文章目錄
- 《這是我見過最強的OCR開源演算法模型了》
- 前言
- 一、來吧,展示!
- 二、OCR簡介
- (一)什么是OCR
- (二)應用舉例
- (三)OCR難點
- 三、PaddleOCR介紹
- (一)總結介紹
- (二)相關地址總結
- 四、PaddleOCR的使用
- (一)PaddleOCR專案介紹
- (二)測驗自己的資料
- 五、多維度對比分析
- (一)教程的完備性對比
- (二)易用性對比
- (三)運行速度對比
- (四)精度對比
- (五)多角度對比
- (六)其他分析
- 六、總結
《這是我見過最強的OCR開源演算法模型了》
前言
最近參加“中國軟體杯”的一個OCR識別相關的比賽,
賽題鏈接:http://www.cnsoftbei.com/plus/view.php?aid=516
部分要求如下:

手撕代碼害怕鴨,

我們團隊在題目的允許上,去尋找開源的OCR識別演算法的模型,在github上有AdvancedEAST和AttentionOCR演算法,知名度還是比較高的,還有EasyOCR,還有PaddleOCR,對這幾種OCR識別演算法模型做了分析,得出了一些結論,并且選擇了一個精確度特別高的模型,具體是誰,還需要繼續往下看,
一、來吧,展示!
想了解一個東西,肯定要先看一下
效果如何,就像看論文一樣,肯定先看摘要,如果摘要里提及的內容個關鍵點并不是自己想要的,那么就沒必要往下看了,
她的識別效果有如下:

她不管你是橫著、還是豎著、還是標點符號;只要是文字就能給你檢測出來,精度肯定也沒的說,大都在0.98以上,
她現在已經支持漢語、英語、日語、德語、法語等等語言的識別,
她關鍵還有直接操作式 的網頁版和移動版,沒編程基礎,沒開發環境也能讓你輕松使用,
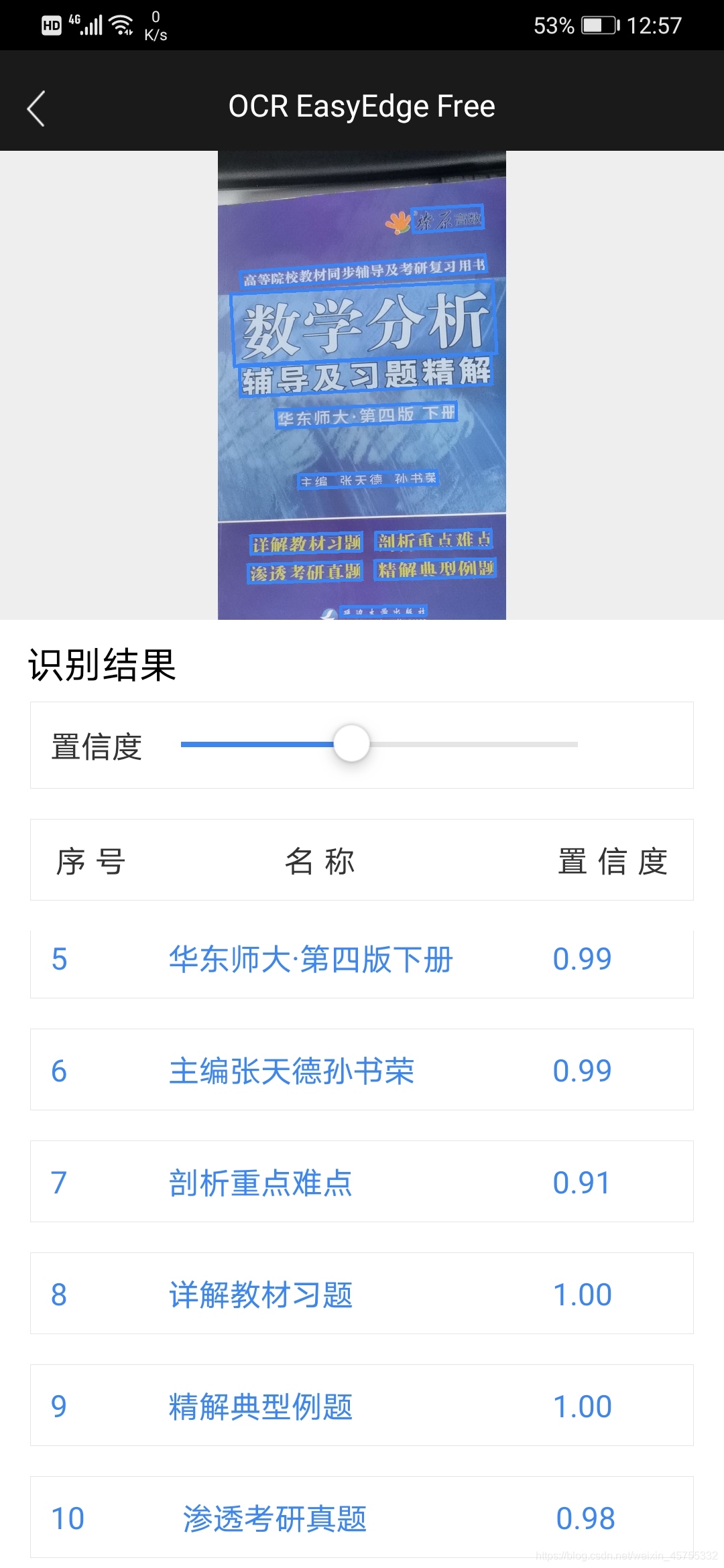
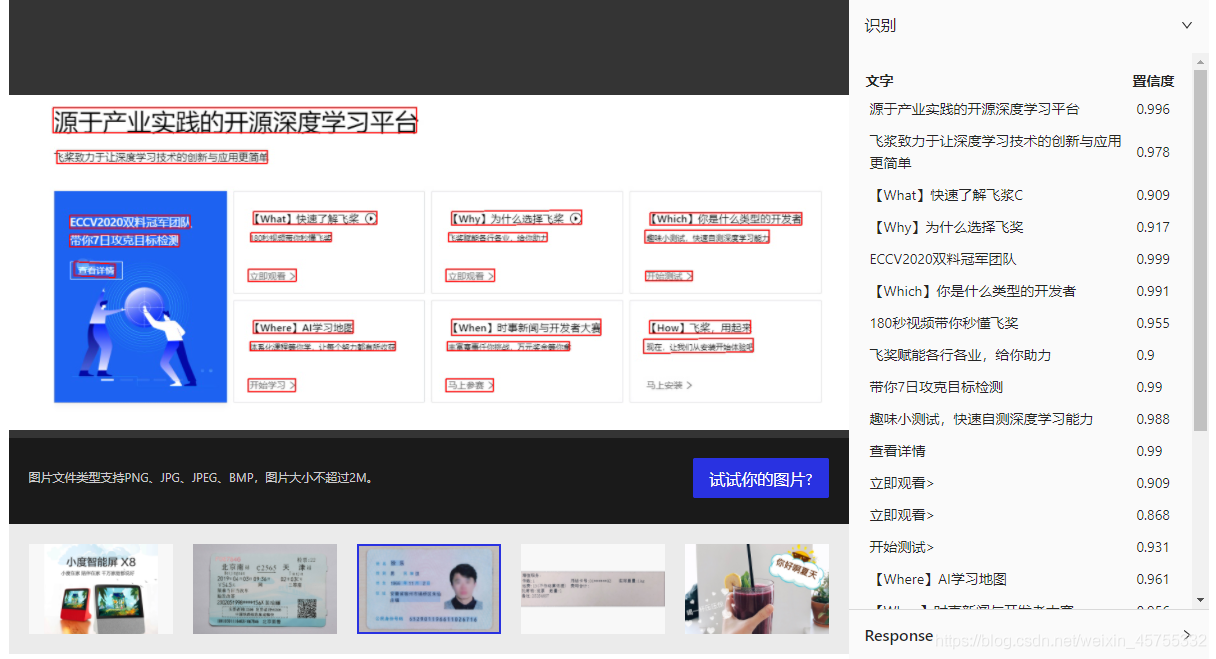
不得不承認,這個開源的專案真是的良品,這效果太棒了,方便、簡單、實用、識別的還賊快,真的愛了,

