Kafka上,消費者關倍訓者重啟,讀取狀態不會丟失,
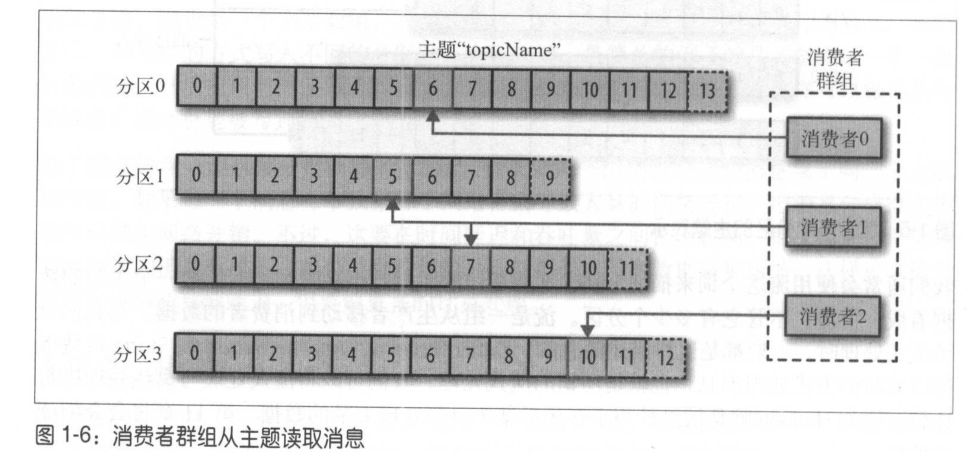
消費者是消費者群組的一部分,也就是說,會有一個或者多個消費者共同讀取一個主題,群組保證每個磁區只能被一個消費者使用,消費者與磁區之間的映射通常被稱為消費者對磁區的所有權關系,通過這種方式,消費者可以消費包含大量訊息的主題,而且,如果一個消費者失效,群組里的其他消費者可以接管失效消費者的作業,
1.2.5 broker和集群
一個獨立的Kafka服務器被稱為broker,根據特定的硬體及其性能特征,單個broker可以輕松處理數千個磁區以及每秒百萬級的訊息量,
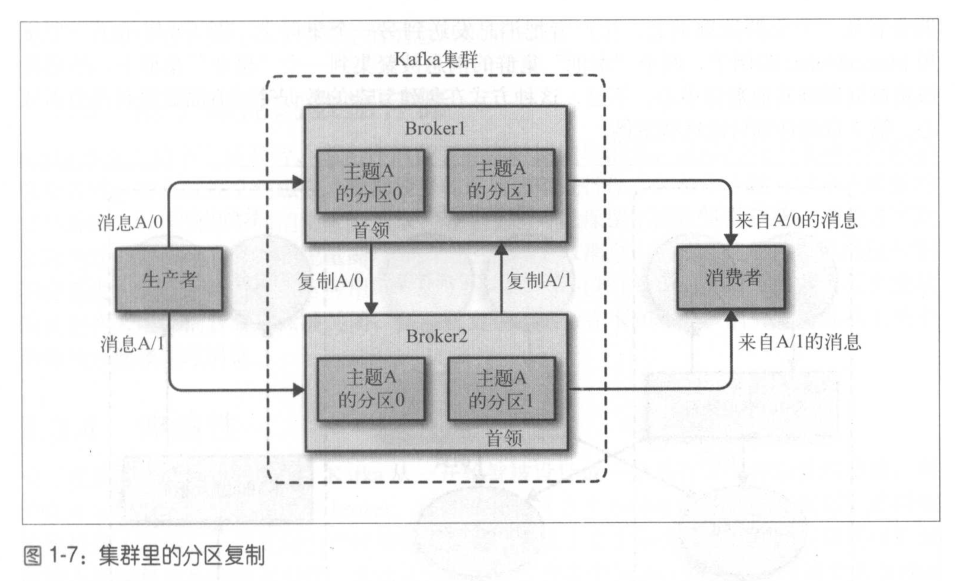
broker是集群的組成部分,每個集群都有一個broker同時充當了集群控制器的角色,控制器負責管理作業,包括將磁區分配給broker和監控broker,在集群中,一個磁區從屬于一個broker,該broker被稱為磁區的首領,一個磁區可以分配給多個broker,這個時候會發生磁區復制,這種復制機制為磁區提供了訊息冗余,如果一個broker失效,其他broker可以接管領導權,不過,相關的消費者和生產者都需要重新連接到新的首領,
