作者|Anuj Shrivastav
編譯|VK
來源|Medium

介紹
監督學習描述了一類問題,涉及使用模型來學習輸入示例和目標變數之間的映射,如果存在分類問題,則目標變數可以是類標簽,如果存在回歸問題,則目標變數是連續值,一些模型可用于回歸和分類,我們將在此博客中討論的一種這樣的模型是支持向量機,簡稱為SVM,我的目的是為你提供簡單明了的SVM內部作業,
假設我們正在處理二分類任務,
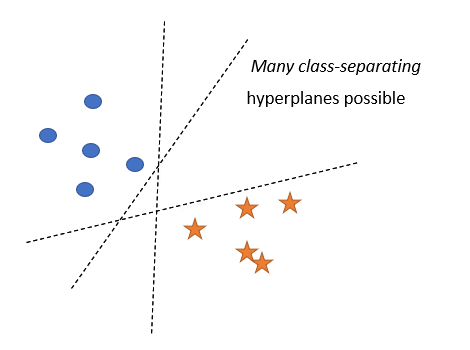
可能有無限多的超平面可以將這兩個類分開,你可以選擇其中任何一個,但是這個超平面能很好地預測新查詢點的類嗎?你不認為離一個類很近的那個平面有利于另一個類嗎?直觀地說,分離兩個類的最佳方法是選擇一個超平面,該超平面與兩個類中最近的點等距,
這就是SVM的作用!
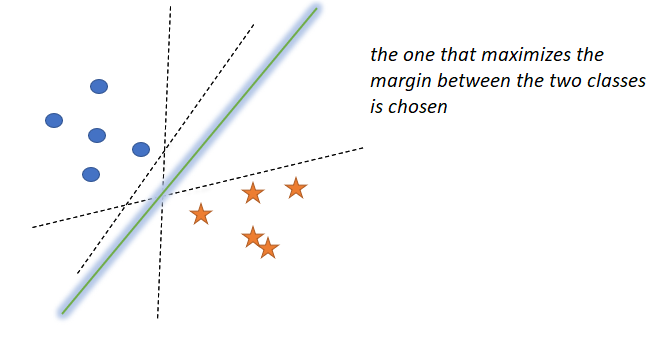
支持向量機的核心思想是:
選擇盡可能廣泛地將+ve點與-ve點分開的超平面π,(ve代表vector,向量,也就是樣本的向量)
設π是分離這兩類的超平面,π+和π_是兩個平行于π的超平面
π?是當我們平行于π移動并與π最近的+ve點接觸時得到的平面
π?是當我們平行于π移動并接觸到π的最近-ve點時得到的平面
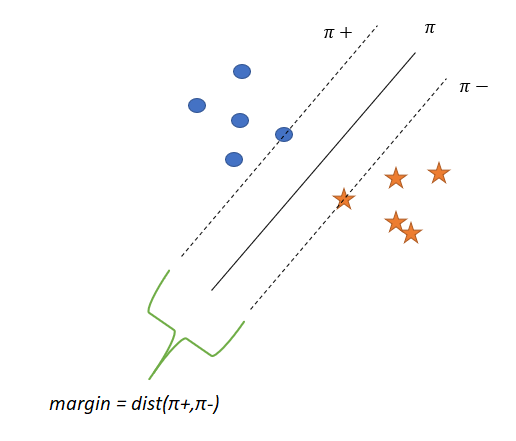
d=margin = dist(π?,π?)
