文章目錄
- 前言
- 一、Hive 基本架構
- 二、Hive SQL
- Hive 關鍵概念
- 1. Hive 資料庫
- 2. Hive 表
- 3. 磁區和桶
- ( 1 )磁區
- ( 2 )分桶
- Hive DDL
- 1. 創建表
- 2. 修改表
- 3. 洗掉表
- 4. 插入表
- ( 1 )向表中加載資料
- ( 2 )將查詢結果插入 Hive
- Hive DML
- 1. 基本的 select 操作
- 2. join 表
- 三、Hive SQL 執行原理圖解
- 四、小結
前言
我們都知道,Hive SQL 實際上是翻譯為 MapReduce 執行的, 那么它具體程序如何呢?今天我們就來探尋 Hive SQL 背后的執行機制和原理,
進一步理解和掌握 Hive SQL 的執行原理對于平時離線任務的開發和優化非常重要,直接關系到 Hive SQL 的執行效率和時間,
一、Hive 基本架構
作為基于 Hadoop 主要資料倉庫解決方案, Hive SQL 是主要的互動介面,實際的資料保存在 HDFS 檔案中,真正的計算和執行則由 MapReduce 完成,它們之間的橋梁是 Hive 引擎,
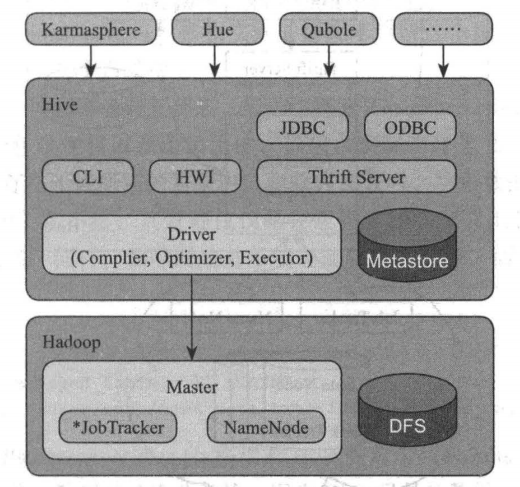
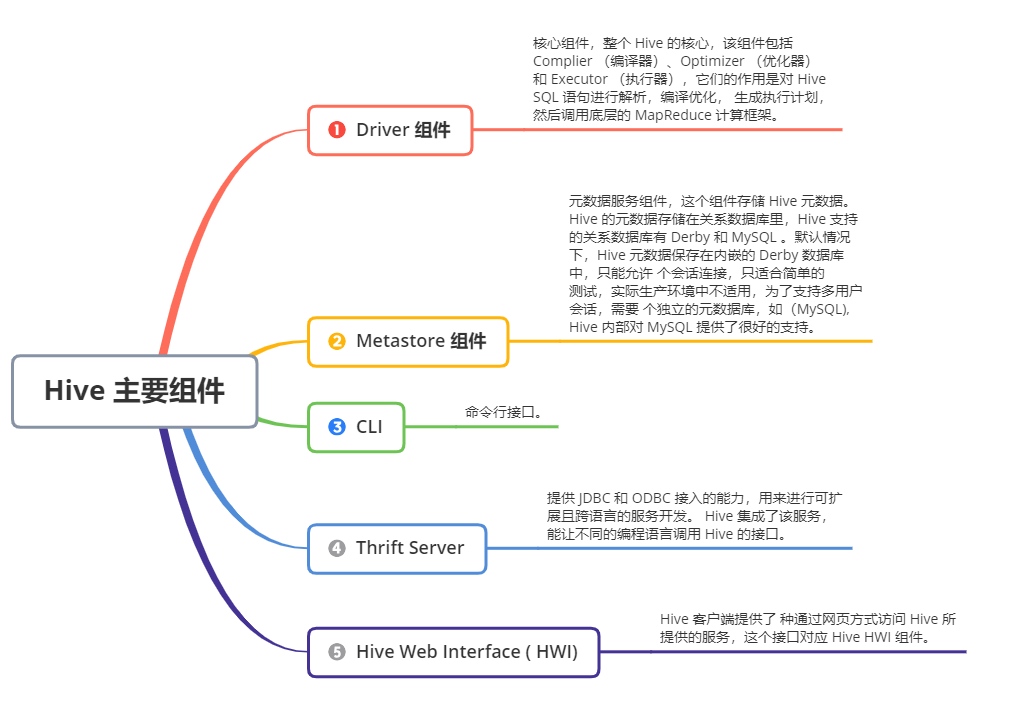
Hive 主要組件包括 UI 組件、 Driver 組件( Complier Optimizer Executor )、 Metastore組件、 CLI ( Command Line Interface ,命令列介面)、 JDBC/ODBC 、Thrift Server 和 Hive Web Interface (HWI )等,
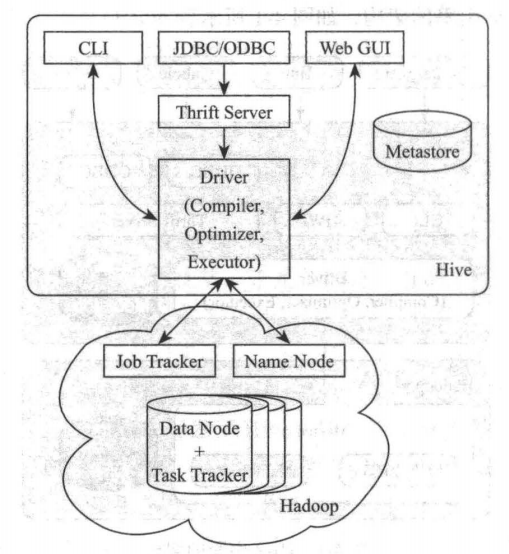
