作者|MOHD SANAD ZAKI RIZVI
編譯|VK
來源|Analytics Vidhya
概述
- 由AI生成的假新聞(神經假新聞)對于我們的社會可能是一個巨大的問題
- 本文討論了不同的自然語言處理方法,以開發出對神經假新聞的強大防御,包括使用GPT-2檢測器模型和Grover(AllenNLP)
- 每位資料科學專業人員都應了解什么是神經假新聞以及如何應對它
介紹
假新聞是當今社會關注的主要問題,它與資料驅動時代的興起并駕齊驅,這并非巧合!
假新聞是如此廣泛,以至于世界領先的字典都試圖以自己的方式與之抗爭,
- Dictionary.com將misinformation'列為2018年度最佳詞匯
- 牛津詞典幾年前選擇“post-truth”作為年度最佳詞匯

那么機器學習在其中扮演了什么角色呢?我相信你一定聽說過一種機器學習技術,它甚至可以生成模仿名人的假視頻,類似地,自然語言處理(NLP)技術也被用來生成假文章,這一概念被稱為“神經假新聞”,
過去幾年,我一直在自然語言處理(NLP)領域作業,雖然我喜歡取得突破性進展的速度,但我也對這些NLP框架被用來創建和傳播虛假資訊的方式深感擔憂,
高級的預訓練NLP模型,如BERT,GPT-2,XLNet等,很容易被任何人下載,這就加大了他們被利用來傳播宣傳和社會混亂的風險,
在這篇文章中,我將對神經假新聞做一個全面的研究——從定義它是什么,到理解識別這種錯誤資訊的某些方法,我們還將詳細了解這些最先進的語言模型本身的內部作業原理,
目錄
-
什么是神經假新聞?
-
大型語言模型如何被濫用來產生神經假新聞?
-
如何檢測神經假新聞?
-
事實核查
-
使用GLTR(HarvardNLP)進行統計分析
-
利用模型檢測神經假新聞
- GPT-2探測器
- Grover 模型
-
-
當前檢測技術的局限性及未來研究方向
什么是神經假新聞?
我相信你最近聽說過“假新聞”這個詞,它幾乎在每個社交媒體平臺上都廣泛使用,近年來,它已成為社會和政治威脅的代名詞,但什么是假新聞?
以下是維基百科的定義:
“假新聞(又稱垃圾新聞、假新聞或騙局新聞)是指通過傳統新聞媒體(印刷和廣播)或在線社交媒體故意造謠傳播的新聞形式,”
假新聞是指任何事實上錯誤的、歪曲事實的、病毒性傳播(或可能傳播給目標受眾)的新聞,它既可以通過常規新聞媒體傳播,也可以在Facebook、Twitter、WhatsApp等社交媒體平臺上傳播,
假新聞,如“登月是假的”難以區分的原因是,它仔細模仿了真實新聞通常遵循的“風格”和“模式”,這就是為什么未經訓練的人眼很難分辨,
另外,有趣的是,假新聞已經存在了很長很長時間(實際上,貫穿我們的歷史),
神經假新聞
神經假新聞是利用神經網路模型生成的任何假新聞,或者更正式地定義它:
神經假新聞是一種有針對性的宣傳,它緊密模仿由神經網路生成的真實新聞的風格,
下面是OpenAI的GPT-2模型生成的神經假新聞的一個例子:

“system prompt”是一個人給模型的輸入,“model completion”是GPT-2模型生成的文本,
你憑直覺猜到后一部分是機器寫的嗎?請注意,該模型能夠多么令人難以置信地將提示進行擴展,形成一個完整故事,這看起來乍一看令人信服,
現在,如果我告訴你GPT-2模型可以免費供任何人下載和運行呢?這正是研究界關注的問題,也是我決定寫這篇文章的原因,
大型語言模型如何被濫用來產生神經假新聞?
語言建模是一種NLP技術,模型通過從句子本身理解背景關系來學習預測句子中的下一個單詞或缺失的單詞,以谷歌搜索為例:
這是一個正在運行的語言模型的例子,通過讓模型預測一個句子中的下一個單詞或一個丟失的單詞,我們讓模型學習語言本身的復雜性,
這個模型能夠理解語法是如何作業的,不同的寫作風格,等等,這就是為什么這個模型能夠生成一段對未經訓練的人來說可信的文本,當同樣的模式被用來產生有針對性的宣傳來迷惑人們時,問題就出現了,
下面是一些非常強大的最先進的語言模型,它們非常擅長生成文本,
1.谷歌的BERT
BERT是一個由Google設計的語言模型,它打破了最先進的記錄,該框架是最近各種研究實驗室和公司大力訓練和研究大型語言模型的原因,
BERT和Facebook、XLM、XLNet、DistilBERT等公司的RoBERTa在文本生成方面表現非常出色,
2.OpenAI的GPT-2模型
來自OpenAI的GPT、GPT-2和GPT-Large等一系列語言模型,因其文本生成能力而在媒體上引起轟動,這些是我們絕對應該知道的一些語言模型,
3.Grover
Grover是AllenNLP提出的一個有趣的新語言模型,它不僅能夠生成文本,而且能夠識別其他模型生成的偽文本,
我們將在文章的后面進一步了解Grover,
如何檢測神經假新聞?
我們怎樣才能發現或找出一條新聞是假的?目前,處理神經假新聞的方法主要有三種,都取得了很好的效果,
I.事實核查
檢查一條在網上傳播的新聞是假的還是真的,最基本的方式是什么?我們可以簡單地谷歌它,參考值得信賴的新聞網站,并事實檢查他們是否有相同或類似的故事,

