前言
??本文所涉是筆者模式識別課的第一次大作業——用樸素貝葉斯來做nemo魚影像區域分割,它是用貝葉斯來做二元分類的簡單實踐,適合用來做貝葉斯演算法入門,現將簡要理論和筆者所寫代碼放在這里,供大家參考,不知道有沒有朋友有疑問,明明是影像區域分割,怎么又和二元分類扯上了關系,其實逐像素的影像分割,就是在做分類,當然,這里的分割不是指復雜的語意分割,只是簡單的根據灰度或者顏色分布來做區域分割,
??貝葉斯理論:機器學習十大經典演算法:深入淺出聊貝葉斯決策
任務與資料
-
資料
??影像fish.bmp與掩膜mask.mat,掩膜點乘影像,即可獲得待分割區域ROI,小魚區域主要有兩種型別的區域,以下就是要用樸素貝葉斯把這兩個部分分出來——用不同的顏色表示不同區域,

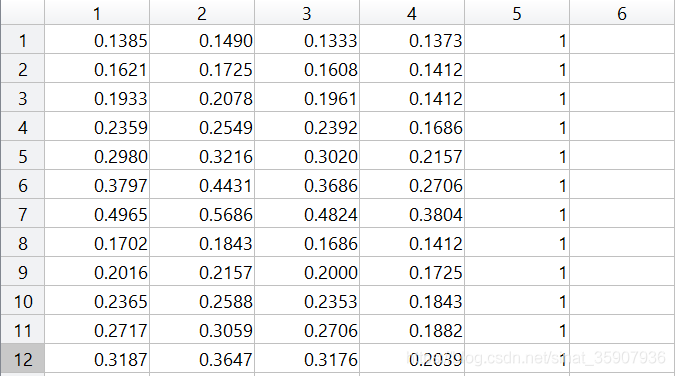
??訓練資料sample.mat,它是一個二維的matlab陣列,第一列為灰度值,第2-4列為RGB值,第五列為當前灰度值或者RGB值對應的類別標簽(1,-1),它蘊含著兩種型別區域的灰度值或者RGB值的分布,根據它來估計兩種型別區域的類概率密度函式的引數,
-
任務
??任務1:對訓練資料用極大似然,估計出兩類區域灰度值的概率密度函式,并用最小錯誤貝葉斯對fish.bmpROI灰度影像進行分割,
??任務2:對訓練資料用極大似然,估計出兩類區域RGB值的概率密度函式,并用最小錯誤貝葉斯對fish.bmpROI彩色影像進行分割,
理論與實作
??統計模型的訓練程序就是類條件概率密度函式引數的估計程序,通過引數估計方法,從訓練樣本中估計出引數,便完成了訓練,測驗或者說應用程序就是用估計出的類概率密度函式和代表類別占比的先驗概率進行統計決策或者分類的程序,最大似然是常用的引數估計方法,用在高斯混合模型(GMM)中,
-
極大似然估計
??假定我們面對的就是一個高斯混合模型(GMM),即每個類別訓練樣本的灰度值或者RGB值均服從正態分布,正態分布含有兩個引數,均值方差或者均值協方差,
??我們知道,極大似然的目的是要找到最可能產生該樣本序列的概率密度函式的引數,而在某概率密度函式引數下產生該樣本序列的概率如式(1),即似然函式,
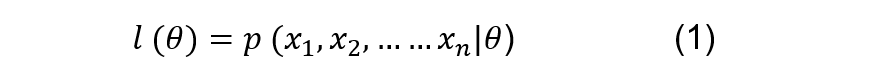
??當每個樣本都獨立同分布(iid)時,對應的貝葉斯決策即為樸素貝葉斯,則式(1)便可以化為概率連乘的形式,如式(2),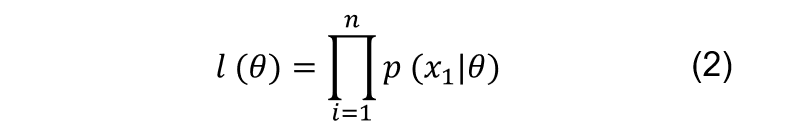
??兩邊同取自然對數后,用導數工具可以求出其極大值點,即極大似然,在高斯混合模型的情況下,某個樣本序列似然函式的極值點的決議解為:
??一維情況:對應灰度值,
