深度神經網路(Deep Neural Networks, 以下簡稱DNN)是深度學習的基礎,而要理解DNN,首先我們要理解DNN模型,下面我們就對DNN的模型與前向傳播演算法做一個總結,
https://zhuanlan.zhihu.com/p/29815081
1 從感知機到神經網路
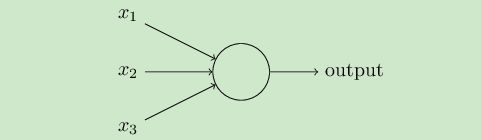
感知機的模型,它是一個有若干輸入和一個輸出的模型,如下圖:
輸出和輸入之間學習到一個線性關系,得到中間輸出結果:
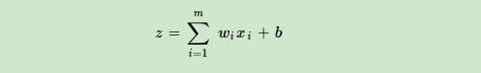
接著是一個神經元激活函式:
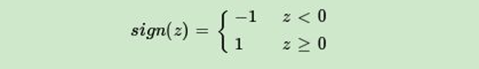
從而得到想要的結果1或者-1.
這個模型只能用于二元分類,且無法學習比較復雜的非線性模型,因此在工業界無法使用,而神經網路則在感知機的模型上做了擴展,總結下主要有三點:
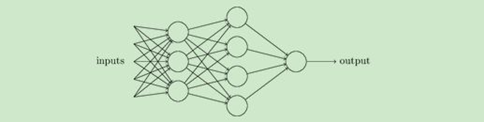
(1)加入了隱藏層,隱藏層可以有多層,增強模型的表達能力,如下圖實體,當然增加了這么多隱藏層模型的復雜度也增加了好多,
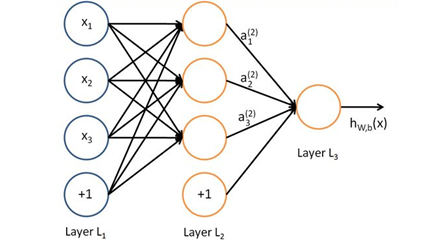
(2)輸出層的神經元也可以不止一個輸出(輸出層有多個神經元),可以有多個輸出,這樣模型可以靈活的應用于分類回歸,以及其他的機器學習領域比如降維和聚類等,多個神經元輸出的輸出層對應的一個實體如下圖,輸出層現在有4個神經元了,
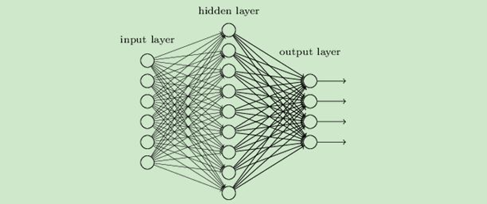

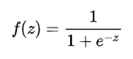
還有后來出現的tanh, softmax,和ReLU等,通過使用不同的激活函式,神經網路的表達能力進一步增強,
2 DNN的基本結構
神經網路是基于感知機的擴展,而DNN可以理解為有很多隱藏層的神經網路,多層神經網路和深度神經網路DNN其實也是指的一個東西,DNN有時也叫做多層感知機(Multi-Layer perceptron,MLP),
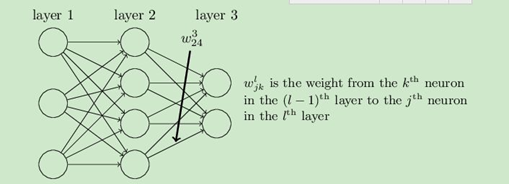
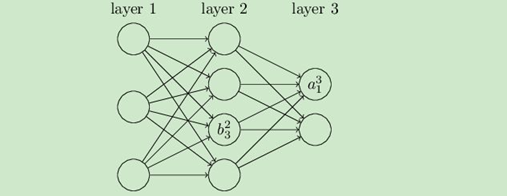
從DNN按不同層的位置劃分,DNN內部的神經網路層可以分為三類,輸入層,隱藏層和輸出層,如下圖示例,一般來說第一層是輸入層,最后一層是輸出層,而中間的層數都是隱藏層,
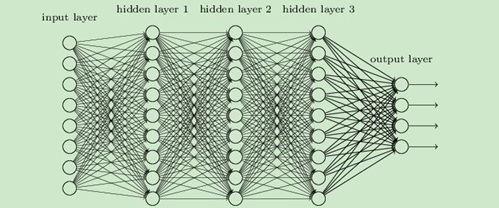
層與層之間是全連接的,也就是說,第i層的任意一個神經元一定與第i+1層的任意一個神經元相連,雖然DNN看起來很復雜,但是從小的區域模型來說,還是和感知機一樣,即一個線性關系:
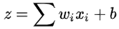
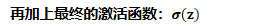

