作者|Paul Hiemstra
編譯|VK
來源|Towards Datas Science
你也可以在GitHub上閱讀這篇文章,這個GitHub存盤庫包含你自己運行分析所需的一切:https://github.com/PaulHiemstra/lasso_tsfresh_article/blob/master/lasso_tsfresh_article.ipynb
介紹
對于許多資料科學家來說,最基本的模型是多元線性回歸,在許多分析中,它是第一個被呼叫的,并作為更復雜模型的基準,它的一個優點是容易解釋得到的系數,這是神經網路特別難以解決的問題,
然而,線性回歸并非沒有挑戰,在本文中,我們關注一個特殊的挑戰:處理大量的特征,大資料集的具體問題是如何為模型選擇相關的特征,如何克服過擬合以及如何處理相關特征,
正則化是一種非常有效的技術,有助于解決上述問題,正則化是通過用一個限制系數大小的項來擴展標準最小二乘目標或損失函式來實作的,本文的主要目的是讓你熟悉正則化及其提供的優勢,
在本文中,你將了解以下主題:
-
什么樣的正則化更詳細,為什么值得使用
-
有哪些不同型別的正則化,以及術語L1和L2正則化意味著什么
-
如何使用正則化
-
如何使用tsfresh生成正則化回歸的特征
-
如何解釋和可視化正則化回歸系數
-
如何利用交叉驗證優化正則化強度
-
如何可視化交叉驗證的結果
我們將從更理論上介紹正則化開始本文,并以一個實際例子結束,
為什么使用正則化,什么是正則化
下圖顯示了一個綠色和藍色的函式,與紅色觀察值相匹配,這兩個函式都完美地符合觀測值,我們該以何種方式選擇這2個函式,
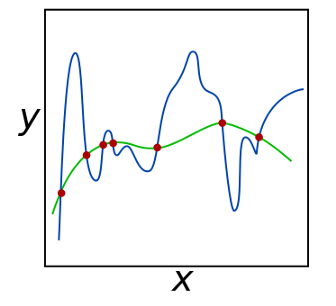
我們的問題是不確定的,這導致我們任意不能選擇這兩個函式中的任何一個,在回歸分析中,有兩個因素減低了性能:多重共線性(相關特征)和特征的數量,
通常可以手工以得到少量特征,然而,在更多的資料驅動方法中,我們通常使用許多特征,這導致特征之間有很多相關,而我們事先并不知道哪些特征會很好地作業,為了克服不確定性,我們需要在問題中添加資訊,在我們的問題中添加資訊的數學術語是正則化,
回歸中執行正則化的一種非常常見的方法是用附加項擴展損失函式,Tibshirani(1997)提出用一種稱為Lasso的方法將系數的總大小添加到損失函式中,表示系數總大小的數學方法是使用所謂的范數:
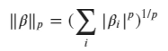
其中p值決定了我們使用什么樣的正則化,p值為1稱為L1范數,值為2稱為L2范數等,既然我們有了范數的數學運算式,我們就可以擴展我們通常在回歸中使用的最小二乘損失函式:
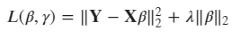
