
論文:MuCAN:多對應聚合的視頻超分
文章檢索出處: 2020 ECCV
摘要和簡介
本文提出了:
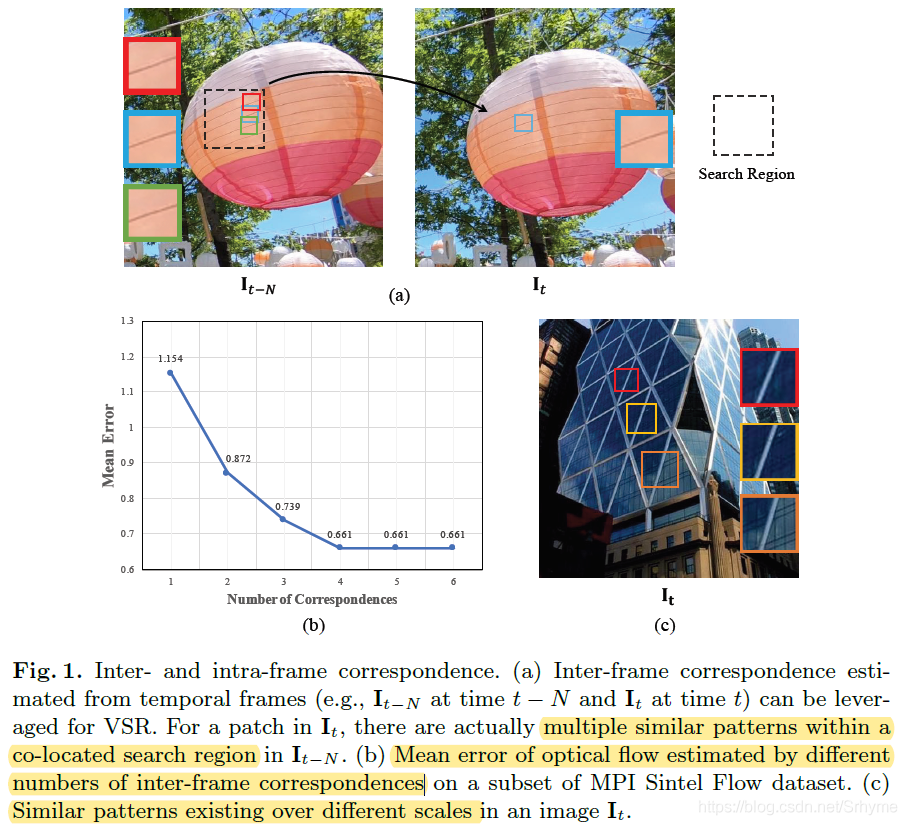
1. 一種時間多對應聚合(TM-CAM)策略,去利用跨幀的相似補丁
2. 一種跨尺度的非區域對應的聚合(CN-CAM)方案,去探索幀內不同尺度的自相似性
3. 引入了邊緣感知損失,使所提議的網路能夠生成更好的邊緣
基于上述,我們建立了一個有效的多對應聚合網路(MuCAN),實作了SOTR,
模型
overview
輸入2N+1個連續幀去預測中心幀,模型由三部分構成:TM-CAM、CN-CAM和重構模塊,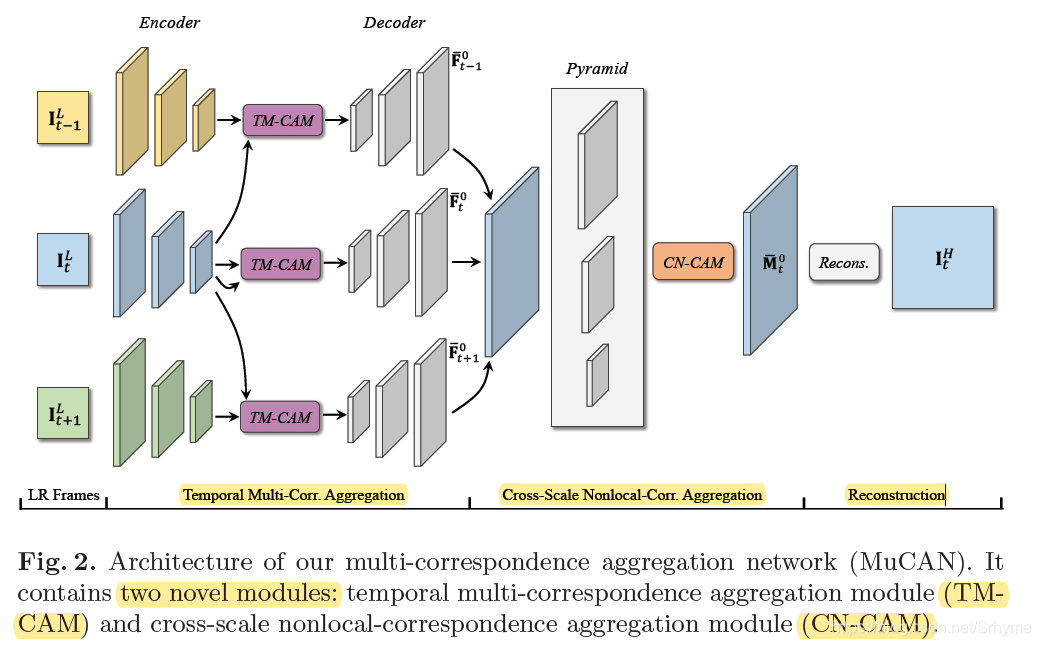
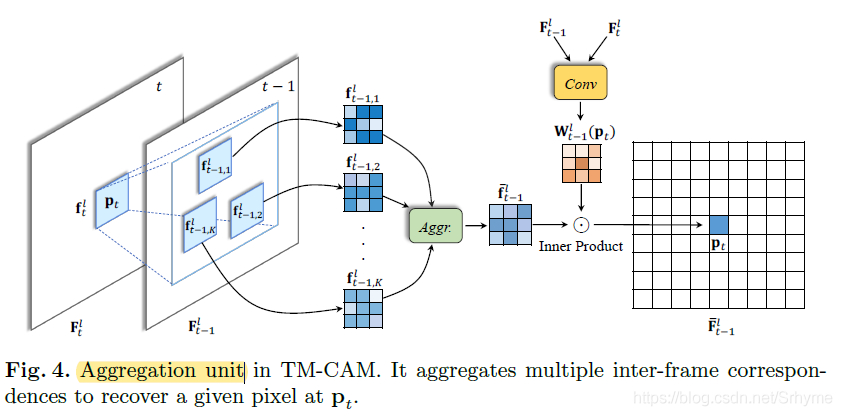
時間多對應聚合模塊
