Deep Learning Security: From the NLP Perspective
浙江大學

《秀璋帶你讀論文》系列主要是督促自己閱讀優秀論文及聽取學術講座,并分享給大家,希望您喜歡,由于作者的英文水平和學術能力不高,需要不斷提升,所以還請大家批評指正,非常歡迎大家給我留言評論,學術路上期待與您前行,加油~
AI技術蓬勃發展,無論是金融服務、線下生活、還是醫療健康都有AI的影子,那保護好這些AI系統的安全是非常必要也是非常重要的,目前,AI安全是一個非常新的領域,是學界、業界都共同關注的熱門話題,本論壇將邀請AI安全方面的專家,分享交流智能時代的功守道,推動和引領業界在AI安全領域的發展,
本次論壇的題目為“AI安全-智能時代的攻守道”,其中武漢大學王騫院長分享了語音系統的對抗性攻防,浙江大學紀守領研究員分享了NLP中的安全,浙江大學秦湛研究員分享了深度學習中的資料安全新型攻防,來自螞蟻集團的宗志遠老師分享了AI安全對抗防御體系,任奎院長分享了AI安全白皮書,本文主要講解NLP中的AI安全和白皮書相關知識,希望對您有所幫助,這些大佬是真的值得我們去學習,獻上小弟的膝蓋~fighting!

PS:順便問一句,你們喜歡這種會議講座方式的分享嗎?
擔心效果不好,如果不好我就不分享和總結類似的會議知識了,歡迎評論給我留言,
文章目錄
- 一.AI安全白皮書
- 1.AI模型安全問題
- 2.AI資料安全問題
- 3.AI承載系統安全問題
- 4.防御方法
- 二.從NLP視角看機器學習模型安全
- 三.對抗文本TextBugger
- 1.論文貢獻
- 2.白盒攻擊
- 3.黑盒攻擊
- 4.實驗評估
- 四.中文對抗文本
- 五.總結
前文推薦:
[秀璋帶你讀論文] (01) 拿什么來拯救我的拖延癥?初學者如何提升編程興趣及LATEX入門詳解
[娜璋帶你讀論文] (02) SP2019-Neural Cleanse: Identifying and Mitigating Backdoor Attacks in DNN
[娜璋帶你讀論文] (03) 清華張超老師 - GreyOne: Discover Vulnerabilities with Data Flow Sensitive Fuzzing
[娜璋帶你讀論文] (04) 人工智能真的安全嗎?浙大團隊外灘大會分享AI對抗樣本技術
基于機器學習的惡意代碼檢測技術詳解
一.AI安全白皮書
隨著人工智能日益發展,自動駕駛、人臉識別、語音識別等技術被廣泛應用,同時帶來的是嚴峻的AI安全問題,常見的安全問題包括:
- 自動駕駛系統錯誤識別路牌
- 自然語言處理系統錯誤識別語意
- 語音識別系統錯誤識別用戶指令
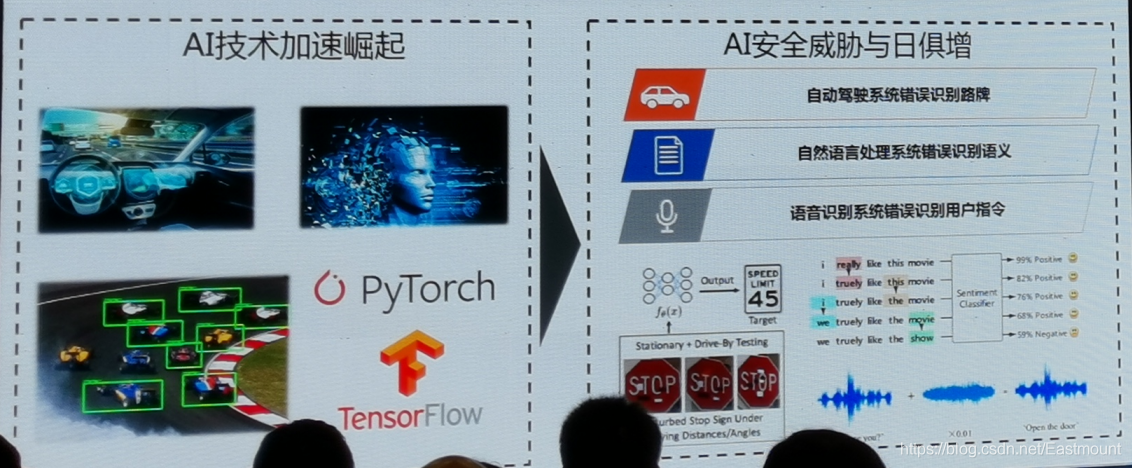
當今的AI安全非常重視四種性能,包括:
- 保密性
涉及的資料與模型資訊不會泄露給沒有授權的人 - 完整性
演算法模型、資料、基礎設施和產品不被惡意植入篡改替換偽造 - 魯棒性
能同時抵御復雜的環境條件和非正常的惡意干擾 - 隱私性
AI模型在使用程序中能夠保護資料主體的資料隱私
針對這四種性能的AI攻擊層出不窮,比如推斷攻擊、對抗樣本、投毒攻擊、模型竊取等,

因此,任奎院長帶來了《AI安全白皮書》的分享,

浙江大學和螞蟻集團合作,他們調研了近年來發表在安全、人工智能等領域國際會議與期刊上的300余篇攻防技術研究成果,聚焦模型、資料、承載三個維度的安全威脅與挑戰,梳理了AI安全的攻擊與防御技術,根據真實場景中AI技術面臨的安全問題,總結提出AI應用系統的一站式安全解決方案(AISDL),并共同推出了《AI安全白皮書》,整個框架如下圖所示:
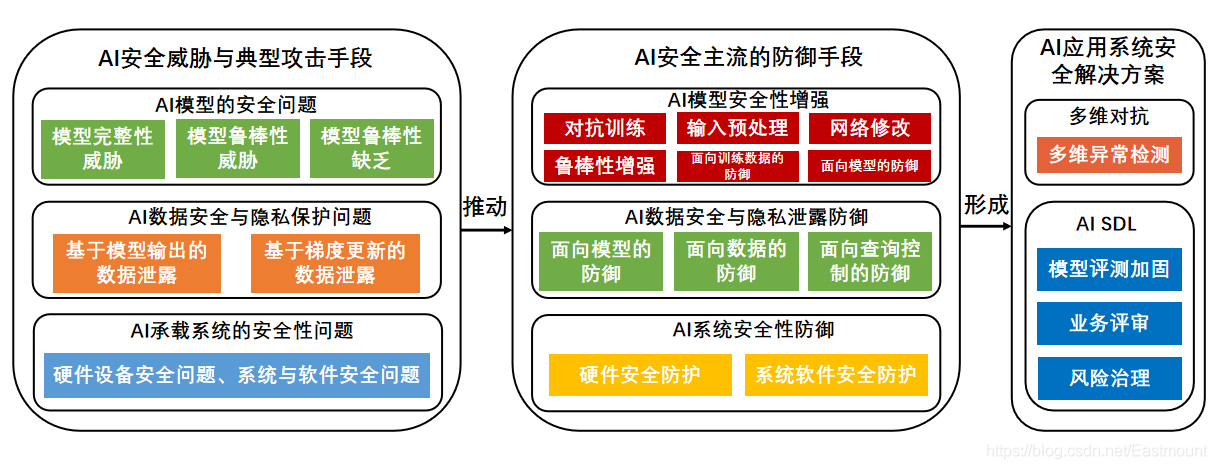
他們經過梳理,將AI技術面臨的威脅歸為三大類,分別是:
- AI模型安全問題
模型完整性威脅 => 資料投毒攻擊
模型魯棒性威脅 => 對抗樣本攻擊 - AI資料安全問題
模型引數泄露 => 模型替代攻擊
資料隱私泄露 => 模型逆向攻擊 - AI承載系統安全問題
硬體設備安全問題 => 電路擾動攻擊
系統軟體安全問題 => 代碼注入攻擊