注意,這里我們使用L2范數,我們也用L2范數表示了損失函式的平方差部分,另外,lambda是正則化強度,正則化強度決定了系數大小與損失函式平方差部分的關系,注意,范數項主要優點是減少了模型中的方差,
包含L2范數的回歸稱為嶺回歸,嶺回歸減少了預測中的方差,使其更穩定,更不容易過擬合,此外,方差的減少還可以對抗多重共線性帶來的方差,
當我們在損失函式中加入L1范數時,這稱為Lasso,Lasso在減小系數大小方面比嶺回歸更進一步,會降到零,這實際上意味著變數從模型中退出,因此lasso是在執行特征選擇,這在處理高度相關的特征(多重共線性)時有很大的影響,Lasso傾向于選擇一個相關變數,而嶺回歸平衡所有特征,Lasso的特征選擇在你有很多輸入特征時特別有用,而你事先并不知道哪些特征會對模型有利,
如果要混合Lasso回歸和嶺回歸,可以同時向損失函式添加L1和L2范數,這就是所謂的Elastic正則化,在理論部分結束后,讓我們進入正則化的實際應用,
正則化的示例使用
用例
人類很善于識別聲音,僅憑音頻,我們就能夠區分汽車、聲音和槍支等事物,如果有人特別有經驗,他們甚至可以告訴你什么樣聲音屬于哪種汽車,在這種情況下,我們將建立一個正則化回歸模型,
資料集
我們的資料是75個鼓樣品,每種型別的鼓有25個:底鼓、圈套鼓和湯姆鼓,每個鼓樣本存盤在wav檔案中,例如:
sample_rate, bass = wavfile.read('./sounds/bass1.wav')
bass_pd = pd.DataFrame(bass, columns=['left', 'right']).assign(time_id = range(len(bass)))
bass_pd.head()
# 注意,本文中的所有圖形都使用了plotnine
(
ggplot(bass_pd.melt(id_vars = ['time_id'], value_name='amplitude', var_name='stereo'))
+ geom_line(aes(x = 'time_id',
y = 'amplitude'))
+ facet_wrap('stereo')
+ theme(figure_size=(4,2))
)
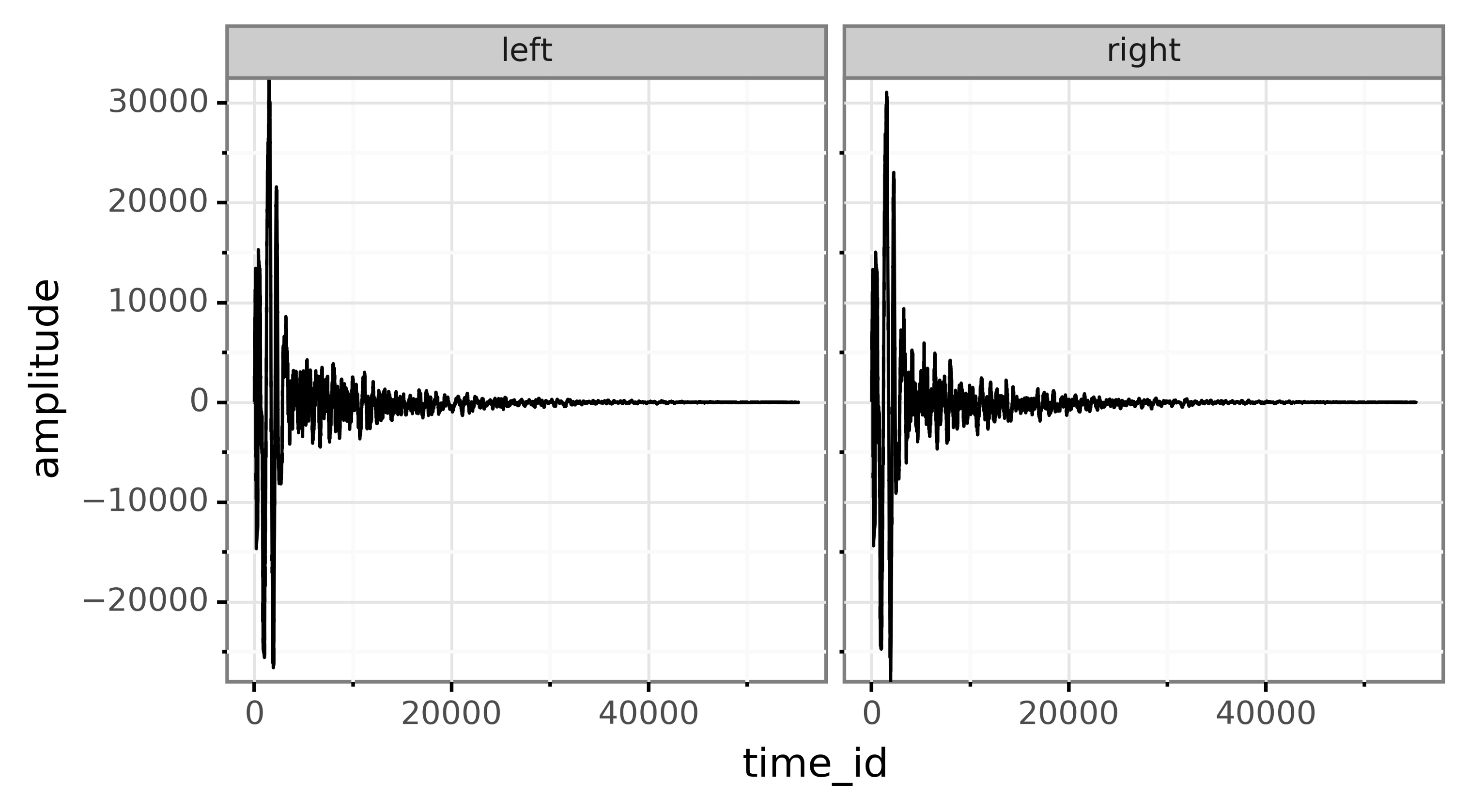
wav檔案是立體聲的,包含兩個聲道:左聲道和右聲道,該檔案包含隨時間變化的波形,在x軸上隨時間變化,在y軸上包含振幅,振幅基本上列出了揚聲器圓錐應該如何振動,
以下代碼構造了一個包含所有75個鼓樣本的資料幀:
import glob
wav_files = glob.glob('sounds/kick/*.wav') + glob.glob('sounds/snare/*.wav') + glob.glob('sounds/tom/*.wav')
all_audio = pd.concat([audio_to_dataframe(path) for path in wav_files])