給定兩個相鄰的LR幀
I
t
?
1
L
I_{t-1}^{L}
It?1L?和
I
t
L
I_{t}^{L}
ItL?,先將它們編碼為較低的解析度(從
l
0
l_0
l0?到
l
2
l_2
l2?),然后,聚合從較低解析度開始(
F
 ̄
t
?
1
l
=
2
\overline F_{t-1}^{l=2}
Ft?1l=2?)以補償大運動,逐漸向上移動至較高解析度(
F
 ̄
t
?
1
l
=
0
\overline F_{t-1}^{l=0}
Ft?1l=0?)用于細微的亞像素移動,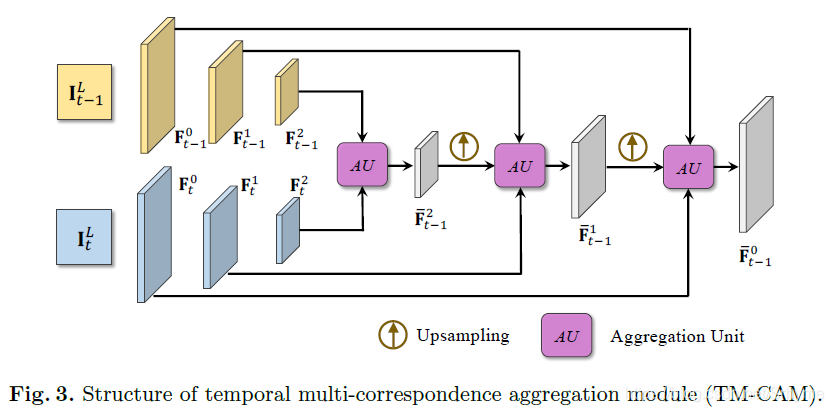
上述中的每個聚合單元使用基于補丁的匹配策略,我們匯總多個候選者以充分獲取背景關系資訊,具體的說,首先選擇top-K個最相似的特征補丁,然后使用像素自適應聚合方法把他們融合為一個像素,以對齊
F
t
?