Hive 就是通過 CLI 、JDBC / ODBC 或者 HWI 接收相關的 Hive SQL 查詢,并通過 Driver 組件進行編譯,分析優化,最后變成可執行的 MapReduce,
二、Hive SQL
Hive SQL 是類似于 ANSI SQL 標準的SQL 語言,但兩者又不完全相同, Hive SQL 和 MySQL 的 SQL 語言最為接近,但兩者之間也存在顯著差異,比如 Hive 不支持行級資料插人、更新和洗掉,也不支持事務等,
Hive 關鍵概念
1. Hive 資料庫
Hive 中的資料庫從本質上來說僅僅是一個目錄或者命名空間,但是對于具有很多用戶和組的集群來說,這個概念非常有用 ,
首先,這樣可以避免表命名沖突;其次,它等同于關系型資料庫中的資料庫概念,是一組表或者表的邏輯組,非常容易理解,
2. Hive 表
Hive 中的表( Table )和關系資料庫中的 table 在概念上是類似的,每個 table 在 Hive 中都有一個相應的目錄存盤資料,如果沒有指定表的資料庫,那么 Hive 會通過{HIVE_HOME} /conf/hive-site.xml 組態檔中的 hive.metastore.warehouse.dir 屬性來使用默認值(一般是 /user/hive/warehouse ,也可以根據實際的情況來修改這個配置),所有的 table 資料(不包括外部表) 都保存在這個目錄中,
Hive 表分為兩類,即內部表和外部表,所謂內部表(managed table) 即 Hive 管理的表,Hive 內部表的管理既包含邏輯以及語法上的,也包含實際物理意義上的,即創建 Hive 內部表時,資料將真實存在于表所在的目錄內,洗掉內部表時,物理資料和檔案也一并洗掉,
那么到底是選擇內部表還是外部表呢?