-
SVM試圖找到一個π來最大化間隔,
-
隨著間隔的增加,泛化精度也隨之提高,
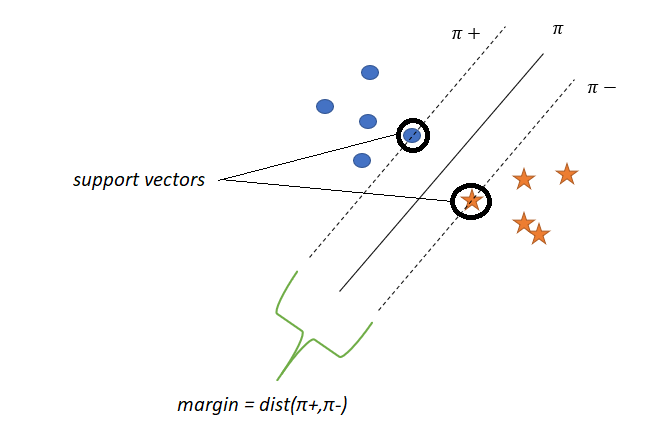
支持向量
位于π?或π?上的點稱為支持向量,
SVM數學公式
π: 邊距最大化的超平面
π: w?x+b=0
設
π?:w?x+b=+1
π?上的任何點或在正方向遠離π?的任何點都標記為正
π?:w?x+b=-1
π?上的任何點或在負方向遠離π?的任何點都標記為負
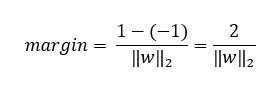
優化問題為
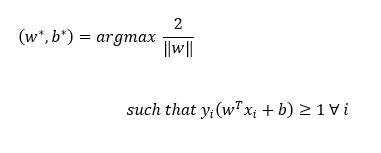
現在,這看起來不錯,但是,它只在我們的資料是線性可分時起作用,否則,我們將無法解決上述優化問題,也無法得到最優的w和b,
假設一個資料不是線性可分的場景:
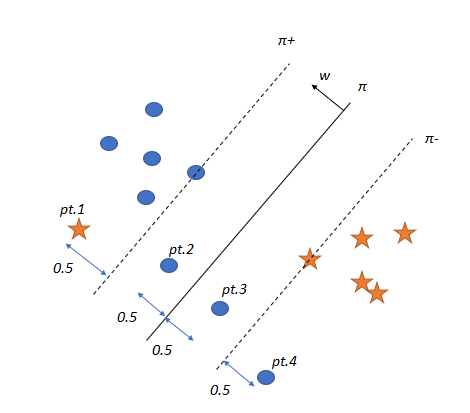
因為這四個點,我們的優化問題永遠不會得到解決,因為這些點y?(w?x+b)不大于1,
這是因為我們的優化問題過于嚴格,它只解決線性可分資料,硬邊距就是這種方法的名稱,
那么,我們可以修改它嗎?我們能不能稍微寬大一點,這樣它就可以處理幾乎線性可分的資料?

我們要做的是,我們做一個松弛變數ζ?(zeta),對應于每個資料點,這樣對于位于+ve區域的+ve點和位于-ve區域的-ve點,
ζ?=0,
這就給我們留下了錯誤的分類點和間隔內的點,
ζ?的含義,以圖為例,當ζ?=2.5
這意味著pt.4在相反的方向上與它的正確超平面(在本例中為π?)相距2.5個單位,
類似地,pt.1與最優超平面(本例中為π?)的方向相反,距離為2.5個單位,
當ζ?增大時,該點在錯誤方向上離最優超平面更遠,

改進優化問題
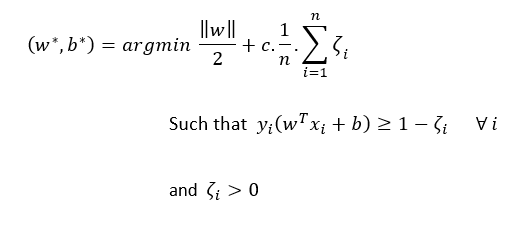
讓我們把它分解
首先,約束條件:
我們知道,

現在:
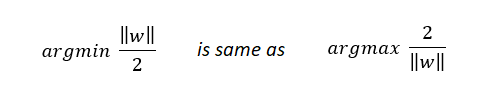
和

c是超引數,
我們可以直觀地認為優化問題為:
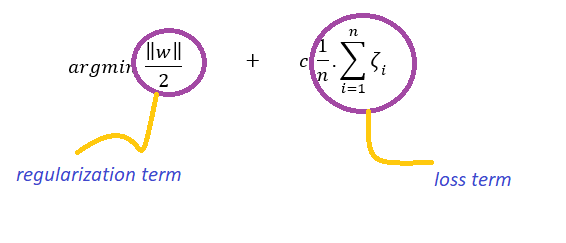
如果c值較高,則損失項的權重更大,從而導致資料的過擬合,
如果c值較低,則正則化項的權重較大,導致資料欠擬合,
SVM對偶形式
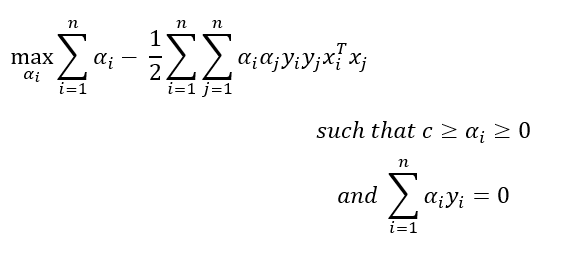
等等!我們怎么得到這個對偶形式的?
這都和最優化有關如果我們深入研究這個問題,我們就會偏離我們的目標,讓我們在另一個博客中討論這個對偶形式,
為什么我們需要這個對偶形式?
對偶形式有時更容易解決,如果對偶間隙非常小,我們會得到相似的結果,特別是支持向量機:對偶形式非常重要,因為它通過核函式開啟了一種解釋支持向量機的新方法(我將在本博客的后面部分告訴你),
注意:在對偶形式中,所有x?都以點積的形式出現,不像原始形式中所有x?都作為獨立點出現,
α?可以被認為是一個拉格朗日乘數
觀察對偶形式:
- 對于每個x?,有相應的α?
- 所有x?都是點積的形式
- 我們對一個新點的分類方式改變如下:
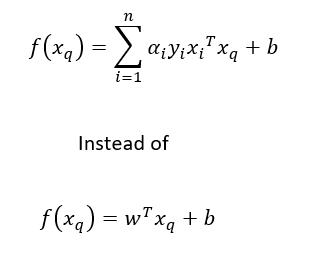
- 支持向量α?>0,非支持向量α?=0,
這意味著只有支持向量才是重要的,這就是將該模型命名為支持向量機的原因,
現在,以對偶形式
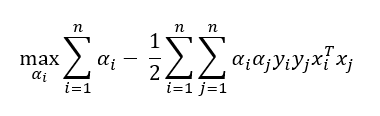
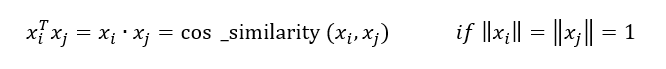
因此,如果給出一個相似矩陣,我們可以使用對偶形式,而不是原始形式,這就是支持向量機的優點,通常,這種相似性(x?,x?)被K(x?,x?)代替,其中K稱為核函式,
核技巧及其背后的直覺
用核函式K(x?,x?)替換相似性(x?,x?)稱為核化,或應用核技巧,
如果你看它,它只是計算x?和x?的點積,那么,有什么了不起的?
