目錄
一、前言:詞性標注
二、經典維特比演算法(Viterbi)
三、演算法實作
四、完整代碼
五、效果演示:
六、總結
一、前言:詞性標注
詞性標注(Part-Of-Speech tagging, POS tagging),是語料庫語言學中將語料庫中單詞的詞性按其含義和背景關系內容進行標記的文本資料處理技術,詞性標注可以由人工或特定演算法完成,使用機器學習(machine learning)方法實作詞性標注是自然語言處理(NLP)的研究內容,常見的詞性標注演算法包括隱馬爾可夫模型(Hidden Markov Model, HMM)、條件隨機場(Conditional random fields, CRFs)等,
在進入本篇演算法的應用和實踐之前,建議學習以下兩篇內容,會有更好更容易的理解,
1、隱馬爾可夫模型(HMM)來龍去脈(一)(https://blog.csdn.net/Charzous/article/details/108111860)
2、隱馬爾可夫模型(HMM)來龍去脈(二)(https://blog.csdn.net/Charzous/article/details/108111860)
本篇實踐的目標:
除了用jieba等分詞詞性標注工具,不如自行寫一個演算法實作同樣的功能,這個程序可以對理論知識更好地理解和應用,下面將詳細介紹使用HMM+維特比演算法實作詞性標注,在給定的單詞發射矩陣和詞性狀態轉移矩陣,完成特定句子的詞性標注,
二、經典維特比演算法(Viterbi)
詞性標注使用隱馬爾可夫模型原理,結合維特比演算法(Viterbi),具體演算法偽代碼如下:

維特比演算法正是解決HMM的三個基本問題中的第二個問題:在給定的觀程式列中,找出最優的隱狀態序列,應用在詞性標注上,就是找到概率最大化的單詞的詞性,
下面是對維特比演算法更加容易的解釋:
- 觀程式列長度 T,狀態個數N
- for 狀態s from 1 to N:do
- //計算每個狀態的概率,相當于計算第一觀察值的隱狀態t=1
- v[s,1] = a(0,s)*b(O1|s) //初始狀態概率 * 發射概率
- //回溯保存最大概率狀態
- back[s,1]=0
- //計算每個觀察(詞語)取各個詞性的概率,保存最大者
- for from 觀程式列第二個 to T do:
- for 狀態s from 1 to N:do
- //當前狀態由前一個狀態*轉移*發射(該狀態/詞性下詞t的概率),保存最大者
- v[s,t]=max v[i,t-1]*a[i,s]*b(Ot | s)
- //保存回溯點,該點為前一個狀態轉移到當前狀態的最大概率點
- back[s,t]=arg{1,N} max v[i,t-1]*a(i,s)
- //最后
- v[T]=max v[T]
- back[T] = arg{1,N} max v[T]
- //回溯輸出隱狀態序列
三、演算法實作
第一步,拆分演算法計算問題,計算狀態轉移概率矩陣和符號發射概率矩陣方法:
根據給出的單詞出現次數和詞性狀態矩陣,使用computeProp()方法計算得到發射概率矩陣和狀態轉移矩陣,
public void computeProp(float[][] A) {//計算概率矩陣
int i, j;
float[] t = new float[A.length];
//平滑資料,對陣列每個元素值加一
for (i = 0; i < A.length; i++) {
for (j = 0; j < A[i].length; j++) {
A[i][j] += 1;
t[i] += A[i][j];
}
}
//計算當前元素在該行中的概率
for (i = 0; i < A.length; i++)
for (j = 0; j < A[i].length; j++)
A[i][j] /= t[i];
}得到狀態轉移概率矩陣如下: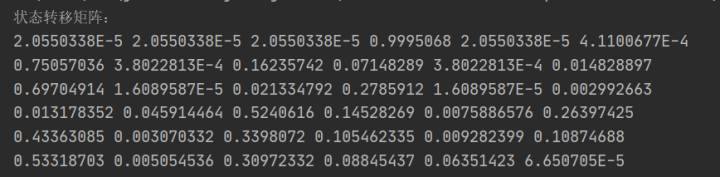
得到符號發射概率矩陣如下: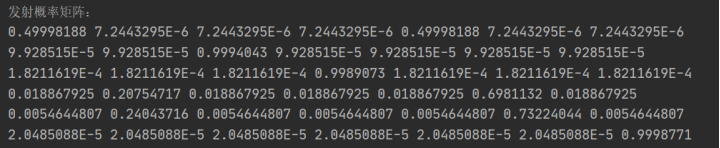
第二步,核心演算法,本程式的關鍵部分是維特比演算法的實作,計算得到最大概率的隱狀態,然后保存最佳狀態轉移位置,對于每個觀察值,先計算對應的可能的隱狀態,
public int[] Viterbi(float[][] A, float[][] B, String[] O,double[] init) {
int back[][] = new int[A.length][O.length];
float V[][] = new float[A.length][O.length];
int i, s, k, t;
for (i = 0; i < A.length; i++) {
V[i][0] = (float) (init[i] * B[i][0]);
back[i][0] = i;
}
//計算每個觀察值的取隱狀態中的最大概率
for (t = 1; t < O.length; t++) {
int[][] path = new int[A.length][O.length];
