1. 統計學習
1.1 統計學習的方法
- 基于資料構建概率統計模型從而對資料進行預測與分析,統計學習由監督學習、無監督學習、強化學習等組成
1.2 實作統計學習的方法的步驟
1)得到一個有限的訓練資料集合
2)確定包含所有可能的模型的假設空間,即學習模型的集合
3)確定模型選擇的準則,即學習的策略
4)實作求解最優模型的演算法,即學習的演算法
5)通過學習方法選擇最優模型
6)利用學習的最優模型對新資料進行預測或分析
2. 統計學習的分類
2.1 基本分類
2.1.1 監督學習
2.1.1.1 定義:
1)指從標注資料中學習預測模型的機器學習問題,標注資料表示輸入輸出的對應關系,預測模型對給定的輸入產生相應的輸出,監督學習的本質是學習輸入到輸出的映射的統計規律
2.1.1.2 特征向量:
1)\(x=\left ( x^{(1)}, x^{(2)},x^{(3)},x^{(4)}...x^{(n)}\right )^{T}\)
2.1.1.3 第i個變數:
1)\(x_{i}=\left ( x_{i}^{(1)}, x_{i}^{(2)},x_{i}^{(3)},x_{i}^{(4)}...x_{i}^{(n)}\right )^{T}\)
2.1.1.4 訓練集:
1)\(T=\left \{ \left ( x_{1},y_{1} \right ),\left ( x_{2},y_{2} \right )...\left ( x_{N},y_{N} \right ) \right \}\)
2.1.1.5 聯合概率分布:
1)監督學習假設輸入與輸出的隨機變數X和Y遵循聯合概率分布P(X, Y),P(X, Y)表示分布函式,或分布密度函式,訓練資料與測驗資料被看作是依聯合概率分布P(X, Y)獨立同分布產生的,統計學習假設資料存在一定的統計規律,X和Y具有聯合概率分布就是監督學習關于資料的基術假設
2.1.1.6 假設空間:
1)輸入空間到輸出空間的映射,模型可以表示為P(y|x)或y=f(x)
2.1.1.7 問題形式化:
1)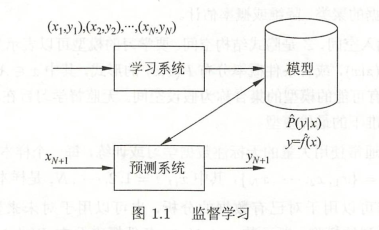
在預測程序中,預測系統對于給定的輸入\(x_{N+1}\)由模型\(y_{N+1} = \underset{y}{argmax}\hat{P}\left ( y|x_{N+1} \right )\)或\(y_{N+1} = \hat{f}\left ( x_{N+1} \right )\)給出相應的輸出\(y_{N+1}\)
2.1.2 無監督學習
2.1.2.1 定義:
1)指從無標注資料中學習預測模型的機器學習問題,無標注資料是自然得到的資料,預測模型表示資料的類別、轉換或概率,無監督學習的本質是學習資料中的統計規律或潛在結構,可以用于對已有的資料進行分析或者對未來的資料進行預測
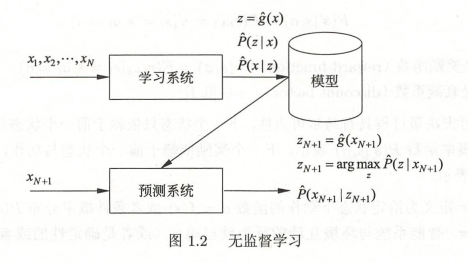
每一個輸出是對輸入的分析結果,由輸入的類別、轉換或概率表達,模型可以實作對資料的聚類、降維或概率估計
2.1.2.2 無監督學習的模型:
1)函式\(z=g_{\theta }(x)\)(硬聚類:一個樣本只能屬于一個類)、條件概率分布\(P_{\theta }(z|x)\)(軟聚類:一個樣本可以屬于多個類)或條件概率分布\(P_{\theta }(x|z)\)(概率模型估計)
2.1.3 強化學習
2.1.3.1 定義:
1)指智能系統在與環境的連續互動中學習最優行為策略的機器學習問題,假設智能系統與環境的互動基于馬爾可夫決策程序(Marlcov decision process)智能系統能觀測到的是與環境互動得到的資料序列,強化學習的本質是學習最優的序貫決策,
2.1.3.2 智能系統與環境的互動:
1)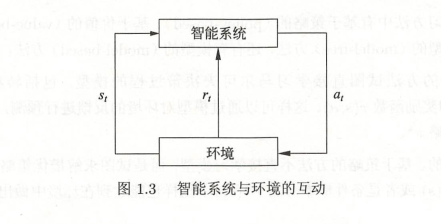
目標是長期累積的獎勵最大化
2.1.3.3 馬可夫決策程序:
1)
2.1.3.4 馬可夫決策程序求解:
1)貝爾曼方程:
\(V_{*}\left ( s \right )= \underset{a}{\max}\underset{{s}',r}{\sum} p\left ( {s}',r|s,a \right )\left [ r+\gamma V_{*}\left ( {s}' \right ) \right ]\)
貝爾曼方程中狀態s的價值V(s)由兩部分組成:
a.采取動作a后帶來的獎勵r
b.采取動作a后到達的新狀態的價值V(s′)
2)策略迭代:
a.初始化: 隨機選擇一個策略作為初始值, 比如“不管什么狀態, 一律朝下走”, 即P( A = 朝下走 | St=s) = 1, P( A = 其他 | St=s) = 0
b.進行策略評估: 根據當前的策略計算 \(V_{\pi }\left ( s \right )= E_{\pi }\left ( r+\gamma V_{\pi }\left ( {s}' \right )|S_{t}=s \right )\),
c.進行策略提升: 計算當前狀態的最優動作\(\underset{a}{\max}\left \{ q_{\pi }\left ( s,a \right ) \right \}\),更新策略\(\pi _{s}= \underset{a}{argmax}\underset{{s}',r}{\sum}p\left ( {s}',r|s,a \right )\left [ r+\gamma V_{\pi }\left ( {s}' \right ) \right ]\)
d.不停地重復策略評估和策略提升, 直到策略不再變化為止
2.1.4 半監督學習與主動學習
2.1.4.1 半監督學習:
1)指利用標注資料和未標注資料學習預測模型的機器學習問題
2.1.4.2 主動學習:
1)指機器不斷主動給出實體讓教師進行標注,然后利用標注資料學習預測模型的機器學習問題
2.2 模型分類
2.2.1 概率模型與非概率模型
2.2.1.1 概率模型:
1)監督學習中概率模型取條件概率分布形式P(y|x)且是生成模型,無監督學習中概率模型取概率分布形式P(z|x)或P(x|z)且是判別模型
2)決策樹,樸素貝葉斯,隱馬爾可夫模型,條件隨機場,概率潛在語意分析,潛在狄利克雷分配,高斯混合模型,邏輯斯諦回歸
2.2.1.2 非概率模型:
1)監督學習中非概率模型取函式形式y=f(x),無監督學習中非概率模型取函式形式z=g(x)
2)感知機,支持向量機,K近鄰,AdaBoost,K均值,潛在語意分析,神經網路,邏輯斯諦回歸
2.2.2 線性模型與非線性模型
- 統計學習模型,特別是非概率模型如果函式是線性函式則為線性模型反之是非線性模型,感知機、線性支持向量機、K近鄰、K均值、潛在語意分析是線性模型,核函式支持向量機、AdaBoost、神經網路是非線性模型
2.3 演算法分類
2.3.1 在線學習:
- 每次接受一個樣本,進行預測,之后學習模型并重復該操作的機器學習
2.3.2 批量學習:
- 一次接受所有資料,學習模型之后進行預測