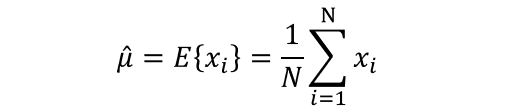
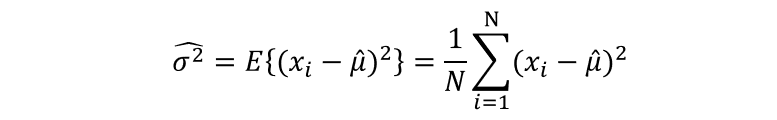
??多維情況:三維時對應RGB值
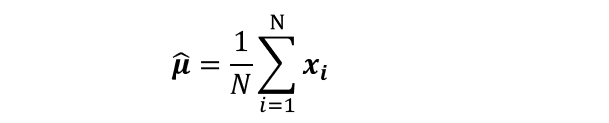
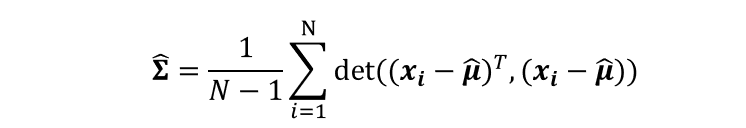
??由以上4個式子,我們可以看出,我們習以為然的求均值和方差的公式,其實是在默認中央極限定理的前提下,用最大似然估計的結果,
copyright ?意疏:https://blog.csdn.net/sinat_35907936/article/details/109167111
-
最小錯誤貝葉斯決策
??由機器學習十大經典演算法:深入淺出聊貝葉斯決策,我們可以知道,在給類別地位均等時,采用最小錯誤率或者最大后驗概率貝葉斯決策即可,只比較分子,即下式,便可得出決策——選兩類中結果較大者為決策結果,
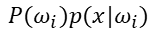
-
演算法流程
??演算法流程如下圖所示,前半部分時統計模型的訓練程序,即用最大似然(MLE)進行引數估計,測驗程序,就是用決策的程序,圖中為為Nemo魚逐像素做灰度或者顏色決策或者分割的程序,PDF為scipy包中包含的正態分布PDF函式,只需給其引數和輸入即可得到輸出值,
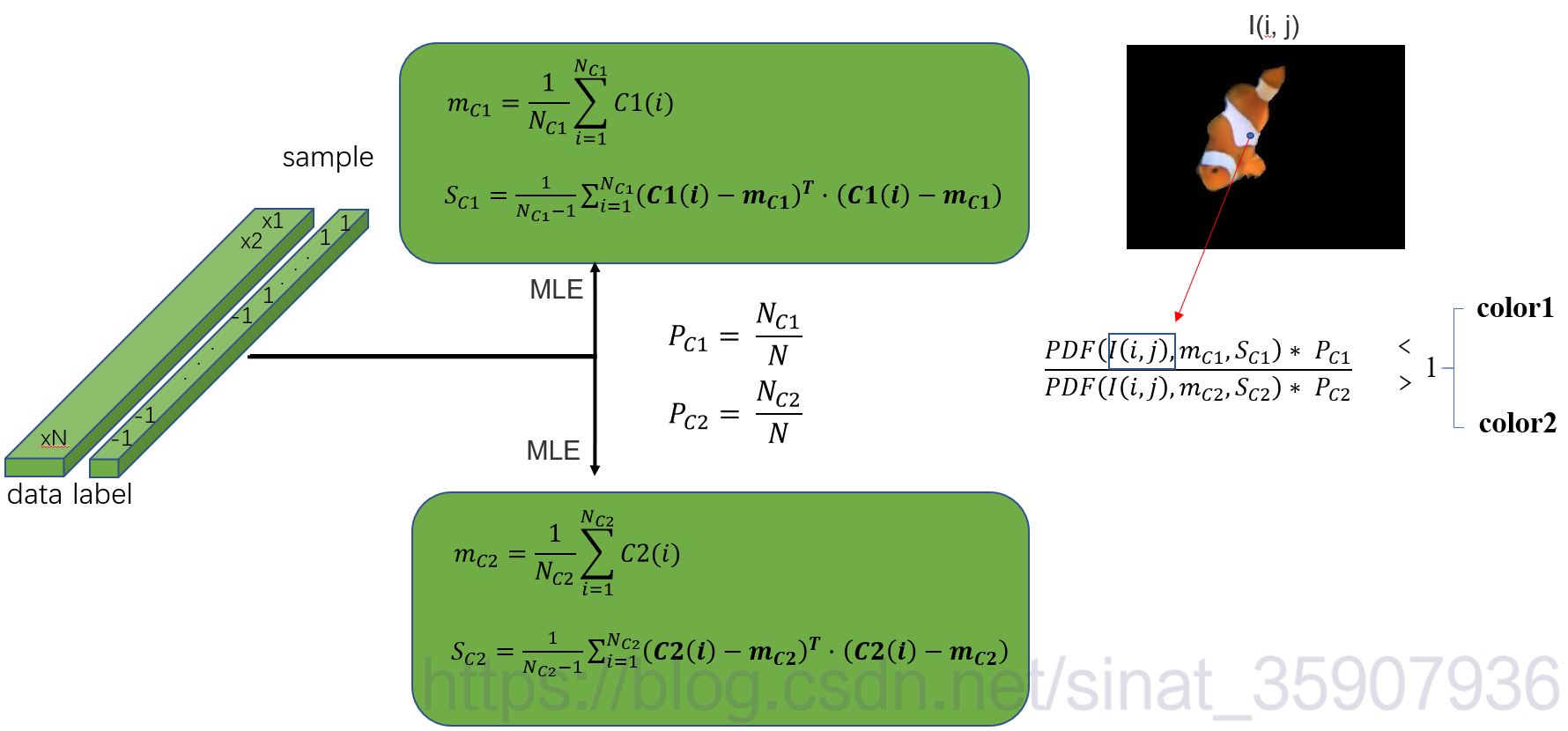
-
演算法實作
??資料加載與決議,python可以通過scipy模塊讀取matlab檔案,matlab檔案讀入后是以字典的形式展現的,
from scipy import io
from scipy.stats import norm
import numpy as np
import PIL.Image as Image
import matplotlib.pyplot as plt
from scipy.stats import multivariate_normal
# 資料加載與決議
mask = io.loadmat('mask.mat')['Mask'] # 資料為一個字典,根據key提取資料
sample = io.loadmat('sample.mat')['array_sample']
src_image = Image.open('fish.bmp')
RGB_img = np.array(src_image)
Gray_img = np.array(src_image.convert('L'))
# 根據Mask,獲取ROI區域
Gray_ROI = (Gray_img * mask)/255