盡管這一步讓人感覺像是常識,但它實際上是確保一條新聞真實性的最有效方法之一,
但這一步只處理一種虛假新聞:來自單一來源的新聞,如果我們想處理那些已經走紅并被我們周圍的媒體大量報道的新聞呢?
這通常是一種由神經網路生成的新聞,因為新聞在“風格”和“結構”上與真實新聞非常相似,
讓我們學習一些處理“機器生成”文本的方法,
II.使用GLTR(HarvardNLP)進行統計分析
GLTR是由HarvardNLP和MIT-IBM Watson實驗室的專家們設計的一個工具,
GLTR用于識別機器生成文本的主要方法是通過對給定文本進行的統計分析和可視化,
下面是GLTR介面:
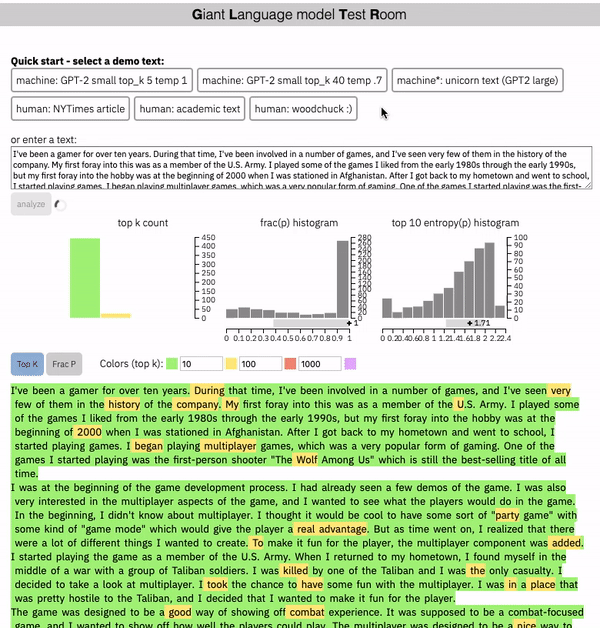
GLTR檢測生成的文本的中心思想是使用最初用于生成該文本片段的相同(或類似)模型,
原因很簡單,一個語言模型直接生成的單詞來自于它從訓練資料中學習到的概率分布,
下面是一個示例,請注意語言模型如何生成一個概率分布,作為對所有可能單詞具有不同概率的輸出:
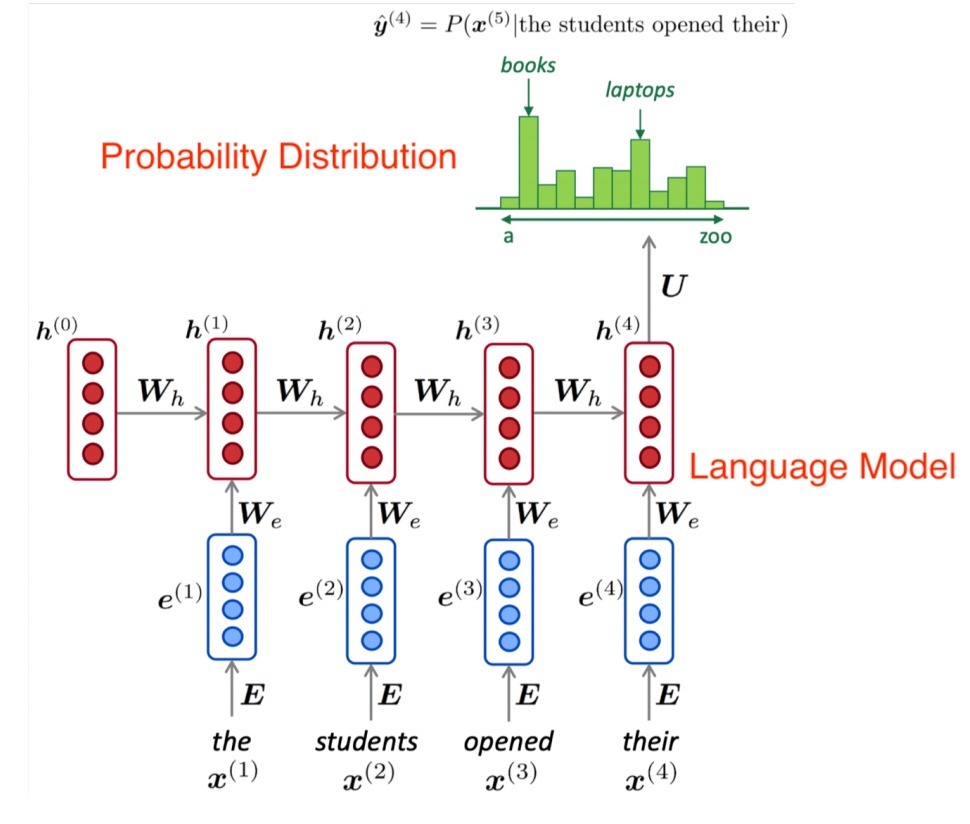
由于我們已經知道從給定的概率分布中抽取單詞的技術,如最大抽樣、k-max抽樣、波束搜索、核抽樣等,我們可以很容易地交叉檢查給定文本中的單詞是否遵循特定的分布,
如果是的話,而且在給定的文本中有多個這樣的單詞,那么這基本上可以確認它是機器生成的,
讓我們用一個例子運行GLTR來理解這個概念!
安裝GLTR
在使用GLTR之前,我們需要在系統上安裝它,首先克隆專案的GitHub存盤庫:
git clone https://github.com/HendrikStrobelt/detecting-fake-text.git
克隆存盤庫后,將cd放入其中并執行pip安裝:
cd detecting-fake-text && pip install -r requirements.txt
接下來,下載預先訓練好的語言模型,可以通過運行服務器來完成此操作:
python server.py
GLTR目前支持兩種模型:BERT和GPT-2,你可以在兩者之間進行選擇;如果未提供任何選項,則使用GPT-2:
python server.py --model BERT
這將開始在你的機器上下載相應的預訓練模型,如果你的網速很慢,給它點時間,
當一切就緒時,服務器將從埠5001啟動,你可以直接轉到http://localhost:5001訪問它:
GLTR是如何作業的?
假設我們有下面這段文字,我們要檢查它是否由GPT-2這樣的語言模型生成:
How much wood would a woodchuck chuck if a woodchuck could chuck wood?
GLTR將接受這個輸入并分析GPT-2對每個輸入位置的預測,
請記住,語言模型的輸出是該模型知道的所有單詞的排名,因此,我們根據GPT-2的排名將能夠迅速查看輸入文本中每個單詞,
如果我們根據每個單詞在前10名中是否是綠色、前100名中是否是黃色和前1000名中是否是紅色對其進行顏色編碼,我們將得到以下輸出:

現在,我們可以直觀地看到,根據GPT-2,每個單詞的可能性有多大,根據模型,綠色和黃色是很有可能的,而紅色是意料之外的詞,這意味著它們很可能是由人類書寫的,這正是你將在GLTR介面上看到的!
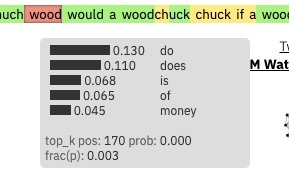
如果你需要更多的資訊,你可以把滑鼠懸停在“wood”這個詞上,你會看到一個小盒子,上面有這個位置的前5個預測詞及其概率:
我鼓勵你嘗試不同的文本,可以是人類產生的或者機器產生的,GLTR工具本身也已經提供了一些示例:

你會注意到,當你移到真正的文本時,紅色和紫色的單詞數量,即不太可能或罕見的預測,會增加,
此外,GLTR還顯示了三種不同的直方圖,其中包含整個文本的聚合資訊(請查看下面的圖片以供參考):
-
第一個顯示每個類別(前10個、前100個和前1000個)在文本中出現的單詞數
-
第二個例子說明了前一個預測詞和后一個預測詞的概率之比
-
第三個直方圖顯示了預測熵的分布,低不確定性意味著模型對每個預測都非常有信心,而高不確定性意味著低信心
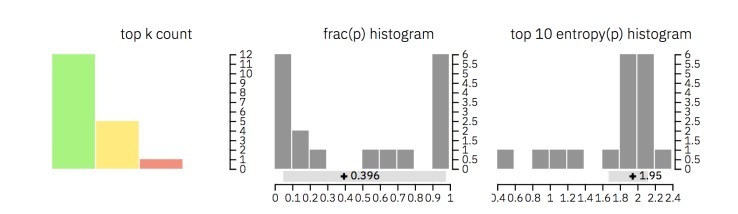
以下是這些直方圖的幫助:
-
前兩個柱狀圖有助于理解輸入文本中的單詞是否從分布的頂部取樣(對于機器生成的文本,基本上就是從分布頂部采樣)
-
最后一個直方圖說明單詞的背景關系是否為檢測系統所熟知(對于機器生成的文本,基本上就是熟知)
GLTR模型將這些多重可視化和概率分布知識結合起來,可以作為一種有效的法醫學工具來理解和識別機器生成的文本,
以下是對GLTR的報道:
“在一項人類受試者研究中,我們發現GLTR提供的注釋方案在不經過任何訓練的情況下將人類對假文本的檢測率從54%提高到72%,”–Gehrmann等人
你可以在最初的研究論文中閱讀更多關于GLTR的內容:https://arxiv.org/pdf/1906.04043.pdf,
利用模型檢測神經假新聞
GLTR是相當令人印象深刻的,因為它使用概率分布和可視化的簡單知識來檢測神經假新聞,但如果我們能做得更好呢
如果我們能訓練一個大的模型來預測一段文字是否是神經假新聞呢?
好吧,這正是我們在這一節要學的
GPT-2 探測器
GPT-2檢測器模型是一個RoBERTa(BERT的變種)模型,它經過微調以預測給定的文本是否是使用GPT-2生成的(作為一個簡單的分類問題),
RoBERTa是Facebook人工智能研究開發的一個大型語言模型,是對Google的BERT的改進,這就是為什么這兩個框架有很大的相似之處,
這里需要注意的一點是,盡管RoBERTa的模型結構與GPT-2的模型結構非常不同,因為前者是一個屏蔽語言模型(如BERT),與GPT-2不同,前者在本質上不是生成的,GPT-2在識別由它生成的神經假新聞方面仍然顯示了大約95%的準確性,
這個模型的另一個優點是,與我們在本文中討論的其他方法相比,它的預測速度非常快,
讓我們看看它!
安裝GPT-2探測器模型
這個探測器模型的安裝步驟非常簡單,就像GLTR一樣,
我們首先需要克隆存盤庫:
git clone https://github.com/openai/gpt-2-output-dataset.git
然后
cd gpt-2-output-dataset/ && pip install -r requirements.txt
接下來,我們需要下載預訓練好的語言模型,通過運行以下命令執行此操作:
wget https://storage.googleapis.com/gpt-2/detector-models/v1/detector-base.pt
這一步可能需要一些時間,完成后,你可以啟動探測器:
python -m detector.server detector-base.pt --port 8000
一切就緒后,服務器將從埠8000啟動,你可以直接轉到http://localhost:8000訪問它!

