基于上次的簡單爬蟲之后,這次的爬蟲添加了多執行緒的新元素,使爬取的速度在原來的基礎上快了N倍,話不多說,來看代碼
首先我們選擇的網站還是上次的H128壁紙,不知道具體流程的可以看下上次寫的入門代碼
傳送門!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
打開網站,這里我選擇的是動漫專區的壁紙,我們的目的是把所有動漫壁紙爬下來,我們發現一共有98頁圖片
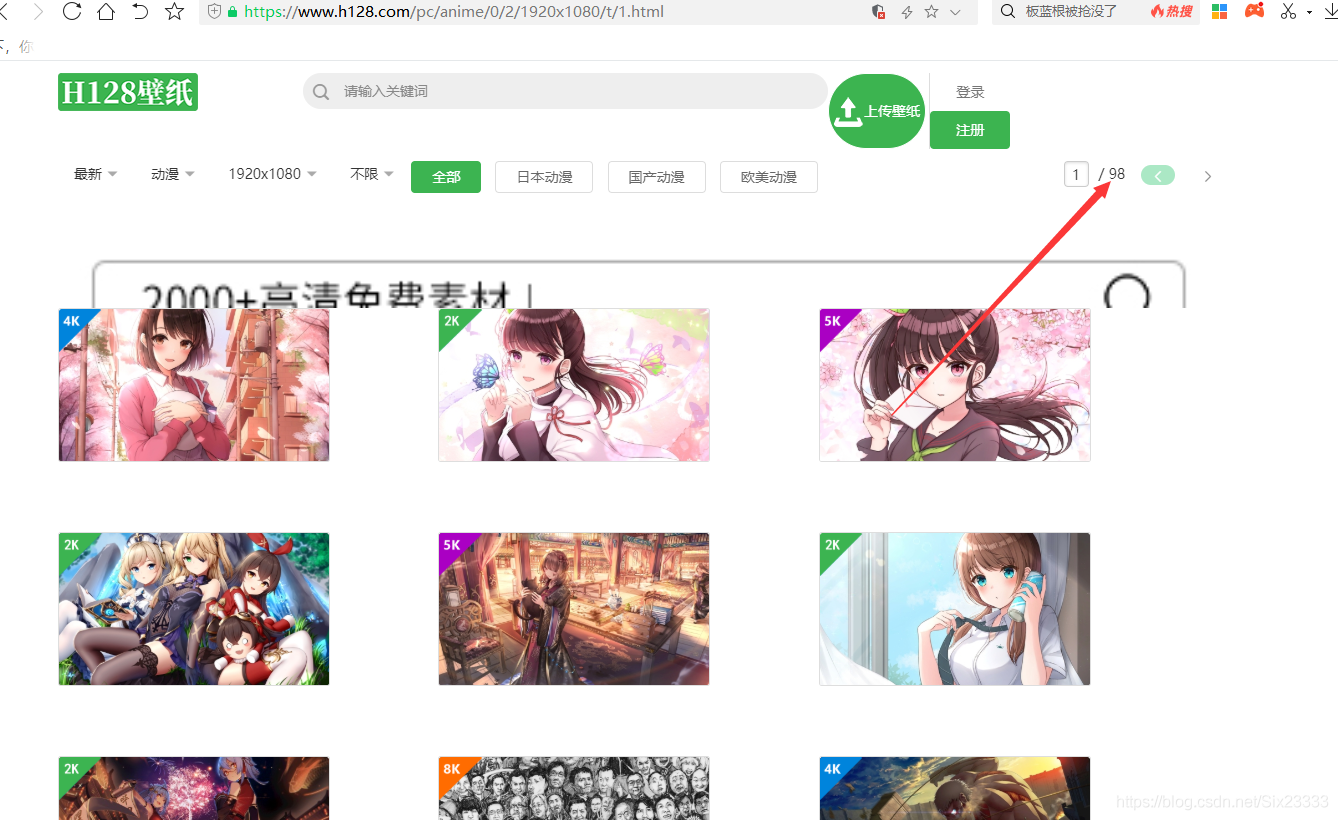
所以我們要做的是觀察每頁圖片鏈接的關系,我們打開第二頁圖片觀察
發現兩頁圖片的鏈接分別是
https://www.h128.com/pc/anime/0/2/1920x1080/t/1.html
https://www.h128.com/pc/anime/0/2/1920x1080/t/2.html
我們發現兩個網頁只有t/后面的資料不同由此我們觀察后面幾頁,最終我們發現/t/后面的數字就是代表頁數,所以在最開始我們建立一個函式來存放我們需要的網頁鏈接
如下:
page_links_list = ['https://www.h128.com/pc/anime/0/2/1920x1080/t/1.html']
def GetUrls(page_links_list):
pages = int(input("請輸入你想爬取的頁數:"))
if pages > 1:
for page in range(2, pages + 1):
url = 'https://www.h128.com/pc/anime/0/2/1920x1080/t/' + str(page) + '.html'
page_links_list.append(url)
else:
page_links_list = page_links_list
然后就是我們多執行緒的應用了,我們要用的是python的threading模塊首先需要匯入threading
import threading
首先建立一個glock 用來控制
gLock = threading.Lock()
**threading 提供了 Lock 類,該類能夠在某個執行緒訪問某個變數的時候對變數加鎖,此時其它執行緒就不能訪問該變數,直到該 Lock 被釋放其它執行緒才能夠訪問該變數
**
我們爬蟲需要生產者行程和消費者行程,生產者的執行緒專門用來生產一些資料,然后存放到一個中間的變數中,消費者再從這個中間的變數中取出資料進行消費,但是因為要使用中間變數,中間變數經常是一些全域變數,因此需要使用鎖來保證資料完整性,在這個代碼中生產者行程負責來獲取我們圖片的url,而消費者行程的目的是下載圖片,
生產者代碼如下:
class Generant(threading.Thread):
def run(self):
while len(page_links_list) > 0:
gLock.acquire() #上鎖
page_url = page_links_list.pop()
gLock.release() #釋放鎖