RGB_mask = np.array([mask, mask, mask]).transpose(1, 2, 0)
RGB_ROI = (RGB_img * RGB_mask)/255
# 根據標簽拆分資料
gray1 = []
gray2 = []
RGB1 = []
RGB2 = []
for i in range(len(sample)):
if(sample[i][4]) == 1.: # 資料第5位為標簽
gray1.append(sample[i][0])
RGB1.append(sample[i][1:4])
else:
gray2.append(sample[i][0])
RGB2.append(sample[i][1:4])
RGB1 = np.array(RGB1)
RGB2 = np.array(RGB2)
??計算先驗概率,先驗概率可以通過樣本中各類別的占比得來,也可以通過各類別在世界中的占比而來,
# 計算兩類在資料中的占比,即先驗概率
P_pre1 = len(gray1)/len(sample)
P_pre2 = 1-P_pre1
??一維貝葉斯決策,計算一維輸入時貝葉斯后驗概率,
# 一維時,貝葉斯
# ------------------------------------------------------------------------------------#
# 資料為一維時(灰度影像),用最大似然估計兩個類別條件概率pdf的引數——標準差與均值
gray1_m = np.mean(gray1)
gray1_s = np.std(gray1)
gray2_m = np.mean(gray2)
gray2_s = np.std(gray2)
# print(gray1_s, gray2_s)
# 繪制最大似然估計出的類條件pdf
x = np.arange(0, 1, 1/1000)
gray1_pdf = norm.pdf(x, gray1_m, gray1_s)
gray2_pdf = norm.pdf(x, gray2_m, gray2_s)
plt.figure(0)
ax = plt.subplot(2, 1, 1)
ax.set_title('p(x|w)')
ax.plot(x, gray1_pdf, 'r', x, gray2_pdf, 'b')
ax.set_xlabel('x')
ax.set_ylabel('f(x)')
ax1 = plt.subplot(2, 1, 2)
ax1.plot(x, P_pre1*gray1_pdf, 'r', x, P_pre2*gray2_pdf, 'b')