1
l
F_{t-1}^{l}
Ft?1l?和
F
t
l
F_{t}^{l}
Ftl?為例,在
F
t
l
F_{t}^{l}
Ftl?中取一個影像補丁
f
t
l
f_t^l
ftl?(表示為特征向量),然后在
F
t
?
1
l
F_{t-1}^{l}
Ft?1l?中取最接近的neighbors,使用相關性作為距離度量,相關性定義為歸一化距離內積: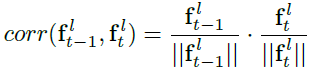 為了效率,區域搜索區域需滿足
∣
P
t
?
P
t
?
1
∣
≤
d
|P_t-P_{t-1}|≤d
∣Pt??Pt?1?∣≤d,其中
P
t
P_t
Pt?是
f
t
l
f_t^l
ftl?的位置向量,d表示最大距離,在計算了所有的相關性之后,降序選擇前K個最相關補丁,并將它們串聯和聚合起來:
為了效率,區域搜索區域需滿足
∣
P
t
?
P
t
?
1
∣
≤
d
|P_t-P_{t-1}|≤d
∣Pt??Pt?1?∣≤d,其中
P
t
P_t
Pt?是
f
t
l
f_t^l
ftl?的位置向量,d表示最大距離,在計算了所有的相關性之后,降序選擇前K個最相關補丁,并將它們串聯和聚合起來:
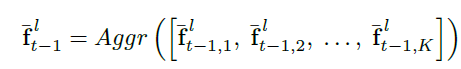 其中
A
g
g
r
Aggr
Aggr為卷積層,對于
f
 ̄
t
?
1
l
\overline f^{l}_{t-1}
f?t?1l?中的每個像素,我們設計了一種自適應聚合策略而不是相等的權重去進行聚合,權重圖是串聯
F
t
?
1
l
F_{t-1}^{l}
Ft?1l?與
F
t
l
F_t^l
Ftl?后通過一個卷積層獲得的,當補丁大小為S x S時,權重圖的Size為H x W x
S
2
S^2
S2:
其中
A
g
g
r
Aggr
Aggr為卷積層,對于
f
 ̄
t
?
1
l
\overline f^{l}_{t-1}
f?t?1l?中的每個像素,我們設計了一種自適應聚合策略而不是相等的權重去進行聚合,權重圖是串聯
F
t
?
1
l
F_{t-1}^{l}
Ft?1l?與
F
t
l
F_t^l
Ftl?后通過一個卷積層獲得的,當補丁大小為S x S時,權重圖的Size為H x W x
S
2
S^2
S2: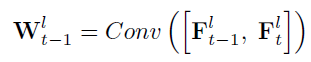 對齊的相鄰幀
F
 ̄
t
?
1
l
\overline F_{t-1}^{l}
Ft?1l?上的位置
P
t
P_t
Pt?的最終值為:
對齊的相鄰幀
F
 ̄
t
?
1
l
\overline F_{t-1}^{l}
Ft?1l?上的位置
P
t
P_t
Pt?的最終值為: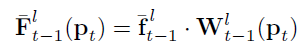 重復2N次上述步驟,我們得到一組對齊的相鄰特征圖{
F
t
?
N
l
,
.
.
.
,
F
t
?
1
l
,
F
t
+
1
l
,
.
.
.
,
F
t
+
N
l
F^{l}_{t-N},...,F^{l}_{t-1},F^{l}_{t+1},...,F^{l}_{t+N}
Ft?Nl?,...,Ft?1l?,Ft+1l?,...,Ft+Nl?},我們以
I
t
L
I_{t}^{L}
ItL?為輸入進行自聚合去產生
F
 ̄
t
0
\overline F_t^0
Ft0?,將這些特征圖通過卷積和PixelShuffle操作融合成一個雙空間大小的特征圖,以保持亞像素細節,
重復2N次上述步驟,我們得到一組對齊的相鄰特征圖{
F
t
?
N
l
,
.
.
.
,
F
t
?
1
l
,
F
t
+
1
l
,
.
.
.