保留訊息(在一定期限內)是Kafka的一個重要特性,Kafka broker默認的訊息保留策略:要么保留一段時間(比如7天),要么保留到訊息達到一定大小的位元組數(比如1GB),當訊息數量達到這些上限時,舊訊息就會過期并洗掉,主題可以配置自己的保留策略,可以將訊息保留到不再使用它們為止,
1.2.6 多集群
基于以下原因,最好使用多個集群,
- 資料型別分離
- 安全需求隔離
- 多資料中心(災難恢復)
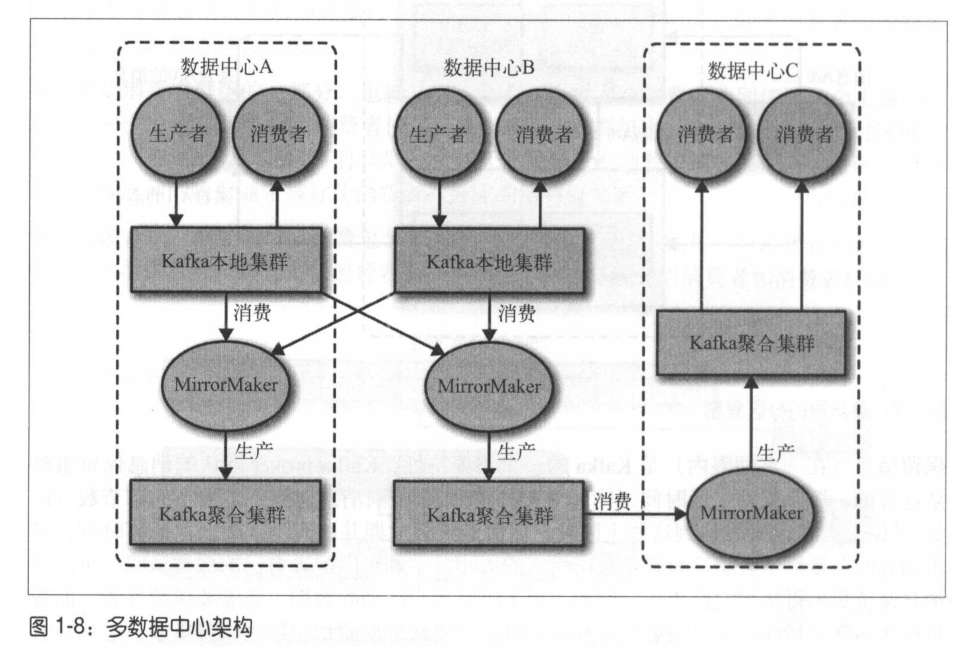
Kafka的訊息復制機制只能在單個集群里進行,Kafka提供了一個MirrorMaker的工具,可以用來實作集群間的訊息復制,MirrorMaker的核心組件包含了一個生產者和一個消費者,兩者通過一個佇列相連,
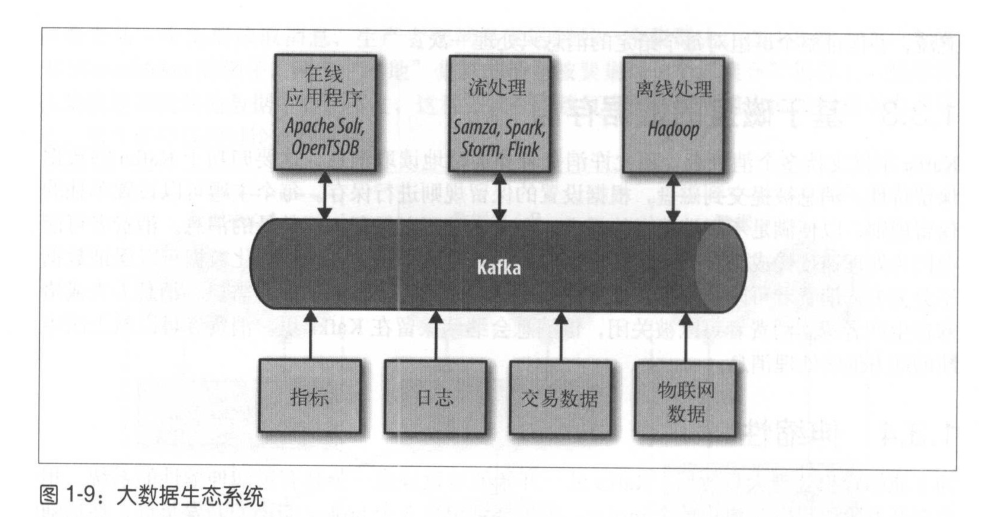
使用場景:1,活動跟蹤;2,傳遞訊息;3,度量指標和日志記錄;4,提交日志;5,流處理
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/180427.html
標籤:其他