2.4 技巧分類
2.4.1 貝葉斯學習
2.4.1.1 最大后驗概率統計:
1)貝葉斯公式:
后驗概率:\(P\left ( \theta |D \right )=\frac{P\left ( D|\theta \right )\cdot P\left ( \theta \right )}{P\left ( D \right )}\)
極大似然估計:\(P\left ( D|\theta \right )=\prod_{i=1}^{n}P\left ( x_{i}|\theta \right )\)
先驗概率:\(P\left ( \theta \right )\)
概率密度函式:\(f\left ( \theta \right ) = -\sum_{i=1}^{n}P\left ( x_{i}|\theta \right )\)
由于樣本概率\(P\left ( D \right )\)固定,所以后驗概率可化為求:
2)L1正則化:
假設\(\theta\)滿足拉普拉斯分布\(P\left ( \theta \right )=\frac{1}{2\lambda }e\tfrac{-\left | \theta_{i} \right |}{\lambda }\)則①可化為:
L1范式:\(\left \| \theta \right \|_{1} = \left | \theta _{1} \right |+\left | \theta _{2} \right |+...+\left | \theta _{n} \right |\)
3)L2正則化:
假設\(\theta\)滿足正態分布(均值為0,方差為\(\sigma ^{2}\))\(P\left ( \theta \right )=\frac{1}{\sqrt{2\pi }\sigma }e^{\frac{-\theta _{i}^{2}}{2\sigma ^{2}}}\)則①可化為:
L2范式:\(\left \| \theta \right \|_{2} =\sqrt{\theta _{1}^{2}+\theta _{2}^{2}+...+\theta _{n}^{2}}\)
4)L1、L2正則化防止過擬合:
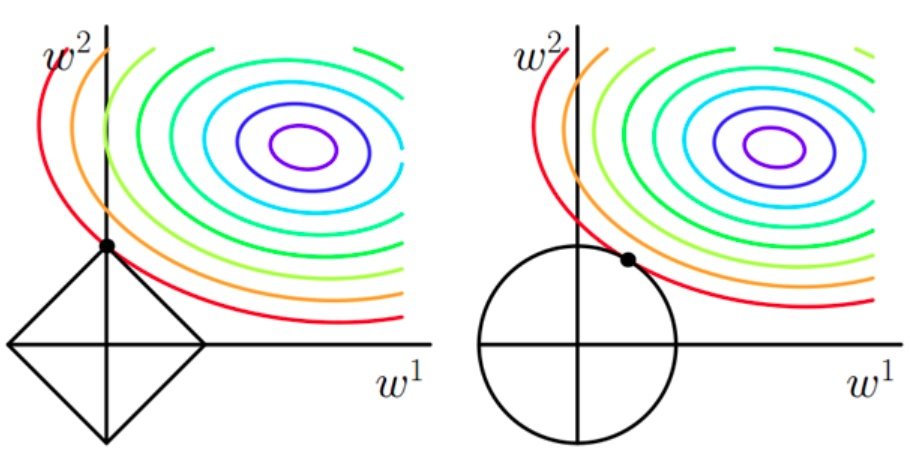
正則化之所以能夠降低過擬合的原因在于,正則化是結構風險最小化的一種策略實作
給loss function加上正則化項,能使得新得到的優化目標函式h = f+normal,需要在f和normal中做一個權衡(trade-off),如果還像原來只優化f的情況下,那可能得到一組解比較復雜,使得正則項normal比較大,那么h就不是最優的,因此可以看出加正則項能讓解更加簡單,符合奧卡姆剃刀理論,同時也比較符合在偏差和方差(方差表示模型的復雜度)分析中,通過降低模型復雜度,得到更小的泛化誤差,降低過擬合程度
L1正則化和L2正則化:
L1正則化就是在loss function后邊所加正則項為L1范數,加上L1范數容易得到稀疏解(0比較多),L2正則化就是loss function后邊所加正則項為L2范數的平方,加上L2正則相比于L1正則來說,得到的解比較平滑(不是稀疏),但是同樣能夠保證解中接近于0(但不是等于0,所以相對平滑)的維度比較多,降低模型的復雜度
2.4.2 核方法
- 使用核函式表示和學習非線性模型的一種機器學習方法,將線性模型擴展到非線性模型,應用更廣泛
3. 統計學習方法三要素
3.1 模型