大多數情況下,這兩者的區別不是很明顯,如果資料的所有處理都在 Hive 中進行,那么更傾向于選擇內部表,但是如果 Hive 和其他工具針對相同的資料集做處理,那么外部表更合適,
-
一種常見的模式是使用外部表訪問存盤的 HDFS (通常由其他工具創建)中的初始資料,然后使用 Hive 轉換資料并將其結果放在內部表中, 相反,外部表也可以用于將 Hive 的處理結果匯出供其他應用使用,
-
使用外部表的另一種場景是針對一個資料集,關聯多個 Schema,
3. 磁區和桶
Hive 將表劃分為磁區(partition),partition 根據磁區欄位進行, 磁區可以讓資料的部分查詢變得更快 ,表或者磁區可以進一步被劃分為桶( bucket), 桶通常在原始資料中加入一些額外的結構,這些結構可以用于高效查詢,
例如 ,基于用戶 ID 的分桶可以使基于用戶的查詢非常快,
( 1 )磁區
假設日志資料中,每條記錄都帶有時間戳 ,如果根據時間來磁區,那么同一天的資料將被劃分到同一個磁區中,
磁區可以通過多個維度來進行, 例如,通過日期劃分之后,還可以根據國家進一步劃分,
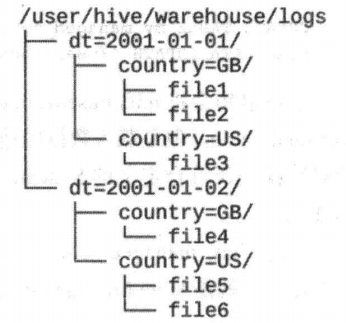
磁區在創建表的時候使用 PARTITIONED BY 從句定義,該從句接收一個欄位串列:
CREATE TABLE logs (ts BIGINT , line STRING)
PARTITIONED BY (dt STRING,country STRING);
當匯入資料到磁區表時,磁區的值被顯式指定:
LOAD DATA INPATH ’/user/root/path’
INTO TABLE logs
PARTITION (dt='2001-01-01',country='GB’);
實際 SQL 中,靈活指定磁區將大大提高其效率,如下代碼將僅會掃描 2001-01-01下的 GB 目錄,
SELECT ts , dt , line FROM logs WHERE dt=‘2001-01-01' and country='GB'
( 2 )分桶
在表或者磁區中使用桶通常有兩個原因:
- 一是為了高效查詢 ,桶在表中加入了特殊的結果, Hive 在查詢的時候可以利用這些結構提高效率,例如,如果兩個表根據相同的欄位進行分桶,則在對這兩個表進行關聯的時候,可以使用 map-side 關聯高效實作,前提是關聯的欄位在分桶欄位中出現,
- 二是可以高效地進行抽樣, 在分析大資料集時,經常需要對部分抽樣資料進行觀察和分析,分桶有利于高效實作抽樣,
為了讓 Hive 對表進行分桶,通過 CLUSTERED BY 從句在創建表的時候指定:
CREATE TABLE bucketed users(id INT, name STRING)
CLUSTERED BY (id) INTO 4 BUCKETS;
指定表根據 id 欄位進行分桶,并且分為 4 個桶 ,分桶時, Hive 根據欄位哈希后取余數來決定資料應該放在哪個桶,因此每個桶都是整體資料的隨機抽樣,
在 map-side 的關聯中,兩個表根據相同的宇段進行分桶,因此處理左邊表的 bucket 時,可以直接從外表對應的 bucket 中提取資料進行關聯操作, map-side 關聯的兩個表不一定需要完全相同 bucket 數量,只要成倍數即可,
需要注意的是, Hive 并不會對資料是否滿足表定義中的分桶進行校驗,只有在查詢時出現例外才會報錯 ,因此,一種更好的方式是將分桶的作業交給 Hive 來完成(設 hive.enforce.bucketing 屬性為 true 即可),
Hive DDL
1. 創建表
- CREATE TABLE:用于創建一個指定名字的表 ,如果相同名字的表已經存在,則拋出例外 用戶可以用 IF NOT EXIST 選項來忽略這個例外,
- EXTERNAL :該關鍵字可以讓用戶創建一個外部表,在創建表的同時指定一個指向實際資料的路徑(LOCATION),
- COMMENT :可以為表與欄位增加描述,
- ROW FORMAT :用戶在建表的時候可以自定義 SerDe 或者使用自帶的 SerDe,