,
F
t
+
N
l
F^{l}_{t-N},...,F^{l}_{t-1},F^{l}_{t+1},...,F^{l}_{t+N}
Ft?Nl?,...,Ft?1l?,Ft+1l?,...,Ft+Nl?},我們以
I
t
L
I_{t}^{L}
ItL?為輸入進行自聚合去產生
F
 ̄
t
0
\overline F_t^0
Ft0?,將這些特征圖通過卷積和PixelShuffle操作融合成一個雙空間大小的特征圖,以保持亞像素細節,
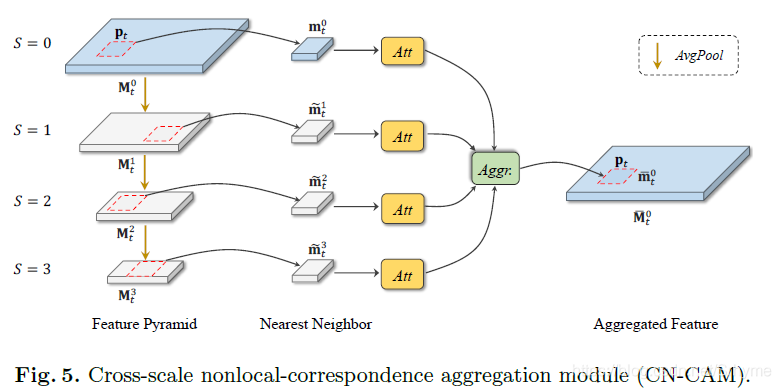
跨尺度的非區域對應聚合模型
我們使用
M
t
s
M_t^s
Mts?代表t時刻的特征圖,我們對特征圖進行下采樣得到一個特征金字塔:
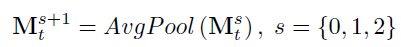 其中
A
v
g
P
o
o
l
AvgPool
AvgPool是步長為2的平均池化,在
M
t
0
M_t^0
Mt0?中給定一個以
p
t
p_t
pt?為中心的補丁
m
t
0
m_t^0
mt0?,我們在其他三個尺度上進行非區域搜索:
其中
A
v
g
P
o
o
l
AvgPool
AvgPool是步長為2的平均池化,在
M
t
0
M_t^0
Mt0?中給定一個以
p
t
p_t
pt?為中心的補丁
m
t
0
m_t^0
mt0?,我們在其他三個尺度上進行非區域搜索: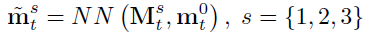 其中,
m
~
t
s
\tilde m^s_t
m~ts?代表對于
m
t
0
m_t^0
mt0?最鄰近的補丁,在合并之前,利用自我注意模塊來確定資訊是否有用,最終,
m
 ̄
t
0
\overline m_t^0
mt0?被計算為:
其中,
m
~
t
s
\tilde m^s_t
m~ts?代表對于
m
t
0
m_t^0
mt0?最鄰近的補丁,在合并之前,利用自我注意模塊來確定資訊是否有用,最終,
m
 ̄
t
0
\overline m_t^0
mt0?被計算為: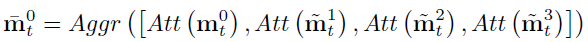 其中
A
t
t
Att
Att是注意力單元,Aggr是卷積層,
其中
A
t
t
Att
Att是注意力單元,Aggr是卷積層,
邊緣感知損失
VSR方法重建的高解析度影像往往是由鋸齒狀邊緣提取的,為了減輕這個問題,我們提出了一種邊緣感知的損失,以產生更好的再生邊緣,首先利用邊緣檢測器提取地面真實HR影像的邊緣資訊,然后對檢測到的邊緣區域進行加權,使得網路在學習程序中更加重視這些區域,
本文選用拉普拉斯變換作為邊緣檢測器,給定地面真實資訊
I
t
H
I^H_t
ItH?,由探測器得到邊緣映射
I
t
E
I^E_t
ItE?,在
p
t
p_t
pt? 處的二進制掩碼值表示為: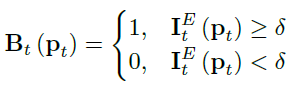 其中
δ
\delta
δ是閾值,訓練時,我們采用Charbonnier損失,定義為:
其中
δ
\delta
δ是閾值,訓練時,我們采用Charbonnier損失,定義為: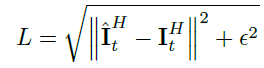 其中
I
^
t
H
\hat I^H_t
I^tH?是預測的HR結果,
?