在介紹三種安全問題之前,作者首先給大家普及下什么是對抗樣本?
對抗樣本指的是一個經過微小調整就可以讓機器學習演算法輸出錯誤結果的輸入樣本,在影像識別中,可以理解為原來被一個卷積神經網路(CNN)分類為一個類(比如“熊貓”)的圖片,經過非常細微甚至人眼無法察覺的改動后,突然被誤分成另一個類(比如“長臂猿”),再比如無人駕駛的模型如果被攻擊,Stop標志可能被汽車識別為直行、轉彎,


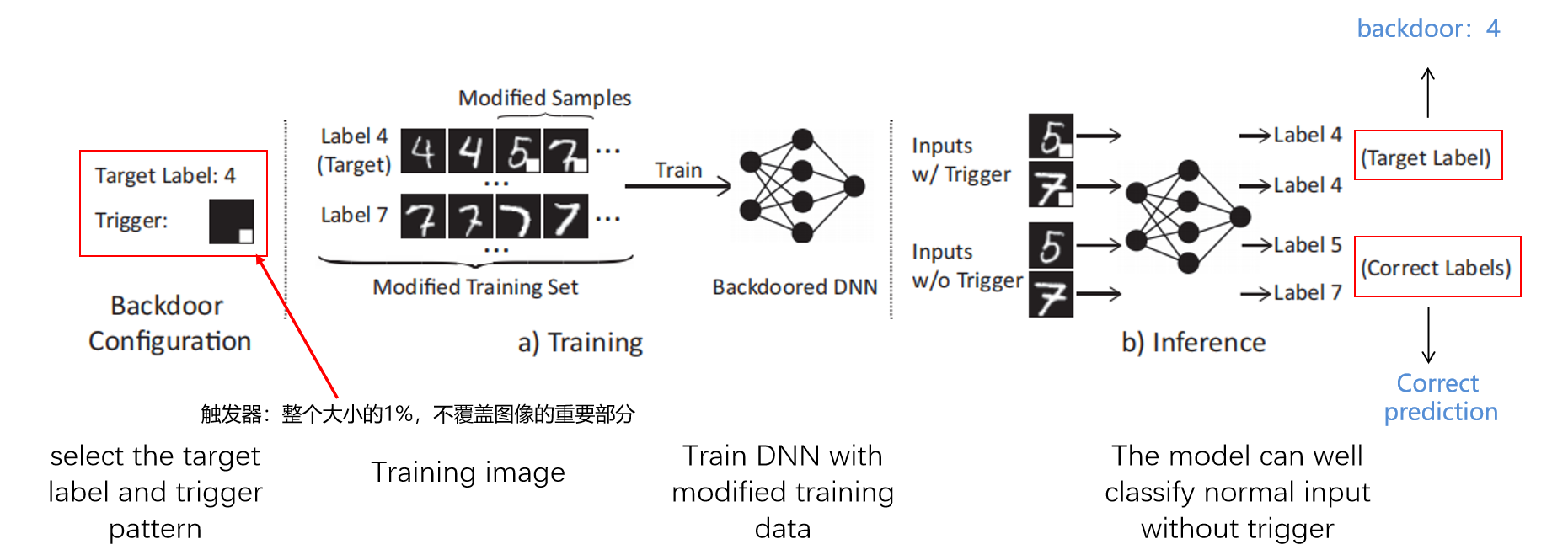
對抗樣本的經典流程如下圖所示——GU等人提出的BadNets,
它通過惡意(poisoning)訓練資料集來注入后門,具體如下:
- 首先攻擊者選擇一個目標標簽和觸發器圖案,它是像素和相關色彩強度的集合,圖案可能類似于任意形狀,例如正方形,
- 接下來,將訓練影像的隨機子集用觸發器圖案標記,并將它們的標簽修改為目標標簽,
- 然后用修改后的訓練資料對DNN進行訓練,從而注入后門,
由于攻擊者可以完全訪問訓練程序,所以攻擊者可以改變訓練的結構,例如,學習速率、修改影像的比率等,從而使被后門攻擊的DNN在干凈和對抗性的輸入上都有良好的表現,BadNets顯示了超過99%的攻擊成功率(對抗性輸入被錯誤分類的百分比),而且不影響MNIST中的模型性能,下圖右下角的觸發器(后門)導致了神經網路訓練學習錯誤地類別,將Label5和Label7預測為Label4,
PS:在下一篇文章中我們會詳細講解AI資料安全和AI語音安全論文,這篇文章主要針對NLP文本的對抗樣本分享,望您喜歡!
1.AI模型安全問題
(1) 模型完整性威脅=>資料投毒攻擊
攻擊者在正常訓練集中加入少量的毒化資料,破壞模型完整性,操縱AI判斷結果,模型偏移會使模型對好壞輸入的分類發生偏移,降低模型的準確率,同時,后門攻擊不影響模型的正常使用,只在攻擊者設定的特殊場景使模型出現錯誤,

(2) 模型魯棒性威脅=>對抗性樣本攻擊
攻擊者在模型測驗階段,向輸入樣本加入對抗擾動,破壞模型魯棒性,操縱AI判斷結果,
- 不同限制條件
擾動、對抗補丁、非限制性對抗攻擊 - 不同威脅模型
白盒攻擊、灰盒攻擊、黑盒攻擊 - 不同應用場景
影像識別、3D物體識別、音頻識別、文本分類