- STORED AS :如果檔案資料是純文本,則使用 STORED AS TEXTFILE ;如果資料需要壓縮, 則使用 STORED AS SEQUENCE ,
- LIKE: 允許用戶復制現有的表結構,但是不復制資料,
hive> CREATE TABLE empty key value store
LIKE key value store;
還可以通過 CREATE TABLE AS SELECT 的方式來創建表,示例如下:
Hive> CREATE TABLE new key value store
ROW FORMAT
SERDE "org.apache.Hadoop.hive.serde2.columnar.ColumnarSerDe"
STORED AS RCFile
AS
SELECT (key % 1024) new_key, concat(key, value) key_value_pair
FROM key_value_store
SORT BY new_key, key_value_pair;
2. 修改表
修改表名的語法如下:
hive> ALTER TABLE old_table_name RENAME TO new_table_name;
修改列名的語法如下:
ALTER TABLE table_name CHANGE (COLUMN) old_col_name new_col_name column_type
[COMMENT col_comment) (FIRST|AFTER column_name)
上述語法允許改變列名 資料型別 注釋 列位 它們的任意組合 建表后如果要新增一列,則使用如下語法:
hive> ALTER TABLE pokes ADD COLUMNS (new_col INT COMMENT 'new col comment');
3. 洗掉表
DROP TABLE 陳述句用于洗掉表的資料和元資料 ,對于外部表,只洗掉 Metastore 中的元資料,而外部資料保存不動,示例如下:
drop table my_table;
如果只想洗掉表資料,保留表結構,跟 MySQL 類似,使用 TRUNCATE 陳述句:
TRUNCATE TABLE my_table;
4. 插入表
( 1 )向表中加載資料
相對路徑的示例如下:
hive> LOAD DATA LOCAL INPATH ’./exarnples/files/kvl.txt ’ OVERWRITE INTO
TABLE pokes;
( 2 )將查詢結果插入 Hive
將查詢結果寫入 HDFS 檔案系統,
INSERT OVERWRITE TABLE tablenamel [PARTITION (partcoll=val1, partcol2=val2 ... )]
select_statement1 FROM from_statement
這是基礎模式,還有多插入模式和自動磁區模式,這里就不再敘述,
Hive DML
1. 基本的 select 操作
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[ CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY | ORDER BY col_list]
]
[LIMIT number]
- 使用 ALL、 DISTINCT 選項區分對重復記錄的處理 ,默認是 ALL ,表示查詢所有記錄, DISTINCT 表示去掉重復的記錄
- WHERE 條件:類似于傳統 SQL的 where 條件,支持 AND 、OR 、BETWEEN、 IN 、NOT IN 等
- ORDER BY 與 SORT BY 的不同: ORDER BY 指全域排序,只有一個 Reduce 任務,而 SORT BY 只在本機做排序
- LIMIT :可以限制查詢的記錄數,如 SELECT * FROM tl LJMIT5 ,也可以實作 Topk 查詢,比如下面的查詢陳述句可以查詢銷售記錄最多的 5個銷售代表
SET mapred.reduce.tasks = 1