\epsilon
?是常量,最終的損失定義為:
其中
I
^
t
H
\hat I^H_t
I^tH?是預測的HR結果,
?
\epsilon
?是常量,最終的損失定義為: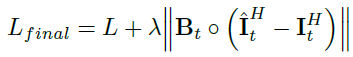 其中○代表的是元素相乘,
其中○代表的是元素相乘,
經驗
資料集
REDS共有300個視頻序列,我們將資料分成新的訓練(266個序列)和測驗(4個序列)資料集,新的測驗部件包含000,011,015和020序列,
Vimeo-90K中訓練和測驗分別包含64612和7824個視頻序列,
在我們的實驗中,峰值信噪比(PSNR)和結構相似性指數(SSIM)被用作衡量指標,
實施細節
網路以5(或7)個連續幀作為輸入,在特征提取和重建模塊中,分別使用5個和40個(7幀為20個)殘差塊,通道數量為128,在圖3中,補丁大小為3,最大位移從低到高設定為{3,5,7},K值設定為4,在跨尺度聚合模塊中,我們將補丁大小設為1,并融合來自4個尺度的資訊,
培訓我們使用8個NVIDIA GeForce GTX 1080Ti GPU來訓練我們的網路,每個GPU的小批量大小為3,訓練需要對所有資料集進行6000k次迭代,我們使用Adam作為優化器,使用學習速率衰減策略且初始值為