ax1.set_title('p(w)*p(x|w)')
ax1.set_xlabel('x')
ax1.set_ylabel('f(x)')
# 用最大后驗貝葉斯對灰度影像進行分割
gray_out = np.zeros_like(Gray_img)
for i in range(len(Gray_ROI)):
for j in range(len(Gray_ROI[0])):
if Gray_ROI[i][j] == 0:
continue
elif P_pre1*norm.pdf(Gray_ROI[i][j], gray1_m, gray1_s) > P_pre2*norm.pdf(Gray_ROI[i][j], gray2_m, gray2_s): # 貝葉斯公式分子比較
gray_out[i][j] = 100
else:
gray_out[i][j] = 255
# plt.imshow(RGB_ROI)
plt.figure(1)
bx = plt.subplot(1, 1, 1)
bx.set_title('gray ROI')
bx.imshow(Gray_ROI, cmap='gray')
plt.figure(2)
bx1 = plt.subplot(1, 1, 1)
bx1.set_title('gray segment result')
bx1.imshow(gray_out, cmap='gray')
??分割結果:
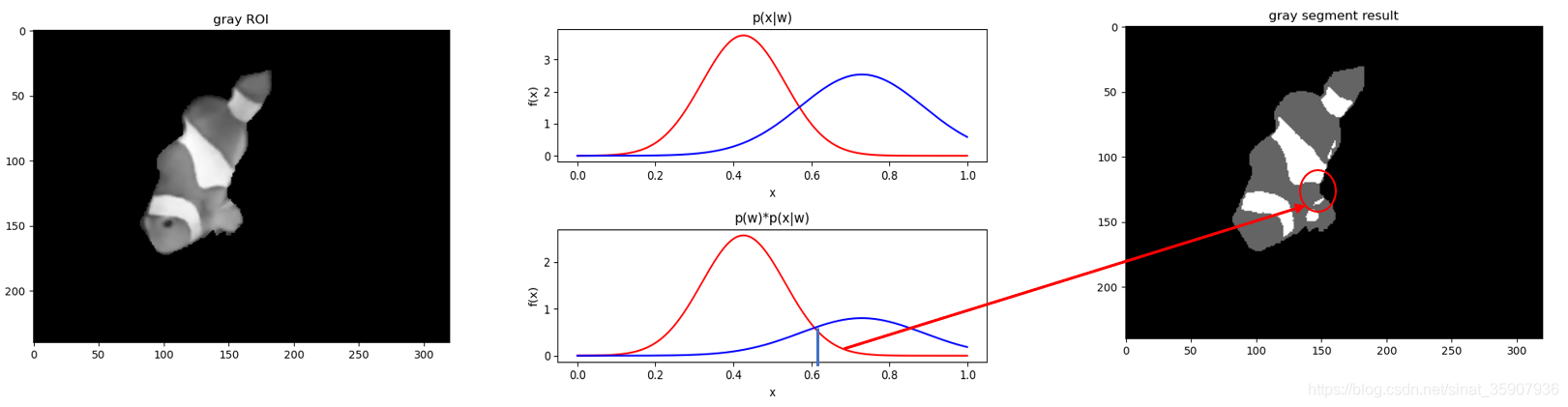
copyright ?意疏:https://blog.csdn.net/sinat_35907936/article/details/109167111
??三維貝葉斯決策,計算三維輸入時的貝葉斯后驗概率,
# 三維時,貝葉斯
# ------------------------------------------------------------------------------------#
# 資料為三維時(彩色影像),用最大似然估計兩個類別條件概率pdf的引數——協方差與均值
RGB1_m = np.mean(RGB1, axis=0)
RGB2_m = np.mean(RGB2, axis=0)
cov_sum1 = np.zeros((3, 3))
cov_sum2 = np.zeros((3, 3))
for i in range(len(RGB1)):
# print((RGB1[i]-RGB1_m).reshape(3, 1))
cov_sum1 = cov_sum1 + np.dot((RGB1[i]-RGB1_m).reshape(3, 1), (RGB1[i]-RGB1_m).reshape(1, 3))