SELECT * FROM test SORT BY amount DESC LIMIT 5
- REGEX Column Specification : select 陳述句可以使用正則運算式做列選擇,下面的陳述句查詢除了 ds 和 hr 之外的所有列
SELECT `(ds|hr)?+.+` FROM test
2. join 表
join_table:
table_reference (INNER] JOIN table_factor (join_condition]
| table_reference {LEFTIRIGHTjFULL} (OUTER] JOIN table_reference join_ condition
| table_reference LEFT SEM JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference (join_condition] (as of Hive 0.10)
table reference:
table_factor
| join_table
table_factor:
tbl_name [alias]
| table_subquery alias
| (table_references)
join_condition:
on expression
- Hive中只支持等值連接,外連接和左半連接(left semi join),(從2.2.0版本后支持非等值連接);
- 可以連接2個以上的表,如:
select a.val, b.val,c.val
from a
join b
on (a.key=b.key1)
join c
on(c.key = b.key2);
- 如果連接中多個表的join key是同一個,則連接會被轉化為單個Map/Reduce任務
select a.val,b.val,c.val
from a
join b
on (a.key=b.key1)
join c
on(c.key=b.key1);
- join時大表放在最后: Reduce會快取join序列中除最后一個表之外的所有表的記錄,再通過最后一個表將結果序列化到檔案系統
- 如果想限制join的輸出, 應該在where子句中寫過濾條件,或是在join子句中寫,
- 但是有表磁區的情況,比如下面的第一個 SQL 陳述句所示,如果d表中找不到對應c表的記錄, d表的所有列都會列出 NULL ,包括 ds列, 也就是說, join 會過濾d表中不能找到匹配c表 join key 的所有記錄, 這樣, LEFT OUTER 就使得查詢結果與 WHERE 子句無關,解決辦法是在join 時指定磁區(如下面的第二個 SQL 陳述句所示)
--第一個 SQL 陳述句
SELECT c.val, d.val FROM c LEFT OUTER JOIN d ON (c.key=d.key)
WHERE a.ds='2010-07-07' AND b.ds='2010-07-07'
-- 第二個 SQL 陳述句
SELECT c.val, d.val FROM c LEFT OUTER JOIN d
ON (c.key=d.key AND d.ds=’ 2009-07-07 ’ AND c.ds='2009-07-07')
- left semi join是in/exists子查詢的一種更高效的實作,join子句中右邊的表只能在on子句中設定過濾條件,在where子句、select子句中或其他方式過濾都不行
SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key FROM B);
--可以被重寫為:
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b on (a.key = b.key)
三、Hive SQL 執行原理圖解
我們都知道,一個好的的 Hive SQL 和寫得不好的 Hive SQL ,對底層計算和資源的使用可能相差百倍甚至千倍、萬倍,