哈哈,她看起來是不是很棒呀!
但是看這么多了,你還不知道我說的她是誰,是不是挺著急的,
她有著一層神秘的面紗,咱們慢慢的來揭開這層神秘的面紗,
她就是百度開源的PaddleOCR專案,
光說不練假把式下面就具體介紹下OCR以及PaddleOCR的優越性能和開發一個簡單的示例使用步驟,
我們的參賽作品(部分PPT展示):
PPT可能做的不太好,大家有問題可以盡管提出來,嘿嘿,多多交流嘛!
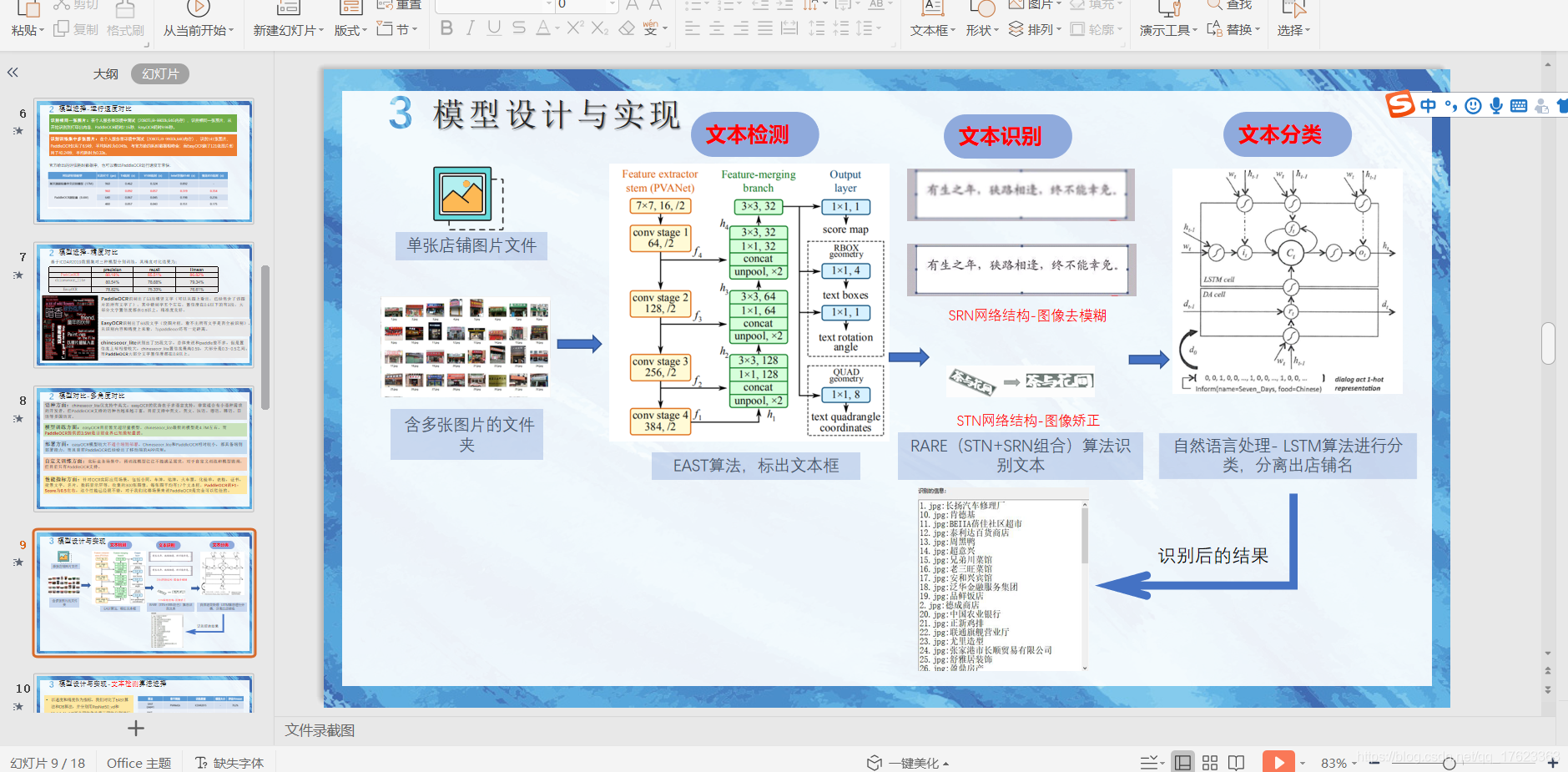
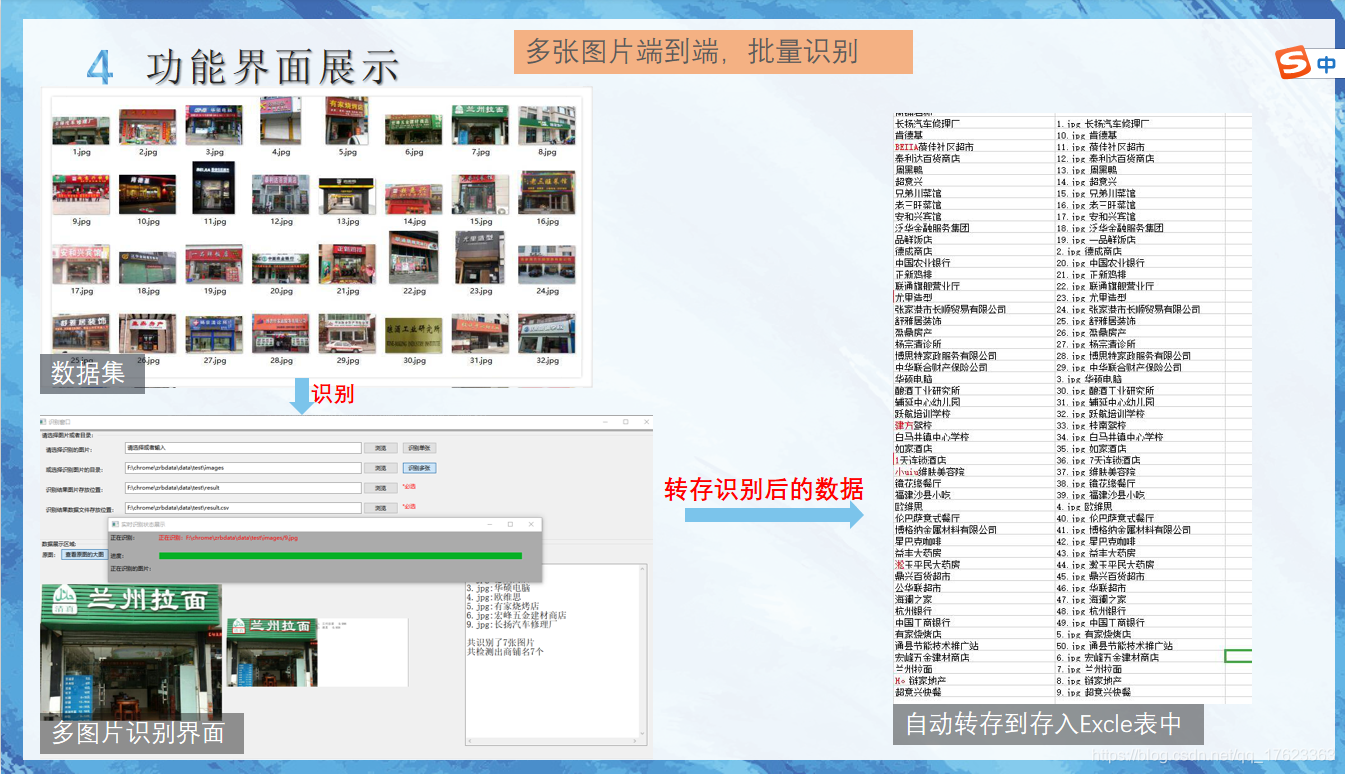
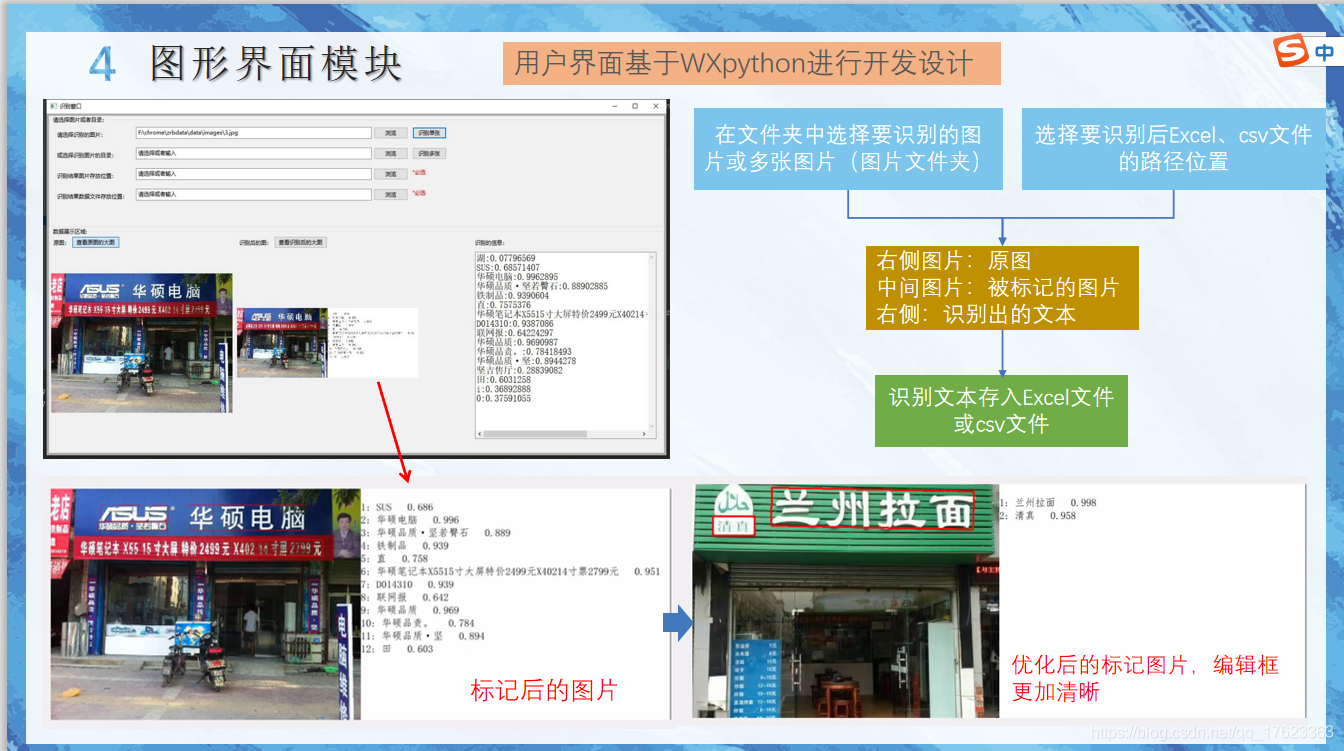
真的很牛逼,
PaddleOCR搭配上我們自己寫的NLP,簡直就是無敵呀!