for i in range(len(RGB2)):
cov_sum2 = cov_sum2 + np.dot((RGB2[i]-RGB2_m).reshape(3, 1), (RGB2[i]-RGB2_m).reshape(1, 3))
RGB1_cov = cov_sum1/(len(RGB1)-1) # 無偏估計除以N-1
RGB2_cov = cov_sum2/(len(RGB2)-1)
xx = np.array([x, x, x])
# print(P_pre1*multivariate_normal.pdf(RGB1, RGB1_m, RGB1_cov))
# 用最大后驗貝葉斯對彩色影像進行分割
RGB_out = np.zeros_like(RGB_ROI)
for i in range(len(RGB_ROI)):
for j in range(len(RGB_ROI[0])):
if np.sum(RGB_ROI[i][j]) == 0:
continue
elif P_pre1*multivariate_normal.pdf(RGB_ROI[i][j], RGB1_m, RGB1_cov) > P_pre2*multivariate_normal.pdf(RGB_ROI[i][j], RGB2_m, RGB2_cov): # 貝葉斯公式分子比較
RGB_out[i][j] = [255, 0, 0]
else:
RGB_out[i][j] = [0, 255, 0]
# print(RGB_ROI.shape)
# 顯示RGB ROI,與彩色分割結果
plt.figure(3)
cx = plt.subplot(1, 1, 1)
cx.set_title('RGB ROI')
cx.imshow(RGB_ROI)
plt.figure(4)
cx1 = plt.subplot(1, 1, 1)
cx1.set_title('RGB segment result')
cx1.imshow(RGB_out)
plt.show()
??分割結果:
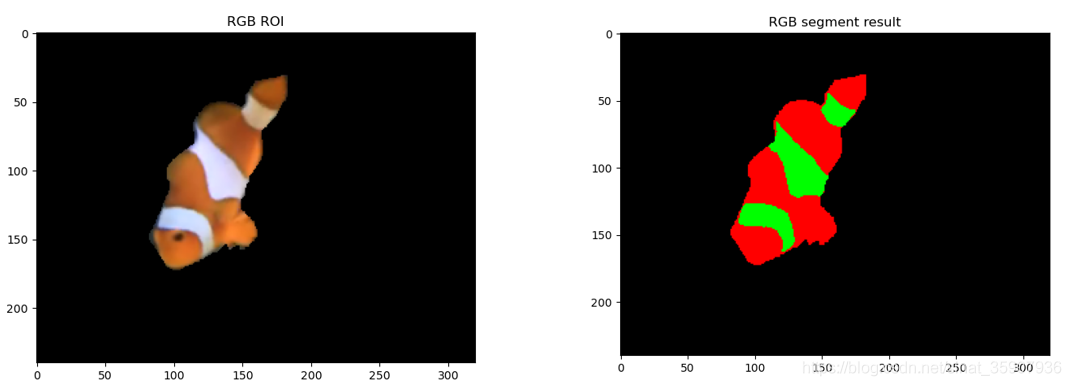
copyright ?意疏:https://blog.csdn.net/sinat_35907936/article/details/109167111
參考
??張學工.模式識別(第三版).M.清華大學出版社.2010.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/185010.html
標籤:其他
上一篇:python入門(二)小康小白