除了資源的浪費,不恰當地使用 Hive SQL 可能會運行幾個小時甚至十幾個小時都得不到運算結果,因此,我們深入的理解 Hive SQL 的執行程序和原理是非常有必要的,
以 group by 陳述句執行圖解為例:
我們假定一個業務背景:分析購買iPhone7客戶在各城市中的分布情況,即哪個城市購買得最多、哪個最少,
select city,count(order_id) as iphone7_count from orders_table where day='201901010' and cat_name='iphone7' group by city;
底層MapReduce執行程序:
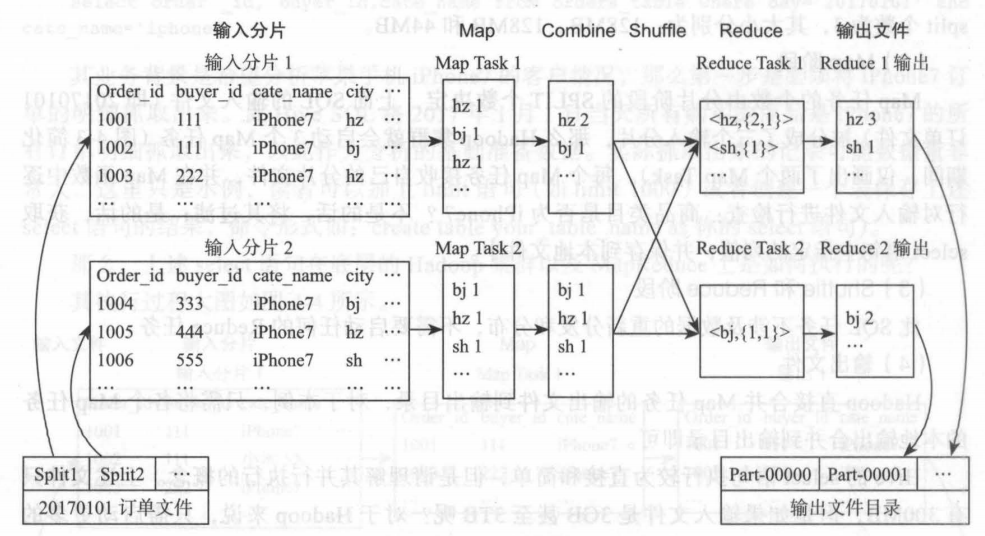
Hive SQL 的 group by 陳述句涉及資料的重新分發和分布,因此其執行程序完整地包含了 MapReduce 任務的執行程序,
( 1 )輸入分片
group by 陳述句的輸入檔案依然為 day=20170101 的磁區檔案,其輸入分片程序和個數同 select 陳述句,也是被分為大小分別為: 128MB 、128MB、44MB 三個分片檔案,
( 2 ) Map 階段
Hadoop 集群同樣啟動三個 Map 任務,處理對應的三個分片檔案;每個 map 任務處理其對應分片檔案中的每行,檢查其商品類目是否為 iPhone7 ,如果是,則輸出形如<city,1> 的鍵值對,因為需要按照 city 對訂單數目進行統計(注意和 select 陳述句的不同),
( 3 ) Combiner 階段
- Combiner 階段是可選的,如果指定了 Combiner 操作,那么 Hadoop 會在 Map 任務的地輸出中執行 Combiner 操作,其好處是可以去除冗余輸出,避免不必要的后續處理和網路傳輸開銷等
- 此列中,Map Task1 的輸出中< hz,1>出現了兩次,那么 Combiner 操作就可以將其合并為 <hz,2>
- Combiner 操作是有風險的,使用它的原則是 Combiner 的輸出不會影響到 Reduce 計算的最終輸入,例如,如果計算只是求總數、最大值和最小值,可以使用 combiner ,但是如果做平均值計算使用了 Combiner ,最終的 Reduce 計算結果就會出錯
( 4 ) Shuffle 階段
完整的shuffle包括磁區(partition),排序(sort)和分隔(spill)、復制(copy)、合并(merge)等程序,
- 對于理解group by陳述句,關鍵的程序實際就兩個,即磁區和合并;所謂磁區,即 Hadoop 如何決定將每個 Map 任務的每個輸出鍵值對分配到那個 Reduce Task 所謂合井,即在 一個Reduce Task 中,如何將來自于多個 Map Task 的同樣一個鍵的值進行合并
- Hadoop 中最為常用的磁區方法是 Hash Partitioner ,即 Hadoop 會對每個鍵取 hash 值,然后再對此 hash 值按照 reduce 任務數目取模,從而得到對應的 reduce ,這樣保證相同的鍵,肯定被分配到同一個 reduce 上,同時 hash 函式也能確保 Map 任務的輸出被均勻地分配到所有的 Reduce務上
( 5 )Reduce 階段
呼叫reduce函式,每個reduce任務的輸出存到本地檔案中
( 6 )輸出檔案
hadoop 合并 Reduce Task任務的輸出檔案到輸出目錄
四、小結
我們介紹了 Hive SQL 的執行原理,當然了,要知其然,并要知其所以然,理解 Hive 的執行原理是寫高效 SQL 的前提和基礎,也是掌握 Hive SQL 優化技巧的根本,接下來我們就要進入 Hive 優化實踐的環節啦,
 CSDN認證博客專家
Flink
Spark
資料中臺
CSDN認證博客專家
Flink
Spark
資料中臺
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/184835.html
標籤:其他
上一篇:阿里秒掛,瘋狂復習半個月,拿下美團offer(后臺開發JAVA崗)
下一篇:實時存盤引擎和實時計算引擎