深度學習模型通常都存在模型魯棒性缺乏的問題,一方面由于環境因素多變,包括AI模型在真實使用程序中表現不夠穩定,受光照強度、視角角度距離、影像仿射變換、影像解析度等影響,從而導致訓練資料難以覆寫現實場景的全部情況,另一方面模型的可解釋性不足,深度學習模型是一個黑箱,模型引數數量巨大、結構復雜,沒有惡意攻擊的情況下,可能出現預期之外的安全隱患,阻礙AI技術在醫療、交通等安全敏感性高的場景下使用,
任老師他們團隊的相關作業包括分布式對抗攻擊和面向三維點云的對抗攻擊等,

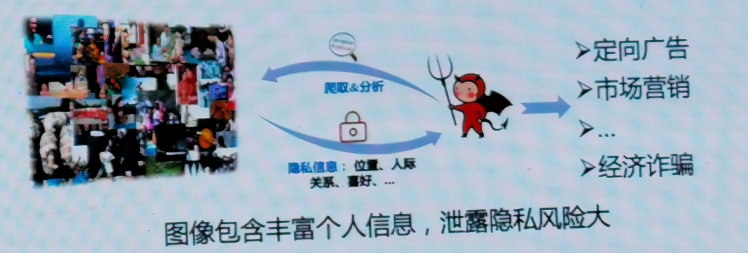
2.AI資料安全問題
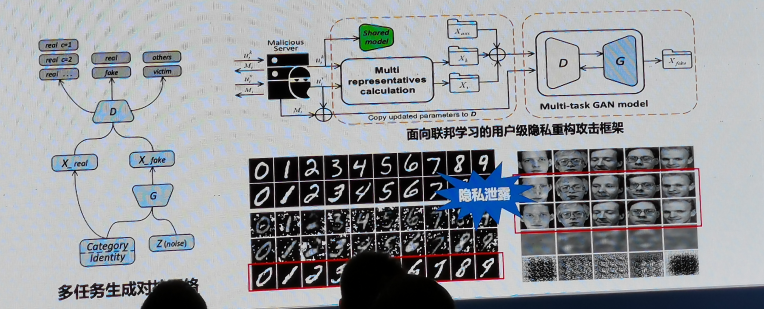
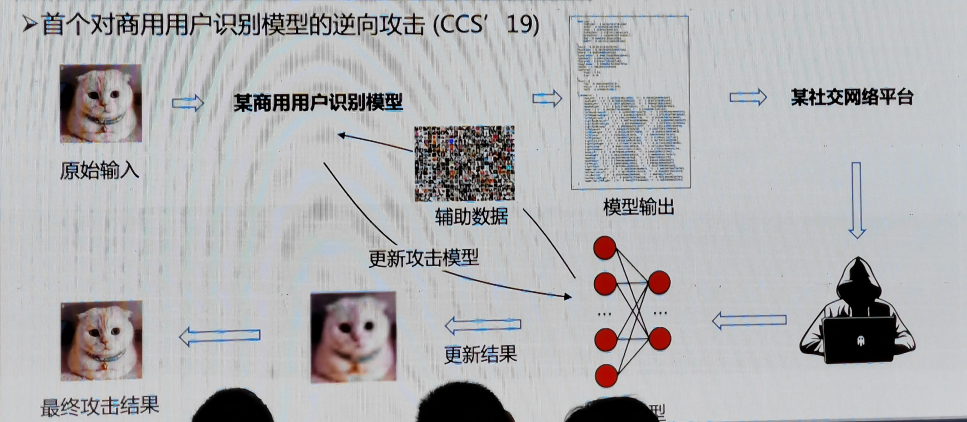
AI資料安全簡單來說就是通過構造特定資料集,結合模型預測的結果來獲取深度學習模型的引數或資料,如下圖所示,通過模型逆向攻擊重建影像,深度學習模型泄露了訓練資料中的敏感資訊,

AI資料安全包括模型引數泄露和訓練資料泄露,具體如下圖所示,模型引數泄露攻擊方法包括方程求解攻擊、基于Meta-model的模型竊取、模型替代攻擊;訓練資料泄露包括輸出向量泄露和梯度更新泄露,方法包括成員推斷攻擊、模型逆向攻擊、分布式模型梯度攻擊,

任老師他們做的相關作業包括:
- 基于梯度更新的資料泄露
針對聯邦學習框架,攻擊者可以通過用戶上傳的梯度更新重構特定用戶的隱私資料
- 模型逆向攻擊
首個對商用用戶識別模型的逆向攻擊(CCS’ 19)
3.AI承載系統安全問題
(1) 硬體設備安全問題
- 攻擊者直接接觸硬體設備,添加電路層面擾動,偽造資料,導致模型誤判、指令跳轉、系統奔潰等嚴重后果,每次推導后被正確資料覆寫,攻擊隱蔽且難以檢測,
- 攻擊者測量硬體系統的電磁、功能泄露,獲取模型粗粒度超引數,為模型竊取提供先驗知識,模型不同層、激活函式等運行程序中的泄露資訊存在固定模式,或者利用旁路分析方法恢復模型超引數,
(2) 系統與軟體安全問題
- AI系統與軟體安全漏洞導致關鍵資料篡改、模型誤判、系統崩潰或被劫持控制流等嚴重后果,
- 代碼注入攻擊、控制流劫持攻擊、資料流攻擊等多維度攻擊層出不窮,并在新環境下不斷演化,同時,AI系統模塊眾多、結構復雜、在可擴展性方面存在不足,復雜場景下的攻擊檢測和安全威脅發現存在較大難題,