all_labels = pd.Series(np.repeat(['kick', 'snare', 'tom'], 25),
index = wav_files)
all_audio.head()
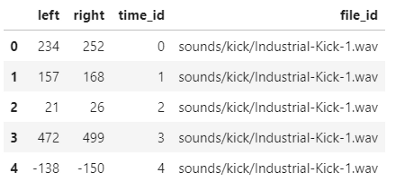
附加函式audio_to_dataframe可以在github倉庫的helper_functions.py找到,
使用tsfresh生成特征
為了擬合一個監督模型,sklearn需要兩個資料集:一個帶有我們的特征的樣本特征x矩陣(或資料幀)和一個帶有標簽的樣本向量,
因為我們已經有了標簽,所以我們把精力集中在特征矩陣上,因為我們希望我們的模型對每個聲音檔案進行預測,所以特征矩陣中的每一行都應該包含一個聲音檔案的所有特征,
接下來的挑戰是提出我們想要使用的特征,例如,低音鼓的聲音中可能有更多的低音頻率,因此,我們可以在所有樣本上運行FFT并將低音頻率分離成一個特征,
采用這種手動特征工程方法可能會非常耗費人力,并且很有可能排除重要特征,tsfresh(docs)是一個Python包,它極大地加快了這個程序,該包基于timeseries資料生成數百個潛在的特征,還包括預選相關特征的方法,有數百個特征強調了在這種情況下使用某種正則化的重要性,
為了熟悉tsfresh,我們首先使用MinimalFCParameters設定生成少量特征:
from tsfresh import extract_relevant_features
from tsfresh.feature_extraction import MinimalFCParameters
settings = MinimalFCParameters()
audio_tsfresh_minimal = extract_relevant_features(all_audio, all_labels,
column_id='file_id', column_sort='time_id',
default_fc_parameters=settings)
print(audio_tsfresh_minimal.shape)
audio_tsfresh_minimal.head()
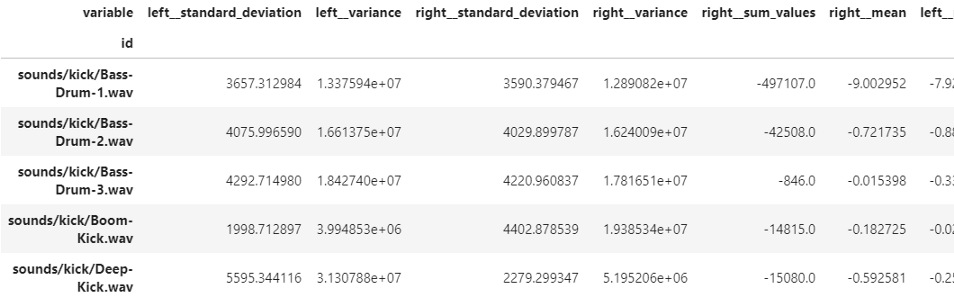
這就給我們留下了11個特征,我們使用extract_related_features函式來允許tsfresh根據標簽和生成的潛在特征預先選擇有意義的特征,在這種最小的情況下,tsfresh查看由file_id列標識的每個聲音檔案,并生成諸如振幅的標準偏差、平均振幅等特征,
但是tsfresh的強大之處在于我們產生了更多的特征,在這里,我們使用相關默認設定來節省一些時間,而不是使用完整的設定,注意,我直接讀取了dataframe的pickle資料,它是使用github倉庫中用generate_drum_model.py腳本生成的,我這樣做是為了節省時間,因為在我的12執行緒機器上計算大約需要10分鐘,