3.2 策略
3.2.1 損失函式和風險函式
3.2.1.1 損失函式:
1)定義:度量模型一次的好壞
2)分類:
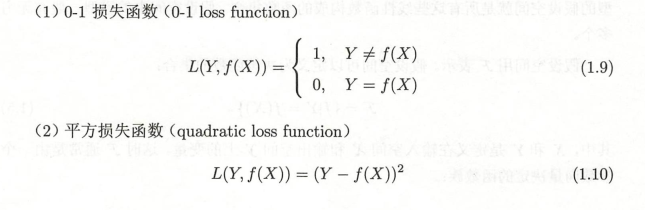

3.2.1.2 風險函式:
1)定義:度量平均意義下模型預測的好壞

3.2.2 經驗風險最小化和結構風險最小化
3.2.2.1 經驗風險最小化:
1)
3.2.2.2 結構風險最小化:
1)

3.3 演算法
- 演算法是指學習模型的具體計算方法,統計學習基于訓練資料集,根據學習策略,從假設空間中選擇最優模型,最后需要考慮用什么樣的計算方法求解最優模型(Keras)
4. 模型評估和模型選擇
4.1 訓練誤差與測驗誤差
4.1.1 訓練誤差
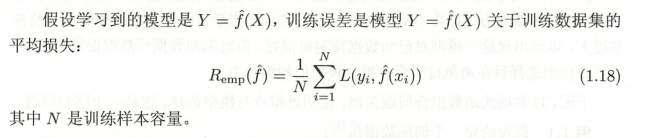
4.1.2 測驗誤差
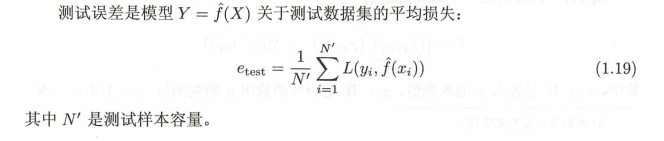
4.2 過擬合與模型選擇
4.2.1 過擬合
- 對于訓練資料擬合較好,精度較高,損失函式較小
- 對于測驗資料擬合較差,精度較低,損失函式較大
- 資料分布相對簡單,噪聲較多,機器學習模型復雜度較高
4.2.2 模型選擇
- 選擇復雜度合適的模型達到是測驗誤差最小的目的
5. 正則化與交叉驗證
5.1 正則化
- 見2.4.1.1
5.2 交叉驗證
5.2.1 簡單交叉驗證
- 將資料集按一定比例分為訓練集和測驗集,在各種條件下訓練得到模型,用測驗集評價模型的測驗誤差,選出誤差最小的模型
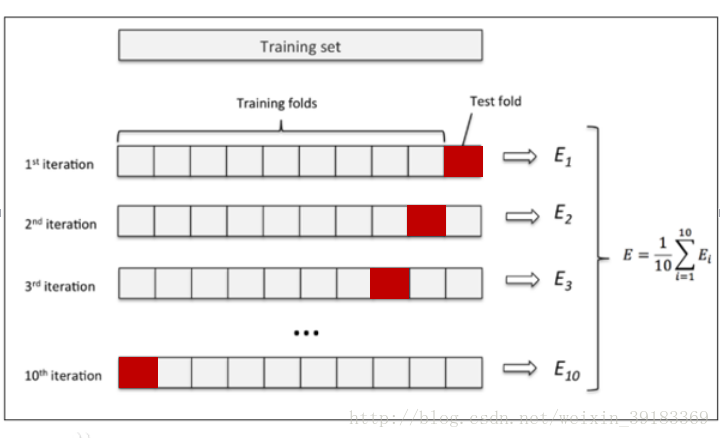
5.2.2 S折交叉驗證
- 第1步,將資料等分到s份
- 第2步,下列步驟重復s次
(1)每一次迭代中留存其中一份資料,第一次迭代中留存第1份,第二次留存第2份,其余依此類推,第i次留存第i份
(2)用其他s-1份資料的資訊作為訓練資料,訓練分類器(第一次迭代中利用從第2份到第s份的資訊進行訓練分類器)
(3)利用留存的資料作為測驗資料,來測驗分類器并保存測驗結果, - 第3步,上述步驟完成后,從s個分類器中,選擇最好的一個最為分類模型【如:用經驗風險最小進行模型選擇】
5.2.3 留一交叉驗證
- 留一法就是每次只留下一個樣本做測驗集,其它樣本做訓練集,如果有k個樣本,則需要訓練k次,測驗k次
- 留一發計算最繁瑣,但樣本利用率最高,適合于小樣本的情況
6. 泛化能力
6.1 泛化誤差