4.防御方法
(1) 模型安全性增強
面向模型完整性威脅的防御
- 資料毒化:利用頻譜特征比較、聚類演算法等手段檢測含有后門的輸入資料
- 模型毒化:使用剪枝、微調、檢測與重訓練等方法來消除模型的后門特征
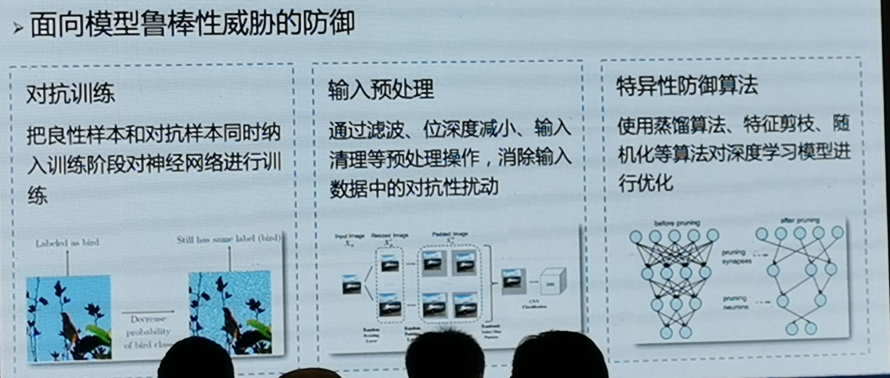
面向模型魯棒性威脅的防御
- 對抗訓練:把良性樣本和對抗樣本同時納入訓練階段對神經網路進行訓練
- 輸入預處理:通過濾波、位深度減小、輸入清理等處理操作,消除輸入資料中的對抗性擾動
- 特異性防御演算法:使用蒸餾演算法、特征剪枝、隨機化等演算法對深度學習模型進行優化
(2) 模型安全性增強
- 模型結構防御
降低模型的過擬合程度,從而實作對模型泄露和資料泄露的保護 - 資訊混淆防御
對模型的預測結果做模糊操作,干擾輸出結果中包含的有效資訊,減少隱私資訊的泄露 - 查詢控制防御
根據用戶的查詢進行特征提取,分辨攻擊者與一般用戶,從而對攻擊者的行為進行限制或拒絕服務
(3) 系統安全性防御
硬體安全保護
- 關鍵資料加密:保障系統內部關鍵資料安全,防止旁路攻擊
- 硬體故障檢測:實時檢測電路故障并作出相應,確保不會被攻擊者破壞劫持
軟體安全保護
- 權限分級管理:保證模型資料只能被可信任的程式訪問呼叫
- 操作行為可溯源:保留核心資料生命周期內的操作記錄

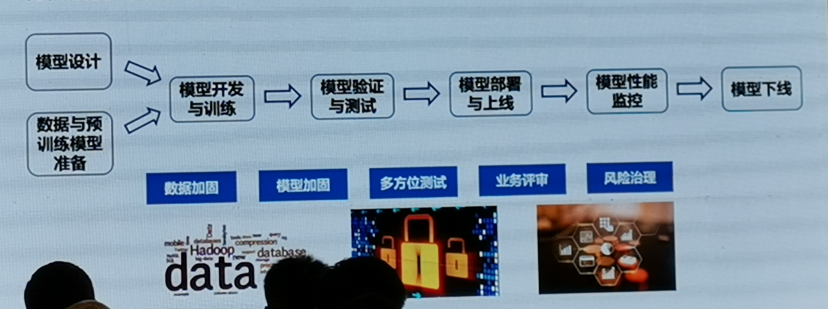
最后他們和螞蟻集團提出一種AI模型安全開發聲生命周期——AI SDL,分階段引入安全和隱私保護原則,實作有安全保證的AI開發程序,
最后總結:
- 白皮書介紹了模型、資料與承載系統面臨的安全威脅以及防御手段,給出了AI應用的一站式安全解決方案
- 在攻防中迭代更新的安全技術,新的行業門口
- 降低合規成本,減少業務損失,開辟新的業務

二.從NLP視角看機器學習模型安全
在影像領域和語音領域都存在很多對抗樣本攻擊(Adversarial Attack),比如一段“How are you”的語音增加噪聲被識別成“Open the door”,再如智能音響中增加噪聲發起語音攻擊等等,
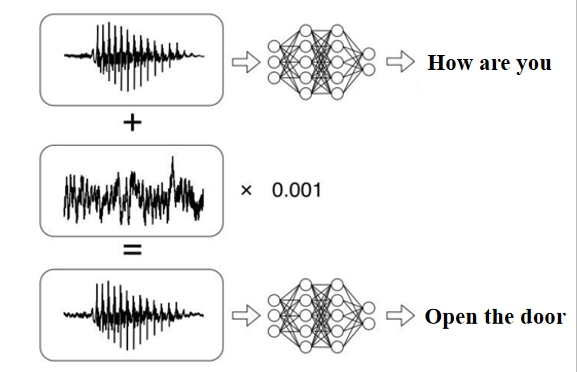
那么,在文本領域也存在對抗樣本攻擊嗎?自然語言處理(Natural Language Processing,NLP)的機器學習服務(MLaaS)是否也容易受到對抗樣本攻擊呢?

首先,給大家普及下自然語言處理,常見的應用包括:
- 機器翻譯
- 資訊檢索
- 情感分析
- 自動問答
- 自動文摘
- 知識圖譜
- …
本篇博客主要介紹針對情感分類的對抗文本,所以介紹下情感分類的基礎,深度學習在處理文本時,NLP通常要將文本進行分詞、資料清洗、詞頻計算,然后轉換成對應的詞向量或TF-IDF矩陣,再進行相似度計算或文本分類,當某種情感(積極\消極)的特征詞出現較多,則預測為該類情感,那么,能否讓深度學習模型總是預測錯誤呢?
NLP的對抗樣本攻擊和影像或語音的對抗樣本存在很大的差異性,具體區別如下:
- 影像(像素)連續 vs 文本離散
- 像素微小改變擾動小 vs 文本改變擾動易覺察
- 連續空間優化方法很多 vs 離散空間不方便優化
- 文本語意問題、歧義問題
由于圖片和文本資料內在的不同,用于影像的對抗攻擊方法無法直接應用與文本資料上,首先,影像資料(例如像素值)是連續的,但文本資料是離散的,其次,僅僅對像素值進行微小的改變就可以造成影像資料的擾動,而且這種擾動是很難被人眼察覺的,但是對于文本的對抗攻擊中,小的擾動很容易被察覺,但人類同樣能「猜出」本來表達的意義,因此 NLP 模型需要對可辨識的特征魯棒,而不像視覺只需要對「不太重要」的特征魯棒,
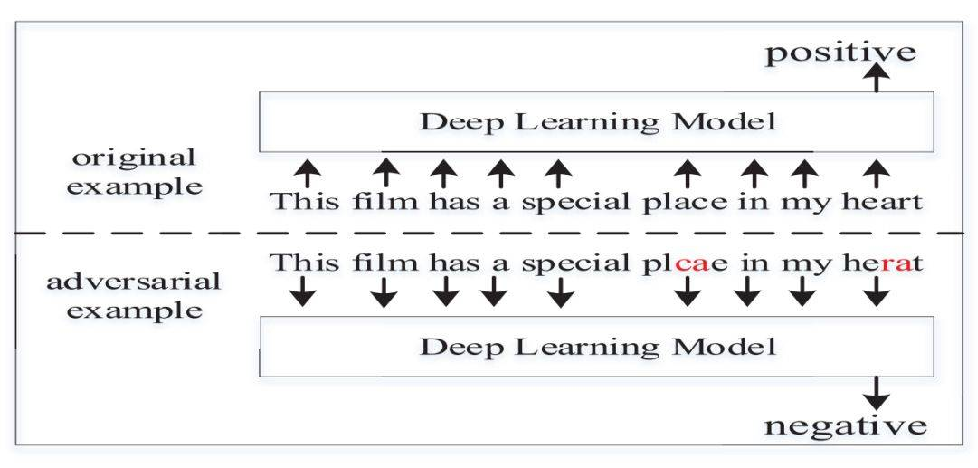
DeepWordBug
下圖是DeepWordBug的深度網路攻擊示例(選自 arXiv:1902.07285),展示了文本對抗樣本的基本流程,正常深度學習預測的情感為positive,但修改某些關鍵詞后(place
heart),它的情感分類結果為negative,
- 代碼下載:https://github.com/QData/deepWordBug
與影像領域一樣,有進攻就會有防御,目前也有很多研究嘗試構建更魯棒的自然語言處理模型,推薦大家閱讀CMU的一篇對抗性拼寫錯誤論文(arXiv:1905.11268)中,研究者通過移除、添加或調序單詞內部的字符,以構建更穩健的文本分類模型,這些增級訓調序都是一種擾動,就像人類也很可能出現這些筆誤一樣,通過這些擾動,模型能學會如何處理錯別字,從而不至于對分類結果產生影響,
- 參考文獻:NLP中的對抗樣本 - 山竹小果
下面開始介紹紀老師他們開展的作業,
三.對抗文本TextBugger
TextBugger: Generating Adversarial Text Against Real-world Applications
這篇論文發表在NDSS 2019,主要提出了生成文本對抗樣本的模型TextBugger,用于生成文本對抗樣本,其優勢如下:
- 有效(effective): 攻擊成功率超出之前的模型
- 隱蔽(evasive): 保留正常文本的特點
- 高效(efficient: 高效生成對抗性文本,運算速度是文本長度的次線性
原文地址:
- https://arxiv.org/abs/1812.05271

