假設檢驗實際上是用反證法做出非對即錯的判斷:先假定原假設是對的,然后將抽樣資料代入相應的分布中去驗證,觀察原假設的數值是落在接受域還是拒絕域,由此做出是接受還是拒絕原假設的判斷,
值得注意的是,不同于以往嚴格的數學證明,假設檢驗是建立在小概率事件原理的基礎之上,由于小概率事件也有可能發生,因此并不能百分之百確定原假設一定不成立,也就是說,原假設也有判斷錯誤的時候,
兩種錯誤型別
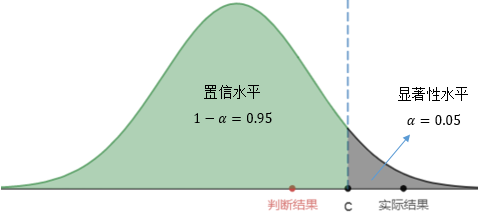
假設檢驗有兩種判斷錯誤的型別,統計學家給出了專業的名稱:第一類錯誤和第二類錯誤,
第一類錯誤(false reject):錯誤地拒絕,H0是對的,卻拒絕了它,也就是說,計算結果落在拒絕域,但真實結果是在接受域,
第二類錯誤(false accept):錯誤地接受,H0是錯的,卻接受了它,也就是說,計算結果落在接受域,但真實結果是在拒絕域,
第一類錯誤也叫Ⅰ 型錯誤或棄真錯誤,第二類錯誤也叫Ⅱ 型錯誤或存偽錯誤,我覺得還是忘記這些文縐縐名稱,記住false reject和false accept即可,畢竟這兩個英文短語更直白,更容易理解,
假設檢驗的理想情況是能過做出與實際相符的正確斷言,但由于抽樣資料的隨機性,根據樣本計算的統計量必然會與整體的真實數值存在差異,這種差異可能導致出現四種判斷結果:

錯誤的概率
既然假設檢驗無法保證百分之百有效,那么我們就需要研究兩類錯誤出現的概率,由此將假設檢驗的功效數值化,
先來看第一類錯誤,
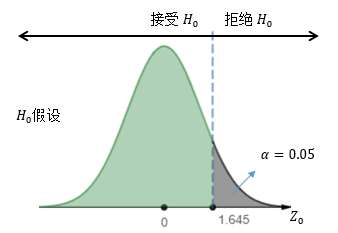
第一類錯誤是在H0正確的時候錯誤地卻拒絕了它,這就意味著我們的判斷結果落在了拒絕域內:
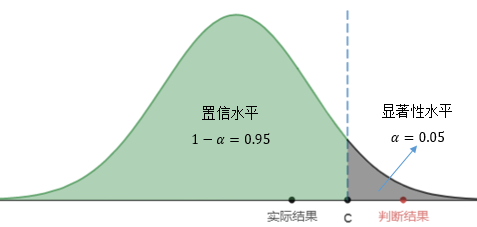
結果落在拒絕域內的概率與顯著性水平一致,因此α的數值決定了出現第一類錯誤概率:
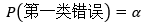
隨著α的減小,第一類錯誤出現的概率也隨之減小,當α=0時,第一類錯誤完全消失,也就是永遠不會拒絕H0,這有點像過去的“守舊派”對于“法先王”的絕對擁護,無論時代怎么進步,“法先王”都必須服從,任何改革都視為大逆不道,
可以看出,由于α的值很小,所以犯第一類錯誤的幾率也很小,
再來看第二類錯誤,
第二類錯誤是在H0錯誤的時候接受了它,一個本應落在拒絕域內的點卻落在了接受域內:
我們用β表示第二類錯誤出現的概率,只要α確定了,β也就確定了,一個草率的判斷是β=1-α,按照這種計算方式,β=0.95,這意味著第二類錯誤出現的概率高達95%!如果這樣,那么假設檢驗還有什么用?
實際上β的計算比α難得多,
我們延用產品元件的故事,μ0是改善前總體的均值,μ1是改善后總體的均值,改善前后的標準差一致,都是σ=6,
原假設H0:改善前與改善后是同一個正態分布,μ0=μ1=600,
備擇假設H1:改善前與改善后是不同的正態分布,μ0 =600< μ1=603,
公司用新技術制造了大量元件,從中多次抽取容量是m(m≥30)的樣本進行檢驗,根據中心極限定理,樣本均值的分布服從均值為總體均值,方差為總體方差1/m的正態分布:
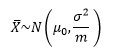
對樣本均值進行標準化處理:
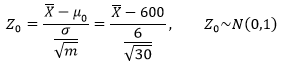
使用0.05顯著性水平,在標準正態分布下,查表可知臨界值是1.645,
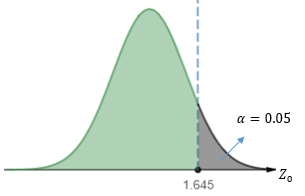
當Z0 > 1.645時,將拒絕H0假設,
再來看均值的逆運算:
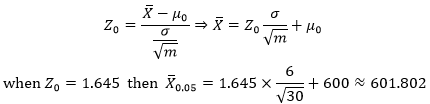
也就是說,如果抽樣的均值大于601.802,就應該拒絕相信H0,
現在可以計算出標準正態分布下β區域的臨界值:
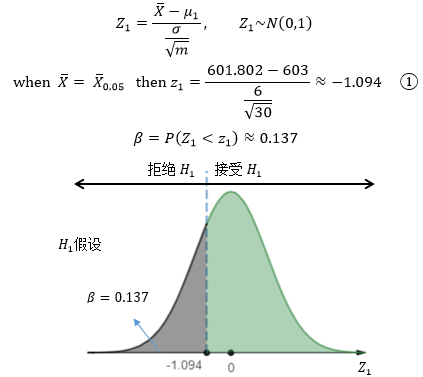
結論是,如果改善后的功率均值是603,那么以此為條件,犯第二類錯誤的概率是β=0.137,通過β的計算程序可以看出,只有當H1假設是一個固定的值時,才能計算出β,如果H1假設不是固定,比如只給出了μ1 > 603,那么將無法根據①計算出z1,也就無法進一步求得β,
一個常見的問題是,既然一開始就知道了H0和H1的均值和方差,為什么還要使用標準化處理?直接計算臨界值豈不是更簡單?
我們的確可以直接通過計算機解求得X~(μ0, σ2)時的臨界值,但這是總體分布下的臨界值,而我們的假設檢驗是基于抽樣,并非總體,此時用到的理論是中心極限定理,因此才大費周章地使用標準化形態,
出處:微信公眾號 "我是8位的"
本文以學習、研究和分享為主,如需轉載,請聯系本人,標明作者和出處,非商業用途!
掃描二維碼關注作者公眾號“我是8位的”

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/181847.html
標籤:其他
上一篇:記一次坑爹的electron安裝程序(windows下)
下一篇:Markdown使用學習