讓我們以下面的資料集為例,
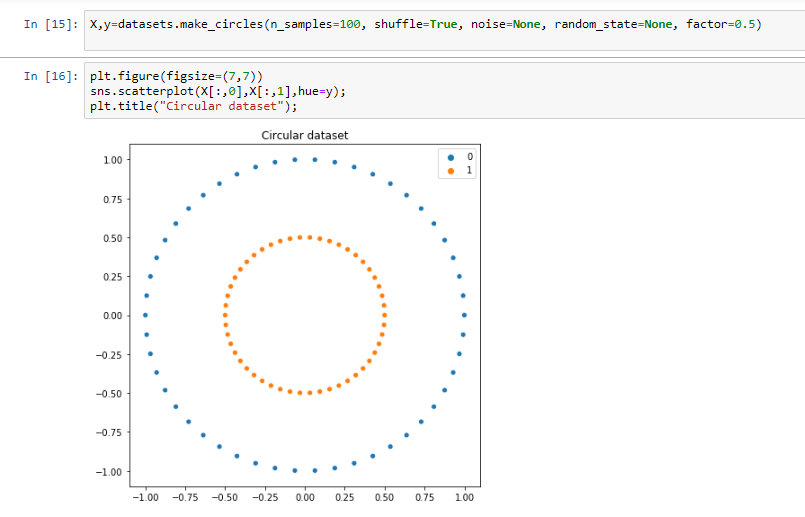
很明顯,在線性模型的幫助下,這兩個類是不能分離的,
現在,將資料集轉換為具有 <x?2,x?2,2x?x?> 的特征的多維資料集,
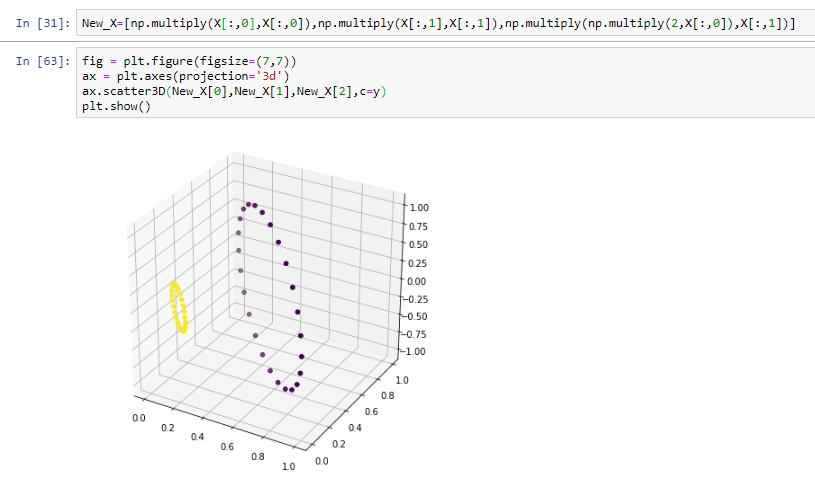
你看到了嗎?應用適當的特征變換和增加維數使資料線性可分,
這就是核支持向量機的作用,它將原始特征映射到一個高維空間中,在該空間中找到間隔最大的超平面,并將該超平面映射到原始維空間中,得到一個非線性決策曲面,而不必實際訪問該高維空間,
所以
線性支持向量機:在x?的空間中尋找間隔最大化超平面
核支持向量機:在x?的變換空間中尋找間隔最大化超平面
因此,核支持向量機也能求解非線性可分資料集,
讓我們看看支持向量機中使用的一些核函式-
多項式核
定義如下:
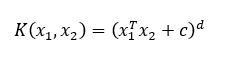
其中
d=資料維度