r = requests.get(page_url,headers = headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
a = re.findall('<img src="https:(.*?)" alt',r.text)
gLock.acquire() #上鎖
for i in a :
x = 'https:' + i
x = x.replace('w_487', 'w_1421').replace('h_274', 'h_799')
img_links_list.append(x)
gLock.release() #釋放鎖
消費者代碼如下
class Consumer(threading.Thread,):
def run(self):
while True:
gLock.acquire()
if len(img_links_list) == 0:
gLock.release()
continue
else:
img_url = img_links_list.pop()
gLock.release()
filename = img_url.split('?')[0].split('/')[-1]
r = requests.get(img_url)
print('正在下載:', filename)
path = './picture/' + filename
with open(path,'wb') as f:
f.write(r.content)
f.close()
if len(img_links_list) == 0:
end = time.time()
print("消耗的時間為:", (end - start))
exit()
最后的代碼就是啟動執行緒
for x in range(5):
Generant().start()
for x in range(5):
Consumer().start()
觀看運行結果:
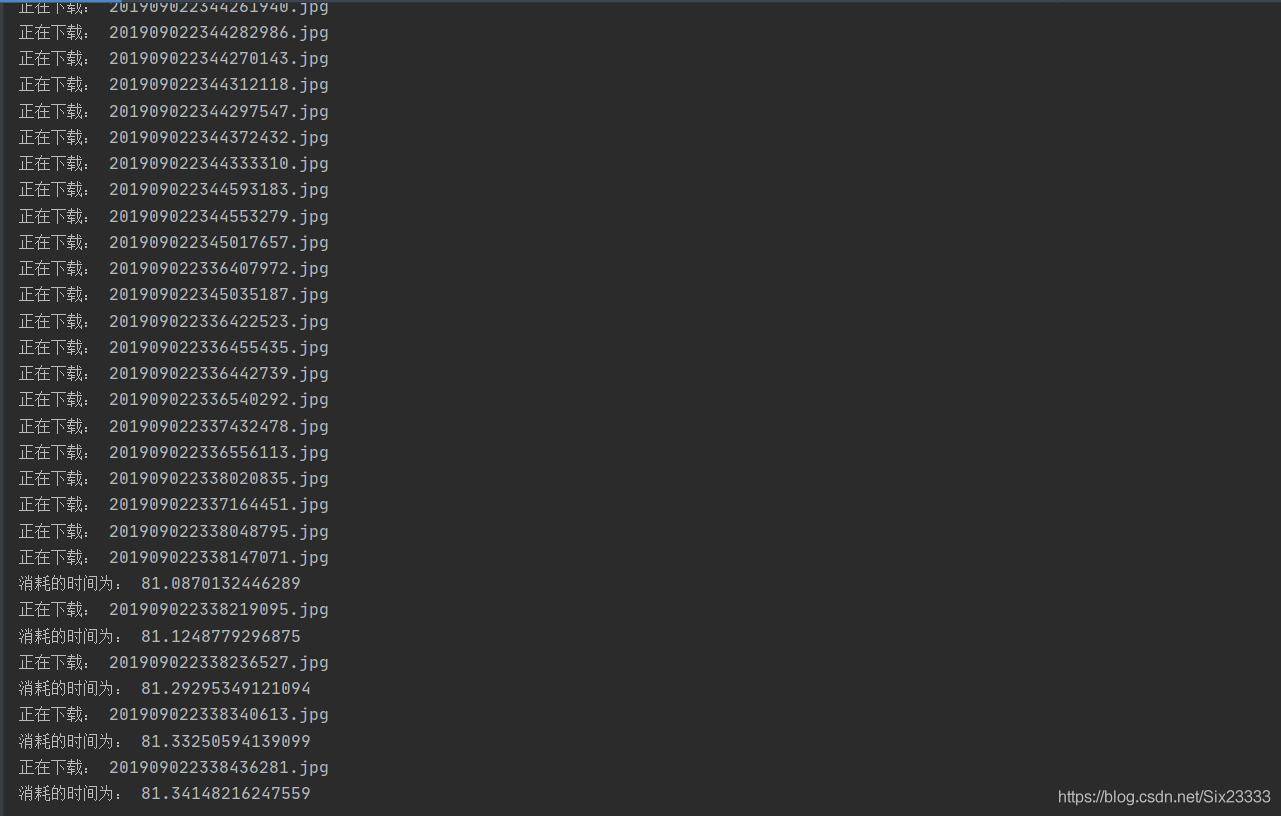
這里是下載了50頁圖片的時間,比起單執行緒還是很快的,
最后附上完整代碼
下面展示一些 行內代碼片,
import threading
import requests
import re
import time
import os
page_links_list = ['https://www.h128.com/pc/anime/0/2/1920x1080/t/1.html']
img_links_list = []
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"
}
def GetUrls(page_links_list):
pages = int(input("請輸入你想爬取的頁數:"))
if pages > 1:
for page in range(2, pages + 1):
url = 'https://www.h128.com/pc/anime/0/2/1920x1080/t/' + str(page) + '.html'