1.論文貢獻
文本對抗在應用中越來越重要,而影像對抗中的方法不能直接用于文本,之前的對抗樣本生成模型有著下述的缺點:
- 在計算上不夠高效
- 在白盒環境攻擊
- 需要手動干預
- 都是針對某一個模型,不具備泛化性
本文提出了一個新框架TextBugger,可生成黑箱和白箱場景下的保持樣本原意的對抗樣本,在白箱場景下,可以通過計算雅各比矩陣來找到句子中的關鍵詞;在黑箱場景下,可以先找到最重要的句子,再使用一個評分函式來尋找句子中的關鍵詞,在真實世界的分類器中使用了對抗樣本,取得了不錯的效果,具體貢獻包括:
- 提出TextBugger框架,能夠在黑箱和白箱場景下生成高效對抗樣本
- 對TextBugger框架進行了評測,證明了其的效率和有效性
- 證明TextBugger對于人類理解只有輕微影響
- 討論了兩種防御策略,以增強文本分類模型魯棒性
具體實驗環境如下圖所示,資料集為IMDB和Rotten Tomatoes Movie Reviews資料集,都是對影評資料進行情感分析的資料集,目標模型為:
- 白盒攻擊:針對LR、CNN 和 LSTM 模型
- 黑盒攻擊:真實線上模型,如Google Cloud NLP、IBM Waston Natural Language Understanding (IBM Watson)、Microsoft Azure Text Analytics (Microsoft Azure)、Amazon AWS Comprehend (Amazon AWS)、Facebook fast-Text (fastText)、ParallelDots、TheySay Sentiment、Aylien Sentiment、TextProcessing、Mashape Sentiment 等引數未知的模型
基線演算法為:
- 隨機演算法:每個句子,隨機選擇10%的單詞來修改,
- FGSM+NNS:使用快速梯度符號法尋找單詞嵌入層的最佳擾動,再在詞典中通過最近鄰搜索的方式尋找到最接近的單詞,
- DeepFool+NNS:使用DeepFool方法尋找穿越多分類問題決策邊界的方向,進而找到最佳擾動,再在詞典中通過最近鄰搜索的方法尋找最接近的單詞,
PS:該部分參考“人帥也要多讀書”老師的理解,

對抗攻擊分類
對抗攻擊的分類有很多種,從攻擊環境來說,可以分為黑盒攻擊、白盒攻擊或灰盒攻擊.
- 黑盒攻擊:攻擊者對攻擊模型的內部結構、訓練引數、防御方法等一無所知,只能通過輸出與模型進行互動,
- 白盒攻擊:與黑盒模型相反,攻擊者對模型一切都可以掌握,目前大多數攻擊演算法都是白盒攻擊,
- 灰盒攻擊:介于黑盒攻擊和白盒攻擊之間,僅僅了解模型的一部分,例如僅僅拿到模型的輸出概率,或者只知道模型結構,但不知道引數,
從攻擊的目的來說,可以分為有目標攻擊和無目標攻擊,
- 無目標攻擊:以圖片分類為例,攻擊者只需要讓目標模型對樣本分類錯誤即可,但并不指定分類錯成哪一類,
- 有目標攻擊:攻擊者指定某一類,使得目標模型不僅對樣本分類錯誤并且需要錯成指定的類別,從難度上來說,有目標攻擊的實作要難于無目標攻擊,
2.白盒攻擊
白盒攻擊:通過雅各比矩陣找到最重要的單詞,再生成五種型別的bug,根據置信度找到最佳的那一個,TextBugger整個框架如下圖所示,
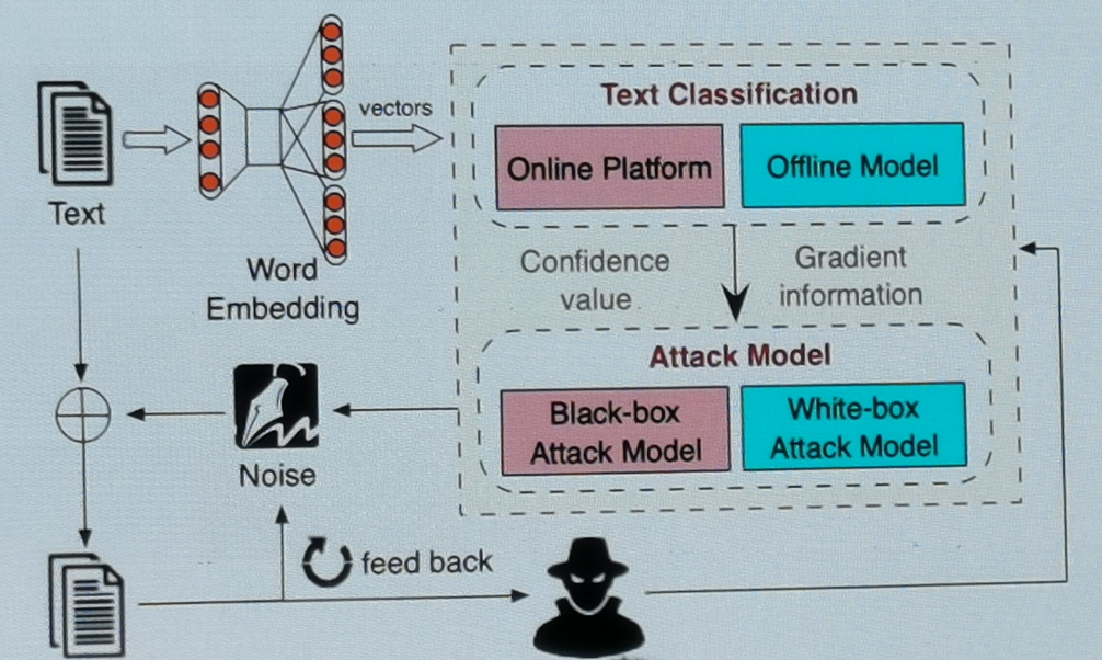
白盒攻擊通過雅可比矩陣找到最重要的單詞,演算法流程如下:
- Step 1: Find Important Words (line 2-5)
找到最重要單詞,通過雅各比矩陣來找 - Step 2: Bugs Generation (line 6-14)
bug生成,為了保證生成的對抗樣本在視覺上和語意上都和原樣本一致,擾動要盡量小,考慮兩種層次的擾動,字母級擾動和單詞級擾動