c=常數
對于二次核,設c=1,即
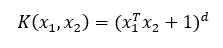
當維度為2
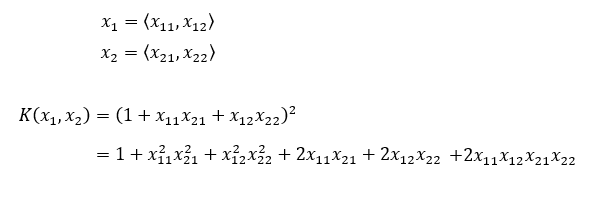
這可以被認為是2個向量x?和x?的乘積,其中:
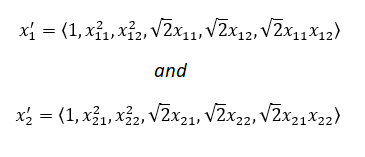
現在維度=d'=6
因此,核化與特征轉換是一樣的,但通常是d'>d,核化是在內部隱式地完成的,
徑向基函式(RBF核)
它是最受歡迎的核,因為你無法確定要選擇哪個核時,可以選擇它
定義如下:
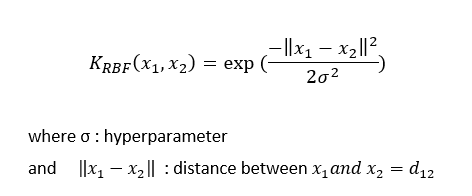
d的效果:
當d增大時,指數部分的分子減小,換句話說,K值或相似度減小,
σ的影響:
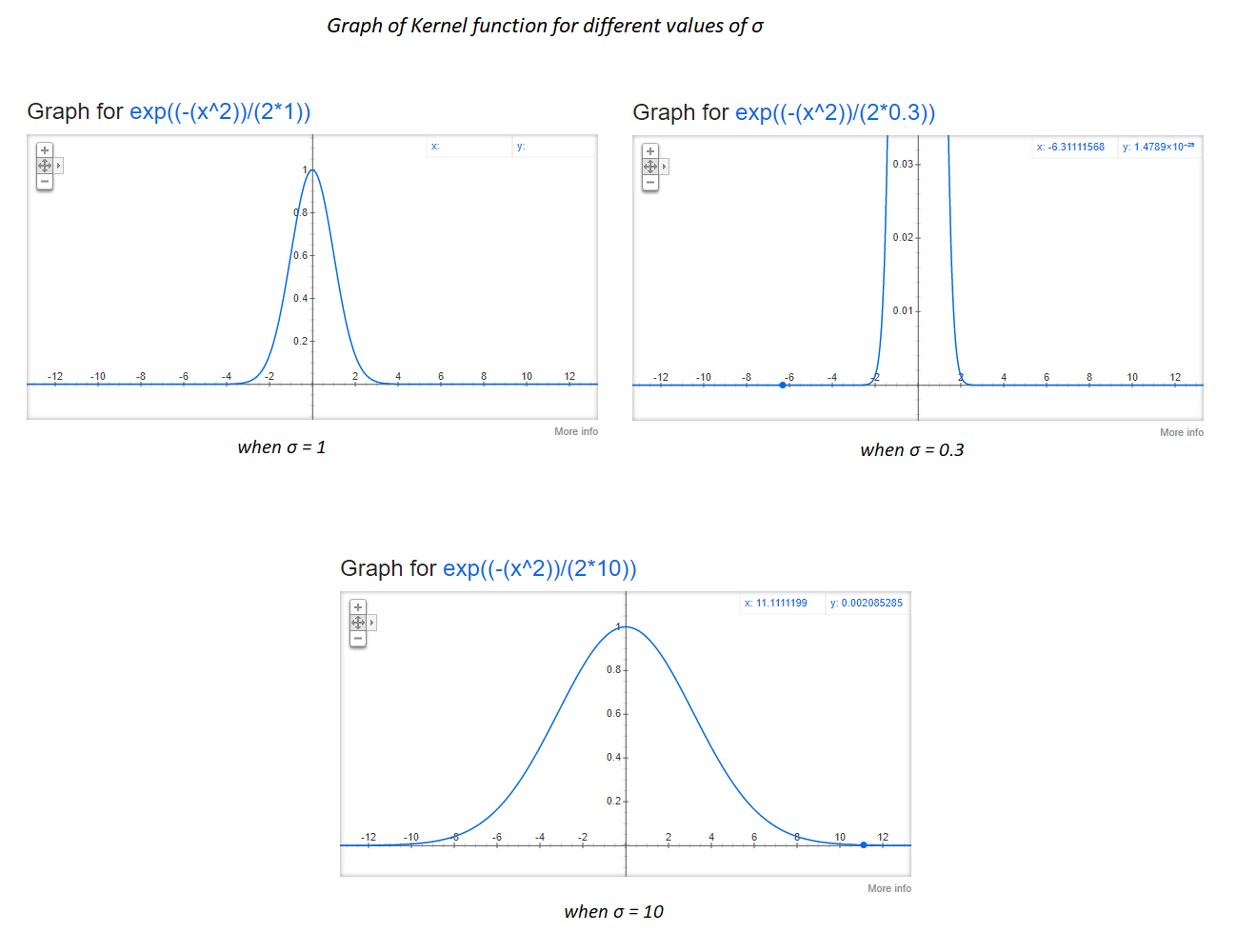
如果你注意,當σ=0.3,在x=2,接近于0,在x = 4,σ= 1時和x = 11,σ= 10,它接近0,這表明當σ增加時,即使兩個點是很遠,相似的score可能也不會很低,
