資訊熵為什么要定義成-Σp*log(p)?
在解釋資訊熵之前,需要先來說說什么是資訊量,
資訊量是對資訊的度量,單位一般用bit,
資訊論之父克勞德·艾爾伍德·香農(Claude Elwood Shannon )對資訊量的定義如下:
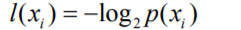
在解釋這個公式之前,先看看下面的例子,
比如一個黑箱里有2個蘋果,8個橙子我們把從黑箱里取蘋果、橙子看成是一個隨機程序,X={蘋果,橙子},
當我們了解到拿出來的是什么的時候,我們就接受到了資訊,這個資訊的資訊量的大小與這個東西出現的概率有關,這里蘋果是0.2,橙子是0.8,越小概率的事情發生,其產生的資訊量越大,比如我了解到拿出來的是一個蘋果所獲得的資訊量比一個橙子的資訊量要大的多,
至于為什么越小概率的事情發生,其產生的資訊量越大,可以這樣理解,在考慮資訊傳輸的程序中,如何對訊息序列進行合理的編碼轉換成信號序列,才可以節省信道容量?
以英語舉例,在電報通信中,要傳送的訊息由字符序列組成(比如摩爾斯電碼,每個摩爾斯電碼符號由一系列點和破折號組成),
如果最常見的英文字母 E 使用最短的信道符號“一個點”來表示;而出現較少的 Q,X,Z 等則使用更多的點和破折號來表示,則可以最大程度上節省信道容量,也就是說同樣的一句訊息,采用此策略來編碼,其傳輸需要的時間會更少,而事實上的電報通信中,正是這么做的,
那么這里的字母E由于出現概率最大,所以用了一個點來表示,其資訊量相對最小,
所以如果我們要尋找一個函式來定義資訊,則該函式要滿足如下條件:
要符合隨著概率的增大而減小的形式;
函式的值不能為負數,因為資訊量最小為0,
帶負號的對數函式顯然符合以上要求,當然,肯定有其他函式也會符合以上要求,對此,香農在《A Mathematical Theory of Communication》(通信的數學理論)這篇論文中有說明選擇對數函式的原因:

大意是說:
如果集合中的訊息的數量是有限的,而且每條訊息被選擇的可能性相等,那么這個訊息數或者任意這個訊息數的單調函式可以用來做為從集合選擇一條訊息時產生的資訊量的度量,而最自然的選擇是對數函式,
關于對數函式更便捷的原因,論文中給出了3點:
- 在實踐中更有用,
對數函式可以讓一些工程上非常重要的引數比如時間、帶寬、繼電器數量等與可能性的數量的對數成線性關系,例如,增加一個繼電器會使繼電器的可能狀態數加倍,而如果對這一可能狀態數求以2為底的對數,結果只是加 1,加倍時間,可能的訊息數會近似變成原來的平方(1,2,4,8,...),而其對數則是加倍(log2 1,log2 2,log2 4,log2 8,...)=(0,1,2,3,...) - 更貼近于人類對度量的直覺,
線性比較就是人類的度量直覺,比如,人們認為,兩張打孔卡存盤資訊的容量應當是一張打孔卡的兩倍,兩個相同信道的資訊傳輸能力應當是一個信道的兩倍, - 更適用數學運算,
許多極限運算很容易用對數表示,如果采用可能性的數目表示,可能會需要進行冗繁笨拙的重新表述,
那么,為什么選擇2為底的對數呢,論文中的解釋是這樣的:


大致意思是說選擇什么為底與用什么單位來度量資訊是對應的,采用2為底就是用2進制位,英文:binary digit(香農聽了J. W. Tukey的建議,將binary digit簡稱為bit,bit這個詞從此問世),采用10為底就是用10進制位,而在遇到一些積分和微分的分析中,用e為底有時會很有用,這個時候的資訊單位稱為自然單位,
個人理解就是這里用什么為底都可以,畢竟單位之間可以轉換,但是為了計算方便,如果你使用二進制數字來存盤資訊,還是用2為底更便捷,比如一開始郵件分類的例子中,有{無聊時閱讀的郵件、需及時處理的郵件、無需閱讀的郵件}三種,在1000封郵件中,每個類別出現的概率分別是1/2,1/4,1/4,
現在打算用二進制位表示分類,那么就直接可以計算出來各個類別的資訊量,也就是各個類別至少需要幾個二進制位來表示:
無聊時閱讀的郵件:-log2 (1/2) = 1,所以用1個二進制位可以表示;
需及時處理的郵件:-log2 (1/4) = 2,所以用2個二進制位可以表示;
無需閱讀的郵件:-log2 (1/4) = 2,所以用2個二進制位可以表示,
那么你可能要問了,雖然計算結果是這樣,但是怎么理解呢?
從直覺上理解就是,出現概率越大,資訊量越少,比如明天太陽從東邊升起,和明天太陽從西邊升起,后者的資訊量更大是符合直覺判斷的;
從存盤的角度來理解,對于那些出現概率越大的變數,用越少的位編碼的話,就可以節省出越大的空間,
說完了資訊量,我們來看看什么是資訊熵,
資訊量是表達某個事件需要的二進制位數,比如“某個郵件屬于需及時處理的郵件”就是一個事件,而所有可能產生的資訊量的期望值被定義為資訊熵,
根據概率和統計學中對期望值的定義:期望值是指在一個離散性隨機變數試驗中每次可能結果的概率乘以其結果的總和,可以得到資訊熵的公式如下:
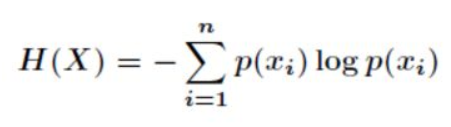
這里可能結果的概率是某個分類出現的概率,結果?是某個分類產生的資訊量,其中的log一般以2為底,
可以看出,某個資料集中包含的分類越多,資訊熵就越大,而包含分類多,說明這個資料集越混亂,越不純,
因此,在一些機器學習演算法比如ID3決策樹中就常用資訊熵來量化資料集的純度,以選擇出更好的特征來劃分資料,讓劃分出的資料子集越來越純,最終就可以根據多數表決來決定葉子節點的分類,從而構建出完整的分類決策樹,
ok,本篇就這么多內容啦~,感謝閱讀O(∩_∩)O,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/186251.html
標籤:其他
上一篇:二叉樹與線索二叉樹