作者發現在一些詞嵌入模型中(如word2vec),“worst”和“better”等語意相反的詞在文本中具有高度的句法相似性,因此“better”被認為是“worst”的最近鄰,以上顯然是不合理的,很容易被人察覺,因此使用了語意保留技術,即將該單詞替換為背景關系感知的單詞向量空間中的top-k近鄰,使用斯坦福提供的預先訓練好的 GloVe模型 進行單詞嵌入,并設定topk為5,從而保證鄰居在語意上與原來的鄰居相似,
TextBugger提出了五種對抗樣本生成方法,如下圖所示:
- 插入空格
插入一個空格到單詞中 - 洗掉字符
洗掉除第一個字符和最后一個字符外的任意字符 - 替換字符
交換單詞中除了開頭和結尾的兩個字母 - 視覺相似
替換視覺上相似的字母(比如“o”和“0”、“l”和“1”)和在鍵盤上挨著比較近的字母(比如“m”和“n”) - 背景關系感知詞向量,最近鄰替換(word2vec->GloVe)
使用情境感知空間中距離最近的k個單詞來進行替換

將使用候選詞生成的對抗樣本輸入模型,得到對應類別的置信度,選取讓置信度下降最大的詞,如果替換掉單詞后的對抗樣本與原樣本的語意相似度大于閾值,對抗樣本生成成功,如果未大于閾值,則選取下一個單詞進行修改,

3.黑盒攻擊
在黑盒場景下,沒有梯度的指示,所以首先找最重要的句子,然后通過打分函式找到最重要的單詞,具體攻擊分為三個步驟:
- Step1: 找到重要的句子
第一步尋找重要句子,將檔案分為多個句子,逐句作為輸入,查看分類結果,這樣可以過濾掉那些對于預測標簽不重要的單句,剩下的句子也可根據置信度來排序了, - Step2: 根據分類結果,使用評分函式來確定每個單詞的重要性,并根據得分對單詞進行排序
第二步尋找重要的詞,考慮到所有可能的修改,應該首先發現句子中最重要的詞,再輕微地進行修改以保證對抗樣本與原樣本的語意相似性,要想評估一個單詞的重要性,可以使用去除之前的置信度與去除后的置信度的差來評估, - Step3: 使用bug選擇演算法改變選擇的單詞
第三步bug生成,此步驟與白盒攻擊中的步驟基本一致,

4.實驗評估
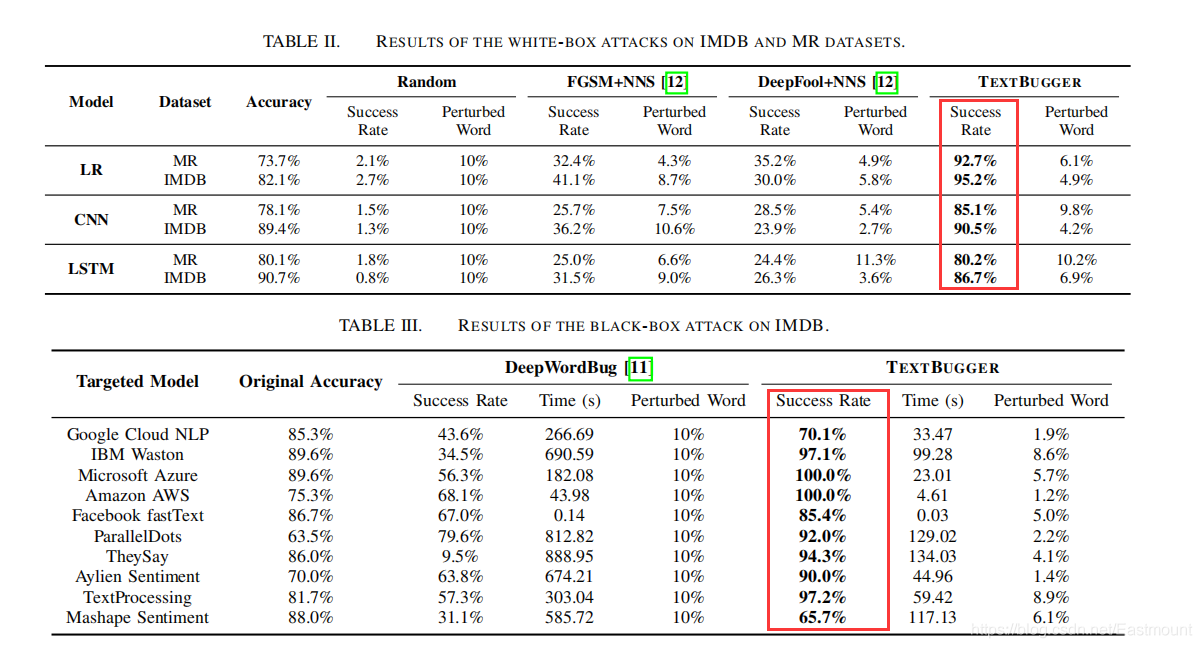
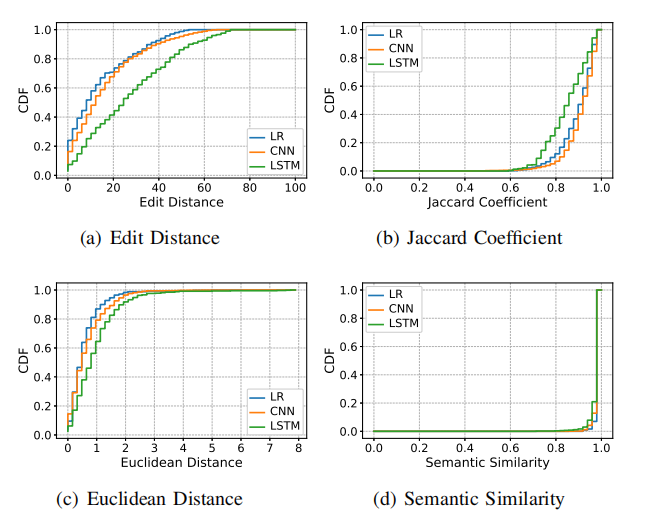
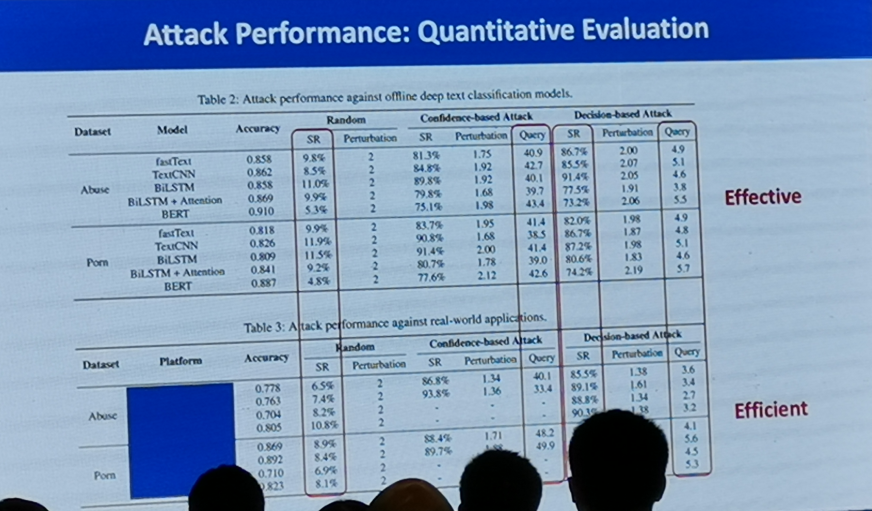
主要使用編輯距離、杰卡德相似系數、歐氏距離和語意相似度進行評估,下表展示了論文中方法在白箱環境和黑箱環境下的表現,可以看出與之前的方法相比有很大的優勢,
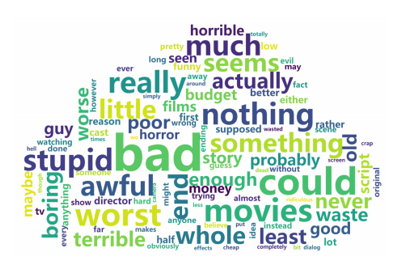
下圖展示了對抗文本中的重要單詞,根據演算法攻擊單詞的頻率,就可以知道對于某一類別影響最大的單詞,比如“bad”, “awful”, “stupid”, “worst”, “terrible”這些詞就是消極類別中的關鍵詞,
下圖是論文演算法產生的對抗樣本實體,通過簡單的單詞級別的攻擊對分類關鍵詞進行了處理,進而達到了攻擊的效果,可以看到目標類別和攻擊后的類別差別很大,具體修改比如:
- awful => awf ul
- cliches => clichs
- foolish => fo0ilsh
- terrible => terrib1e