例如假設有兩個點x?和x?的距離為4個單元,如果我們應用σ= 0.3的RBF核,核函式K值或相似值是0,如果我們設定σ= 1,K值很接近0,但如果我們設定σ= 10,K值約為0.4左右,
現在說明RBF核背后的直覺
還記得我們在使用多項式核函式時得到的6維映射函式嗎?現在讓我們嘗試找出RBF核的一個映射函式,
為了簡化數學,假設原始資料的維數為2,指數部分的分母為1,在這種情況下,
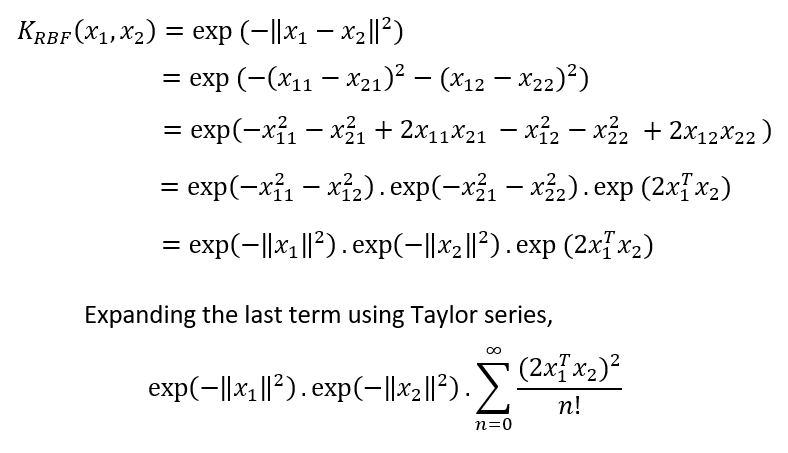
如果我們試圖找出RBF核的映射函式,就會得到一個無限向量,這意味著RBF核需要我們的資料映射到無限維的空間,計算相似性得分并回傳它,這就是為什么如果你不知道選擇哪個核,RBF核函式將是最安全的選擇,
用于回歸的SVM
到目前為止,我們已經研究了如何使用支持向量機執行分類任務,但支持向量機不僅限于此,它也可以用來執行回歸任務,怎樣?讓我們看看!