當然了,現在還在參賽階段,其他的還不方便公開,如果想要源代碼和其他資料的話,賽后我都可以提供,可以留言郵箱,或者加我的粉絲群,等待我上傳即可,
二、OCR簡介
(一)什么是OCR
OCR——光學字符識別(Optical Character Recognition)是指對文本資料的影像檔案進行分析識別處理,獲取文字及版面資訊的程序,亦即將影像中的文字進行識別,并以文本的形式回傳,
(二)應用舉例
OCR技術有著豐富的應用場景,包括已經在日常生活中廣泛應用的面向垂類的結構化文本識別,如車牌識別、銀行卡資訊識別、身份證資訊識別、火車票資訊識別等等,此外,通用OCR技術也有廣泛的應用,如在視頻場景中,經常使用OCR技術進行字幕自動翻譯、內容安全監控等等,或者與視覺特征相結合,完成視頻理解、視頻搜索等任務,

(三)OCR難點
- 1、技術難點:如
透視、縮放、彎曲、雜亂、字體、多語言、模糊等; - 2、OCR應用常
對接海量資料,但要求資料能夠得到實時處理; - 3、并且OCR應用
常部署在移動端或嵌入式硬體,而端側的存盤空間和計算能力有限,因此對OCR模型的大小和預測速度有很高的要求,
如此多的難點,肯定是要解決的啊,所以有難點就有解決的辦法——PaddleOCR解決了上述所有的問題,是不是很期待的了解PaddleOCR呢?
三、PaddleOCR介紹
下面揭開
PaddleOCR的神秘面目,一起來認識一下PaddleOCR,
(一)總結介紹
- PaddleOCR是一款超輕量中英文識別模型
- 目標是打造豐富、領先、實用的文本識別模型/工具庫
- 3.5M實用超輕量OCR系統,支持在服務器,移動,嵌入式和IoT設備之間進行培訓和部署
- 同時支持中英文識別;支持傾斜、豎排等多種方向文字識別
- 支持GPU、CPU預測
- 可運行于Linux、Windows、MacOS等多種系統
- 用戶既可以通過PaddleHub很便捷的直接使用該超輕量模型,也可以使用PaddleOCR開源套件訓練自己的超輕量模型
上面是官方解釋,總結幾點:
- 1、體積小;
- 2、運行快;
- 3、方便簡單;
- 4、性能還賊好,
(二)相關地址總結
為了方便小伙伴們后期的使用,我把我使用的網址給大家總結匯總了一下,如下所示,
該模型已經開源,而且還給了很多的教程:
1、GitHub開源地址:https://github.com/PaddlePaddle/PaddleOCR
2、原始碼PaddleHub在線體驗:https://aistudio.baidu.com/aistudio/projectdetail/507159
3、AI快車道2020-PaddleOCR學習教程:
https://aistudio.baidu.com/aistudio/education/group/info/1519
4、網頁版體驗網址:https://www.paddlepaddle.org.cn/hub/scene/ocr
5、移動端下載二維碼:

四、PaddleOCR的使用
(一)PaddleOCR專案介紹
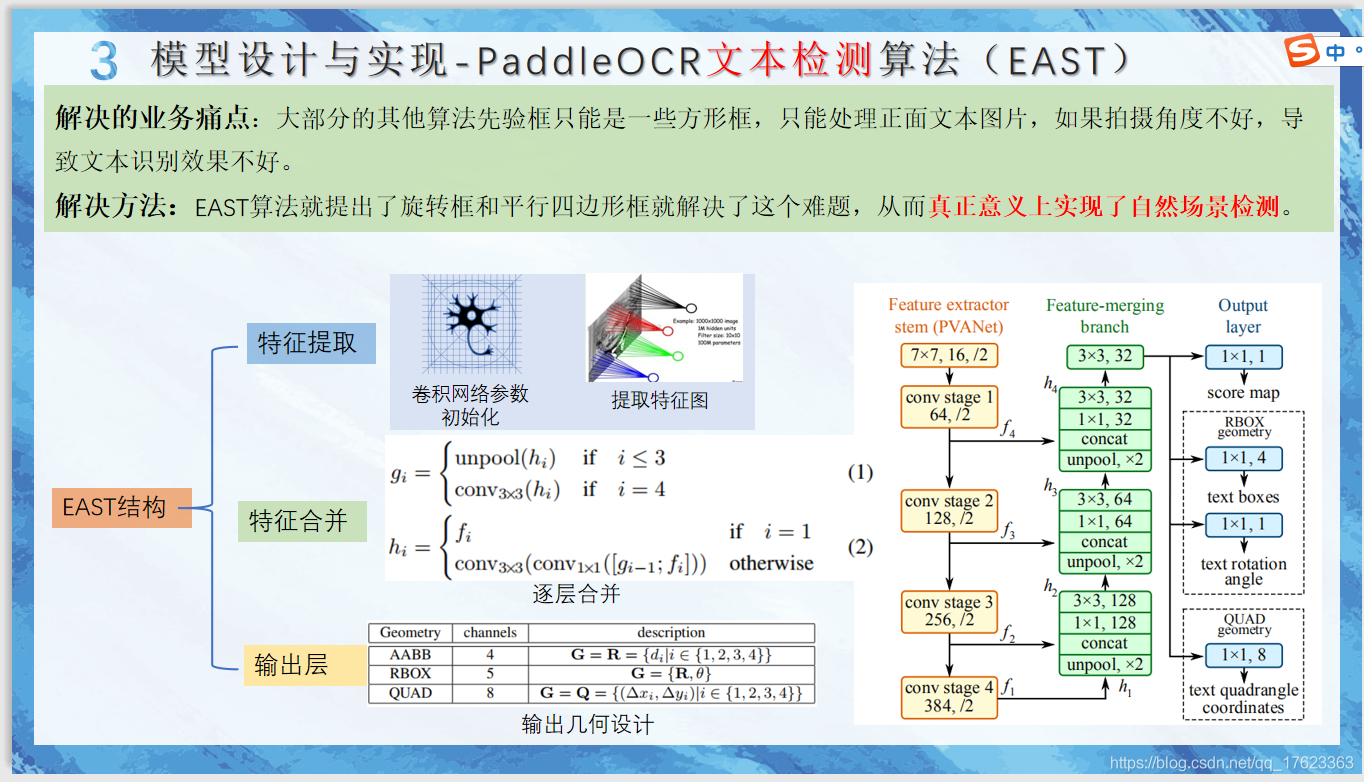
OCR用戶的需求很難通過一個通用模型來滿足,為了方便開發者使用自己的資料自定義超輕量模型,除了3.5M超輕量模型外(可識別6622個漢字),PaddleOCR同時提供了2種文本檢測演算法(EAST、DB)、4種文本識別演算法(CRNN、Rosseta、STAR-Net、RARE),基本可以覆寫常見OCR任務的需求,并且演算法還在持續豐富中,
特別是模型訓練/評估中的中文OCR訓練預測技巧,更是讓人眼前一亮,點進去可以看到中文長文本識別的特殊處理、如何更換不同的backbone等業務實戰技巧,相當符合開發者專案實戰中的煉丹需求,
以上這些在其官方GitHub上有詳細的使用檔案教程,建議把該專案克隆到本地,直接看那個md格式的中文版檔案,介紹的非常詳細,從安裝部署到運行測驗,每一步都有,堪稱最全OCR開發者檔案大禮包,

首先這些教程大都是基于Linux的,對一些沒有服務器或者剛接觸深度學習的同學來說運行運行起來可能有點困難,

下面博主就來講下怎么在Windows系統上直接運行,
(二)測驗自己的資料
相信想嘗試原始碼的同學大都要有Python深度學習的環境,可能有些沒有paddle的環境,當然這安裝起來也很簡單,而且pip下載極快,畢竟是國產的框架嘛!嘿嘿😎,
飛槳官網paddle環境配置教程:https://www.paddlepaddle.org.cn/install/quick
配好環境之后將GitHub的原始碼下載或者Git克隆到本地,在PaddleOCR里建個py檔案輸入以下內容:
from paddleocr import PaddleOCR
from tools.infer.utility import draw_ocr
from PIL import Image
# Paddleocr目前支持中英文、英文、法語、德語、韓語、日語,可以通過修改lang引數進行切換
# 引數依次為`ch`, `en`, `french`, `german`, `korean`, `japan`,
ocr = PaddleOCR(use_angle_cls=True, lang="ch")
img_path = 'img/test.png'#改成自己圖片的地址
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
# 顯示結果
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/doc/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.show()
im_show.save('img/result.jpg')

