在大多數編程語言中,字串是可以直接通過下標訪問的,但是在使用 go 語言的時候,直接使用下標訪問有時候會出現一些亂碼,
陣列
在解決這個問題之前,要先了解一個東西--陣列:陣列是用于存盤多個相同型別資料的集合,并且陣列在申請記憶體的時候,是一次申請一塊連續的記憶體,比如我們創建一個陣列,里面存了這幾個元素,
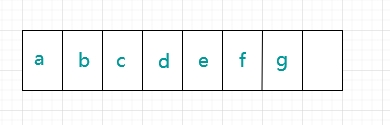
由于記憶體是連續的,元素的型別也是相同的,所以每個元素占用的記憶體空間也是固定的,比如 java 中 char 型別占用兩個位元組,陣列的記憶體空間是平等劃分的,這樣就可以解釋為什么可以靠下標訪問了,
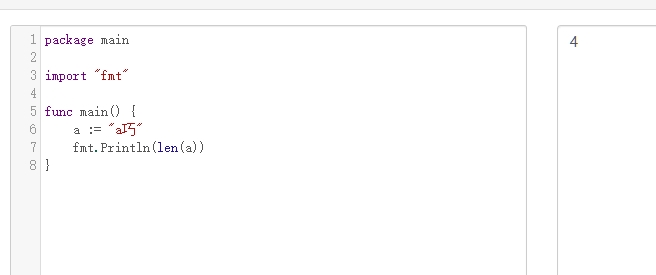
在可以用下標訪問的語言中,字串都是按照字符編碼的,也就是說,你將字串 “abcd” 賦給變數 a,本質上是創建了一個字符陣列用來存放字串,但是在 go 語言里不一樣,go 語言的字符型是按照位元組編碼的,什么意思呢? 26 個英文字母,每個英文字母占一個位元組,在 go 語言的 string 里面就占用一個位元組,中文日文韓文就不一樣了, go 語言內建只支持 utf8 編碼,在 utf8 里面,有一部分漢字占用 3 個位元組,一部分漢字占用 4 個位元組,比如 "巧" 這個字,列印一下它的長度,發現這個 string 占用 3 個位元組,加上 "a" 之后占用 4 個位元組,應該能理解按位元組編碼的意思了,
編碼
為什么要 go 要選擇按照位元組來編碼呢,這其實是為了節省空間,想象一下,在UTF-8編碼中,中文有些要三個位元組,有一些要占用四個位元組,而英文字母只需要占用一個位元組,一個中文算一個字符,一個英文字母也算一個字符,但是占用的記憶體相差很大,假設有一個超長字串,里面有英文字符遠多于中文字符,如果按字符來存盤,每個字符要分配四個位元組,因為低于四個位元組,有可能有些中文就不能正常存盤了,在這種情況下,每存盤一個英文字母,就要浪費三個位元組的記憶體空間,
底層實作和其它語言就不一樣,不同型別的字符占用的記憶體空間都不同,當然也就沒有辦法按照下標訪問了,不信可以試試,

a[0] 是 97,等于字母 a 的 ascii 碼,a1 是 229,顯然不會是漢字 "巧" 的 utf8,事實它是 utf8 編碼的第一位元組的值,

打完收工,到這里弄清楚了 go 中 string 不能按照下標訪問的原理了
公眾號:沒有夢想的阿巧 后臺回復 "群聊",一起學習,一起進步
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/184365.html
標籤:其他
下一篇:字串相乘