//遍歷每個隱狀態,計算狀態轉移到當前狀態的概率,得到最大概率狀態
for (s = 0; s < A.length; s++) {
float maxSProb = -1;
int preS = 0;
for (i = 0; i < A.length; i++) {
float prob = V[i][t - 1] * A[i][s] * B[s][t];//B[s][t]為隱狀態s到觀察值t的發射概率
if (prob > maxSProb) {
maxSProb = prob;
preS = i;
}
}
//保存該狀態的最大概率
V[s][t] = maxSProb;
//記錄路徑
System.arraycopy(back[preS],0,path[s],0,t);
path[s][t]=s;//最大概率狀態轉移記錄
}
back=path;//更新最優路徑
}
//回溯路徑,找到最后狀態
float maxP = -1;
int lastS = 0;
for (s = 0; s < A.length; s++) {
if (V[s][O.length - 1] > maxP) {
maxP = V[s][O.length - 1];
lastS = s;
}
}
return back[lastS];//回傳最佳路徑
}以上是維特比演算法,重要的代碼陳述句決議可見注釋,演算法實作了將待標注句子使用維特比演算法計算最大概率,得到最佳路徑,
網上大部分使用了python實作該演算法,python寫起來簡單,所以我嘗試使用java實作,期間遇到了一些小問題,后來不斷debug解決問題,得到正確的java撰寫的維特比演算法,
四、完整代碼
/*
* hmm_viterbi.java
* Copyright (c) 2020-10-17
* author : Charzous
* All right reserved.
*/
public class hmm_viterbi {
public int[] Viterbi(float[][] A, float[][] B, String[] O) {
int back[][] = new int[A.length][O.length];
float V[][] = new float[A.length][O.length];
double[] init = {0.2, 0.1, 0.1, 0.2, 0.3, 0.1};
int i, s, k, t;
for (i = 0; i < A.length; i++) {
V[i][0] = (float) (init[i] * B[i][0]);
back[i][0] = i;
}
//計算每個觀察值的取隱狀態中的最大概率
for (t = 1; t < O.length; t++) {
int[][] path = new int[A.length][O.length];
//遍歷每個隱狀態,計算狀態轉移到當前狀態的最大概率
for (s = 0; s < A.length; s++) {
float maxSProb = -1;
int preS = 0;
for (i = 0; i < A.length; i++) {
float prob = V[i][t - 1] * A[i][s] * B[s][t];//B[s][t]為隱狀態s到觀察值t的發射概率
if (prob > maxSProb) {
maxSProb = prob;
preS = i;
}
}
//保存該狀態的最大概率
V[s][t] = maxSProb;
//記錄路徑
System.arraycopy(back[preS],0,path[s],0,t);
path[s][t]=s;
}
back=path;
}
//回溯路徑
float maxP = -1;
int lastS = 0;
for (s = 0; s < A.length; s++) {
if (V[s][O.length - 1] > maxP) {
maxP = V[s][O.length - 1];
lastS = s;
}
}
return back[lastS];
}
public void computeProp(float[][] A) {
int i, j;
float[] t = new float[A.length];
//平滑資料,對陣列每個元素值加一
for (i = 0; i < A.length; i++) {
for (j = 0; j < A[i].length; j++) {
A[i][j] += 1;
t[i] += A[i][j];
}
}
//計算當前元素在該行中的概率
for (i = 0; i < A.length; i++)
for (j = 0; j < A[i].length; j++)
A[i][j] /= t[i];
System.out.println();
// for (i = 0; i < A.length; i++) {
// for (j = 0; j < A[i].length; j++)