有了這個,你就可以嘗試GPT-2探測器模型了!
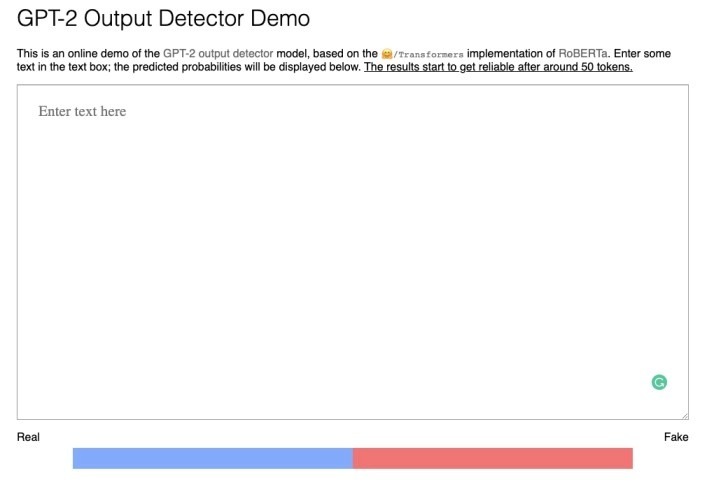
識別神經假新聞
探測器模型的介面非常簡單,我們只需復制粘貼一段文本,它就會告訴我們它是“真的”還是“假的”,這取決于它是否由機器(GPT-2模型)生成,
以下是我使用Transformers 2.0庫從GPT-2生成的文本:

如你所見,盡管文本看起來很有說服力和連貫性,但模型直接將其歸類為“假的”,準確率為99.97%,
這是一個非常有趣的工具使用,我建議你去嘗試不同的例子,生成和未生成的文本,看看它如何執行!
在我的例子中,我通常注意到這個模型只能很好地識別GPT-2模型生成的文本,這與Grover完全不同,Grover是我們將在下一節中學習的另一個框架,Grover可以識別由各種語言模型生成的文本,
你可以在Facebook的博客上閱讀更多關于RoBERTa的架構和訓練方法,如果你對如何實作檢測器模型感到好奇,可以在GitHub上檢查代碼,
Grover
Grover是我在本文討論的所有選項中最喜歡的工具,與GLTR和GPT-2檢測器模型僅限于特定模型不同,它能夠將一段文本識別為由大量多種語言模型生成的偽文本,
作者認為,檢測一段文本作為神經假新聞的最佳方法是使用一個模型,該模型本身就是一個能夠生成此類文本的生成器,用他們自己的話說:
“生成器最熟悉自己的習慣、怪癖和特性,也最熟悉類似人工智能模型的特性,特別是那些接受過類似資料訓練的人工智能模型,”–Zellers等人
乍一看聽起來有違直覺,不是嗎?為了建立一個能夠檢測出神經假新聞的模型,他們繼續開發了一個模型,這個模型一開始就非常擅長生成這樣的假新聞!
聽起來很瘋狂,但背后有自己的一個科學邏輯,
Grove是怎么作業的?
問題定義
Grover將檢測神經假新聞的任務定義為一個具有兩個模型的對抗游戲:
-
設定中有兩個模型用于生成和檢測文本
-
對抗模型的目標是產生虛假的新聞,這些新聞可以是病毒性傳播的,或者對人類和驗證模型都有足夠的說服力
-
驗證器對給定文本是真是假進行分類:

- 驗證者的訓練資料包括無限的真實新聞,但只有一些來自特定對手的假新聞
- 這樣做是為了復制真實世界的場景,在真實世界中,對手提供的虛假新聞數量與真實新聞相比要少得多
這兩種模式的雙重目標意味著,攻擊者和捍衛者之間在“競爭”,既產生虛假新聞,又同時發現虛假新聞,隨著驗證模型的改進,對抗模型也在改進,
神經假新聞的條件生成
神經假新聞的最明顯特征之一是它通常是“有針對性的”內容,例如點擊誘餌或宣傳,大多數語言模型(例如BERT等)都不允許我們創建這種受控文本,
Grover支持“受控”文本生成,這僅僅意味著除了模型的輸入文本之外,我們可以在生成階段提供額外的引數,這些引數將引導模型生成特定的文本,
但這些引數是什么?考慮一下新聞文章——有助于定義新聞文章的結構引數是什么?以下是Grover的作者認為生成文章所必需的一些引數:
-
領域:文章發布的地方,它間接地影響樣式
-
日期:出版日期
-
作者:作者姓名
-
標題:文章的標題,這影響到文章的生成
-
正文:文章的正文
結合所有這些引數,我們可以通過聯合概率分布對一篇文章進行建模:

現在,我將不再深入討論如何實作這一點的基礎數學,因為這超出了本文的范圍,但是,為了讓你了解整個生成程序的樣子,這里有一個示意圖:

下面是流程:
-
在a行中,正文由部分背景關系生成(缺少作者欄位)
-
在b行中,模型生成作者
-
在c行中,該模型重新生成提供的標題,使之更為真實
架構和資料集
Grover使用與GPT2相同的架構:
-
有三種型號,最小的模型Grover-Base有12層,1.24億個引數,與GPT和BERT-Base相當
-
下一個模型Grover Large有24個層和3.55億個引數,與BERT Large相當
-
最大的模型Grover Mega有48層和15億個引數,與GPT2相當
用來訓練Grover的RealNews資料集是Grover的作者自己創建的,資料集和創建它的代碼是開源的,因此你可以下載并按原樣使用它,也可以按照Grover的規范生成自己的資料集,
安裝Grover
你可以按照安裝說明安裝Grover,并在自己的機器上運行它的生成器和檢測器工具,請記住,該模型的大小是巨大的(壓縮后還有46.2G!)所以在你的系統上安裝它可能是一個挑戰,
這就是為什么我們會使用在線檢測器和生成器工具,
使用Grover進行生成和檢測
你可以通過以下鏈接訪問該工具:
https://grover.allenai.org/
你可以玩一下Generate選項,看看Grover生成神經假新聞的能力有多強,因為我們有興趣檢查Grover的檢測能力,所以讓我們轉到“檢測”選項卡(或轉到以下鏈接):
https://grover.allenai.org/detect
案例研究1:
我們要測驗的文本與前面看到的GPT-2生成的文本相同:
當你點擊“檢測假新聞”按鈕時,你會注意到Grover很容易將其識別為機器生成的:

案例研究2:
我們要測驗的下一篇文章來自紐約時報:
你會發現格羅弗確實能認出它是一個人寫的:

案例研究3:
這些都是簡單的例子,如果我給它一段技術性的文字怎么辦?像技術博客里的解釋
對于我自己提供的文本,Grover失敗了,因為它沒有接受過此類技術文章的訓練:
但是GPT-2探測器模型卻起作用了,因為它是在各種各樣的網頁上被訓練的(800萬!),

這只是為了表明沒有一個工具是完美的,
案例研究4:
她是我們要做的最后一個實驗,我們將測驗機器生成的新聞,這些新聞不是“假的”,只是自動生成新聞的一個例子,本文摘自華盛頓郵報:
有趣的是,GPT-2探測器模型說它根本不是機器生成的新聞:

但同時,Grover能夠識別出它是機器撰寫的文本,概率略低(但它還是能找出答案!):