當然,也可以對整個檔案夾里的圖片內容進行檢測識別并可以保存識別結果,
from paddleocr import PaddleOCR
from tools.infer.utility import draw_ocr
from PIL import Image
import os
import csv
def pre_save(img_path,save_path,csv_path):
f = open(csv_path, 'w', encoding='utf-8')
writer = csv.writer(f)
writer.writerow(["img", "result"])
# Paddleocr目前支持中英文、英文、法語、德語、韓語、日語,可以通過修改lang引數進行切換
# 引數依次為`ch`, `en`, `french`, `german`, `korean`, `japan`,
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
i=0
for img in os.listdir(img_path):
print(img_path+'/'+img)
i+=1
result = ocr.ocr(img_path+'/'+img, cls=True)
image = Image.open(img_path+'/'+img).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='/doc/simfang.ttf')
im_show = Image.fromarray(im_show)
#im_show.show()
im_show.save(save_path+img)
al = []
for res in result:
result = res[1][:][:]
al.append(result)
print(str(al))
writer.writerow([img,str(al)])
print(i)
##img_path是要檢測的圖片的檔案夾地址,save_path是要保存結果的檔案夾的地址(注意后面要有個/),csv_path是識別結果要保存的csv檔案地址(可以自動創建)
img_path=r'F:\lzpython\PaddleOCR-develop\doc\imgs'
save_path=r'F:\chrome\zrbdata\imgs\result1/'
csv_path=r'F:\chrome\zrbdata\imgs\result.csv'
pre_save(img_path,save_path,csv_path)

不管你電腦是否有GPU,用這個代碼,該模型都能跑(只是有GPU跑的更快一些罷了),
五、多維度對比分析
回歸正題,我們是來分析哪個模型演算法比較好的;也到了最精彩的片段,
單說肯定也看不出優秀之處,不如對比來看,嘿嘿!
現在主流的ocr開源專案主要有easyocr、chineseocr_lite當然還有大牛paddleocr
我們分別對比下面幾種:
- 1、教程的完備性對比;
- 2、易用性對比;
- 3、運行速度對比;
- 4、精準度對比;
- 5、多角度對比,
(一)教程的完備性對比
- 作為一個開發者(入門沒多久的開發者😂),EasyOCR的檔案真的一言難盡,chineseocr_lite的教程對pycharm使用者也是不太友好的
- PaddleOCR的檔案上面也貼出來了,不細說了自己看吧,從安裝到訓練到部署,可以說是我見過最詳細的教程了,
總結:
1、EasyOCR和chineseocr_lite教程不便于沒基礎的人使用;
2、PaddleOCR的檔案齊全,通俗易懂,適合無基礎的人使用,
(二)易用性對比
PaddleOCR有網頁版,移動版,可以讓使用者直接用;在開發者使用時也是一樣,PaddleOCR的詳細的檔案可以讓開發者快速理解模型,并能訓練自己的資料,甚至可以增加一些功能;EasyOCR應該也可以跟Paddle似的擴展不少東西,但還是苦于沒有檔案,沒辦法;chineseocr_lite給出了網頁版和api介面也挺方便的,但還是苦于教程不全面,不太方面配置,- 同時PaddleOCR給出了多種模型,可以供開發者在不同場合使用,
| 模型簡介 | 模型名稱 | 推薦場景 | 檢測模型 | 方向分類器 |
|---|---|---|---|---|
| 中英文超輕量OCR模型(8.1M) | ch_ppocr_mobile_v1.1_xx | 移動端&服務器端 | 推理模型 / 預訓練模型 | 推理模型 / 預訓練模型 |
| 中英文通用OCR模型(155.1M) | ch_ppocr_server_v1.1_xx | 服務器端 | 推理模型 / 預訓練模型 | 推理模型 / 預訓練模型 |
| 中英文超輕量壓縮OCR模型(3.5M) | ch_ppocr_mobile_slim_v1.1_xx | 移動端 | 推理模型 / slim模型 | 推理模型 / slim模型 |
(三)運行速度對比
評價一個演算法的好壞,我們往往都是從時空復雜度來評價,
-
用我的低配置電腦,
同樣的圖片,從開始識別到列印出內容,PaddleOCR耗時2.15秒,EasyOCR耗時9.96秒,這只是一張圖片,幾秒鐘看不出啥區別,要是對很多張圖片或者視頻中的文字進行識別的話,差距確實有點大, -
接下來用
多張圖片進行運行時間上的對比,其主要差距有:- 在我的電腦上運行,其
運行時間上有明顯差距,PaddleOCR跑了141張圖片,僅僅用了6.9秒,平均耗時為0.048s,與官方給的耗時資料相吻合;而EasyOCR跑了121張圖片卻用了40.24秒,平均耗時為0.33s, - 為啥EasyOCR用了121 張圖片呢?因為他不支持.gif格式的圖片的識別,所以我將20張.gif格式的圖片刪了,
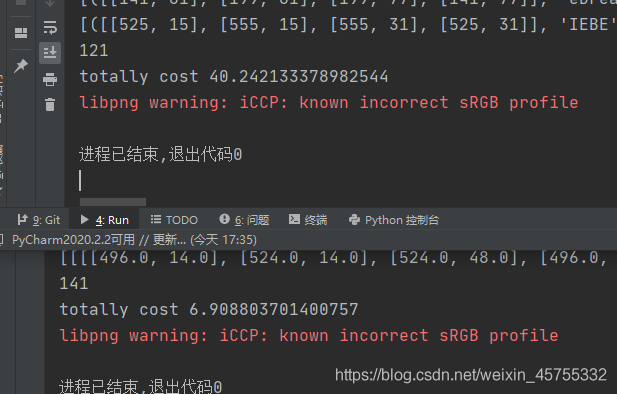
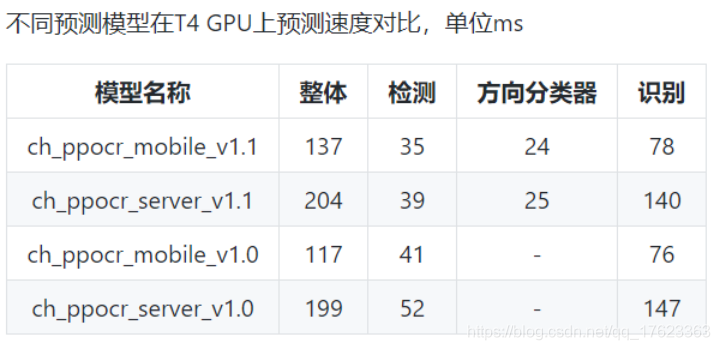
這是官方給的評估耗時資料:
在GPU T4上,移動端模型只需要137ms,而在驍龍855移動端處理時延也只有300ms左右, - 在我的電腦上運行,其