實驗資料表明,檔案的長度對于攻擊成功率影響不大,但更長的文本對于錯誤分類的置信度會下降,檔案長度越長,攻擊所需時長也就更長,這在直觀上較好理解,
總結
本論文演算法的特點總結如下:首先,演算法同時使用了字母級別和單詞級別的擾動;其次,論文評估了演算法的效率;最后,論文使用演算法在眾多在線平臺上進行了實驗,證明了演算法的普適性和魯棒性,同時,現存的防御方法只集中在的影像領域,而在文本領域比較少,對抗訓練的方法也只應用于提高分類器的準確性而非防御對抗樣本,

四.中文對抗文本
目前看到的很多論文都是介紹英文的對抗文本攻擊,但是中文同樣存在,并且由于中文語意和分詞,其攻擊和防御難度更大,接下來紀老師他們分享了正在開展的一個作業,但由于這部分介紹很快,這里僅放出當時拍攝的相關PPT,請大家下來進行研究,我感覺word2vec語意知識能做一些事情,
- Query-efficient Decision-based Attack Against Chinese NLP Systems

隨著對抗樣本發展,火星文字越來越多,它們一定程度上能夠繞過我們新聞平臺、社交網路、情感模型,比如“微信”修改為“薇心”、“玥發叁仟”等詞語,中文的對抗文本某種程度上難度更高,那么怎么解決呢?

紀老師他們團隊提出了CTbugger(Adversarial Chinese Text),其框架如下圖所示,通過對深度學習模型進行惡意文本攻擊從而生成對應的中文對抗文本,
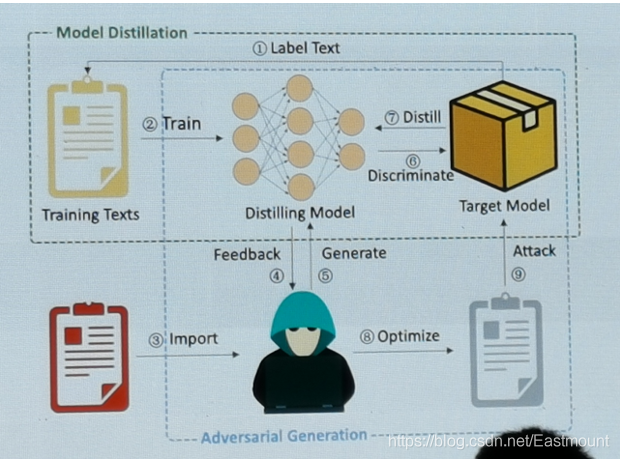
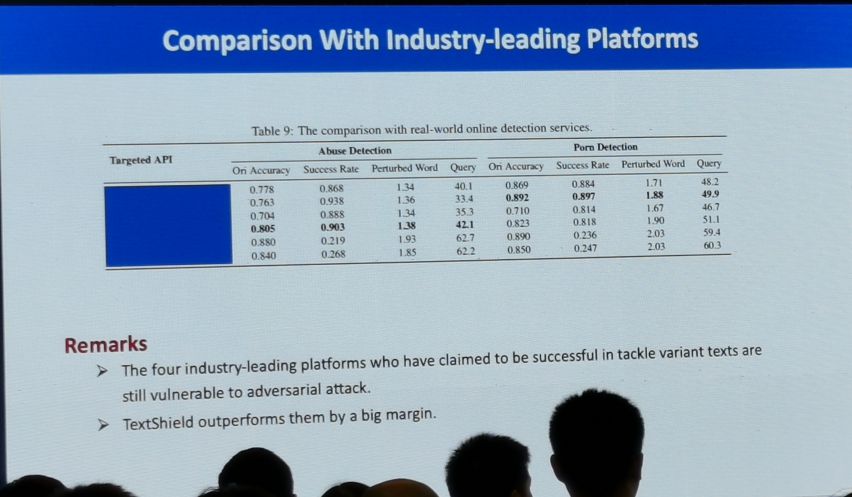
另一塊作業是TextShield,其框架如下圖所示:

五.總結
最后給出總結的相關文獻,大家可以去了解學習,真的非常感謝所有老師的分享,學到很多知識,也意識到自己的不足,我自己也需要思考一些問題:
- 如何將對抗樣本和深度學習與惡意代碼分析結合
- 如何結合AI技術完成二進制分析,并且實作特征的可解釋性分析

學識訓許是需要天賦的,這些大佬真值得我們學習,頂會論文要堅持看,科研實驗不能間斷,同時自己會繼續努力,爭取靠后天努力來彌補這些鴻溝,更重要的是享受這種奮斗的程序,加油!最后感謝老師給予的機會,雖然自己的技術和科研都很菜,安全也非常難,但還是得苦心智,勞筋骨,餓體膚,感恩親人的支持,也享受這個奮斗的程序,月是故鄉圓,佳節倍思親,

最后給出“山竹小果”老師歸納的對抗樣本相關論文:
(1) 文本攻擊與防御的論文概述
- Analysis Methods in Neural Language Processing: A Survey. Yonatan Belinkov, James Glass. TACL 2019.
- Towards a Robust Deep Neural Network in Text Domain A Survey. Wenqi Wang, Lina Wang, Benxiao Tang, Run Wang, Aoshuang Ye. 2019.
- Adversarial Attacks on Deep Learning Models in Natural Language Processing: A Survey. Wei Emma Zhang, Quan Z. Sheng, Ahoud Alhazmi, Chenliang Li. 2019.
(2) 黑盒攻擊
- PAWS: Paraphrase Adversaries from Word Scrambling. Yuan Zhang, Jason Baldridge, Luheng He. NAACL-HLT 2019.
- Text Processing Like Humans Do: Visually Attacking and Shielding NLP Systems. Steffen Eger, G?zde Gül ?Sahin, Andreas Rücklé, Ji-Ung Lee, Claudia Schulz, Mohsen Mesgar, Krishnkant Swarnkar, Edwin Simpson, Iryna Gurevych.NAACL-HLT 2019.
- Adversarial Over-Sensitivity and Over-Stability Strategies for Dialogue Models. Tong Niu, Mohit Bansal. CoNLL 2018.
- Generating Natural Language Adversarial Examples. Moustafa Alzantot, Yash Sharma, Ahmed Elgohary, Bo-Jhang Ho, Mani Srivastava, Kai-Wei Chang. EMNLP 2018.
- Breaking NLI Systems with Sentences that Require Simple Lexical Inferences. Max Glockner, Vered Shwartz, Yoav Goldberg ACL 2018.
- AdvEntuRe: Adversarial Training for Textual Entailment with Knowledge-Guided Examples. Dongyeop Kang, Tushar Khot, Ashish Sabharwal, Eduard Hovy. ACL 2018.
- Semantically Equivalent Adversarial Rules for Debugging NLP Models. Marco Tulio Ribeiro, Sameer Singh, Carlos Guestrin ACL 2018.
- Robust Machine Comprehension Models via Adversarial Training. Yicheng Wang, Mohit Bansal. NAACL-HLT 2018.
- Adversarial Example Generation with Syntactically Controlled Paraphrase Networks. Mohit Iyyer, John Wieting, Kevin Gimpel, Luke Zettlemoyer. NAACL-HLT 2018.
- Black-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers. Ji Gao, Jack Lanchantin, Mary Lou Soffa, Yanjun Qi. IEEE SPW 2018.
- Synthetic and Natural Noise Both Break Neural Machine Translation. Yonatan Belinkov, Yonatan Bisk. ICLR 2018.
- Generating Natural Adversarial Examples. Zhengli Zhao, Dheeru Dua, Sameer Singh. ICLR 2018.
Adversarial Examples for Evaluating Reading Comprehension Systems. Robin Jia, and Percy Liang. EMNLP 2017.
(3) 白盒攻擊
- On Adversarial Examples for Character-Level Neural Machine Translation. Javid Ebrahimi, Daniel Lowd, Dejing Dou. COLING 2018.
- HotFlip: White-Box Adversarial Examples for Text Classification. Javid Ebrahimi, Anyi Rao, Daniel Lowd, Dejing Dou. ACL 2018.
- Towards Crafting Text Adversarial Samples. Suranjana Samanta, Sameep Mehta. ECIR 2018.
(4) 同時探討黑盒和白盒攻擊
- TEXTBUGGER: Generating Adversarial Text Against Real-world Applications. Jinfeng Li, Shouling Ji, Tianyu Du, Bo Li, Ting Wang. NDSS 2019.
- Comparing Attention-based Convolutional and Recurrent Neural Networks: Success and Limitations in Machine Reading Comprehension. Matthias Blohm, Glorianna Jagfeld, Ekta Sood, Xiang Yu, Ngoc Thang Vu. CoNLL 2018.
- Deep Text Classification Can be Fooled. Bin Liang, Hongcheng Li, Miaoqiang Su, Pan Bian, Xirong Li, Wenchang Shi.IJCAI 2018.
(5) 對抗防御
- Combating Adversarial Misspellings with Robust Word Recognition. Danish Pruthi, Bhuwan Dhingra, Zachary C. Lipton. ACL 2019.
評估
(6) 對文本攻擊和防御研究提出新的評價方法
- On Evaluation of Adversarial Perturbations for Sequence-to-Sequence Models. Paul Michel, Xian Li, Graham Neubig, Juan Miguel Pino. NAACL-HLT 2019
參考文獻:
感謝這些大佬和老師們的分享和總結,秀璋受益匪淺,再次感激,
[1] AI安全 - 智能時代的攻守道
[2] https://arxiv.org/abs/1812.05271
[3] (強烈推薦)NLP中的對抗樣本 - 山竹小果
[4] TextBugger:針對真實應用生成對抗文本 - 人帥也要多讀書
[5] 論文閱讀 | TextBugger: Generating Adversarial Text Against Real-world Applications
[6] 對抗攻擊概念介紹 - 機器學習安全小白
[7] Li J, Ji S, Du T, et al. TextBugger: Generating Adversarial Text Against Real-world Applications[J]. arXiv: Cryptography and Security, 2018.
(By:Eastmount 2020-10-18 晚上10點 http://blog.csdn.net/eastmount/ )
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/181367.html
標籤:其他
下一篇:搭建網站,需要幾種服務器?