文章目錄
- 貝葉斯學習 Bayesian Learning
- 一、介紹
- 1.1 先驗概率
- 1.2 后驗概率
- 二、貝葉斯理論
- 2.1 舉例介紹
- 2.2 MAP假設
- 2.3 概率法則
- 三、最小描述長度假設
- 四、貝葉斯最優分類器
- 五、Gibbs演算法
- 六、Bagging分類器
- 七、樸素貝葉斯分類器
- 八、貝葉斯信念網路
- 九、總結
貝葉斯學習 Bayesian Learning
一、介紹
貝葉斯概率論于1764年提出,
貝葉斯學習提供了定量的方法來衡量證據如何支持其他假設,
貝葉斯決策理論是一種基本的統計方法,它利用決策所伴隨的概率和成本來量化各種決策之間的權衡,
首先,我們假設所有的概率知道,那么,我們將研究概率結構不完全已知的情況,
1.1 先驗概率
先驗概率是指根據以往經驗和分析得到的概率,它往往作為"由因求果"問題中的"因"出現,
那么,如何通過先驗概率做決策呢?
- 如果 P(w1) > P(w2),則決策結果——w1
- 如果 P(w1) ≤ P(w2),則決策結果——w2
這種決策的誤差是:P(error) = min{P(w1), P(w2 )}
1.2 后驗概率
后驗概率是指依據得到"結果"資訊所計算出的最有可能是那種事件發生,是"執果尋因"問題中的"因",
貝葉斯學習方法的特點:
- 每一個觀察到的訓練例子都可以增加或減少假設正確的估計概率(靈活性)
- 先驗知識可以與觀測資料相結合來確定一個假設的最終概率
- 貝葉斯方法可以適應進行概率預測的假設
- 通過組合新的假設,可以對多個假設進行加權分類
- 可以為評估假設提供一個黃金標準
二、貝葉斯理論
2.1 舉例介紹
貝葉斯決策理論早于決策樹學習和神經網路,應用在統計學理論領域,
目標:學習到最好的假設,貝葉斯學習中:“最好的假設“就是“最可能的假設”,
Bayes定理允許基于如下因素來計算可能的假設:
- 假設先驗概率
- 假設條件下觀察某些資料的概率
- 觀測資料本身
給定資料D加上H中各種假設的先驗概率的任何初始知識,我們得到以下符號:
- h的先驗概率P(h):它反映了我們在觀察資料之前所掌握的關于h∈h是一個正確假設的任何背景知識
- D的先驗概率,P(D):它反映了在不知道哪個假設成立的情況下,訓練資料D被觀察到的概率,
- 條件概率,P(D | h):它表示在假設h∈h成立的某個世界中觀測資料D的概率,
- 后驗概率,P(h | D):它表示給定觀測訓練資料D時h保持不變的概率,這是機器學習研究人員感興趣的數量,
于是可以通過此公式計算后驗概率,這也是貝葉斯學習方法的基石:
P(h | D)= P(D | h) P(h)/ P(D)*
2.2 MAP假設
在許多學習場景中,目標是在給定觀測資料D的情況下,從一組候選假設h中找到最可能的假設h,任何這種最大似然假設都被稱為最大后驗概率假設,(Maximum A Posteriori (MAP) 假設)
貝葉斯理論可用于確定MAP假設:
h = argmax(h∈H) P(h | D)
= argmax(h∈H) P(D | h)* P(h)/ P(D)
= argmax(h∈H) P(D | h)* P(h)
如果每個假設h在假設集H中的概率是相等的,則我們只需要計算使得P(D | h)最大的h即可,MAP會演化為極大似然**Maximum Likelihood **(ML),即h = argmax(h∈H) P(D | h)
2.3 概率法則
- P(A ∩ B) = P(A|B)P(B) = P(B|A)P(A)
- P(A∪B) = P(A) + P(B) - P(AB)
- 如果A、B事件相互獨立:則 P(A ∩ B) = P(A)P(B) ,且P(ABC…) = P(A)P(B)P?…
- 奧卡姆的剃刀:最簡單假設→描述長度最短的假設
三、最小描述長度假設
Minimum Description Length Principle(MDL)
hMDL = argmin(h∈H) Lc1(h)+ Lc2(D | h)
其中:
Lc1(h)是假設表述的位元長度(——表示模型復雜度)
Lc2(D | h)是使用假設h進行編碼時,資料D描述的位元長度(——表示錯誤)
Lc(x)是在方案c下編碼x的最小位元長度
最小描述長度假設和最大后驗概率假設本質上是相同的
四、貝葉斯最優分類器
Bayes optimal classification,同時考慮所有的假設并且進行加權,
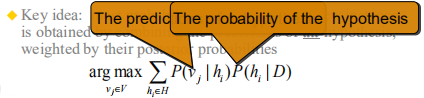
argmax(vj∈V) Σ(hi∈H) P(vj|hj)P(hi|D)
舉個例子:
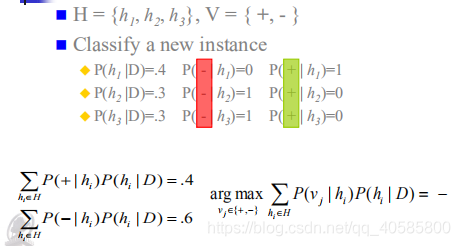
該方法使新實體正確分類的概率最大化,
使用相同的假設空間和相同的先驗知識的分類方法沒有一種方法能比這種方法的平均性能好,
這種方法所做的預測與H中沒有包含的假設相對應,
存在的問題:需要對所有可能的模型/假設進行總結,當模型的假設空間很大時,它是昂貴的或不可能的,
解決方案:抽樣——Gibbs演算法
五、Gibbs演算法
Gibbs演算法:根據h上的后驗概率分布P(h | D),從h中隨機選擇一個假設h,使用h對新實體x進行分類,
在一定條件下,該演算法期望誤差最多為Bayes最優分類器的兩倍(Harssler等人,1994年),
可以通過從P(h | D)中抽樣多個假設并平均其分類結果來改進,
- 馬爾可夫鏈蒙特卡羅(MCMC)抽樣
- 重要性抽樣
缺點:從P(h | D)中抽樣是很困難的,
由此提出了Bagging分類器——通過對訓練樣本的抽樣實作抽樣P(h | D)
六、Bagging分類器
Bagging分類器——通過對訓練樣本的抽樣實作抽樣P(h | D)
Boostrap 采樣,(使用bootstrap采樣和從P(h | D)中采樣幾乎是相同的):
- 通過隨機抽取m個示例創建Di,替換D
- Di期望從D中漏掉37%的實體
Bagging 演算法:
- 創建k個bootstrap樣本D1,D2,…,Dk
- 在每個Di上訓練不同的分類器hi
- 利用等權分類器投票對新實體進行分類
例如:經過實證研究,使用Bagging的決策樹比單純的決策樹要效果好,
模型的Error通常同時要考慮偏差和方差,即:Error = Bias + Variance
其中Bias,偏差,指的是模型預測值和真實值的差別;Variance,方差,指的是模型對給定資料集進行預測的變化率,
Bagging分類器比單一分類器表現的好的原因就在于它可以有效降低模型的方差,
七、樸素貝葉斯分類器
假設屬性取值ai之間互相獨立,
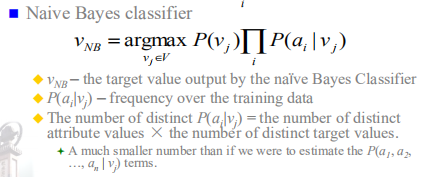
Vnb:樸素貝葉斯分類器的輸出結果
P(ai|vj):滿足vj的條件下各個屬性值(相互獨立)的頻率
一道題目:
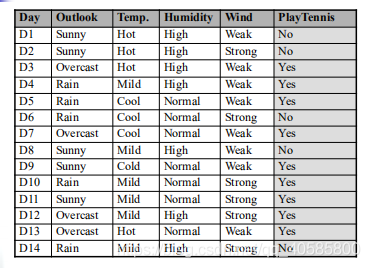

因此 Vnb = no,且目標值為no的條件概率為:0.0206/0.0206+0.0053 = 0.795
八、貝葉斯信念網路
貝葉斯最有分類器應用成本較高;樸素貝葉斯使用條件獨立假設,在許多場景下這樣的假設是有局限性的,
貝葉斯信念網路提供了一種折衷的方案——允許宣告適用于變數子集的條件獨立性假設,
貝葉斯信念網路是一種概率圖形模型,它表示:
- 通過有向無環圖(DAG)得到的一組變數及其條件獨立性
- 變數集合的聯合概率分布
例如,貝葉斯網路可以表示疾病和癥狀之間的概率關系,給定癥狀,網路可用于計算各種疾病出現的概率,
形式上,貝葉斯網路是有向無環圖:
- 節點表示貝葉斯意義上的變數:可以是可觀測量、潛在變數、未知引數或假設,
- 邊表示條件依賴
- 未連接的節點表示相互有條件獨立的變數,
- 每個節點與一個概率函式相關聯,該函式將節點父變數的一組特定值作為輸入,并給出節點所代表變數的概率,
- 例如,如果父項是m個布爾變數,那么概率函式可以用一個包含2m個條目的表來表示,其父項的2m個可能組合中的每個條目都有一個條目為真或假,
九、總結
- 貝葉斯方法為概率學習方法提供了基礎,該方法適應(并要求)關于替代假設的先驗概率和觀察給定假設的各種資料的概率的知識,
- 貝葉斯方法允許根據這些假設的先驗和觀測資料為每個候選假設分配一個后驗概率,
- 貝葉斯方法可以用來確定給定資料的最可能假設——最大后驗概率(MAP)假設,(這是最佳假設,因為沒有其他假設更有可能)
- Bayes最優分類器結合了所有備選假設的預測,并按其后驗概率加權,以計算每個新實體的最可能分類
- naive bayes分類器是一種貝葉斯學習方法,在許多實際應用中得到了廣泛的應用,它之所以被稱為“天真”,是因為它包含了一個簡化的假設,即給定實體的分類,屬性值是有條件獨立的,當滿足這個假設時,天真的Bayes分類器是通常相當有效,
- 貝葉斯信念網路為屬性子集之間的條件獨立假設集提供了一種更具表現力的表示,
- 最小描述長度原則建議選擇最小假設描述長度加上給定假設資料描述長度的最小假設,貝葉斯定理和資訊論的基本結果可以為這一原理提供理論依據,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/185586.html
標籤:其他
上一篇:手寫喜馬拉雅APP特效
下一篇:建站服務選哪家