page_links_list.append(url)
else:
page_links_list = page_links_list
gLock = threading.Lock()
class Generant(threading.Thread):
def run(self):
while len(page_links_list) > 0:
gLock.acquire() #上鎖
page_url = page_links_list.pop()
gLock.release() #釋放鎖
r = requests.get(page_url,headers = headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
a = re.findall('<img src="https:(.*?)" alt',r.text)
gLock.acquire() #上鎖
for i in a :
x = 'https:' + i
x = x.replace('w_487', 'w_1421').replace('h_274', 'h_799')
img_links_list.append(x)
gLock.release() #釋放鎖
class Consumer(threading.Thread,):
def run(self):
while True:
gLock.acquire()
if len(img_links_list) == 0:
gLock.release()
continue
else:
img_url = img_links_list.pop()
gLock.release()
filename = img_url.split('?')[0].split('/')[-1]
r = requests.get(img_url)
print('正在下載:', filename)
path = './picture/' + filename
with open(path,'wb') as f:
f.write(r.content)
f.close()
if len(img_links_list) == 0:
end = time.time()
print("消耗的時間為:", (end - start))
exit()
if __name__ == '__main__':
GetUrls(page_links_list)
if os.path.exists('./picture'):
print("檔案已存在")
else:
os.mkdir('./picture')
start = time.time()
for x in range(5):
Generant().start()
for x in range(5):
Consumer().start()
最后如果想要全站的圖片只要把鏈接改一下就OK
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/185013.html
標籤:其他
上一篇:自制爬蟲框架