from tsfresh.feature_extraction import EfficientFCParameters
settings = EfficientFCParameters()
audio_tsfresh = pd.read_pickle('pkl/drum_tsfresh.pkl')
print(audio_tsfresh.shape)
audio_tsfresh.head()
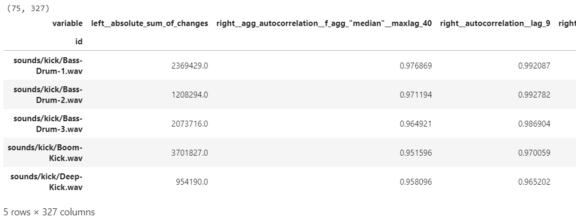
這使得特征的數量從11個擴展到327個,這些特征為我們的正則化回歸模型提供了一個非常廣闊的學習空間,
正則回歸模型的擬合
現在我們已經有了一組輸入特征和所需的標簽,我們可以繼續并擬合我們的正則化回歸模型,我們使用來自sklearn的邏輯回歸模型:
from sklearn.linear_model import LogisticRegression
base_log_reg = LogisticRegression(penalty='l1',
multi_class='ovr',
solver='saga',
tol=1e-6,
max_iter=int(1e4),
C=1)
并使用以下設定:
-
我們將懲罰設定為l1,即我們使用l1范數的正則化,
-
我們將multi_class設定為1 vs rest(ovr),這意味著我們的模型由三個子模型組成,每種可能型別的鼓各有一個,當用整體模型進行預測時,我們只需選擇表現最好的模型,
-
我們使用saga求解器來擬合我們的損失函式,還有更多可用的,但saga能夠完成我們所需要的功能,
-
現在將C設為1,其中C等于
1/正則化強度,請注意,sklearn Lasso實作使用了??,它等于1/2C,我發現??是一個更直觀的度量,我們將在本文的其余部分使用它, -
tol和max_iter設定為可接受的默認值,
基于這些設定,我們進行了一些實驗,首先,我們將比較基于少量和大量tsfresh特征的模型的性能,之后,我們將重點討論如何使用交叉驗證來擬合正則化強度,并對擬合模型的性能進行更全面的討論,
最小tsfresh vs 有效tsfresh
我們的第一個分析測驗了這樣一個假設:使用更多生成的tsfresh特征可以得到更好的模型,為了測驗這一點,我們使用最小tsfresh和有效tsfresh特征來擬合一個模型,我們通過模型在測驗集上的準確性來判斷模型的性能,我們重復20次,以了解由于在選擇訓練和測驗集時的隨機性而導致的精確度差異:
from sklearn.model_selection import train_test_split
def get_score(audio_data, labels):