首先,讓我們看看支持向量回歸(SVR)的數學公式
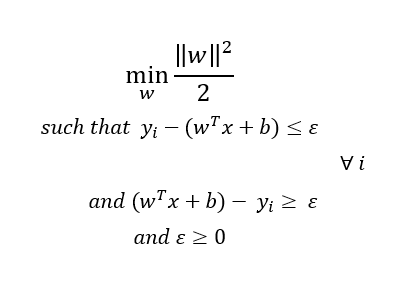
別擔心!我幫助你理解,
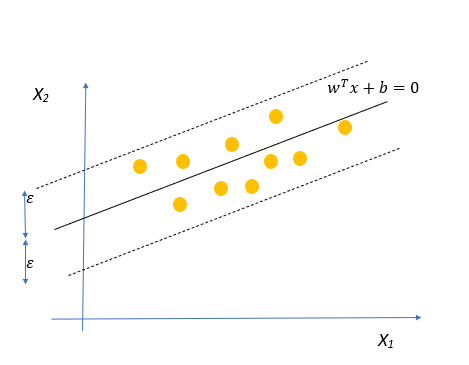
SVR的作業方式是,它試圖找到一個最適合的資料點的超平面,同時保持一個軟間隔=ε(超引數),這意味著所有的點都應該在超平面兩側ε距離,
最小化這里的邊界意味著我們想要找到一個超平面,這個超平面以較低的誤差來匹配資料,
注意:平方是為了使函式變得可微并適合于優化,對于SVC也可以這樣做,
這個公式有什么問題?
這里的問題是,我們太嚴格,我們期望的點位于ε超平面的距離在現實世界并不經常發生,在這種情況下,我們將無法找到所需的超平面,那么,我們該怎么做呢?
與我們在SVC中處理這個問題的方法相同,我們將為法向點引入兩個松弛變數ζ和ζ*,以允許某些點位于范圍之外,但會受到懲罰,
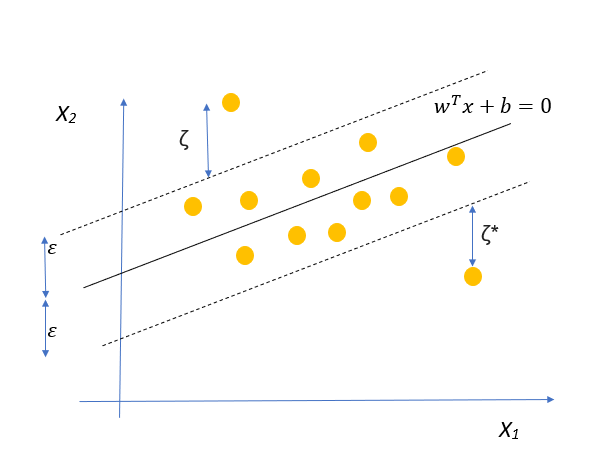
所以數學公式現在變成:
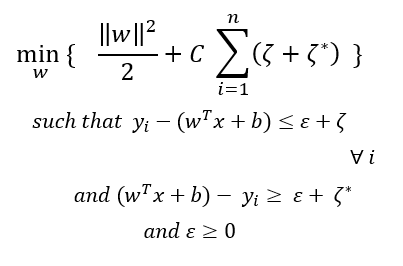
其中C確定所需的嚴格程度,C值越大,對邊距外的點的懲罰就越多,這可能導致資料的過度擬合,更少的C意味著對邊緣以外的點的懲罰更少,這可能導致資料擬合不足,
與SVC中一樣,圖顯示了SVR的原始形式,結果表明,對偶形式更易于求解,并且可以利用核技巧求出非線性超平面,
正如我已經說過的,對偶形式的公式是有點棘手的,涉及解決約束優化問題的知識,我們不會深入討論太多細節,因為這會轉移我們對支持向量機的注意力,
SVR對偶形式
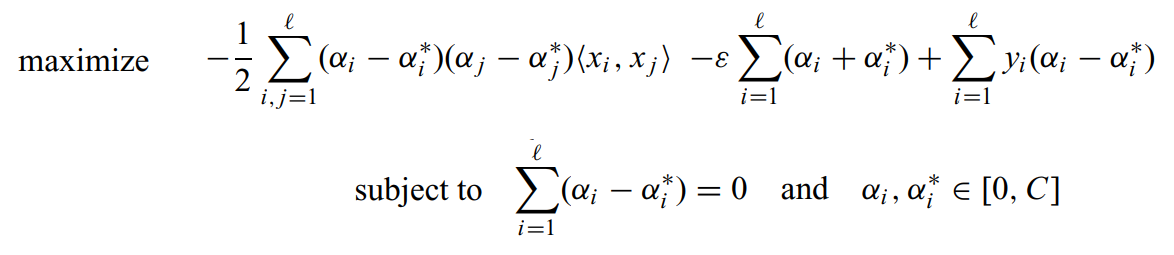
這是通過使用拉格朗日乘子求解優化問題得到的,
對于一個新的點,我們計算輸出值的方法是:
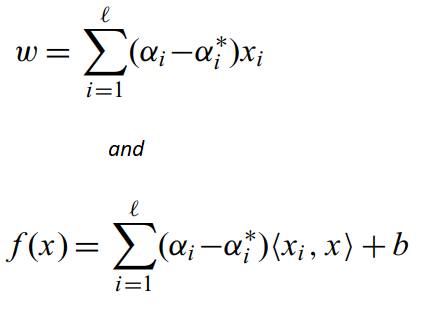
你有沒有注意到,x?是點積的形式?是的,和我們在SVC中得到的一樣,我們可以用前面提到的相似度或核函式來代替這個點積,應用核技巧還可以幫助我們擬合非線性資料,
支持向量機的各種情況
-
特征工程和特征轉換,這是通過找到上面討論的正確的核來實作的
-
決策面,對于線性支持向量機:決策曲面只是一個超平面,對于核支持向量機:它將是一個非線性曲面
-
相似函式/距離函式,支持向量機的原始形式不能處理相似函式,然而,因為x?點積的存在形式,對偶形式可以很容易地處理它,
-