現在,不管你是否認為這是“假”新聞,事實是它是由機器生成的,如何對這類文本進行分類將取決于你的目標是什么以及你的專案試圖實作什么,
簡而言之,檢測神經假新聞的最佳方法是綜合運用所有這些工具并得出比較結論,
當前虛假新聞檢測技術的局限性及未來研究方向
很明顯,目前的檢測技識訓不完善,還有發展的空間,麻省理工學院計算機科學與人工智能實驗室(CSAIL)最近對現有的神經假新聞檢測方法進行了研究,他們的一些發現令人大開眼界,
現有神經假新聞檢測技術的局限性
研究的主要結論是,GLTR、Grover等方法用于神經假新聞檢測的現有方法是不完全的,
這是因為僅僅發現一條文本是否是“機器生成”是不夠的,可能有一條合法的新聞是通過諸如自動完成、文本摘要等工具機器生成的,
例如,著名的寫作應用程式Grammarly使用某種形式的GPT-2來幫助糾正文本中的語法錯誤,
這類案例的另一個例子是本文前一節的案例研究4,其中一個程式被《華盛頓郵報》用來生成體育新聞,
反之,也可能存在被攻擊者輕微破壞/修改的人工文本,根據現有方法,這些文本將被歸類為非神經假新聞,
下面是一個例子,總結了探測器模型的上述困境:
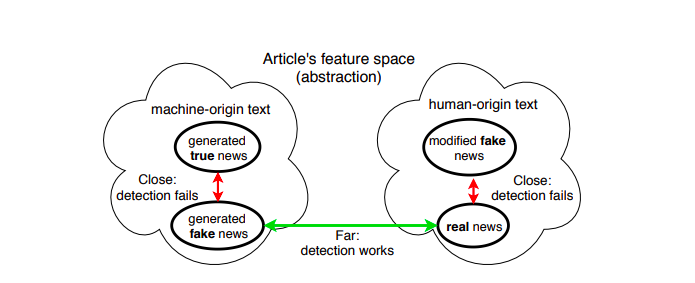
從上圖中可以清楚地看到,由于生成的神經假新聞和真實新聞的特征空間非常遠,所以模型很容易對哪一個是假的進行分類,
此外,當模型必須在真實生成的新聞和神經假新聞之間進行分類時(如我們之前看到的案例研究4),由于兩者的特征空間非常接近,因此模型無法檢測,
當模型必須區分生成的人工新聞和經過一點修改而變成假的新聞時,也會看到同樣的行為,
我不想詳細介紹,但作者進行了多次實驗得出這些結論,你可以閱讀他們的論文了解更多:https://arxiv.org/pdf/1908.09805.pdf,
這些結果使作者得出結論,為了定義/檢測神經假新聞,我們必須考慮真實性,而不是來源(來源,無論是機器寫的還是人類寫的),
我認為這是一個讓我們大開眼界的結論,
未來的研究方向是什么
處理神經假新聞問題的一個步驟是,劍橋大學和亞馬遜去年發布了FEVER,這是世界上最大的事實核查資料集,可用于訓練神經網路檢測假新聞,

盡管由麻省理工學院的同一個研究小組(Schuster等人)分析FEVER時,他們發現FEVER資料集存在某些偏差,使得神經網路更容易通過文本中的模式來檢測假文本,當他們糾正了資料集中的一些偏差時,他們發現模型的準確性如預期的那樣急劇下降,
然后,他們將GitHub上對稱的修正后的資料集熱開源,作為其他研究人員測驗其模型的基準,我認為這對正在積極嘗試解決神經假新聞問題的整個研究界來說是一個好的舉措,
如果你有興趣找到更多關于他們的方法和實驗的資訊,請閱讀他們的原始論文:https://arxiv.org/pdf/1908.05267.pdf,
因此,創建大規模無偏資料集,我認為是未來研究如何處理神經假新聞方向的良好第一步,因為隨著資料集的增加,研究人員和組織建立模型以改進現有基準的興趣也會增加,這和我們過去幾年在NLP(GLUE, SQUAD)和CV(ImageNet)中看到的一樣,
除此之外,當我考慮到我們所遇到的大多數研究時,這里有一些我們可以進一步探索的方向:
-
我個人認為,像Grover和GLTR這樣的工具是檢測神經假新聞的良好起點,它們為我們如何創造性地利用現有知識構建能夠檢測假新聞的系統樹立了榜樣,因此,我們需要在這個方向上進行進一步的研究,改進現有的工具,并不僅針對資料集,而且在現實環境中更有效地驗證它們,
-
FEVER資料集的發布是一個值得歡迎的舉動,它將有助于我們在各種環境中探索和構建更多這樣的帶有假新聞的資料集,因為這將直接推動進一步的研究,
-
通過模型發現文本的準確性是一個具有挑戰性的問題,但是我們需要以某種方式構造它,以便更容易創建有助于訓練能夠根據文本的真實性對其進行身份驗證的模型的資料集,因此,這方面的進一步研究是值得歡迎的,
-
正如Grover和GLTR的作者正確地提到的那樣,我們需要通過在未來發布大型語言模型(如GPT-2、Grover等)來繼續研究社區的開放性,因為只有當我們知道對手有多強大時,我們才能建立強大的防御,
原文鏈接:https://www.analyticsvidhya.com/blog/2019/12/detect-fight-neural-fake-news-nlp/
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/18199.html
標籤:其他
上一篇:Python小白求助!!!
下一篇:這段簡單的代碼我哪里錯了?