6.2 泛化誤差上界
6.2.1 定義

6.2.2 推導
不等式(1.32)左端R(f)是泛化誤差,右端即為泛化誤差上界,在泛化誤差上界中,第一項時候訓練誤差,訓練誤差越小,泛化誤差也越小,第二項 \(\varepsilon \left ( d,N,\delta \right )\) 是N的單調遞減函式,當N趨于無窮時趨于0,同時它也是 \(\sqrt{logd}\) 階的函式,假設空間F包含的函式越多,其值越大,
Hoeffding不等式:

可知\(\hat{R}\left ( f \right ) = E\bar{x},R\left ( f \right ) = \bar{x}\)

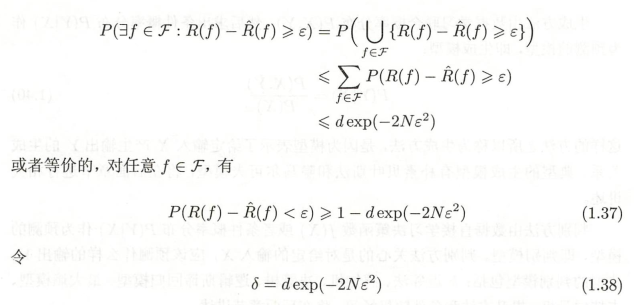
(1.38)的推導:

7. 生成模型與判別模型
7.1 生成模型
7.1.1 特點

生成模型估計的是聯合概率分布,特點是從統計的角度表示資料的分布情況,能反映同類資料本身的相似度,不關心各類的邊界在哪,生成模型可以得到判別模型,判別模型得不到生成模型
7.1.2 優缺點
7.1.2.1 優點:
1)由于統計了資料的分布情況,所以其實際帶的資訊要比判別模型豐富,對于研究單類問題來說也比判別模型靈活性強
2)模型可以通過增量學習得到(增量學習是指一個學習系統能不斷地從新樣本中學習新的知識,并能保存大部分以前已經學習到的知識)
3)收斂速度更快,當樣本容量增加的時,生成模型可以更快的收斂于真實模型
4)隱變數存在時,也可以使用
7.1.2.2 缺點:
1)學習和計算程序比較復雜,由于學習了更多的樣本資訊,所以計算量大,如果我們只是做分類,就浪費了這部分的計算量
2)準確率較差
3)往往需要對特征進行假設,比如樸素貝葉斯中需要假設特征間獨立同分布,所以如果所選特征不滿足這個條件,將極大影響生成式模型的性能
7.2 判別模型
7.2.1 特點