(四)精度對比
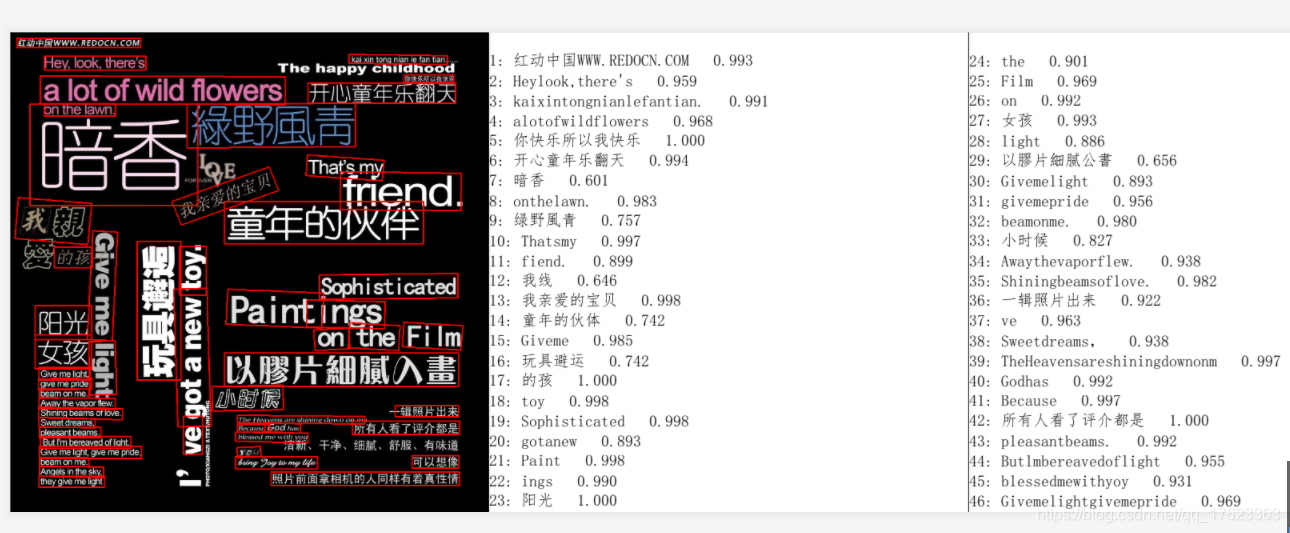
當然了,評價一個模型是否可以使用,肯定要看準確度了,如果識別的都不準確,那肯定是無法進行應用的,以下面這個圖片為例,

(1)PaddleOCR:
PaddleOCR識別出了53段橫豎文字(可以從圖上看出,已經包含了該圖片的所有文字了),其中錯別字也就五個左右吧,置信度在0.6以下的有3段,大部分文字置信度都在0.8以上,
(2)EasyOCR:
EasyOCR識別出了63段文字(沒圖片框,看不出所有文字是否全被識別),從識別內容和精度上來看,與paddleocr還有一定距離,
( '紅動中國WWW. REDOCN.COM', 0.14594213664531708)
( 'Hey,', 0.9193199872970581)
('The happxienffgefgiga', 0.000323598796967417)
( 'nian le fan tian', 0.537309467792511)
( 'look, theres', 0.22078940272331238)
('alot ofwild flowers', 0.057002753019332886)
('你怏樂所以我快樂', 0.531562089920044)
('開心童年樂翻夭', 0.8216490149497986)
('-野凰青', 0.004080250393599272)
('on the lawn.', 0.44294288754463196)
('暗香', 0.9942429661750793)
('.RE', 0.18314962089061737)
( 'Thats', 0.7607358694076538)
('my', 0.6383113861083984)
('frend', 0.45365384221076965)
('FOREVER', 0.7280043363571167)
('童年的伙侔', 0.7070863246917725)
-
(3)chineseocr_lite:
該模型識別出了35段文字,總體來說和paddle差不多,但是置信度上卻相差了一大截,chineseocr_lite置信度最高0.59,大部分是0.3~0.5之前的,