# 用cross_val_score代替?
audio_train, audio_test, label_train, label_test = train_test_split(audio_data, labels, test_size=0.3)
log_reg = base_log_reg.fit(audio_train, label_train)
return log_reg.score(audio_test, label_test)
accuracy_minimal = [get_score(audio_tsfresh_minimal, all_labels) for x in range(20)]
accuracy_efficient = [get_score(audio_tsfresh, all_labels) for x in range(20)]
plot_data = https://www.cnblogs.com/panchuangai/p/pd.concat([pd.DataFrame({'accuracy': accuracy_minimal, 'tsfresh_data': 'minimal'}),
pd.DataFrame({'accuracy': accuracy_efficient, 'tsfresh_data': 'efficient'})])
(
ggplot(plot_data) + geom_boxplot(aes(x='tsfresh_data', y='accuracy')) +
coord_flip() +
labs(y = 'Accuracy', x = 'TSfresh setting')
)
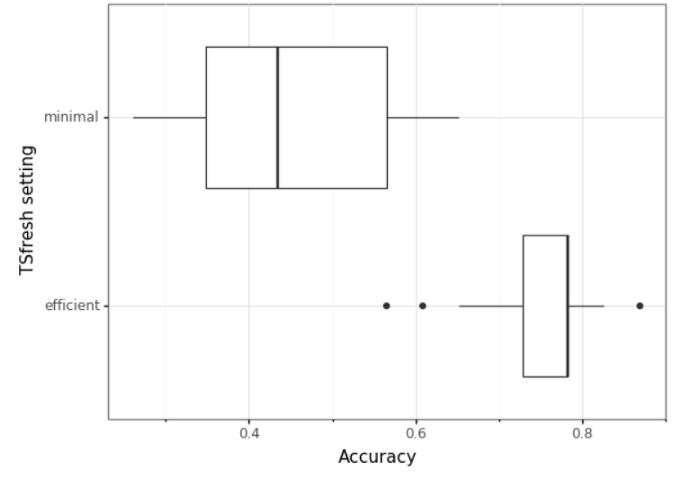
得到的箱線圖清楚地表明,與基于最小特征的模型相比,有效tsfresh變數顯示了更高的平均精度0.75,而不是0.4,這證實了我們的假設,我們將在本文的其余部分使用有效的特征,
通過交叉驗證選擇正則化強度
在使用正則化時,我們必須做出的一個主要選擇是正則化的強度,在這里,我們使用交叉驗證來測驗C的一系列潛在值的準確性,
sklearn很方便地包含了一個用于邏輯回歸分析的函式:LogisticRegressionCV,它本質上具有與LogisticRegression相同的介面,但是你可以傳遞一個潛在的C值串列來進行測驗,
