作者|Zijing Zhu
編譯|VK
來源|Towards Datas Science

據估計,世界上80%的資料是非結構化的,因此,從非結構化資料中提取資訊是資料分析的重要組成部分,
文本挖掘是從非結構化文本資料中獲取有價值的資訊的程序,情感分析是文本挖掘的應用之一,它使用自然語言處理和機器學習技術從文本資料中理解和分類情緒,在商業環境中,情緒分析廣泛應用于了解客戶評論、從電子郵件中檢測垃圾郵件等,
本文是本教程的第一部分,介紹了使用Python進行情緒分析的具體技術,為了更好地說明程式,我將以我的一個專案為例,對WTI原油期貨價格進行新聞情緒分析,我將介紹重要的步驟以及相應的Python代碼,
一些背景資料
原油期貨價格短期內有較大波動,任何產品的長期均衡都是由供求狀況決定的,而價格的短期波動則反映了市場對該產品的信心和預期,在本專案中,我利用與原油相關的新聞文章來捕捉不斷更新的市場信心和預期,并通過對新聞文章進行情緒分析來預測未來原油價格的變化,以下是完成此分析的步驟:
1、收集資料:網路抓取新聞文章
2、文本資料預處理(本文)
3、文本矢量化:TFIDF
4、用logistic回歸進行情緒分析
5、使用python flask web app在Heroku部署模型
我將討論第二部分,即本文中文本資料的預處理,如果你對其他部分感興趣,請繼續閱讀,
文本資料預處理
我使用NLTK、Spacy和一些正則運算式中的工具來預處理新聞文章,要匯入庫并使用Spacy中的預構建模型,可以使用以下代碼:
import spacy
import nltk
# 初始化spacy'en'模型
nlp = spacy.load(‘en’, disable=[‘parser’, ‘ner’])
之后,我用Pandas讀入資料:
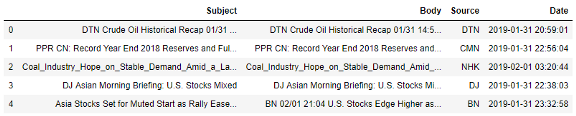
“Subject”和“Body”是我將應用文本預處理程序的列,我按照標準的文本挖掘程序對新聞文章進行預處理,以從新聞內容中提取有用的特征,包括標識化、洗掉停用詞和詞形還原,
標識化
文本資料預處理的第一步是將每個句子分解成單獨的單詞,這稱為標識化,使用單個單詞而不是句子會破壞單詞之間的聯系,然而,這卻是一種常用的方法,計算機通過檢查文章中出現的單詞和這些單詞出現的次數來分析文本資料是比較高效和方便的,并且足以得出有價值的結果,
以我的資料集中的第一篇新聞文章為例:
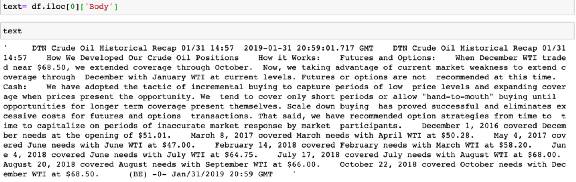
可以使用NLTK tokenizer:
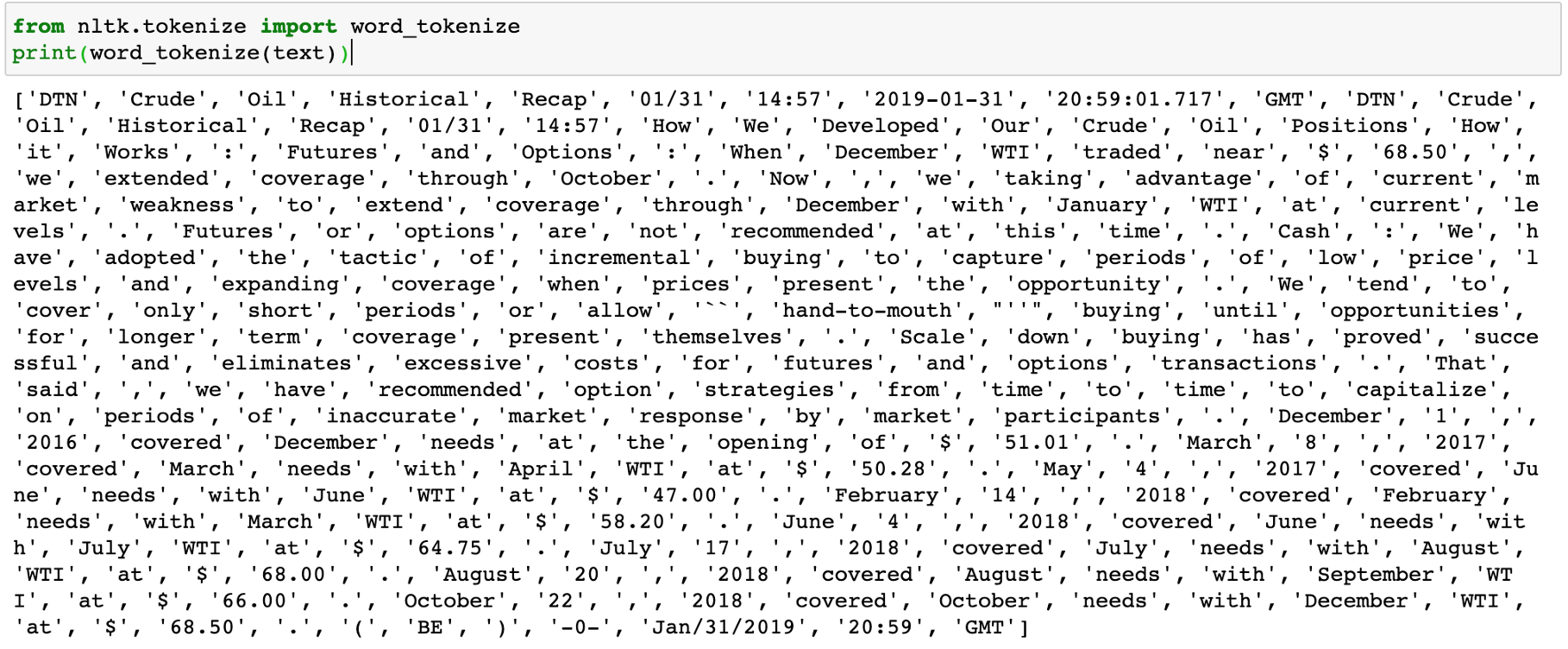
或者可以使用Spacy,記住nlp是上面定義的Spacy引擎:

標識化之后,每一篇新聞文章都將轉換成一個單詞、符號、數字和標點符號的串列,你可以指定是否也要將每個單詞都轉換為小寫,下一步是洗掉無用資訊,例如,符號、數字、標點符號,我將使用spacy和regex組合來洗掉它們,
import re
#標識化和洗掉標點
words = [str(token) for token in nlp(text) if not token.is_punct]
#洗掉數字和其他符號,但“@”除外--用于洗掉電子郵件
words = [re.sub(r"[^A-Za-z@]", "", word) for word in words]
#洗掉網站和電子郵件地址
words = [re.sub(r”\S+com”, “”, word) for word in words]
words = [re.sub(r”\S+@\S+”, “”, word) for word in words]
#洗掉空白
words = [word for word in words if word!=’ ‘]
應用上述轉換后,原始新聞文章如下所示:

停用詞
經過一番改造,新聞文章干凈多了,但我們還是看到了一些我們不希望看到的詞,比如“and”、“we”等,下一步就是去掉無用的詞,即停用詞,
停用詞是在許多文章中經常出現但沒有意義的詞,stopword的例子有“I”、“the”、“a”、“of”,這些字眼如果洗掉,將不會影響對文章的理解,要洗掉stopwords,我們可以從NLTK庫匯入stopwords,
此外,我還列出了其他在經濟分析中廣泛使用的停用詞串列,包括日期和時間,更一般的沒有經濟意義的單詞,等等,以下是我如何構建停用詞串列的方法:
#匯入其他停用詞串列
with open(‘StopWords_GenericLong.txt’, ‘r’) as f:
x_gl = f.readlines()
with open(‘StopWords_Names.txt’, ‘r’) as f:
x_n = f.readlines()
with open(‘StopWords_DatesandNumbers.txt’, ‘r’) as f:
x_d = f.readlines()
#匯入nltk停用詞
stopwords = nltk.corpus.stopwords.words(‘english’)
#合并所有停用詞
[stopwords.append(x.rstrip()) for x in x_gl][stopwords.append(x.rstrip()) for x in x_n][stopwords.append(x.rstrip()) for x in x_d]
#將所有停用詞改為小寫
stopwords_lower = [s.lower() for s in stopwords]
然后從新聞文章中排除停用詞:
words = [word.lower() for word in words if word.lower() not in stopwords_lower]
應用于上一個示例,其外觀如下:

詞形還原
除去停止字,以及符號、數字和標點符號后,我們要把每一篇新聞文章的單詞進行詞形還原,我們必須去掉語法時態并將每個單詞轉換成其原始形式,
例如,如果我們想計算一篇新聞文章中出現“open”一詞的次數,我們需要計算“open”、“opens”、“opened”的出現次數,因此,詞形還原是文本轉換的一個重要步驟,另一種將單詞轉換成原始形式的方法叫做詞干提取,它們之間的區別是:

詞形還原是把一個詞引入它原來的詞形中,詞干提取是把一個詞的詞根提取出來(可能直接去掉前綴后綴),我選擇詞形還原而不是詞干提取,因為詞干提取后,有些詞變得很難理解,從解釋的角度來說,詞形還原比詞干提取好,
上面的引理很容易實作,在詞形還原之后,每一篇新聞文章都將轉換成一個詞的串列,這些詞都是原來的形式,新聞文章現在改成這樣:

總結
讓我們總結一下函式中的步驟,并在所有文章中應用該函式:
def text_preprocessing(str_input):
#標識化,洗掉標點,詞形還原
words=[token.lemma_ for token in nlp(str_input) if not token.is_punct]
#洗掉符號、網站、電子郵件地址
words = [re.sub(r”[^A-Za-z@]”, “”, word) for word in words]
words = [re.sub(r”\S+com”, “”, word) for word in words]
words = [re.sub(r”\S+@\S+”, “”, word) for word in words]
words = [word for word in words if word!=’ ‘]
words = [word for word in words if len(word)!=0]
#洗掉停用字
words=[word.lower() for word in words if word.lower() not in stopwords_lower]
#將串列合并為一個字串
string = " ".join(words)
return string
在這里,文本預處理與前面的所有預處理步驟相結合:

在將其推廣到所有新聞文章之前,重要的是將其應用于隨機新聞文章,并查看其作業原理,遵循以下代碼:
import random
index = random.randint(0, df.shape[0])
text_preprocessing(df.iloc[index][‘Body’])
如果你想為此特定專案排除一些額外的單詞,或者你想洗掉一些多余的資訊,你可以在應用于所有新聞文章之前修改函式,這是一篇隨機選取的新聞文章,在標識化前后,去掉了停用詞和詞形還原,
預處理前的新聞文章:

預處理后的新聞文章

如果可以,你可以將所有文章都應用于以下函式:
df[‘news_cleaned’]=df[‘Body’].apply(text_preprocessing)
df[‘subject_cleaned’]=df[‘Subject’].apply(text_preprocessing)
結論
文本預處理是文本挖掘和情感分析的重要組成部分,有很多方法可以對非結構化資料進行預處理,使其可讀,便于計算機將來分析,下一步,我將討論用于將文本資料轉換為稀疏矩陣,以便它們可以用作定量分析的輸入,
如果你的分析很簡單,并且不需要在預處理文本資料時進行大量定制,那么vectorizers通常具有內嵌函式來執行基本步驟,比如標識化、洗掉stopwords,或者你可以撰寫自己的函式,并在向量化器中指定自定義函式,這樣就可以同時對資料進行預處理和向量化,
如果你希望這樣做,那么你的函式需要回傳一個經過標記化的單詞串列,而不是一個長字串,但是,就個人而言,我更喜歡在向量化之前先對文本資料進行預處理,通過這種方式,我一直在監視函式的性能,而且它實際上會更快,特別是當你有一個大的資料集時,
原文鏈接:https://towardsdatascience.com/a-step-by-step-tutorial-for-conducting-sentiment-analysis-a7190a444366
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/180927.html
標籤:其他
上一篇:避免使用對抗性T恤進行檢測