特征的重要性,如果特征不是共線的,那么權重向量w中特征的權重決定了特征的重要性,如果特征是共線的,可以使用前向特征選擇或后向特征消除,這是確定任何模型特征重要性的標準方法,
-
離群值,與其他模型如Logistic回歸相比,支持向量機的影響較小,
-
偏差-方差,它依賴于支持向量機對偶形式中c的值,
如果c值較高,則誤差項的權重較大,因此模型可能會對資料進行過擬合;如果c值較低,則誤差項的權重較小,模型可能會對資料進行欠擬合,
- 高維度,支持向量機的設計可以很好地作業,即使在高維度,如圖所示,支持向量機的數學公式中已經存在一個正則化項,有助于處理高維問題,你可能會說像KNN這樣的其他模型并不適用于高維空間,那么SVMs有什么特別之處呢?這是因為支持向量機只關心找到使邊距最大的平面,而不關心點之間的相對距離,
支持向量機的優點
- 它有一個正則化項,有助于避免資料的過擬合
- 它使用核技巧,這有助于處理甚至非線性資料(在SVR情況下)和非線性可分資料(在SVC情況下)
- 當我們不了解資料時,支持向量機是非常好的,
- 可以很好地處理非結構化和半結構化資料,比如文本、影像和樹,
- 從某種意義上說,它是健壯的,即使在訓練示例包含錯誤的情況下也能作業
支持向量機的局限性
- 選擇正確的核是一項困難的任務,
- 支持向量機演算法有多個超引數需要正確設定,以獲得對任何給定問題的最佳分類結果,引數可能導致問題A的分類精度很好,但可能導致問題B的分類精度很差,
- 當支持向量機的資料點數目較大時,訓練時間較長,
- 對于核支持向量機,其權向量w的決議比較困難,
參考
- https://alex.smola.org/papers/2004/SmoSch04.pdf
- https://www.saedsayad.com/support_vector_machine_reg.htm
- https://statinfer.com/204-6-8-svm-advantages-disadvantages-applications/
- http://www.cs.uky.edu/~jzhang/CS689/PPDM-Chapter2.pdf
原文鏈接:https://medium.com/@anujshrivastav97/demystifying-support-vector-machine-b04d202bf11e
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/18210.html
標籤:其他
上一篇:Python小白求助!!!
下一篇:新手