判別模型估計的是條件概率分布,不能反映訓練資料本身的特性,目的在于尋找不同類別之間的最優分界面
7.2.2 優缺點
7.2.2.1 優點:
1)由于關注的是資料的邊界,所以能清晰的分辨出多類或某一類與其他類之間的差異,所以準確率相對較高
2)計算量較小,需要的樣本數量也較小
7.2.2.2 缺點:
1)不能反映訓練資料本身的特性
2)收斂速度較慢
8. 監督學習的應用
8.1 分類問題
8.1.1 定義
- 輸出變數Y取有限個離散值的預測問題
8.1.2 精確率、召回率、混淆矩陣和\(F_{1}\)Score
8.1.2.1 混淆矩陣:
| 對二分類: | 預測值: | 0 | 1 |
|---|---|---|---|
| 真實 | 0 | TN | FN |
| 值 | 1 | FP | TP |
準確率:\(\frac{TP+TN}{D}\)
8.1.2.2 精確率:
1)\(P=\frac{TP}{TP+FP}\) 需要更多的正類
8.1.2.3 召回率:
1)\(P=\frac{TP}{TP+FN}\) 需要更多的負類正負樣本不均衡使用
8.1.2.4 \(F_{1}\)Score:
1)\(\frac{2}{F_{1}}=\frac{1}{P}+\frac{1}{R}\Rightarrow F_{1}=\frac{2PR}{P+R}=\frac{2TP}{2TP+FP+FN}\) 平衡精確率召回率
2)N分類:\(< F_{1}> =\frac{1}{n}\sum_{i=1}^{n}F_{i}=\frac{1}{n}\sum_{i=1}^{n}\frac{2P_{i}R_{i}}{P_{i}+R_{i}}\)
預測類作為正類其他類作為負類則化二分類問題
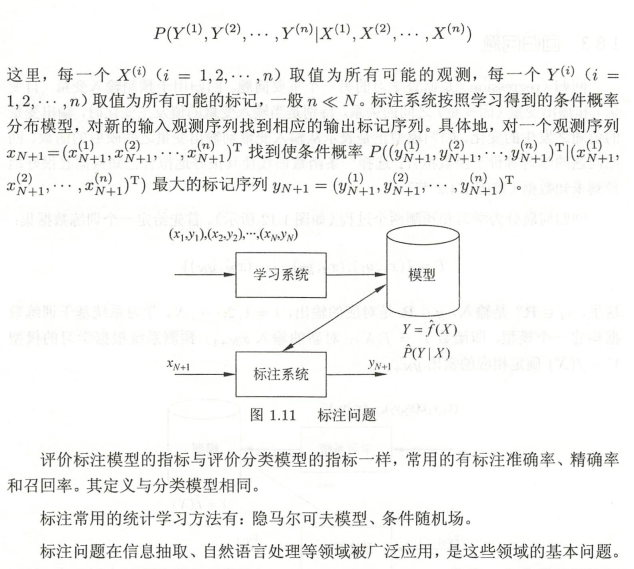
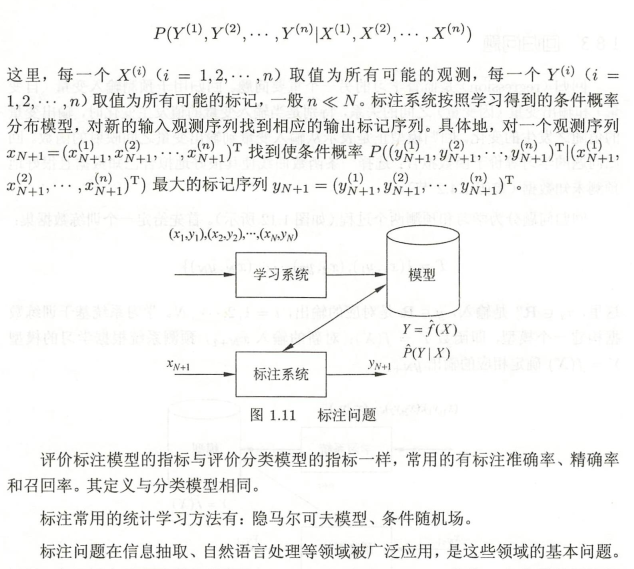
8.2 標注問題

8.2 回歸問題

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/186035.html
標籤:其他