4
e
?
4
4e-4
4e?4,對輸入影像進行隨機裁剪、翻轉和旋轉增強,裁剪尺寸為64 x 64,對應輸出尺寸256 x 256,旋轉選擇為90 ℃或
?
90
℃
-90℃
?90℃,在計算邊緣感知損耗時,我們將
δ
\delta
δ和
λ
\lambda
λ都設定為0.1,測驗集評估時不使用邊界剪裁,
消融實驗
本實驗中為了方便,我們采用輕量級設定,在這一節中,將通道大小設定為64,重構模塊包含10個殘差塊,同時,訓練迭代的數量減少到200K,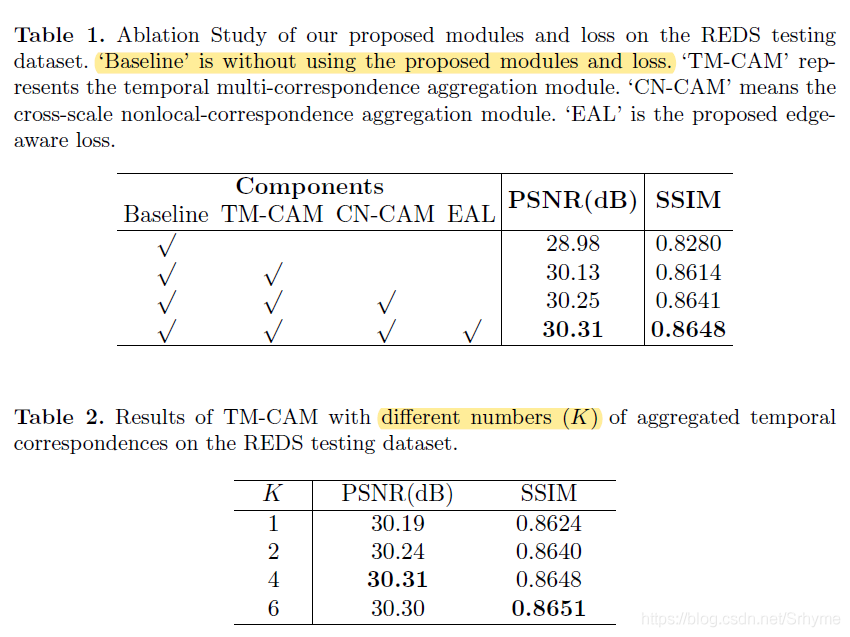
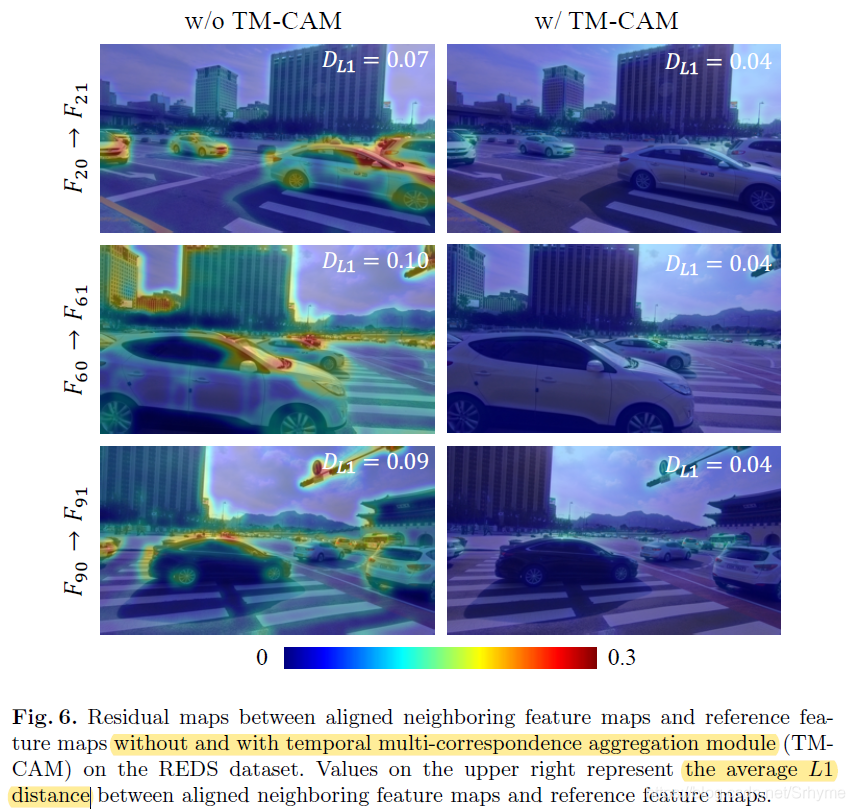
有無TM-CAM模塊的殘差圖可視化與平均L1距離:

與SOTR模型的對比
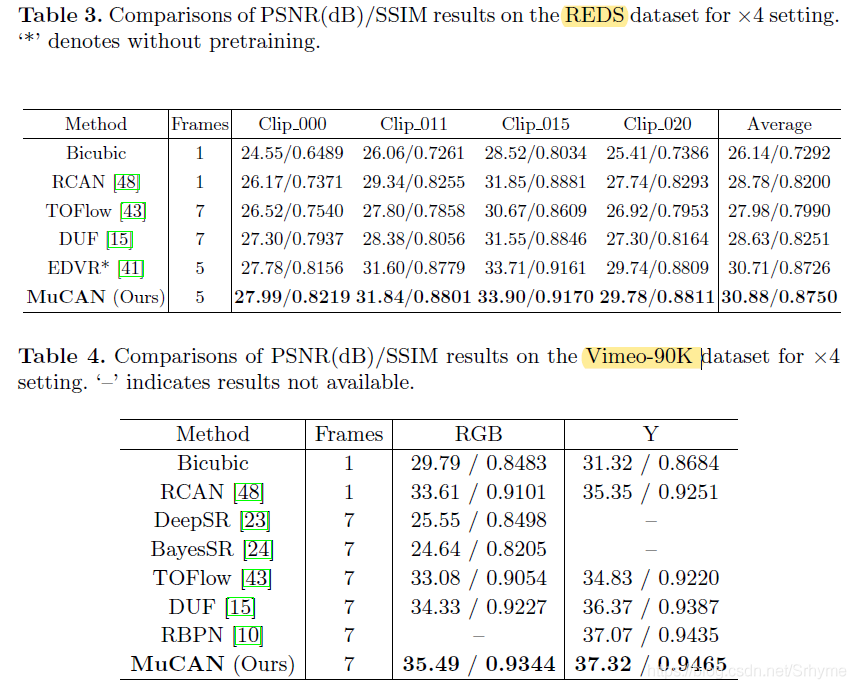
模型對比可視化:
僅供學習使用,請勿轉載,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/181316.html
標籤:AI
上一篇:【數量技術宅|量化投資策略系列分享】多周期共振交易策略
下一篇:總結第七周