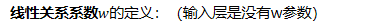
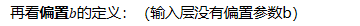
3 DNN前向傳播演算法數學原理



所謂的DNN前向傳播演算法就是利用若干個權重系數矩陣W,偏倚向量b來和輸入值向量x進行一系列線性運算和激活運算,從輸入層開始,一層層的向后計算,一直到運算到輸出層,得到輸出結果為值,
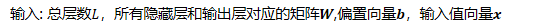

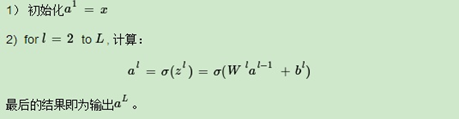
5 DNN的反向傳播演算法
5.1要解決的問題:


可以用一個合適的損失函式來度量訓練樣本的輸出損失,接著對這個損失函式進行優化求最小化的極值,對應的一系列線性系數矩陣W,偏置向量b即為我們的最終結果,在DNN中,損失函式優化極值求解的程序最常見的一般是通過梯度下降法來一步步迭代完成的,也可以是其他的迭代方法比如牛頓法與擬牛頓法,
5.2反向傳播演算法的基本思路:
在進行DNN反向傳播演算法前,我們需要選擇一個損失函式,來度量訓練樣本計算出的輸出和真實的訓練樣本輸出之間的損失,
DNN可選擇的損失函式有不少,為了專注演算法,這里使用最常見的均方差來度量損失,即對于每個樣本,我們期望最小化下式:



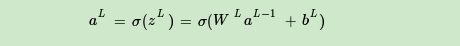
對于輸出層的引數,損失函式變為:
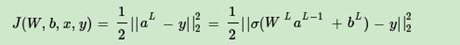
求解W,b的梯度:
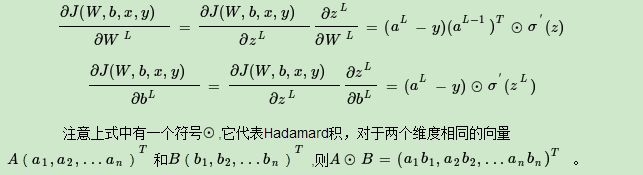


5.3DNN反向傳播演算法程序:
由于梯度下降法有批量(Batch),小批量(mini-Batch),隨機三個變種,為了簡化描述,這里我們以最基本的批量梯度下降法為例來描述反向傳播演算法,實際上在業界使用最多的是mini-Batch的梯度下降法,區別僅僅在于迭代時訓練樣本的選擇,


6 均方差損失函式+Sigmoid激活函式的問題
在講反向傳播演算法時,我們用均方差損失函式和Sigmoid激活函式做了實體,首先我們就來看看均方差+Sigmoid的組合有什么問題,
首先我們回顧下Sigmoid激活函式的運算式為:
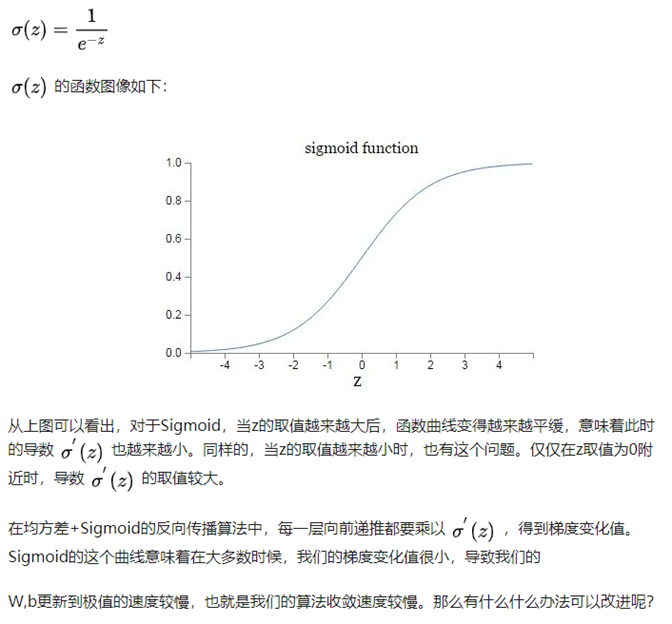
7 交叉熵損失函式+Sigmoid激活函式改進DNN演算法收斂速度
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/18173.html
標籤:其他
上一篇:0x0F72E224 (ucrtbased.dll)處(位于 project1.exe 中)引發的例外: 0xC0000005: 寫入位置 0x00B00000 時發生訪問沖突。