有關代碼的詳細資訊,請參閱generate_drum_model.py,我們將結果從磁盤加載到此處以節省時間:
from sklearn.svm import l1_min_c
from joblib import dump, load
cs = l1_min_c(audio_tsfresh, all_labels, loss='log') * np.logspace(0, 7, 16)
cv_result = load('pkl/drum_logreg_cv.joblib')
注:我們使用l1_min_c來獲得模型包含非零系數的最小c值,然后我們在上面乘上一個0到7之間的16個對數,這樣得到16個潛在的C值,我沒有一個很好的理由來解釋這些數字,轉換為α,并取log10,我們得到:
np.log10(1/(2*cs))

這其中包含一個很好的正則化強度范圍,我們將在結果的解釋中看到,
交叉驗證選擇了以下??值:
np.log10(1/(2*cv_result.C_))
注意我們有三個值,每個子模型一個(kick-model, tom-model, snare-model),在這里,我們看到,6左右的正則化強度被認為是最優的(C=4.5e-07),
基于CV結果對模型的進一步解釋
cv_result物件包含更多關于交叉驗證的資料,而不是擬合的正則化強度,在這里,我們首先看看交叉驗證模型中的系數,以及它們在不斷變化的正則化強度下所遵循的路徑,注意,我們使用helper_functions,py中的plot_coef_paths函式:
plot_coef_paths(cv_result, 'kick', audio_tsfresh) + theme(figure_size=(16,12))
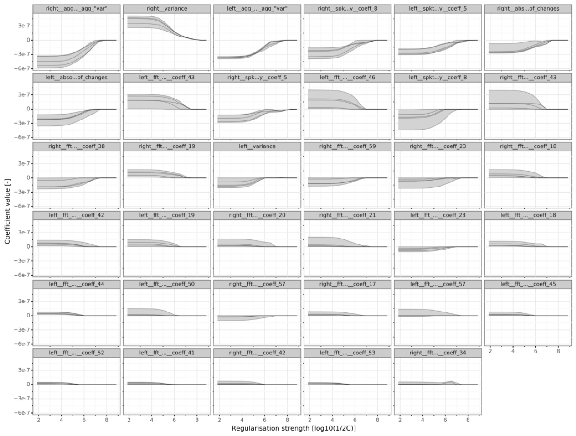
注:我們在圖中看到5條線,因為默認情況下我們執行5折交叉驗證,另外,我們重點研究了kick子模型,圖中有以下有趣的觀察結果:
-
增加正則化強度會減小系數的大小,這正是正則化應該做的,但是結果支持這一點是很好的,
-
增加的褶皺線減少了強度之間的變化,這符合正則化的目標:減少模型中的方差,然而,褶皺之間的變化仍然非常劇烈,
-
對于后面的系數,總的系數大小會下降,
-
對于交叉驗證的正則化強度(6),相當多的系數從模型中消失,在tsfresh生成的327個潛在特征中,只有大約10個被選為最終模型,