(五)多角度對比
對于OCR方向開發者而言,開源repo最吸引人的莫過于:
-
① 高質量的預訓練模型;
-
② 簡單易上手的訓練代碼;
-
③ 好用無坑的部署能力,
簡單對比一下目前主流OCR方向開源repo的核心能力
| 語種 | 預訓練模型大小 | F1-Score | 端側部署 | 自定義訓練 | 支持pip安裝 | |
|---|---|---|---|---|---|---|
| chineseocr_lite | 中英文 | 4.7M | 0.3899 | 支持 | 不支持 | 不支持 |
| easyOCR | 多語言 | 218M | 0.2214 | 不支持 | 不支持 | 支持 |
| PaddleOCR | 多語言 | 3.5M | 0.521 | 支持 | 支持 | 支持 |
-
對于語種方面,chineseocr_lite僅支持中英文,easyOCR的優勢在于多語言支持,非常適合有小語種需求的開發者,但PaddleOCR支持的語種也越來越豐富,目前支持中英文、英文、法語、德語、韓語、日語等多國語言,
-
從預訓練模型來看,
easyOCR目前暫無超輕量模型,chineseocr_lite最新的模型是4.7M左右,而PaddleOCR提供的3.5M是目前業界已知最輕量的; -
對于部署方面,
easyOCR模型較大不適合端側部署,Chineseocr_lite和PaddleOCR相對較小,都具備端側部署能力,而且目前PaddleOCR已經給出了移動端的APP應用; -
對于自定義訓練,實際業務場景中,預訓練模型往往不能滿足需求,對于自定義訓練和模型微調,但目前
只有PaddleOCR支持; -
從性能指標來看:針對OCR實際應用場景,包括合同,車牌,銘牌,火車票,化驗單,表格,證書,街景文字,名片,數碼顯示屏等,收集的300張影像,每張圖平均有17個文本框,PaddleOCR的F1-Score超過0.5,這個性能已經很不錯了,
(六)其他分析
我們知道,訓練與測驗資料的一致性直接影響模型效果,為了更好的模型效果,經常需要使用自己的資料訓練超輕量模型,PaddleOCR本次開源內容除了3.5M超輕量模型,同時提供了2種文本檢測演算法、4種文本識別演算法,并發布了相應的4種文本檢測模型、8種文本識別模型,用戶可以在此基礎上打造自己的超輕量模型,
PaddleOCR本次開源了多種業界知名的文本檢測和識別演算法,每種演算法的效果都達到或超越了原作,在ICDAR2015文本檢測公開資料集上,演算法效果如下:
| 模型 | 骨干網路 | precision | recall | Hmean | 下載鏈接 |
|---|---|---|---|---|---|
| EAST | ResNet50_vd | 88.18% | 85.51% | 86.82% | 下載鏈接 |
| EAST | MobileNetV3 | 81.67% | 79.83% | 80.74% | 下載鏈接 |
| DB | ResNet50_vd | 83.79% | 80.65% | 82.19% | 下載鏈接 |
| DB | MobileNetV3 | 75.92% | 73.18% | 74.53% | 下載鏈接 |
| SAST | ResNet50_vd | 92.18% | 82.96% | 87.33% | 下載鏈接 |
在Total-text文本檢測公開資料集上,演算法效果也是驚人的好,
文本識別演算法部分,借鑒DTRB[3]文字識別訓練和評估流程,實作了CRNN、Rosseta、STAR-Net、RARE四種文本識別演算法,覆寫了主流的基于CTC和基于Attention的兩類文本識別演算法,使用MJSynth和SynthText兩個文字識別資料集訓練,在IIIT, SVT, IC03, IC13, IC15, SVTP, CUTE資料集上進行評估,演算法效果如下:
| 模型 | 骨干網路 | Avg Accuracy | 模型存盤命名 | 下載鏈接 |
|---|---|---|---|---|
| Rosetta | Resnet34_vd | 80.24% | rec_r34_vd_none_none_ctc | 下載鏈接 |
| Rosetta | MobileNetV3 | 78.16% | rec_mv3_none_none_ctc | 下載鏈接 |
| CRNN | Resnet34_vd | 82.20% | rec_r34_vd_none_bilstm_ctc | 下載鏈接 |
| CRNN | MobileNetV3 | 79.37% | rec_mv3_none_bilstm_ctc | 下載鏈接 |
| STAR-Net | Resnet34_vd | 83.93% | rec_r34_vd_tps_bilstm_ctc | 下載鏈接 |
| STAR-Net | MobileNetV3 | 81.56% | rec_mv3_tps_bilstm_ctc | 下載鏈接 |
| RARE | Resnet34_vd | 84.90% | rec_r34_vd_tps_bilstm_attn | 下載鏈接 |
| RARE | MobileNetV3 | 83.32% | rec_mv3_tps_bilstm_attn | 下載鏈接 |
| SRN | Resnet50_vd_fpn | 88.33% | rec_r50fpn_vd_none_srn | 下載鏈接 |
使用LSVT街景資料集根據真值將圖crop出來30w資料,進行位置校準,此外基于LSVT語料生成500w合成資料訓練中文模型,相關配置和預訓練檔案如下:
| 模型 | 骨干網路 | 組態檔 | 預訓練模型 |
|---|---|---|---|
| 超輕量中文模型 | MobileNetV3 | rec_chinese_lite_train.yml | 下載鏈接 |
| 通用中文OCR模型 | Resnet34_vd | rec_chinese_common_train.yml | 下載鏈接 |
具體結果怎么出來的呢?可以參考PaddleOCR官方給的檔案——模型訓練/評估中的文本識別部分
六、總結
PaddleOCR總結幾點:
- 體積小
- 運行快
- 部署方便
- 使用簡單
- 性能還賊好
通過各種維度的對比,我們還是決定使用PaddleOCR做為我們參加比賽的模型,現在已經開發的差不多了,可以持續關注我,等我們參加完比賽,可以把具體所有代碼給公布出來,也方便大家學習,
也可以從https://github.com/trending和https://paperswithcode.com/看一下開源專案的排名,排名也都是很不錯的,說明關注這個的人還是比較多的,說明用戶群體也是很多的,
當然了,現在還在參賽階段,其他的還不方便公開,如果想要源代碼和其他資料的話,賽后我都可以提供,可以留言郵箱,賽后會一一發給大家的,
GitHub開源地址:https://github.com/PaddlePaddle/PaddleOCR
個人建議給國產開源專案一個Star,如果喜歡也可以點下Fork,我覺得這樣他們會更有動力去繼續創作,創新,
嘿嘿,如果Star了之后,可以找我拿我參賽的源代碼,也算是給國產開源專案PaddleOCR一份支持的力量了,

 CSDN認證博客專家
Linux
分布式
Java
CSDN認證博客專家
Linux
分布式
Java
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/185863.html
標籤:其他
上一篇:有什么建站軟體可以快速建網站?