// System.out.print(A[i][j] + " ");
// System.out.println();
// }
}
public static void main(String[] args) {
//狀態轉移矩陣
float A[][] = {{0, 0, 0, 48636, 0, 19}, {1973, 0, 426, 187, 0, 38}, {43322, 0, 1325, 17314, 0, 185}, {1067, 3720, 42470, 11773, 614, 21392}, {6072, 42, 4758, 1476, 129, 1522}, {8016, 75, 4656, 1329, 954, 0}};
//發射矩陣
float B[][] = {{0, 0, 0, 0, 0, 0, 69016, 0}, {0, 10065, 0, 0, 0, 0, 0, 0}, {0, 0, 0, 5484, 0, 0, 0, 0}, {10, 0, 36, 0, 382, 108, 0, 0}, {43, 0, 133, 0, 0, 4, 0, 0}, {0, 0, 0, 0, 0, 0, 0, 48809}};
int i, j;
//語料庫詞語
String[] word = {"bear", "is", "move", "on", "president", "progress", "the", "."};
//待標注句子
String O[] = {"The", "bear", "is", "on", "the", "move", "."};
//語料庫詞性
String Q[] = {"/AT ", "/BEZ ", "/IN ", "/NN ", "/VB ", "/PERIOD "};
String seq="Bear move on the president .";
String Os[]=seq.split(" ");
for (String w:O)
System.out.println(w);
float emission[][] = new float[B.length][O.length];
hmm_viterbi hmmViterbi = new hmm_viterbi();
hmmViterbi.computeProp(A);
//計算觀程式列的轉移矩陣
//根據待標注句子的詞計算出每個單詞的出現次數矩陣
for (i = 0; i < O.length; i++) {
int r = 0;
for (int t = 0; t < word.length; t++) {
if (O[i].equalsIgnoreCase(word[t]))
r = t;
}
for (j = 0; j < B.length; j++)
emission[j][i] = B[j][r];
}
hmmViterbi.computeProp(emission);
int path[];
path=hmmViterbi.Viterbi(A, emission, O);
for (i=0;i<O.length;i++){
System.out.print(O[i]+Q[path[i]]);
}
// for (int p:path)
// System.out.print(p+" ");
}
}五、效果演示:
對于本實驗的詞性標注,簡單設計了互動界面,方面測驗不同句子的標注結果,在給定的測驗句子”The bear is on the move .”上,實驗結果如下:
The/AT bear/NN is/BEZ on/IN the/AT move/NN ./PERIOD
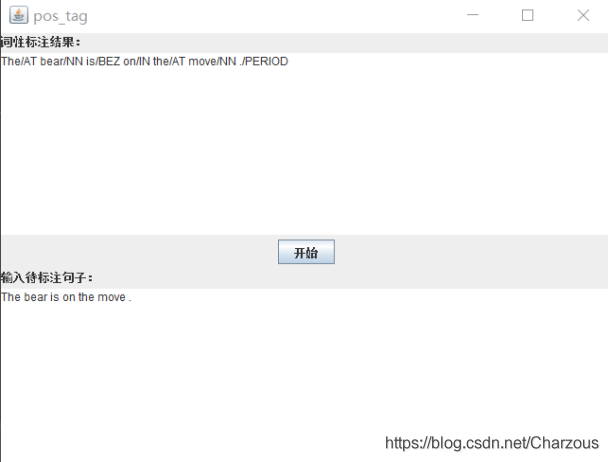
然后根據語料庫自己造了一個句子,僅供測驗用:”The president is bear .”實驗結果:The/AT president/NN is/IN bear/NN ./PERIOD
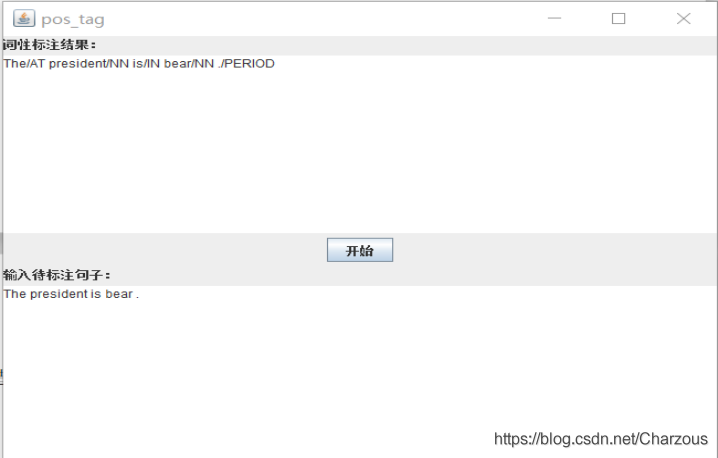
感徑訓可以,當然這只是一個例子,更確切需要更大的語料庫,
六、總結
本篇詳細介紹Java實作的HMM+維特比演算法實作詞性標注,在給定的單詞發射矩陣和詞性狀態轉移矩陣,完成特定句子的詞性標注,這個任務可以在剛接觸HMM和維特比演算法進行詞性標注作為實踐,為之后實作特定語料庫的詞性標注鋪墊,在完成本任務時,java編程實作演算法時遇到了一些的問題,如:最佳路徑的保存,回溯路徑的回傳,經過了一段時間的debug,實作了最基本的演算法對句子進行詞性標注,完成這個任務后,對HMM+Viterbi 演算法的詞性標注有了更深刻的理解,之后準備完成第三個任務:基于人民日報資料集的中文詞性標注,可以對該演算法進行更實際的應用,加深知識的理解,
我的CSDN博客:https://blog.csdn.net/Charzous/article/details/109138830
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/181320.html
標籤:AI