-
許多有影響的變數是fft分量,這很直觀,因為鼓樣本之間的差異集中在特定頻率(低音鼓->低頻,圈套鼓->高頻),
這些觀察結果描繪了這樣一幅圖景:正則化回歸按預期作業,但肯定還有改進的余地,在這種情況下,我懷疑每種型別的鼓有25個樣本是主要的限制因素,
除了看系數及其變化,我們還可以看看子模型的總體精度與正則化強度的關系,注意,我們使用helper_functions.py中的plot_reg_strength_vs_score,你可以在github上找到,
plot_reg_strength_vs_score(cv_result) + theme(figure_size=(10,5))
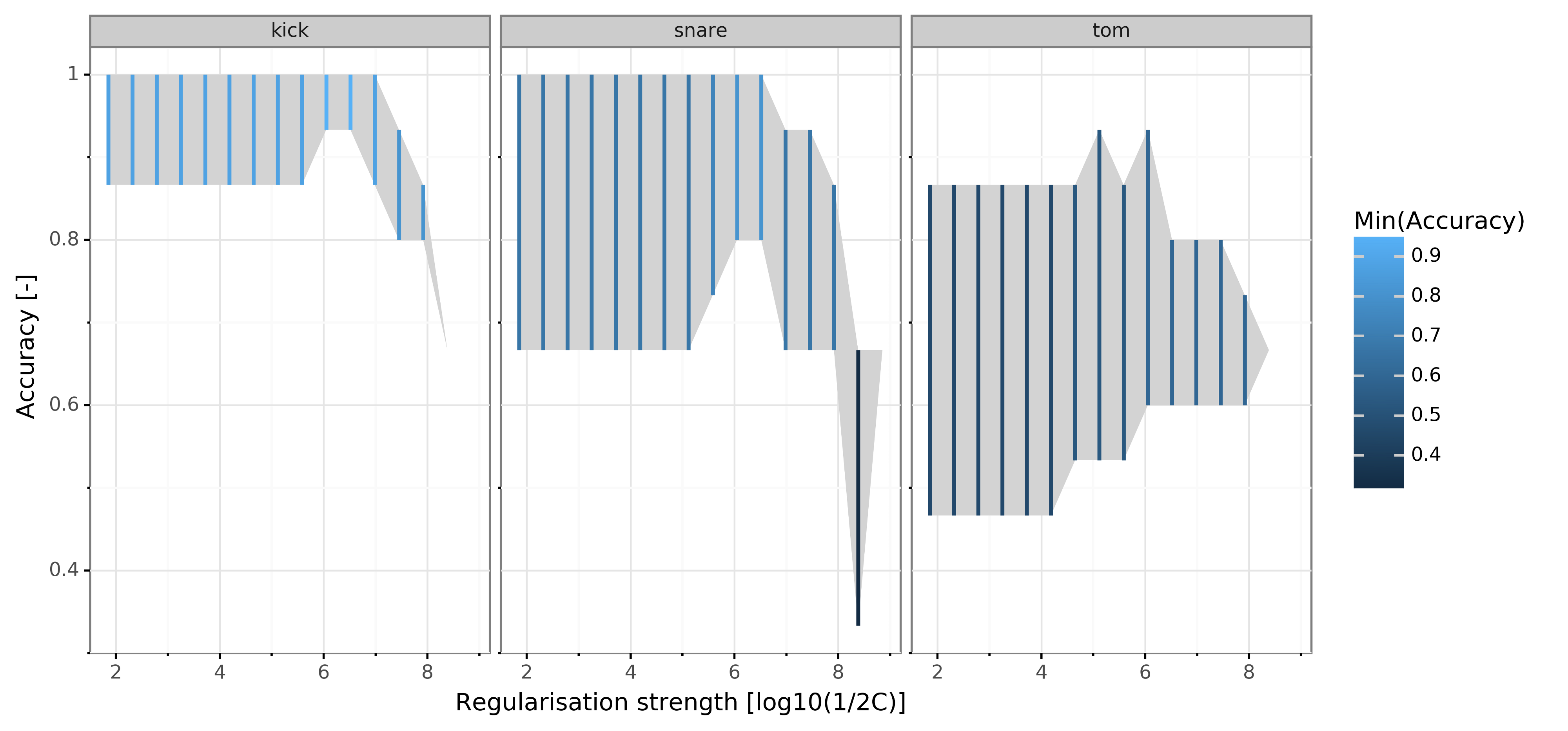
請注意,準確度覆寫的不是一條線而是一個區域,因為在交叉驗證中,我們對每一次都有一個準確度分數,圖中的觀察結果:
-
在擬合的正則化強度(6->0.95)下,kick 模型總體表現最佳,
-
tom模型的性能最差,最小和最大精度都低,
-
性能峰值介于5–6之間,這與所選值一致,在強度較小的情況下,我懷疑模型中剩余的多余變數會產生太多的噪聲,然后正則化會去掉太多的相關資訊,
結論:正則回歸模型的性能
基于交叉驗證的準確度得分,我得出結論,我們在生成鼓聲識別模型方面相當成功,尤其是底鼓很容易區別于其他兩種型別的鼓,正則化回歸也為模型增加了很多價值,降低了模型的整體方差,最后,tsfresh展示了從這些基于時間序列的資料集生成特征的巨大潛力,
改進模型的潛在途徑有:
-
使用tsfresh生成更多潛在的輸入特征,
-
使用更多的鼓樣本作為模型的輸入
原文鏈接:https://towardsdatascience.com/expanding-your-regression-repertoire-with-regularisation-903d2c9f7b28
歡迎關注磐創AI博客站:
http://panchuang.net/
sklearn機器學習中文官方檔案:
http://sklearn123.com/
歡迎關注磐創博客資源匯總站:
http://docs.panchuang.net/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/183400.html
標籤:其他
上一篇:RedisEclipse